 Shuhui Bu
6 years ago
Shuhui Bu
6 years ago
100 changed files with 18242 additions and 13 deletions
Split View
Diff Options
-
+89 -71_knn/knn_classification.ipynb
-
+49 -61_knn/knn_classification.py
-
+0 -01_nn/Perceptron.ipynb
-
+0 -01_nn/Perceptron.py
-
+0 -01_nn/images/L_b.png
-
+0 -01_nn/images/L_w.png
-
+0 -01_nn/images/bp_loss.png
-
+0 -01_nn/images/bp_weight_update.png
-
+0 -01_nn/images/cross_entropy_loss.png
-
+0 -01_nn/images/eqn_13_16.png
-
+0 -01_nn/images/eqn_17_20.png
-
+0 -01_nn/images/eqn_21_22.png
-
+0 -01_nn/images/eqn_23_25.png
-
+0 -01_nn/images/eqn_26.png
-
+0 -01_nn/images/eqn_27_29.png
-
+0 -01_nn/images/eqn_30_31.png
-
+0 -01_nn/images/eqn_32_34.png
-
+0 -01_nn/images/eqn_35_40.png
-
+0 -01_nn/images/eqn_3_4.png
-
+0 -01_nn/images/eqn_5_6.png
-
+0 -01_nn/images/eqn_7_12.png
-
+0 -01_nn/images/eqn_delta_hidden.png
-
+0 -01_nn/images/eqn_delta_j.png
-
+0 -01_nn/images/eqn_ed_net_j.png
-
+0 -01_nn/images/eqn_hidden_units.png
-
+0 -01_nn/images/eqn_matrix1.png
-
+0 -01_nn/images/eqn_w41_update.png
-
+0 -01_nn/images/eqn_w4b_update.png
-
+0 -01_nn/images/eqn_w84_update.png
-
+0 -01_nn/images/formular_2.png
-
+0 -01_nn/images/formular_3.png
-
+0 -01_nn/images/formular_4.png
-
+0 -01_nn/images/formular_5.png
-
+0 -01_nn/images/forumlar_delta4.png
-
+0 -01_nn/images/forumlar_delta8.png
-
+0 -01_nn/images/neuron.gif
-
+0 -01_nn/images/neuron.png
-
+0 -01_nn/images/nn1.jpeg
-
+0 -01_nn/images/nn2.png
-
+0 -01_nn/images/nn3.png
-
+0 -01_nn/images/nn_parameters_demo.png
-
+0 -01_nn/images/perceptron_2.PNG
-
+0 -01_nn/images/perceptron_geometry_def.png
-
+0 -01_nn/images/sigmod.jpg
-
+0 -01_nn/images/sign.png
-
+0 -01_nn/images/softmax.png
-
+0 -01_nn/images/softmax_demo.png
-
+0 -01_nn/images/softmax_neuron.png
-
+0 -01_nn/images/softmax_neuron_output2_eqn.png
-
+0 -01_nn/images/softmax_neuron_output_eqn.png
-
+0 -01_nn/mlp_bp.ipynb
-
+0 -01_nn/mlp_bp.py
-
+0 -01_nn/note.txt
-
+0 -01_nn/softmax_ce.ipynb
-
+0 -01_nn/softmax_ce.py
-
+961 -02_pytorch/0_basic/Tensor-and-Variable.ipynb
-
+653 -02_pytorch/0_basic/autograd.ipynb
-
+205 -02_pytorch/0_basic/dynamic-graph.ipynb
-
BIN2_pytorch/0_basic/imgs/autograd_Variable.png
-
+2 -02_pytorch/0_basic/imgs/autograd_Variable.svg
-
+2 -02_pytorch/0_basic/imgs/com_graph.svg
-
+2 -02_pytorch/0_basic/imgs/com_graph_backward.svg
-
+2 -02_pytorch/0_basic/imgs/tensor_data_structure.svg
-
+1554 -02_pytorch/0_basic/ref_Autograd.ipynb
-
+3043 -02_pytorch/0_basic/ref_Tensor.ipynb
-
+128 -02_pytorch/1_NN/bp.ipynb
-
+703 -02_pytorch/1_NN/deep-nn.ipynb
-
BIN2_pytorch/1_NN/imgs/ResNet.png
-
BIN2_pytorch/1_NN/imgs/lena.png
-
BIN2_pytorch/1_NN/imgs/lena3.png
-
BIN2_pytorch/1_NN/imgs/lena512.png
-
BIN2_pytorch/1_NN/imgs/multi_perceptron.png
-
BIN2_pytorch/1_NN/imgs/residual.png
-
BIN2_pytorch/1_NN/imgs/resnet1.png
-
BIN2_pytorch/1_NN/imgs/trans.bkp.PNG
-
+968 -02_pytorch/1_NN/linear-regression-gradient-descend.ipynb
-
+100 -02_pytorch/1_NN/logistic-regression/data.txt
-
+743 -02_pytorch/1_NN/logistic-regression/logistic-regression.ipynb
-
+332 -02_pytorch/1_NN/logistic-regression/logistic-regression.py
-
+1133 -02_pytorch/1_NN/nn-sequential-module.ipynb
-
+1955 -02_pytorch/1_NN/nn_intro.ipynb
-
+281 -02_pytorch/1_NN/optimizer/adadelta.ipynb
-
+169 -02_pytorch/1_NN/optimizer/adadelta.py
-
+264 -02_pytorch/1_NN/optimizer/adagrad.ipynb
-
+293 -02_pytorch/1_NN/optimizer/adam.ipynb
-
+182 -02_pytorch/1_NN/optimizer/adam.py
-
+396 -02_pytorch/1_NN/optimizer/momentum.ipynb
-
+231 -02_pytorch/1_NN/optimizer/momentum.py
-
+347 -02_pytorch/1_NN/optimizer/rmsprop.ipynb
-
+198 -02_pytorch/1_NN/optimizer/rmsprop.py
-
+441 -02_pytorch/1_NN/optimizer/sgd.ipynb
-
+222 -02_pytorch/1_NN/optimizer/sgd.py
-
+476 -02_pytorch/1_NN/param_initialize.ipynb
-
+355 -02_pytorch/2_CNN/basic_conv.ipynb
-
+109 -02_pytorch/2_CNN/basic_conv.py
-
+582 -02_pytorch/2_CNN/batch-normalization.ipynb
-
+257 -02_pytorch/2_CNN/batch-normalization.py
-
BIN2_pytorch/2_CNN/cat.png
-
+611 -02_pytorch/2_CNN/data-augumentation.ipynb
-
+204 -02_pytorch/2_CNN/data-augumentation.py
+ 89
- 7
1_knn/knn_classification.ipynb
File diff suppressed because it is too large
View File
+ 49
- 6
1_knn/knn_classification.py
View File
| @@ -18,21 +18,21 @@ | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # KNN Classification | |||
| # # kNN Classification | |||
| # | |||
| # | |||
| # KNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近; | |||
| # kNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近; | |||
| # | |||
| # K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 | |||
| # K最近邻(k-Nearest Neighbor,kNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 | |||
| # | |||
| # KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比(组合函数)。 | |||
| # kNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比(组合函数)。 | |||
| # | |||
| # 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。 | |||
| # | |||
| # K-NN可以说是一种最直接的用来分类未知数据的方法。基本通过下面这张图跟文字说明就可以明白K-NN是干什么的 | |||
| # k-NN可以说是一种最直接的用来分类未知数据的方法。基本通过下面这张图跟文字说明就可以明白K-NN是干什么的 | |||
| #  | |||
| # | |||
| # 简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。 | |||
| # 简单来说,k-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。 | |||
| # | |||
| # | |||
| # 算法步骤: | |||
| @@ -45,6 +45,49 @@ | |||
| # * step.6---统计K-最近邻样本中每个类标号出现的次数 | |||
| # * step.7---选择出现频率最大的类标号作为未知样本的类标号 | |||
| # + | |||
| # %matplotlib inline | |||
| import numpy as np | |||
| import matplotlib.pyplot as plt | |||
| # generate sample data | |||
| n = 100 | |||
| x_1_1 = 10 + (np.random.rand(n, 1)*2 -1)*4 | |||
| x_1_2 = 15 + (np.random.rand(n, 1)*2 -1)*4 | |||
| x1 = np.concatenate((x_1_1, x_1_2), axis=1) | |||
| y1 = np.zeros([n, 1]) | |||
| x_2_1 = 20 + (np.random.rand(n, 1)*2 -1)*4 | |||
| x_2_2 = 5 + (np.random.rand(n, 1)*2 -1)*4 | |||
| x2 = np.concatenate((x_2_1, x_2_2), axis=1) | |||
| y2 = np.ones([n, 1]) | |||
| x = np.concatenate((x1, x2), axis=0) | |||
| y = np.concatenate((y1, y2), axis=0) | |||
| y = y.flatten() | |||
| print(y.shape) | |||
| # draw samle data | |||
| plt.scatter(x[:,0], x[:,1], c=y) | |||
| plt.show() | |||
| # + | |||
| # generate test data | |||
| x_test = np.array([[12.5, 10.0], [15.4, 8.0]]) | |||
| k = 5 | |||
| # do knn | |||
| for s in x_test: | |||
| d = np.sum((s - x)**2, axis=1) | |||
| idx = np.argsort(d) | |||
| ys_5 = list(y[idx[:5]]) | |||
| print(ys_5) | |||
| # TODO: you need to implement the vote algorithm | |||
| # - | |||
| # ## Program | |||
| # + | |||
nn/Perceptron.ipynb → 1_nn/Perceptron.ipynb
View File
nn/Perceptron.py → 1_nn/Perceptron.py
View File
nn/images/L_b.png → 1_nn/images/L_b.png
View File
{kind=link}
nn/images/L_w.png → 1_nn/images/L_w.png
View File
{kind=link}
nn/images/bp_loss.png → 1_nn/images/bp_loss.png
View File
{kind=link}
nn/images/bp_weight_update.png → 1_nn/images/bp_weight_update.png
View File
{kind=link}
nn/images/cross_entropy_loss.png → 1_nn/images/cross_entropy_loss.png
View File
{kind=link}
nn/images/eqn_13_16.png → 1_nn/images/eqn_13_16.png
View File
{kind=link}
nn/images/eqn_17_20.png → 1_nn/images/eqn_17_20.png
View File
{kind=link}
nn/images/eqn_21_22.png → 1_nn/images/eqn_21_22.png
View File
{kind=link}
nn/images/eqn_23_25.png → 1_nn/images/eqn_23_25.png
View File
{kind=link}
nn/images/eqn_26.png → 1_nn/images/eqn_26.png
View File
{kind=link}
nn/images/eqn_27_29.png → 1_nn/images/eqn_27_29.png
View File
{kind=link}
nn/images/eqn_30_31.png → 1_nn/images/eqn_30_31.png
View File
{kind=link}
nn/images/eqn_32_34.png → 1_nn/images/eqn_32_34.png
View File
{kind=link}
nn/images/eqn_35_40.png → 1_nn/images/eqn_35_40.png
View File
{kind=link}
nn/images/eqn_3_4.png → 1_nn/images/eqn_3_4.png
View File
{kind=link}
nn/images/eqn_5_6.png → 1_nn/images/eqn_5_6.png
View File
{kind=link}
nn/images/eqn_7_12.png → 1_nn/images/eqn_7_12.png
View File
{kind=link}
nn/images/eqn_delta_hidden.png → 1_nn/images/eqn_delta_hidden.png
View File
{kind=link}
nn/images/eqn_delta_j.png → 1_nn/images/eqn_delta_j.png
View File
{kind=link}
nn/images/eqn_ed_net_j.png → 1_nn/images/eqn_ed_net_j.png
View File
{kind=link}
nn/images/eqn_hidden_units.png → 1_nn/images/eqn_hidden_units.png
View File
{kind=link}
nn/images/eqn_matrix1.png → 1_nn/images/eqn_matrix1.png
View File
{kind=link}
nn/images/eqn_w41_update.png → 1_nn/images/eqn_w41_update.png
View File
{kind=link}
nn/images/eqn_w4b_update.png → 1_nn/images/eqn_w4b_update.png
View File
{kind=link}
nn/images/eqn_w84_update.png → 1_nn/images/eqn_w84_update.png
View File
{kind=link}
nn/images/formular_2.png → 1_nn/images/formular_2.png
View File
{kind=link}
nn/images/formular_3.png → 1_nn/images/formular_3.png
View File
{kind=link}
nn/images/formular_4.png → 1_nn/images/formular_4.png
View File
{kind=link}
nn/images/formular_5.png → 1_nn/images/formular_5.png
View File
{kind=link}
nn/images/forumlar_delta4.png → 1_nn/images/forumlar_delta4.png
View File
{kind=link}
nn/images/forumlar_delta8.png → 1_nn/images/forumlar_delta8.png
View File
{kind=link}
nn/images/neuron.gif → 1_nn/images/neuron.gif
View File
{kind=link}
nn/images/neuron.png → 1_nn/images/neuron.png
View File
{kind=link}
nn/images/nn1.jpeg → 1_nn/images/nn1.jpeg
View File
{kind=link}
nn/images/nn2.png → 1_nn/images/nn2.png
View File
{kind=link}
nn/images/nn3.png → 1_nn/images/nn3.png
View File
{kind=link}
nn/images/nn_parameters_demo.png → 1_nn/images/nn_parameters_demo.png
View File
{kind=link}
nn/images/perceptron_2.PNG → 1_nn/images/perceptron_2.PNG
View File
{kind=link}
nn/images/perceptron_geometry_def.png → 1_nn/images/perceptron_geometry_def.png
View File
{kind=link}
nn/images/sigmod.jpg → 1_nn/images/sigmod.jpg
View File
{kind=link}
nn/images/sign.png → 1_nn/images/sign.png
View File
{kind=link}
nn/images/softmax.png → 1_nn/images/softmax.png
View File
{kind=link}
nn/images/softmax_demo.png → 1_nn/images/softmax_demo.png
View File
{kind=link}
nn/images/softmax_neuron.png → 1_nn/images/softmax_neuron.png
View File
{kind=link}
nn/images/softmax_neuron_output2_eqn.png → 1_nn/images/softmax_neuron_output2_eqn.png
View File
{kind=link}
nn/images/softmax_neuron_output_eqn.png → 1_nn/images/softmax_neuron_output_eqn.png
View File
{kind=link}
nn/mlp_bp.ipynb → 1_nn/mlp_bp.ipynb
View File
nn/mlp_bp.py → 1_nn/mlp_bp.py
View File
nn/note.txt → 1_nn/note.txt
View File
nn/softmax_ce.ipynb → 1_nn/softmax_ce.ipynb
View File
nn/softmax_ce.py → 1_nn/softmax_ce.py
View File
+ 961
- 0
2_pytorch/0_basic/Tensor-and-Variable.ipynb
File diff suppressed because it is too large
View File
+ 653
- 0
2_pytorch/0_basic/autograd.ipynb
View File
| @@ -0,0 +1,653 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "# 自动求导\n", | |||
| "这次课程我们会了解 PyTorch 中的自动求导机制,自动求导是 PyTorch 中非常重要的特性,能够让我们避免手动去计算非常复杂的导数,这能够极大地减少了我们构建模型的时间,这也是其前身 Torch 这个框架所不具备的特性,下面我们通过例子看看 PyTorch 自动求导的独特魅力以及探究自动求导的更多用法。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import torch\n", | |||
| "from torch.autograd import Variable" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 简单情况的自动求导\n", | |||
| "下面我们显示一些简单情况的自动求导,\"简单\"体现在计算的结果都是标量,也就是一个数,我们对这个标量进行自动求导。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 19\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "x = Variable(torch.Tensor([2]), requires_grad=True)\n", | |||
| "y = x + 2\n", | |||
| "z = y ** 2 + 3\n", | |||
| "print(z)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "通过上面的一些列操作,我们从 x 得到了最后的结果out,我们可以将其表示为数学公式\n", | |||
| "\n", | |||
| "$$\n", | |||
| "z = (x + 2)^2 + 3\n", | |||
| "$$\n", | |||
| "\n", | |||
| "那么我们从 z 对 x 求导的结果就是 \n", | |||
| "\n", | |||
| "$$\n", | |||
| "\\frac{\\partial z}{\\partial x} = 2 (x + 2) = 2 (2 + 2) = 8\n", | |||
| "$$\n", | |||
| "如果你对求导不熟悉,可以查看以下[网址进行复习](https://baike.baidu.com/item/%E5%AF%BC%E6%95%B0#1)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 8\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 使用自动求导\n", | |||
| "z.backward()\n", | |||
| "print(x.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "对于上面这样一个简单的例子,我们验证了自动求导,同时可以发现发现使用自动求导非常方便。如果是一个更加复杂的例子,那么手动求导就会显得非常的麻烦,所以自动求导的机制能够帮助我们省去麻烦的数学计算,下面我们可以看一个更加复杂的例子。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "x = Variable(torch.randn(10, 20), requires_grad=True)\n", | |||
| "y = Variable(torch.randn(10, 5), requires_grad=True)\n", | |||
| "w = Variable(torch.randn(20, 5), requires_grad=True)\n", | |||
| "\n", | |||
| "out = torch.mean(y - torch.matmul(x, w)) # torch.matmul 是做矩阵乘法\n", | |||
| "out.backward()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "如果你对矩阵乘法不熟悉,可以查看下面的[网址进行复习](https://baike.baidu.com/item/%E7%9F%A9%E9%98%B5%E4%B9%98%E6%B3%95/5446029?fr=aladdin)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| "\n", | |||
| "Columns 0 to 9 \n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "-0.0600 -0.0242 -0.0514 0.0882 0.0056 -0.0400 -0.0300 -0.0052 -0.0289 -0.0172\n", | |||
| "\n", | |||
| "Columns 10 to 19 \n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "-0.0372 0.0144 -0.1074 -0.0363 -0.0189 0.0209 0.0618 0.0435 -0.0591 0.0103\n", | |||
| "[torch.FloatTensor of size 10x20]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 得到 x 的梯度\n", | |||
| "print(x.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| "1.00000e-02 *\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| " 2.0000 2.0000 2.0000 2.0000 2.0000\n", | |||
| "[torch.FloatTensor of size 10x5]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 得到 y 的的梯度\n", | |||
| "print(y.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 0.1342 0.1342 0.1342 0.1342 0.1342\n", | |||
| " 0.0507 0.0507 0.0507 0.0507 0.0507\n", | |||
| " 0.0328 0.0328 0.0328 0.0328 0.0328\n", | |||
| "-0.0086 -0.0086 -0.0086 -0.0086 -0.0086\n", | |||
| " 0.0734 0.0734 0.0734 0.0734 0.0734\n", | |||
| "-0.0042 -0.0042 -0.0042 -0.0042 -0.0042\n", | |||
| " 0.0078 0.0078 0.0078 0.0078 0.0078\n", | |||
| "-0.0769 -0.0769 -0.0769 -0.0769 -0.0769\n", | |||
| " 0.0672 0.0672 0.0672 0.0672 0.0672\n", | |||
| " 0.1614 0.1614 0.1614 0.1614 0.1614\n", | |||
| "-0.0042 -0.0042 -0.0042 -0.0042 -0.0042\n", | |||
| "-0.0970 -0.0970 -0.0970 -0.0970 -0.0970\n", | |||
| "-0.0364 -0.0364 -0.0364 -0.0364 -0.0364\n", | |||
| "-0.0419 -0.0419 -0.0419 -0.0419 -0.0419\n", | |||
| " 0.0134 0.0134 0.0134 0.0134 0.0134\n", | |||
| "-0.0251 -0.0251 -0.0251 -0.0251 -0.0251\n", | |||
| " 0.0586 0.0586 0.0586 0.0586 0.0586\n", | |||
| "-0.0050 -0.0050 -0.0050 -0.0050 -0.0050\n", | |||
| " 0.1125 0.1125 0.1125 0.1125 0.1125\n", | |||
| "-0.0096 -0.0096 -0.0096 -0.0096 -0.0096\n", | |||
| "[torch.FloatTensor of size 20x5]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 得到 w 的梯度\n", | |||
| "print(w.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "上面数学公式就更加复杂,矩阵乘法之后对两个矩阵对应元素相乘,然后所有元素求平均,有兴趣的同学可以手动去计算一下梯度,使用 PyTorch 的自动求导,我们能够非常容易得到 x, y 和 w 的导数,因为深度学习中充满大量的矩阵运算,所以我们没有办法手动去求这些导数,有了自动求导能够非常方便地解决网络更新的问题。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 复杂情况的自动求导\n", | |||
| "上面我们展示了简单情况下的自动求导,都是对标量进行自动求导,可能你会有一个疑问,如何对一个向量或者矩阵自动求导了呢?感兴趣的同学可以自己先去尝试一下,下面我们会介绍对多维数组的自动求导机制。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 2 3\n", | |||
| "[torch.FloatTensor of size 1x2]\n", | |||
| "\n", | |||
| "Variable containing:\n", | |||
| " 0 0\n", | |||
| "[torch.FloatTensor of size 1x2]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "m = Variable(torch.FloatTensor([[2, 3]]), requires_grad=True) # 构建一个 1 x 2 的矩阵\n", | |||
| "n = Variable(torch.zeros(1, 2)) # 构建一个相同大小的 0 矩阵\n", | |||
| "print(m)\n", | |||
| "print(n)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 4 27\n", | |||
| "[torch.FloatTensor of size 1x2]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 通过 m 中的值计算新的 n 中的值\n", | |||
| "n[0, 0] = m[0, 0] ** 2\n", | |||
| "n[0, 1] = m[0, 1] ** 3\n", | |||
| "print(n)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "将上面的式子写成数学公式,可以得到 \n", | |||
| "$$\n", | |||
| "n = (n_0,\\ n_1) = (m_0^2,\\ m_1^3) = (2^2,\\ 3^3) \n", | |||
| "$$" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "下面我们直接对 n 进行反向传播,也就是求 n 对 m 的导数。\n", | |||
| "\n", | |||
| "这时我们需要明确这个导数的定义,即如何定义\n", | |||
| "\n", | |||
| "$$\n", | |||
| "\\frac{\\partial n}{\\partial m} = \\frac{\\partial (n_0,\\ n_1)}{\\partial (m_0,\\ m_1)}\n", | |||
| "$$\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "在 PyTorch 中,如果要调用自动求导,需要往`backward()`中传入一个参数,这个参数的形状和 n 一样大,比如是 $(w_0,\\ w_1)$,那么自动求导的结果就是:\n", | |||
| "$$\n", | |||
| "\\frac{\\partial n}{\\partial m_0} = w_0 \\frac{\\partial n_0}{\\partial m_0} + w_1 \\frac{\\partial n_1}{\\partial m_0}\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "\\frac{\\partial n}{\\partial m_1} = w_0 \\frac{\\partial n_0}{\\partial m_1} + w_1 \\frac{\\partial n_1}{\\partial m_1}\n", | |||
| "$$" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 10, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "n.backward(torch.ones_like(n)) # 将 (w0, w1) 取成 (1, 1)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 4 27\n", | |||
| "[torch.FloatTensor of size 1x2]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(m.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "通过自动求导我们得到了梯度是 4 和 27,我们可以验算一下\n", | |||
| "$$\n", | |||
| "\\frac{\\partial n}{\\partial m_0} = w_0 \\frac{\\partial n_0}{\\partial m_0} + w_1 \\frac{\\partial n_1}{\\partial m_0} = 2 m_0 + 0 = 2 \\times 2 = 4\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "\\frac{\\partial n}{\\partial m_1} = w_0 \\frac{\\partial n_0}{\\partial m_1} + w_1 \\frac{\\partial n_1}{\\partial m_1} = 0 + 3 m_1^2 = 3 \\times 3^2 = 27\n", | |||
| "$$\n", | |||
| "通过验算我们可以得到相同的结果" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 多次自动求导\n", | |||
| "通过调用 backward 我们可以进行一次自动求导,如果我们再调用一次 backward,会发现程序报错,没有办法再做一次。这是因为 PyTorch 默认做完一次自动求导之后,计算图就被丢弃了,所以两次自动求导需要手动设置一个东西,我们通过下面的小例子来说明。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 12, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 18\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "x = Variable(torch.FloatTensor([3]), requires_grad=True)\n", | |||
| "y = x * 2 + x ** 2 + 3\n", | |||
| "print(y)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 13, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "y.backward(retain_graph=True) # 设置 retain_graph 为 True 来保留计算图" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 14, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 8\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(x.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 15, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "y.backward() # 再做一次自动求导,这次不保留计算图" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 16, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 16\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(x.grad)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以发现 x 的梯度变成了 16,因为这里做了两次自动求导,所以讲第一次的梯度 8 和第二次的梯度 8 加起来得到了 16 的结果。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "**小练习**\n", | |||
| "\n", | |||
| "定义\n", | |||
| "\n", | |||
| "$$\n", | |||
| "x = \n", | |||
| "\\left[\n", | |||
| "\\begin{matrix}\n", | |||
| "x_0 \\\\\n", | |||
| "x_1\n", | |||
| "\\end{matrix}\n", | |||
| "\\right] = \n", | |||
| "\\left[\n", | |||
| "\\begin{matrix}\n", | |||
| "2 \\\\\n", | |||
| "3\n", | |||
| "\\end{matrix}\n", | |||
| "\\right]\n", | |||
| "$$\n", | |||
| "\n", | |||
| "$$\n", | |||
| "k = (k_0,\\ k_1) = (x_0^2 + 3 x_1,\\ 2 x_0 + x_1^2)\n", | |||
| "$$\n", | |||
| "\n", | |||
| "我们希望求得\n", | |||
| "\n", | |||
| "$$\n", | |||
| "j = \\left[\n", | |||
| "\\begin{matrix}\n", | |||
| "\\frac{\\partial k_0}{\\partial x_0} & \\frac{\\partial k_0}{\\partial x_1} \\\\\n", | |||
| "\\frac{\\partial k_1}{\\partial x_0} & \\frac{\\partial k_1}{\\partial x_1}\n", | |||
| "\\end{matrix}\n", | |||
| "\\right]\n", | |||
| "$$\n", | |||
| "\n", | |||
| "参考答案:\n", | |||
| "\n", | |||
| "$$\n", | |||
| "\\left[\n", | |||
| "\\begin{matrix}\n", | |||
| "4 & 3 \\\\\n", | |||
| "2 & 6 \\\\\n", | |||
| "\\end{matrix}\n", | |||
| "\\right]\n", | |||
| "$$" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "x = Variable(torch.FloatTensor([2, 3]), requires_grad=True)\n", | |||
| "k = Variable(torch.zeros(2))\n", | |||
| "\n", | |||
| "k[0] = x[0] ** 2 + 3 * x[1]\n", | |||
| "k[1] = x[1] ** 2 + 2 * x[0]" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 13\n", | |||
| " 13\n", | |||
| "[torch.FloatTensor of size 2]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(k)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "j = torch.zeros(2, 2)\n", | |||
| "\n", | |||
| "k.backward(torch.FloatTensor([1, 0]), retain_graph=True)\n", | |||
| "j[0] = x.grad.data\n", | |||
| "\n", | |||
| "x.grad.data.zero_() # 归零之前求得的梯度\n", | |||
| "\n", | |||
| "k.backward(torch.FloatTensor([0, 1]))\n", | |||
| "j[1] = x.grad.data" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "\n", | |||
| " 4 3\n", | |||
| " 2 6\n", | |||
| "[torch.FloatTensor of size 2x2]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(j)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "下一次课我们会介绍两种神经网络的编程方式,动态图编程和静态图编程" | |||
| ] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python 3", | |||
| "language": "python", | |||
| "name": "python3" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.6.3" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 2 | |||
| } | |||
+ 205
- 0
2_pytorch/0_basic/dynamic-graph.ipynb
View File
| @@ -0,0 +1,205 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "# 动态图和静态图\n", | |||
| "目前神经网络框架分为静态图框架和动态图框架,PyTorch 和 TensorFlow、Caffe 等框架最大的区别就是他们拥有不同的计算图表现形式。 TensorFlow 使用静态图,这意味着我们先定义计算图,然后不断使用它,而在 PyTorch 中,每次都会重新构建一个新的计算图。通过这次课程,我们会了解静态图和动态图之间的优缺点。\n", | |||
| "\n", | |||
| "对于使用者来说,两种形式的计算图有着非常大的区别,同时静态图和动态图都有他们各自的优点,比如动态图比较方便debug,使用者能够用任何他们喜欢的方式进行debug,同时非常直观,而静态图是通过先定义后运行的方式,之后再次运行的时候就不再需要重新构建计算图,所以速度会比动态图更快。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "下面我们比较 while 循环语句在 TensorFlow 和 PyTorch 中的定义" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## TensorFlow" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# tensorflow\n", | |||
| "import tensorflow as tf\n", | |||
| "\n", | |||
| "first_counter = tf.constant(0)\n", | |||
| "second_counter = tf.constant(10)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def cond(first_counter, second_counter, *args):\n", | |||
| " return first_counter < second_counter\n", | |||
| "\n", | |||
| "def body(first_counter, second_counter):\n", | |||
| " first_counter = tf.add(first_counter, 2)\n", | |||
| " second_counter = tf.add(second_counter, 1)\n", | |||
| " return first_counter, second_counter" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "c1, c2 = tf.while_loop(cond, body, [first_counter, second_counter])" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "with tf.Session() as sess:\n", | |||
| " counter_1_res, counter_2_res = sess.run([c1, c2])" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "20\n", | |||
| "20\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(counter_1_res)\n", | |||
| "print(counter_2_res)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到 TensorFlow 需要将整个图构建成静态的,换句话说,每次运行的时候图都是一样的,是不能够改变的,所以不能直接使用 Python 的 while 循环语句,需要使用辅助函数 `tf.while_loop` 写成 TensorFlow 内部的形式\n", | |||
| "\n", | |||
| "这是非常反直觉的,学习成本也是比较高的\n", | |||
| "\n", | |||
| "下面我们来看看 PyTorch 的动态图机制,这使得我们能够使用 Python 的 while 写循环,非常方便" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## PyTorch" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# pytorch\n", | |||
| "import torch\n", | |||
| "first_counter = torch.Tensor([0])\n", | |||
| "second_counter = torch.Tensor([10])" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "while (first_counter < second_counter)[0]:\n", | |||
| " first_counter += 2\n", | |||
| " second_counter += 1" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 12, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "\n", | |||
| " 20\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n", | |||
| "\n", | |||
| " 20\n", | |||
| "[torch.FloatTensor of size 1]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(first_counter)\n", | |||
| "print(second_counter)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到 PyTorch 的写法跟 Python 的写法是完全一致的,没有任何额外的学习成本\n", | |||
| "\n", | |||
| "上面的例子展示如何使用静态图和动态图构建 while 循环,看起来动态图的方式更加简单且直观,你觉得呢?" | |||
| ] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python 3", | |||
| "language": "python", | |||
| "name": "python3" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.5.2" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 2 | |||
| } | |||
BIN
2_pytorch/0_basic/imgs/autograd_Variable.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 184 | Height: 125 | Size: 4.5 kB |
+ 2
- 0
2_pytorch/0_basic/imgs/autograd_Variable.svg
View File
{kind=link}
| @@ -0,0 +1,2 @@ | |||
| <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"> | |||
| <svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="231px" height="231px" version="1.1" content="<mxfile userAgent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36 OPR/48.0.2685.35" version="7.5.4" editor="www.draw.io"><diagram id="07382e78-ac41-cbda-a75f-370a405a7521" name="第 1 页">1ZZdb5swFIZ/DZebwCYkuWyytruZNCnSdjk52IBVg5kxg+zX7xjMhwtVWy2RttzEfo99fPw+NuDhY94+KlJmXyRlwkM+bT38yUMoCPwt/Bnl0is7tO+FVHFqB03Cif9mVvStWnPKKmegllJoXrpiLIuCxdrRiFKycYclUrirliRlC+EUE7FUv3Oqs2EX20n/zHiaDSsHkd3fmcRPqZJ1YdfzEE66Xx/OyZDLbrTKCJXNTML3Hj4qKXXfytsjE8bbwbZ+3sML0bFuxQr9lgmon/CLiJoNFXd16cvgRZNxzU4liU2/Ad4ePmQ6F9ALoEmqsieQ8JZB1kPChThKIVU33WwfxTHolVbyic0iNDpHmwgilFSZmdrlswUxpVn74qaC0So4gkzmTKsLDLETUGTdtacP7Wy/mViORy2bcRxFYs9POuaePISGtXHdUrxiaSS0cUZC/XNvo5+1HAIfqu4W3MGAYFe2UxBaqe5c0mTIBDX0yfrQgll3AkdLXyHo2G86X4nWTBWdgvzwSlD2GwcKjpZQos2SSXgFJOGNkKSK0P8YCd75ryLZrlyTayDZ3BDJj6R4PxX/n6GCXCohWlLZ3+iiRH9NBYVrVEitpSHz8RtRnJwhxRv5gI3aheC+RgpZsGfvHCsRwVNDJgbbGegHA4XDK/7OBnJOqVlmlbqD2lRov1GQf6Wn4fbZ1fOXkIP9yt3D76cM3emDoovNvtrw/R8=</diagram></mxfile>"><defs/><g transform="translate(0.5,0.5)"><rect x="10" y="10" width="210" height="210" fill="#fff2cc" stroke="#d6b656" stroke-dasharray="3 3" pointer-events="none"/><rect x="45" y="90" width="65" height="40" rx="6" ry="6" fill="#ffffff" stroke="#000000" stroke-dasharray="1 4" pointer-events="none"/><g transform="translate(59.5,100.5)"><switch><foreignObject style="overflow:visible;" pointer-events="all" width="35" height="19" requiredFeatures="http://www.w3.org/TR/SVG11/feature#Extensibility"><div xmlns="http://www.w3.org/1999/xhtml" style="display: inline-block; font-size: 12px; font-family: Helvetica; color: rgb(0, 0, 0); line-height: 1.2; vertical-align: top; width: 37px; white-space: nowrap; word-wrap: normal; text-align: center;"><div xmlns="http://www.w3.org/1999/xhtml" style="display:inline-block;text-align:inherit;text-decoration:inherit;"><font style="font-size: 18px">data</font></div></div></foreignObject><text x="18" y="16" fill="#000000" text-anchor="middle" font-size="12px" font-family="Helvetica">[Not supported by viewer]</text></switch></g><rect x="130" y="90" width="70" height="40" rx="6" ry="6" fill="#ffffff" stroke="#000000" stroke-dasharray="1 4" pointer-events="none"/><g transform="translate(146.5,100.5)"><switch><foreignObject style="overflow:visible;" pointer-events="all" width="36" height="19" requiredFeatures="http://www.w3.org/TR/SVG11/feature#Extensibility"><div xmlns="http://www.w3.org/1999/xhtml" style="display: inline-block; font-size: 12px; font-family: Helvetica; color: rgb(0, 0, 0); line-height: 1.2; vertical-align: top; width: 38px; white-space: nowrap; word-wrap: normal; text-align: center;"><div xmlns="http://www.w3.org/1999/xhtml" style="display:inline-block;text-align:inherit;text-decoration:inherit;"><font style="font-size: 18px">grad</font></div></div></foreignObject><text x="18" y="16" fill="#000000" text-anchor="middle" font-size="12px" font-family="Helvetica">[Not supported by viewer]</text></switch></g><rect x="70" y="150" width="95" height="40" fill="#ffffff" stroke="#000000" stroke-dasharray="1 4" pointer-events="none"/><g transform="translate(86.5,160.5)"><switch><foreignObject style="overflow:visible;" pointer-events="all" width="61" height="19" requiredFeatures="http://www.w3.org/TR/SVG11/feature#Extensibility"><div xmlns="http://www.w3.org/1999/xhtml" style="display: inline-block; font-size: 12px; font-family: Helvetica; color: rgb(0, 0, 0); line-height: 1.2; vertical-align: top; width: 63px; white-space: nowrap; word-wrap: normal; text-align: center;"><div xmlns="http://www.w3.org/1999/xhtml" style="display:inline-block;text-align:inherit;text-decoration:inherit;"><font style="font-size: 18px">grad_fn</font></div></div></foreignObject><text x="31" y="16" fill="#000000" text-anchor="middle" font-size="12px" font-family="Helvetica">[Not supported by viewer]</text></switch></g><g transform="translate(21.5,31.5)"><switch><foreignObject style="overflow:visible;" pointer-events="all" width="187" height="26" requiredFeatures="http://www.w3.org/TR/SVG11/feature#Extensibility"><div xmlns="http://www.w3.org/1999/xhtml" style="display: inline-block; font-size: 20px; font-family: Helvetica; color: rgb(0, 0, 0); line-height: 1.2; vertical-align: top; width: 189px; white-space: nowrap; word-wrap: normal; text-align: center;"><div xmlns="http://www.w3.org/1999/xhtml" style="display:inline-block;text-align:inherit;text-decoration:inherit;"><font style="font-size: 24px">autograd.Variable</font></div></div></foreignObject><text x="94" y="23" fill="#000000" text-anchor="middle" font-size="20px" font-family="Helvetica">[Not supported by viewer]</text></switch></g></g></svg> | |||
+ 2
- 0
2_pytorch/0_basic/imgs/com_graph.svg
File diff suppressed because it is too large
View File
{kind=link}
+ 2
- 0
2_pytorch/0_basic/imgs/com_graph_backward.svg
File diff suppressed because it is too large
View File
{kind=link}
+ 2
- 0
2_pytorch/0_basic/imgs/tensor_data_structure.svg
File diff suppressed because it is too large
View File
{kind=link}
+ 1554
- 0
2_pytorch/0_basic/ref_Autograd.ipynb
File diff suppressed because it is too large
View File
+ 3043
- 0
2_pytorch/0_basic/ref_Tensor.ipynb
File diff suppressed because it is too large
View File
+ 128
- 0
2_pytorch/1_NN/bp.ipynb
View File
| @@ -0,0 +1,128 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "# 反向传播算法\n", | |||
| "\n", | |||
| "前面我们介绍了三个模型,整个处理的基本流程都是定义模型,读入数据,给出损失函数$f$,通过梯度下降法更新参数。PyTorch 提供了非常简单的自动求导帮助我们求解导数,对于比较简单的模型,我们也能手动求出参数的梯度,但是对于非常复杂的模型,比如一个 100 层的网络,我们如何能够有效地手动求出这个梯度呢?这里就需要引入反向传播算法,自动求导本质是就是一个反向传播算法。\n", | |||
| "\n", | |||
| "反向传播算法是一个有效地求解梯度的算法,本质上其实就是一个链式求导法则的应用,然而这个如此简单而且显而易见的方法却是在 Roseblatt 提出感知机算法后将近 30 年才被发明和普及的,对此 Bengio 这样说道:“很多看似显而易见的想法只有在事后才变得的显而易见。”\n", | |||
| "\n", | |||
| "下面我们就来详细将一讲什么是反向传播算法。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 链式法则\n", | |||
| "\n", | |||
| "首先来简单地介绍一下链式法则,考虑一个简单的函数,比如\n", | |||
| "$$f(x, y, z) = (x + y)z$$\n", | |||
| "\n", | |||
| "我们当然可以直接求出这个函数的微分,但是这里我们要使用链式法则,令\n", | |||
| "$$q=x+y$$\n", | |||
| "\n", | |||
| "那么\n", | |||
| "\n", | |||
| "$$f = qz$$\n", | |||
| "\n", | |||
| "对于这两个式子,我们可以分别求出他们的微分 \n", | |||
| "\n", | |||
| "$$\\frac{\\partial f}{\\partial q} = z, \\frac{\\partial f}{\\partial z}=q$$\n", | |||
| "\n", | |||
| "同时$q$是$x$和$y$的求和,所以我们能够得到\n", | |||
| "\n", | |||
| "$$\\frac{\\partial q}{x} = 1, \\frac{\\partial q}{y} = 1$$\n", | |||
| "\n", | |||
| "我们关心的问题是\n", | |||
| "\n", | |||
| "$$\\frac{\\partial f}{\\partial x}, \\frac{\\partial f}{\\partial y}, \\frac{\\partial f}{\\partial z}$$\n", | |||
| "\n", | |||
| "链式法则告诉我们如何来计算出他们的值\n", | |||
| "\n", | |||
| "$$\n", | |||
| "\\frac{\\partial f}{\\partial x} = \\frac{\\partial f}{\\partial q}\\frac{\\partial q}{\\partial x}\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "\\frac{\\partial f}{\\partial y} = \\frac{\\partial f}{\\partial q}\\frac{\\partial q}{\\partial y}\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "\\frac{\\partial f}{\\partial z} = q\n", | |||
| "$$\n", | |||
| "\n", | |||
| "通过链式法则我们知道如果我们需要对其中的元素求导,那么我们可以一层一层求导然后将结果乘起来,这就是链式法则的核心,也是反向传播算法的核心,更多关于链式法则的算法,可以访问这个[文档](https://zh.wikipedia.org/wiki/%E9%93%BE%E5%BC%8F%E6%B3%95%E5%88%99)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 反向传播算法\n", | |||
| "\n", | |||
| "了解了链式法则,我们就可以开始介绍反向传播算法了,本质上反向传播算法只是链式法则的一个应用。我们还是使用之前那个相同的例子$q=x+y, f=qz$,通过计算图可以将这个计算过程表达出来\n", | |||
| "\n", | |||
| "\n", | |||
| "\n", | |||
| "上面绿色的数字表示其数值,下面红色的数字表示求出的梯度,我们可以一步一步看看反向传播算法的实现。首先从最后开始,梯度当然是1,然后计算\n", | |||
| "\n", | |||
| "$$\\frac{\\partial f}{\\partial q} = z = -4,\\ \\frac{\\partial f}{\\partial z} = q = 3$$\n", | |||
| "\n", | |||
| "接着我们计算\n", | |||
| "$$\\frac{\\partial f}{\\partial x} = \\frac{\\partial f}{\\partial q} \\frac{\\partial q}{\\partial x} = -4 \\times 1 = -4,\\ \\frac{\\partial f}{\\partial y} = \\frac{\\partial f}{\\partial q} \\frac{\\partial q}{\\partial y} = -4 \\times 1 = -4$$\n", | |||
| "\n", | |||
| "这样一步一步我们就求出了$\\nabla f(x, y, z)$。\n", | |||
| "\n", | |||
| "直观上看反向传播算法是一个优雅的局部过程,每次求导只是对当前的运算求导,求解每层网络的参数都是通过链式法则将前面的结果求出不断迭代到这一层,所以说这是一个传播过程\n", | |||
| "\n", | |||
| "### Sigmoid函数举例\n", | |||
| "\n", | |||
| "下面我们通过Sigmoid函数来演示反向传播过程在一个复杂的函数上是如何进行的。\n", | |||
| "\n", | |||
| "$$\n", | |||
| "f(w, x) = \\frac{1}{1+e^{-(w_0 x_0 + w_1 x_1 + w_2)}}\n", | |||
| "$$\n", | |||
| "\n", | |||
| "我们需要求解出\n", | |||
| "$$\\frac{\\partial f}{\\partial w_0}, \\frac{\\partial f}{\\partial w_1}, \\frac{\\partial f}{\\partial w_2}$$\n", | |||
| "\n", | |||
| "首先我们将这个函数抽象成一个计算图来表示,即\n", | |||
| "$$\n", | |||
| " f(x) = \\frac{1}{x} \\\\\n", | |||
| " f_c(x) = 1 + x \\\\\n", | |||
| " f_e(x) = e^x \\\\\n", | |||
| " f_w(x) = -(w_0 x_0 + w_1 x_1 + w_2)\n", | |||
| "$$\n", | |||
| "\n", | |||
| "这样我们就能够画出下面的计算图\n", | |||
| "\n", | |||
| "\n", | |||
| "\n", | |||
| "同样上面绿色的数子表示数值,下面红色的数字表示梯度,我们从后往前计算一下各个参数的梯度。首先最后面的梯度是1,,然后经过$\\frac{1}{x}$这个函数,这个函数的梯度是$-\\frac{1}{x^2}$,所以往前传播的梯度是$1 \\times -\\frac{1}{1.37^2} = -0.53$,然后是$+1$这个操作,梯度不变,接着是$e^x$这个运算,它的梯度就是$-0.53 \\times e^{-1} = -0.2$,这样不断往后传播就能够求得每个参数的梯度。" | |||
| ] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python 3", | |||
| "language": "python", | |||
| "name": "python3" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.5.2" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 2 | |||
| } | |||
+ 703
- 0
2_pytorch/1_NN/deep-nn.ipynb
File diff suppressed because it is too large
View File
BIN
2_pytorch/1_NN/imgs/ResNet.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 616 | Height: 1295 | Size: 104 kB |
BIN
2_pytorch/1_NN/imgs/lena.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 200 | Height: 200 | Size: 23 kB |
BIN
2_pytorch/1_NN/imgs/lena3.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 512 | Height: 512 | Size: 151 kB |
BIN
2_pytorch/1_NN/imgs/lena512.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 512 | Height: 512 | Size: 151 kB |
BIN
2_pytorch/1_NN/imgs/multi_perceptron.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 396 | Height: 211 | Size: 7.2 kB |
BIN
2_pytorch/1_NN/imgs/residual.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 317 | Height: 615 | Size: 82 kB |
BIN
2_pytorch/1_NN/imgs/resnet1.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1354 | Height: 269 | Size: 69 kB |
BIN
2_pytorch/1_NN/imgs/trans.bkp.PNG
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 510 | Height: 185 | Size: 7.8 kB |
+ 968
- 0
2_pytorch/1_NN/linear-regression-gradient-descend.ipynb
File diff suppressed because it is too large
View File
+ 100
- 0
2_pytorch/1_NN/logistic-regression/data.txt
View File
| @@ -0,0 +1,100 @@ | |||
| 34.62365962451697,78.0246928153624,0 | |||
| 30.28671076822607,43.89499752400101,0 | |||
| 35.84740876993872,72.90219802708364,0 | |||
| 60.18259938620976,86.30855209546826,1 | |||
| 79.0327360507101,75.3443764369103,1 | |||
| 45.08327747668339,56.3163717815305,0 | |||
| 61.10666453684766,96.51142588489624,1 | |||
| 75.02474556738889,46.55401354116538,1 | |||
| 76.09878670226257,87.42056971926803,1 | |||
| 84.43281996120035,43.53339331072109,1 | |||
| 95.86155507093572,38.22527805795094,0 | |||
| 75.01365838958247,30.60326323428011,0 | |||
| 82.30705337399482,76.48196330235604,1 | |||
| 69.36458875970939,97.71869196188608,1 | |||
| 39.53833914367223,76.03681085115882,0 | |||
| 53.9710521485623,89.20735013750205,1 | |||
| 69.07014406283025,52.74046973016765,1 | |||
| 67.94685547711617,46.67857410673128,0 | |||
| 70.66150955499435,92.92713789364831,1 | |||
| 76.97878372747498,47.57596364975532,1 | |||
| 67.37202754570876,42.83843832029179,0 | |||
| 89.67677575072079,65.79936592745237,1 | |||
| 50.534788289883,48.85581152764205,0 | |||
| 34.21206097786789,44.20952859866288,0 | |||
| 77.9240914545704,68.9723599933059,1 | |||
| 62.27101367004632,69.95445795447587,1 | |||
| 80.1901807509566,44.82162893218353,1 | |||
| 93.114388797442,38.80067033713209,0 | |||
| 61.83020602312595,50.25610789244621,0 | |||
| 38.78580379679423,64.99568095539578,0 | |||
| 61.379289447425,72.80788731317097,1 | |||
| 85.40451939411645,57.05198397627122,1 | |||
| 52.10797973193984,63.12762376881715,0 | |||
| 52.04540476831827,69.43286012045222,1 | |||
| 40.23689373545111,71.16774802184875,0 | |||
| 54.63510555424817,52.21388588061123,0 | |||
| 33.91550010906887,98.86943574220611,0 | |||
| 64.17698887494485,80.90806058670817,1 | |||
| 74.78925295941542,41.57341522824434,0 | |||
| 34.1836400264419,75.2377203360134,0 | |||
| 83.90239366249155,56.30804621605327,1 | |||
| 51.54772026906181,46.85629026349976,0 | |||
| 94.44336776917852,65.56892160559052,1 | |||
| 82.36875375713919,40.61825515970618,0 | |||
| 51.04775177128865,45.82270145776001,0 | |||
| 62.22267576120188,52.06099194836679,0 | |||
| 77.19303492601364,70.45820000180959,1 | |||
| 97.77159928000232,86.7278223300282,1 | |||
| 62.07306379667647,96.76882412413983,1 | |||
| 91.56497449807442,88.69629254546599,1 | |||
| 79.94481794066932,74.16311935043758,1 | |||
| 99.2725269292572,60.99903099844988,1 | |||
| 90.54671411399852,43.39060180650027,1 | |||
| 34.52451385320009,60.39634245837173,0 | |||
| 50.2864961189907,49.80453881323059,0 | |||
| 49.58667721632031,59.80895099453265,0 | |||
| 97.64563396007767,68.86157272420604,1 | |||
| 32.57720016809309,95.59854761387875,0 | |||
| 74.24869136721598,69.82457122657193,1 | |||
| 71.79646205863379,78.45356224515052,1 | |||
| 75.3956114656803,85.75993667331619,1 | |||
| 35.28611281526193,47.02051394723416,0 | |||
| 56.25381749711624,39.26147251058019,0 | |||
| 30.05882244669796,49.59297386723685,0 | |||
| 44.66826172480893,66.45008614558913,0 | |||
| 66.56089447242954,41.09209807936973,0 | |||
| 40.45755098375164,97.53518548909936,1 | |||
| 49.07256321908844,51.88321182073966,0 | |||
| 80.27957401466998,92.11606081344084,1 | |||
| 66.74671856944039,60.99139402740988,1 | |||
| 32.72283304060323,43.30717306430063,0 | |||
| 64.0393204150601,78.03168802018232,1 | |||
| 72.34649422579923,96.22759296761404,1 | |||
| 60.45788573918959,73.09499809758037,1 | |||
| 58.84095621726802,75.85844831279042,1 | |||
| 99.82785779692128,72.36925193383885,1 | |||
| 47.26426910848174,88.47586499559782,1 | |||
| 50.45815980285988,75.80985952982456,1 | |||
| 60.45555629271532,42.50840943572217,0 | |||
| 82.22666157785568,42.71987853716458,0 | |||
| 88.9138964166533,69.80378889835472,1 | |||
| 94.83450672430196,45.69430680250754,1 | |||
| 67.31925746917527,66.58935317747915,1 | |||
| 57.23870631569862,59.51428198012956,1 | |||
| 80.36675600171273,90.96014789746954,1 | |||
| 68.46852178591112,85.59430710452014,1 | |||
| 42.0754545384731,78.84478600148043,0 | |||
| 75.47770200533905,90.42453899753964,1 | |||
| 78.63542434898018,96.64742716885644,1 | |||
| 52.34800398794107,60.76950525602592,0 | |||
| 94.09433112516793,77.15910509073893,1 | |||
| 90.44855097096364,87.50879176484702,1 | |||
| 55.48216114069585,35.57070347228866,0 | |||
| 74.49269241843041,84.84513684930135,1 | |||
| 89.84580670720979,45.35828361091658,1 | |||
| 83.48916274498238,48.38028579728175,1 | |||
| 42.2617008099817,87.10385094025457,1 | |||
| 99.31500880510394,68.77540947206617,1 | |||
| 55.34001756003703,64.9319380069486,1 | |||
| 74.77589300092767,89.52981289513276,1 | |||
+ 743
- 0
2_pytorch/1_NN/logistic-regression/logistic-regression.ipynb
File diff suppressed because it is too large
View File
+ 332
- 0
2_pytorch/1_NN/logistic-regression/logistic-regression.py
View File
| @@ -0,0 +1,332 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # Logistic 回归模型 | |||
| # 上一节课我们学习了简单的线性回归模型,这一次课中,我们会学习第二个模型,Logistic 回归模型。 | |||
| # | |||
| # Logistic 回归是一种广义的回归模型,其与多元线性回归有着很多相似之处,模型的形式基本相同,虽然也被称为回归,但是其更多的情况使用在分类问题上,同时又以二分类更为常用。 | |||
| # ## 模型形式 | |||
| # Logistic 回归的模型形式和线性回归一样,都是 y = wx + b,其中 x 可以是一个多维的特征,唯一不同的地方在于 Logistic 回归会对 y 作用一个 logistic 函数,将其变为一种概率的结果。 Logistic 函数作为 Logistic 回归的核心,我们下面讲一讲 Logistic 函数,也被称为 Sigmoid 函数。 | |||
| # ### Sigmoid 函数 | |||
| # Sigmoid 函数非常简单,其公式如下 | |||
| # | |||
| # $$ | |||
| # f(x) = \frac{1}{1 + e^{-x}} | |||
| # $$ | |||
| # | |||
| # Sigmoid 函数的图像如下 | |||
| # | |||
| #  | |||
| # | |||
| # 可以看到 Sigmoid 函数的范围是在 0 ~ 1 之间,所以任何一个值经过了 Sigmoid 函数的作用,都会变成 0 ~ 1 之间的一个值,这个值可以形象地理解为一个概率,比如对于二分类问题,这个值越小就表示属于第一类,这个值越大就表示属于第二类。 | |||
| # 另外一个 Logistic 回归的前提是确保你的数据具有非常良好的线性可分性,也就是说,你的数据集能够在一定的维度上被分为两个部分,比如 | |||
| # | |||
| #  | |||
| # 可以看到,上面红色的点和蓝色的点能够几乎被一个绿色的平面分割开来 | |||
| # ## 回归问题 vs 分类问题 | |||
| # Logistic 回归处理的是一个分类问题,而上一个模型是回归模型,那么回归问题和分类问题的区别在哪里呢? | |||
| # | |||
| # 从上面的图可以看出,分类问题希望把数据集分到某一类,比如一个 3 分类问题,那么对于任何一个数据点,我们都希望找到其到底属于哪一类,最终的结果只有三种情况,{0, 1, 2},所以这是一个离散的问题。 | |||
| # | |||
| # 而回归问题是一个连续的问题,比如曲线的拟合,我们可以拟合任意的函数结果,这个结果是一个连续的值。 | |||
| # | |||
| # 分类问题和回归问题是机器学习和深度学习的第一步,拿到任何一个问题,我们都需要先确定其到底是分类还是回归,然后再进行算法设计 | |||
| # ## 损失函数 | |||
| # 前一节对于回归问题,我们有一个 loss 去衡量误差,那么对于分类问题,我们如何去衡量这个误差,并设计 loss 函数呢? | |||
| # | |||
| # Logistic 回归使用了 Sigmoid 函数将结果变到 0 ~ 1 之间,对于任意输入一个数据,经过 Sigmoid 之后的结果我们记为 $\hat{y}$,表示这个数据点属于第二类的概率,那么其属于第一类的概率就是 $1-\hat{y}$。如果这个数据点属于第二类,我们希望 $\hat{y}$ 越大越好,也就是越靠近 1 越好,如果这个数据属于第一类,那么我们希望 $1-\hat{y}$ 越大越好,也就是 $\hat{y}$ 越小越好,越靠近 0 越好,所以我们可以这样设计我们的 loss 函数 | |||
| # | |||
| # $$ | |||
| # loss = -(y * log(\hat{y}) + (1 - y) * log(1 - \hat{y})) | |||
| # $$ | |||
| # | |||
| # 其中 y 表示真实的 label,只能取 {0, 1} 这两个值,因为 $\hat{y}$ 表示经过 Logistic 回归预测之后的结果,是一个 0 ~ 1 之间的小数。如果 y 是 0,表示该数据属于第一类,我们希望 $\hat{y}$ 越小越好,上面的 loss 函数变为 | |||
| # | |||
| # $$ | |||
| # loss = - (log(1 - \hat{y})) | |||
| # $$ | |||
| # | |||
| # 在训练模型的时候我们希望最小化 loss 函数,根据 log 函数的单调性,也就是最小化 $\hat{y}$,与我们的要求是一致的。 | |||
| # | |||
| # 而如果 y 是 1,表示该数据属于第二类,我们希望 $\hat{y}$ 越大越好,同时上面的 loss 函数变为 | |||
| # | |||
| # $$ | |||
| # loss = -(log(\hat{y})) | |||
| # $$ | |||
| # | |||
| # 我们希望最小化 loss 函数也就是最大化 $\hat{y}$,这也与我们的要求一致。 | |||
| # | |||
| # 所以通过上面的论述,说明了这么构建 loss 函数是合理的。 | |||
| # 下面我们通过例子来具体学习 Logistic 回归 | |||
| import torch | |||
| from torch.autograd import Variable | |||
| import numpy as np | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| # 设定随机种子 | |||
| torch.manual_seed(2017) | |||
| # 我们从 data.txt 读入数据,感兴趣的同学可以打开 data.txt 文件进行查看 | |||
| # | |||
| # 读入数据点之后我们根据不同的 label 将数据点分为了红色和蓝色,并且画图展示出来了 | |||
| # + | |||
| # 从 data.txt 中读入点 | |||
| with open('./data.txt', 'r') as f: | |||
| data_list = [i.split('\n')[0].split(',') for i in f.readlines()] | |||
| data = [(float(i[0]), float(i[1]), float(i[2])) for i in data_list] | |||
| # 标准化 | |||
| x0_max = max([i[0] for i in data]) | |||
| x1_max = max([i[1] for i in data]) | |||
| data = [(i[0]/x0_max, i[1]/x1_max, i[2]) for i in data] | |||
| x0 = list(filter(lambda x: x[-1] == 0.0, data)) # 选择第一类的点 | |||
| x1 = list(filter(lambda x: x[-1] == 1.0, data)) # 选择第二类的点 | |||
| plot_x0 = [i[0] for i in x0] | |||
| plot_y0 = [i[1] for i in x0] | |||
| plot_x1 = [i[0] for i in x1] | |||
| plot_y1 = [i[1] for i in x1] | |||
| plt.plot(plot_x0, plot_y0, 'ro', label='x_0') | |||
| plt.plot(plot_x1, plot_y1, 'bo', label='x_1') | |||
| plt.legend(loc='best') | |||
| # - | |||
| # 接下来我们将数据转换成 NumPy 的类型,接着转换到 Tensor 为之后的训练做准备 | |||
| np_data = np.array(data, dtype='float32') # 转换成 numpy array | |||
| x_data = torch.from_numpy(np_data[:, 0:2]) # 转换成 Tensor, 大小是 [100, 2] | |||
| y_data = torch.from_numpy(np_data[:, -1]).unsqueeze(1) # 转换成 Tensor,大小是 [100, 1] | |||
| # 下面我们来实现以下 Sigmoid 的函数,Sigmoid 函数的公式为 | |||
| # | |||
| # $$ | |||
| # f(x) = \frac{1}{1 + e^{-x}} | |||
| # $$ | |||
| # 定义 sigmoid 函数 | |||
| def sigmoid(x): | |||
| return 1 / (1 + np.exp(-x)) | |||
| # 画出 Sigmoid 函数,可以看到值越大,经过 Sigmoid 函数之后越靠近 1,值越小,越靠近 0 | |||
| # + | |||
| # 画出 sigmoid 的图像 | |||
| plot_x = np.arange(-10, 10.01, 0.01) | |||
| plot_y = sigmoid(plot_x) | |||
| plt.plot(plot_x, plot_y, 'r') | |||
| # - | |||
| x_data = Variable(x_data) | |||
| y_data = Variable(y_data) | |||
| # 在 PyTorch 当中,不需要我们自己写 Sigmoid 的函数,PyTorch 已经用底层的 C++ 语言为我们写好了一些常用的函数,不仅方便我们使用,同时速度上比我们自己实现的更快,稳定性更好 | |||
| # | |||
| # 通过导入 `torch.nn.functional` 来使用,下面就是使用方法 | |||
| import torch.nn.functional as F | |||
| # + | |||
| # 定义 logistic 回归模型 | |||
| w = Variable(torch.randn(2, 1), requires_grad=True) | |||
| b = Variable(torch.zeros(1), requires_grad=True) | |||
| def logistic_regression(x): | |||
| return F.sigmoid(torch.mm(x, w) + b) | |||
| # - | |||
| # 在更新之前,我们可以画出分类的效果 | |||
| # + | |||
| # 画出参数更新之前的结果 | |||
| w0 = w[0].data[0] | |||
| w1 = w[1].data[0] | |||
| b0 = b.data[0] | |||
| plot_x = np.arange(0.2, 1, 0.01) | |||
| plot_y = (-w0 * plot_x - b0) / w1 | |||
| plt.plot(plot_x, plot_y, 'g', label='cutting line') | |||
| plt.plot(plot_x0, plot_y0, 'ro', label='x_0') | |||
| plt.plot(plot_x1, plot_y1, 'bo', label='x_1') | |||
| plt.legend(loc='best') | |||
| # - | |||
| # 可以看到分类效果基本是混乱的,我们来计算一下 loss,公式如下 | |||
| # | |||
| # $$ | |||
| # loss = -(y * log(\hat{y}) + (1 - y) * log(1 - \hat{y})) | |||
| # $$ | |||
| # 计算loss | |||
| def binary_loss(y_pred, y): | |||
| logits = (y * y_pred.clamp(1e-12).log() + (1 - y) * (1 - y_pred).clamp(1e-12).log()).mean() | |||
| return -logits | |||
| # 注意到其中使用 `.clamp`,这是[文档](http://pytorch.org/docs/0.3.0/torch.html?highlight=clamp#torch.clamp)的内容,查看一下,并且思考一下这里是否一定要使用这个函数,如果不使用会出现什么样的结果 | |||
| # | |||
| # **提示:查看一个 log 函数的图像** | |||
| y_pred = logistic_regression(x_data) | |||
| loss = binary_loss(y_pred, y_data) | |||
| print(loss) | |||
| # 得到 loss 之后,我们还是使用梯度下降法更新参数,这里可以使用自动求导来直接得到参数的导数,感兴趣的同学可以去手动推导一下导数的公式 | |||
| # + | |||
| # 自动求导并更新参数 | |||
| loss.backward() | |||
| w.data = w.data - 0.1 * w.grad.data | |||
| b.data = b.data - 0.1 * b.grad.data | |||
| # 算出一次更新之后的loss | |||
| y_pred = logistic_regression(x_data) | |||
| loss = binary_loss(y_pred, y_data) | |||
| print(loss) | |||
| # - | |||
| # 上面的参数更新方式其实是繁琐的重复操作,如果我们的参数很多,比如有 100 个,那么我们需要写 100 行来更新参数,为了方便,我们可以写成一个函数来更新,其实 PyTorch 已经为我们封装了一个函数来做这件事,这就是 PyTorch 中的优化器 `torch.optim` | |||
| # | |||
| # 使用 `torch.optim` 需要另外一个数据类型,就是 `nn.Parameter`,这个本质上和 Variable 是一样的,只不过 `nn.Parameter` 默认是要求梯度的,而 Variable 默认是不求梯度的 | |||
| # | |||
| # 使用 `torch.optim.SGD` 可以使用梯度下降法来更新参数,PyTorch 中的优化器有更多的优化算法,在本章后面的课程我们会更加详细的介绍 | |||
| # | |||
| # 将参数 w 和 b 放到 `torch.optim.SGD` 中之后,说明一下学习率的大小,就可以使用 `optimizer.step()` 来更新参数了,比如下面我们将参数传入优化器,学习率设置为 1.0 | |||
| # + | |||
| # 使用 torch.optim 更新参数 | |||
| from torch import nn | |||
| w = nn.Parameter(torch.randn(2, 1)) | |||
| b = nn.Parameter(torch.zeros(1)) | |||
| def logistic_regression(x): | |||
| return F.sigmoid(torch.mm(x, w) + b) | |||
| optimizer = torch.optim.SGD([w, b], lr=1.) | |||
| # + | |||
| # 进行 1000 次更新 | |||
| import time | |||
| start = time.time() | |||
| for e in range(1000): | |||
| # 前向传播 | |||
| y_pred = logistic_regression(x_data) | |||
| loss = binary_loss(y_pred, y_data) # 计算 loss | |||
| # 反向传播 | |||
| optimizer.zero_grad() # 使用优化器将梯度归 0 | |||
| loss.backward() | |||
| optimizer.step() # 使用优化器来更新参数 | |||
| # 计算正确率 | |||
| mask = y_pred.ge(0.5).float() | |||
| acc = (mask == y_data).sum().data[0] / y_data.shape[0] | |||
| if (e + 1) % 200 == 0: | |||
| print('epoch: {}, Loss: {:.5f}, Acc: {:.5f}'.format(e+1, loss.data[0], acc)) | |||
| during = time.time() - start | |||
| print() | |||
| print('During Time: {:.3f} s'.format(during)) | |||
| # - | |||
| # 可以看到使用优化器之后更新参数非常简单,只需要在自动求导之前使用**`optimizer.zero_grad()`** 来归 0 梯度,然后使用 **`optimizer.step()`**来更新参数就可以了,非常简便 | |||
| # | |||
| # 同时经过了 1000 次更新,loss 也降得比较低了 | |||
| # 下面我们画出更新之后的结果 | |||
| # + | |||
| # 画出更新之后的结果 | |||
| w0 = w[0].data[0] | |||
| w1 = w[1].data[0] | |||
| b0 = b.data[0] | |||
| plot_x = np.arange(0.2, 1, 0.01) | |||
| plot_y = (-w0 * plot_x - b0) / w1 | |||
| plt.plot(plot_x, plot_y, 'g', label='cutting line') | |||
| plt.plot(plot_x0, plot_y0, 'ro', label='x_0') | |||
| plt.plot(plot_x1, plot_y1, 'bo', label='x_1') | |||
| plt.legend(loc='best') | |||
| # - | |||
| # 可以看到更新之后模型已经能够基本将这两类点分开了 | |||
| # 前面我们使用了自己写的 loss,其实 PyTorch 已经为我们写好了一些常见的 loss,比如线性回归里面的 loss 是 `nn.MSE()`,而 Logistic 回归的二分类 loss 在 PyTorch 中是 `nn.BCEWithLogitsLoss()`,关于更多的 loss,可以查看[文档](http://pytorch.org/docs/0.3.0/nn.html#loss-functions) | |||
| # | |||
| # PyTorch 为我们实现的 loss 函数有两个好处,第一是方便我们使用,不需要重复造轮子,第二就是其实现是在底层 C++ 语言上的,所以速度上和稳定性上都要比我们自己实现的要好 | |||
| # | |||
| # 另外,PyTorch 出于稳定性考虑,将模型的 Sigmoid 操作和最后的 loss 都合在了 `nn.BCEWithLogitsLoss()`,所以我们使用 PyTorch 自带的 loss 就不需要再加上 Sigmoid 操作了 | |||
| # + | |||
| # 使用自带的loss | |||
| criterion = nn.BCEWithLogitsLoss() # 将 sigmoid 和 loss 写在一层,有更快的速度、更好的稳定性 | |||
| w = nn.Parameter(torch.randn(2, 1)) | |||
| b = nn.Parameter(torch.zeros(1)) | |||
| def logistic_reg(x): | |||
| return torch.mm(x, w) + b | |||
| optimizer = torch.optim.SGD([w, b], 1.) | |||
| # - | |||
| y_pred = logistic_reg(x_data) | |||
| loss = criterion(y_pred, y_data) | |||
| print(loss.data) | |||
| # + | |||
| # 同样进行 1000 次更新 | |||
| start = time.time() | |||
| for e in range(1000): | |||
| # 前向传播 | |||
| y_pred = logistic_reg(x_data) | |||
| loss = criterion(y_pred, y_data) | |||
| # 反向传播 | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| # 计算正确率 | |||
| mask = y_pred.ge(0.5).float() | |||
| acc = (mask == y_data).sum().data[0] / y_data.shape[0] | |||
| if (e + 1) % 200 == 0: | |||
| print('epoch: {}, Loss: {:.5f}, Acc: {:.5f}'.format(e+1, loss.data[0], acc)) | |||
| during = time.time() - start | |||
| print() | |||
| print('During Time: {:.3f} s'.format(during)) | |||
| # - | |||
| # 可以看到,使用了 PyTorch 自带的 loss 之后,速度有了一定的上升,虽然看上去速度的提升并不多,但是这只是一个小网络,对于大网络,使用自带的 loss 不管对于稳定性还是速度而言,都有质的飞跃,同时也避免了重复造轮子的困扰 | |||
| # 下一节课我们会介绍 PyTorch 中构建模型的模块 `Sequential` 和 `Module`,使用这个可以帮助我们更方便地构建模型 | |||
+ 1133
- 0
2_pytorch/1_NN/nn-sequential-module.ipynb
File diff suppressed because it is too large
View File
+ 1955
- 0
2_pytorch/1_NN/nn_intro.ipynb
File diff suppressed because it is too large
View File
+ 281
- 0
2_pytorch/1_NN/optimizer/adadelta.ipynb
File diff suppressed because it is too large
View File
+ 169
- 0
2_pytorch/1_NN/optimizer/adadelta.py
View File
| @@ -0,0 +1,169 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # Adadelta | |||
| # Adadelta 算是 Adagrad 法的延伸,它跟 RMSProp 一样,都是为了解决 Adagrad 中学习率不断减小的问题,RMSProp 是通过移动加权平均的方式,而 Adadelta 也是一种方法,有趣的是,它并不需要学习率这个参数。 | |||
| # | |||
| # ## Adadelta 法 | |||
| # Adadelta 跟 RMSProp 一样,先使用移动平均来计算 s | |||
| # | |||
| # $$ | |||
| # s = \rho s + (1 - \rho) g^2 | |||
| # $$ | |||
| # | |||
| # 这里 $\rho$ 和 RMSProp 中的 $\alpha$ 都是移动平均系数,g 是参数的梯度,然后我们会计算需要更新的参数的变化量 | |||
| # | |||
| # $$ | |||
| # g' = \frac{\sqrt{\Delta \theta + \epsilon}}{\sqrt{s + \epsilon}} g | |||
| # $$ | |||
| # | |||
| # $\Delta \theta$ 初始为 0 张量,每一步做如下的指数加权移动平均更新 | |||
| # | |||
| # $$ | |||
| # \Delta \theta = \rho \Delta \theta + (1 - \rho) g'^2 | |||
| # $$ | |||
| # | |||
| # 最后参数更新如下 | |||
| # | |||
| # $$ | |||
| # \theta = \theta - g' | |||
| # $$ | |||
| # | |||
| # 下面我们实现以下 Adadelta | |||
| def adadelta(parameters, sqrs, deltas, rho): | |||
| eps = 1e-6 | |||
| for param, sqr, delta in zip(parameters, sqrs, deltas): | |||
| sqr[:] = rho * sqr + (1 - rho) * param.grad.data ** 2 | |||
| cur_delta = torch.sqrt(delta + eps) / torch.sqrt(sqr + eps) * param.grad.data | |||
| delta[:] = rho * delta + (1 - rho) * cur_delta ** 2 | |||
| param.data = param.data - cur_delta | |||
| # + | |||
| import numpy as np | |||
| import torch | |||
| from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 | |||
| from torch.utils.data import DataLoader | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| import time | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 | |||
| x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到 | |||
| x = x.reshape((-1,)) # 拉平 | |||
| x = torch.from_numpy(x) | |||
| return x | |||
| train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换 | |||
| test_set = MNIST('./data', train=False, transform=data_tf, download=True) | |||
| # 定义 loss 函数 | |||
| criterion = nn.CrossEntropyLoss() | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 初始化梯度平方项和 delta 项 | |||
| sqrs = [] | |||
| deltas = [] | |||
| for param in net.parameters(): | |||
| sqrs.append(torch.zeros_like(param.data)) | |||
| deltas.append(torch.zeros_like(param.data)) | |||
| # 开始训练 | |||
| losses = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| adadelta(net.parameters(), sqrs, deltas, 0.9) # rho 设置为 0.9 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses), endpoint=True) | |||
| plt.semilogy(x_axis, losses, label='rho=0.99') | |||
| plt.legend(loc='best') | |||
| # 可以看到使用 adadelta 跑 5 次能够得到更小的 loss | |||
| # **小练习:思考一下为什么 Adadelta 没有学习率这个参数,它是被什么代替了** | |||
| # 当然 pytorch 也内置了 adadelta 的方法,非常简单,只需要调用 `torch.optim.Adadelta()` 就可以了,下面是例子 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| optimizer = torch.optim.Adadelta(net.parameters(), rho=0.9) | |||
| # 开始训练 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| # **小练习:看看 pytorch 中的 adadelta,里面是有学习率这个参数,但是前面我们讲过 adadelta 不用设置学习率,看看这个学习率到底是干嘛的** | |||
+ 264
- 0
2_pytorch/1_NN/optimizer/adagrad.ipynb
File diff suppressed because it is too large
View File
+ 293
- 0
2_pytorch/1_NN/optimizer/adam.ipynb
File diff suppressed because it is too large
View File
+ 182
- 0
2_pytorch/1_NN/optimizer/adam.py
View File
| @@ -0,0 +1,182 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # Adam | |||
| # Adam 是一个结合了动量法和 RMSProp 的优化算法,其结合了两者的优点。 | |||
| # | |||
| # ## Adam 算法 | |||
| # Adam 算法会使用一个动量变量 v 和一个 RMSProp 中的梯度元素平方的移动指数加权平均 s,首先将他们全部初始化为 0,然后在每次迭代中,计算他们的移动加权平均进行更新 | |||
| # | |||
| # $$ | |||
| # v = \beta_1 v + (1 - \beta_1) g \\ | |||
| # s = \beta_2 s + (1 - \beta_2) g^2 | |||
| # $$ | |||
| # | |||
| # 在 adam 算法里,为了减轻 v 和 s 被初始化为 0 的初期对计算指数加权移动平均的影响,每次 v 和 s 都做下面的修正 | |||
| # | |||
| # $$ | |||
| # \hat{v} = \frac{v}{1 - \beta_1^t} \\ | |||
| # \hat{s} = \frac{s}{1 - \beta_2^t} | |||
| # $$ | |||
| # | |||
| # 这里 t 是迭代次数,可以看到,当 $0 \leq \beta_1, \beta_2 \leq 1$ 的时候,迭代到后期 t 比较大,那么 $\beta_1^t$ 和 $\beta_2^t$ 就几乎为 0,就不会对 v 和 s 有任何影响了,算法作者建议$\beta_1 = 0.9$, $\beta_2 = 0.999$。 | |||
| # | |||
| # 最后使用修正之后的 $\hat{v}$ 和 $\hat{s}$ 进行学习率的重新计算 | |||
| # | |||
| # $$ | |||
| # g' = \frac{\eta \hat{v}}{\sqrt{\hat{s} + \epsilon}} | |||
| # $$ | |||
| # | |||
| # 这里 $\eta$ 是学习率,$epsilon$ 仍然是为了数值稳定性而添加的常数,最后参数更新有 | |||
| # | |||
| # $$ | |||
| # \theta_i = \theta_{i-1} - g' | |||
| # $$ | |||
| # 下面我们来实现以下 adam 算法 | |||
| def adam(parameters, vs, sqrs, lr, t, beta1=0.9, beta2=0.999): | |||
| eps = 1e-8 | |||
| for param, v, sqr in zip(parameters, vs, sqrs): | |||
| v[:] = beta1 * v + (1 - beta1) * param.grad.data | |||
| sqr[:] = beta2 * sqr + (1 - beta2) * param.grad.data ** 2 | |||
| v_hat = v / (1 - beta1 ** t) | |||
| s_hat = sqr / (1 - beta2 ** t) | |||
| param.data = param.data - lr * v_hat / torch.sqrt(s_hat + eps) | |||
| # + | |||
| import numpy as np | |||
| import torch | |||
| from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 | |||
| from torch.utils.data import DataLoader | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| import time | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 | |||
| x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到 | |||
| x = x.reshape((-1,)) # 拉平 | |||
| x = torch.from_numpy(x) | |||
| return x | |||
| train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换 | |||
| test_set = MNIST('./data', train=False, transform=data_tf, download=True) | |||
| # 定义 loss 函数 | |||
| criterion = nn.CrossEntropyLoss() | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 初始化梯度平方项和动量项 | |||
| sqrs = [] | |||
| vs = [] | |||
| for param in net.parameters(): | |||
| sqrs.append(torch.zeros_like(param.data)) | |||
| vs.append(torch.zeros_like(param.data)) | |||
| t = 1 | |||
| # 开始训练 | |||
| losses = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| adam(net.parameters(), vs, sqrs, 1e-3, t) # 学习率设为 0.001 | |||
| t += 1 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses), endpoint=True) | |||
| plt.semilogy(x_axis, losses, label='adam') | |||
| plt.legend(loc='best') | |||
| # 可以看到使用 adam 算法 loss 能够更快更好地收敛,但是一定要小心学习率的设定,使用自适应的算法一般需要更小的学习率 | |||
| # | |||
| # 当然 pytorch 中也内置了 adam 的实现,只需要调用 `torch.optim.Adam()`,下面是例子 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| optimizer = torch.optim.Adam(net.parameters(), lr=1e-3) | |||
| # 开始训练 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| # 这是我们讲的最后一个优化算法,下面放一张各个优化算法的对比图结束这一节的内容 | |||
| # | |||
| # 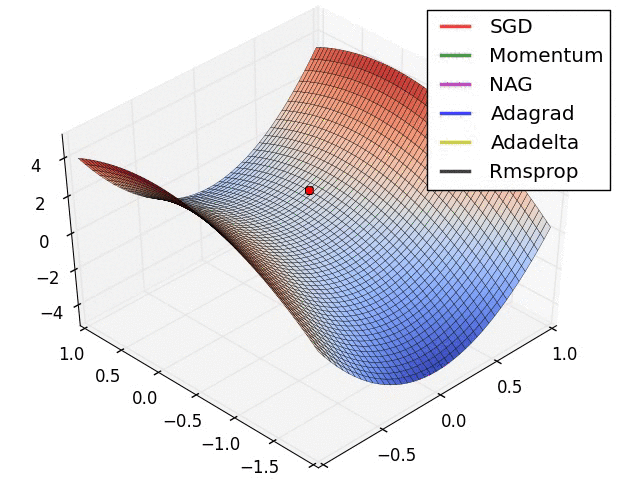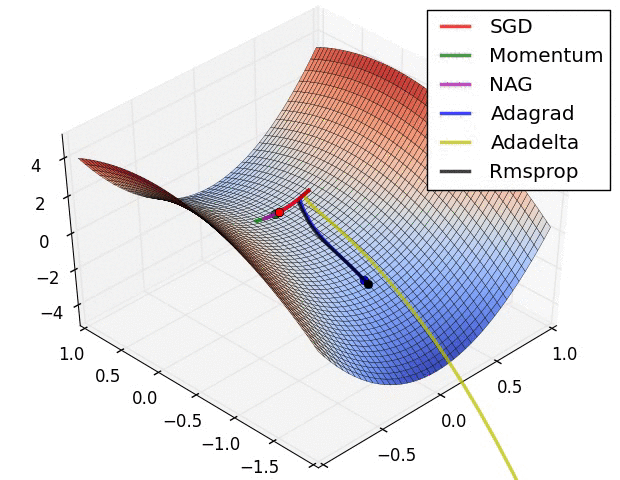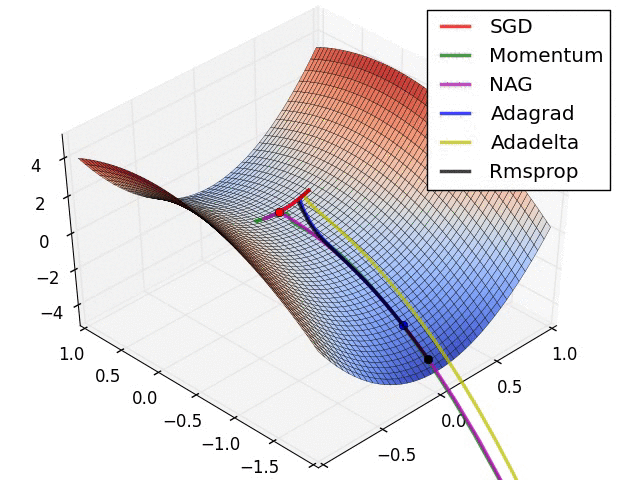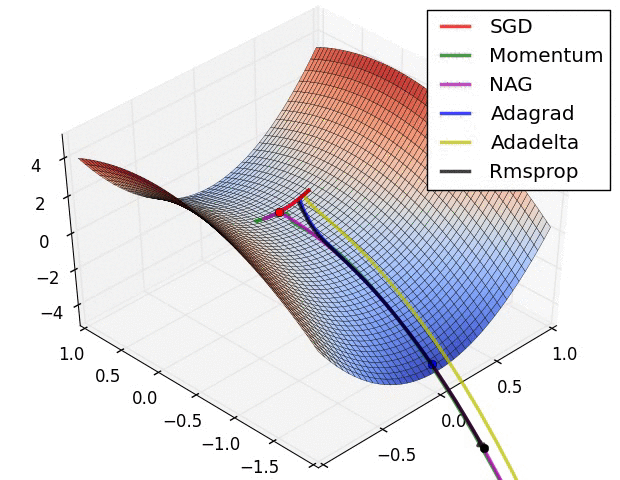 | |||
| # | |||
| # 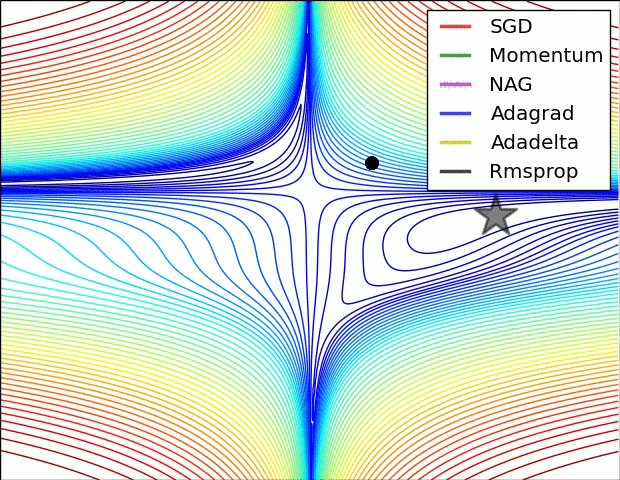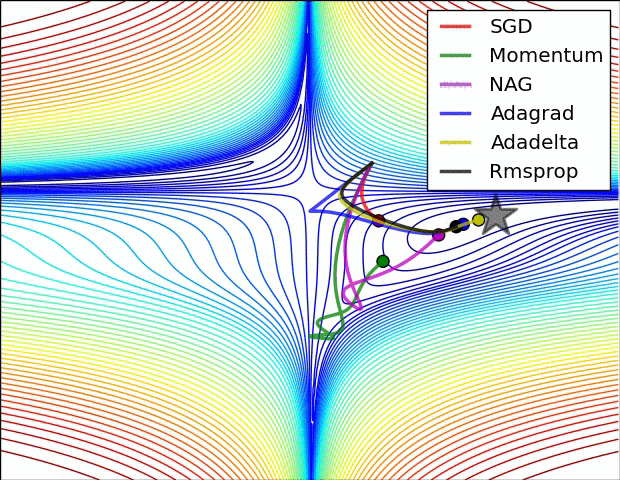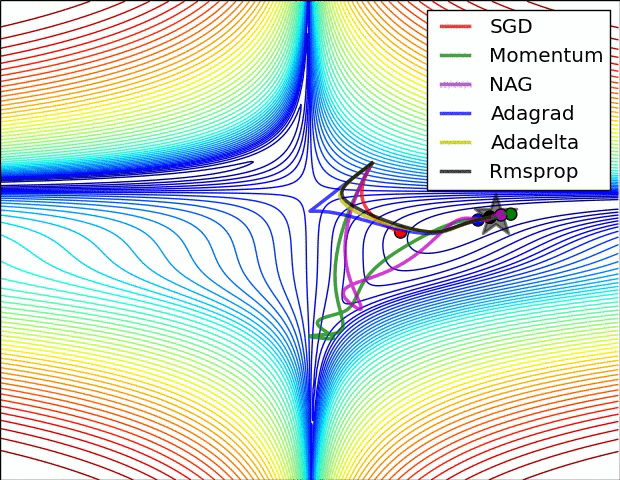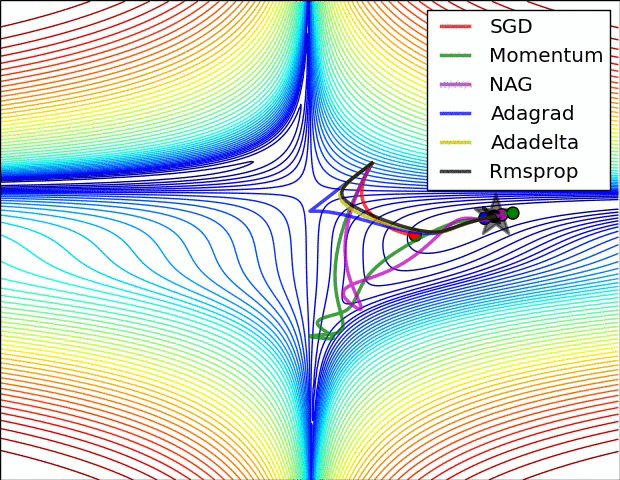 | |||
| # | |||
| # | |||
| # 这两张图生动形象地展示了各种优化算法的实际效果 | |||
+ 396
- 0
2_pytorch/1_NN/optimizer/momentum.ipynb
File diff suppressed because it is too large
View File
+ 231
- 0
2_pytorch/1_NN/optimizer/momentum.py
View File
| @@ -0,0 +1,231 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # 动量法 | |||
| # 使用梯度下降法,每次都会朝着目标函数下降最快的方向,这也称为最速下降法。这种更新方法看似非常快,实际上存在一些问题。 | |||
| # | |||
| # ## 梯度下降法的问题 | |||
| # 考虑一个二维输入,$[x_1, x_2]$,输出的损失函数 $L: R^2 \rightarrow R$,下面是这个函数的等高线 | |||
| # | |||
| #  | |||
| # | |||
| # 可以想象成一个很扁的漏斗,这样在竖直方向上,梯度就非常大,在水平方向上,梯度就相对较小,所以我们在设置学习率的时候就不能设置太大,为了防止竖直方向上参数更新太过了,这样一个较小的学习率又导致了水平方向上参数在更新的时候太过于缓慢,所以就导致最终收敛起来非常慢。 | |||
| # | |||
| # ## 动量法 | |||
| # 动量法的提出就是为了应对这个问题,我们梯度下降法做一个修改如下 | |||
| # | |||
| # $$ | |||
| # v_i = \gamma v_{i-1} + \eta \nabla L(\theta) | |||
| # $$ | |||
| # $$ | |||
| # \theta_i = \theta_{i-1} - v_i | |||
| # $$ | |||
| # | |||
| # 其中 $v_i$ 是当前速度,$\gamma$ 是动量参数,是一个小于 1的正数,$\eta$ 是学习率 | |||
| # 相当于每次在进行参数更新的时候,都会将之前的速度考虑进来,每个参数在各方向上的移动幅度不仅取决于当前的梯度,还取决于过去各个梯度在各个方向上是否一致,如果一个梯度一直沿着当前方向进行更新,那么每次更新的幅度就越来越大,如果一个梯度在一个方向上不断变化,那么其更新幅度就会被衰减,这样我们就可以使用一个较大的学习率,使得收敛更快,同时梯度比较大的方向就会因为动量的关系每次更新的幅度减少,如下图 | |||
| # | |||
| #  | |||
| # | |||
| # 比如我们的梯度每次都等于 g,而且方向都相同,那么动量法在该方向上使参数加速移动,有下面的公式: | |||
| # | |||
| # $$ | |||
| # v_0 = 0 | |||
| # $$ | |||
| # $$ | |||
| # v_1 = \gamma v_0 + \eta g = \eta g | |||
| # $$ | |||
| # $$ | |||
| # v_2 = \gamma v_1 + \eta g = (1 + \gamma) \eta g | |||
| # $$ | |||
| # $$ | |||
| # v_3 = \gamma v_2 + \eta g = (1 + \gamma + \gamma^2) \eta g | |||
| # $$ | |||
| # $$ | |||
| # \cdots | |||
| # $$ | |||
| # $$ | |||
| # v_{+ \infty} = (1 + \gamma + \gamma^2 + \gamma^3 + \cdots) \eta g = \frac{1}{1 - \gamma} \eta g | |||
| # $$ | |||
| # | |||
| # 如果我们把 $\gamma$ 定为 0.9,那么更新幅度的峰值就是原本梯度乘学习率的 10 倍。 | |||
| # | |||
| # 本质上说,动量法就仿佛我们从高坡上推一个球,小球在向下滚动的过程中积累了动量,在途中也会变得越来越快,最后会达到一个峰值,对应于我们的算法中就是,动量项会沿着梯度指向方向相同的方向不断增大,对于梯度方向改变的方向逐渐减小,得到了更快的收敛速度以及更小的震荡。 | |||
| # | |||
| # 下面我们手动实现一个动量法,公式已经在上面了 | |||
| def sgd_momentum(parameters, vs, lr, gamma): | |||
| for param, v in zip(parameters, vs): | |||
| v[:] = gamma * v + lr * param.grad.data | |||
| param.data = param.data - v | |||
| # + | |||
| import numpy as np | |||
| import torch | |||
| from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 | |||
| from torch.utils.data import DataLoader | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| import time | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 | |||
| x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到 | |||
| x = x.reshape((-1,)) # 拉平 | |||
| x = torch.from_numpy(x) | |||
| return x | |||
| train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换 | |||
| test_set = MNIST('./data', train=False, transform=data_tf, download=True) | |||
| # 定义 loss 函数 | |||
| criterion = nn.CrossEntropyLoss() | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 将速度初始化为和参数形状相同的零张量 | |||
| vs = [] | |||
| for param in net.parameters(): | |||
| vs.append(torch.zeros_like(param.data)) | |||
| # 开始训练 | |||
| losses = [] | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| sgd_momentum(net.parameters(), vs, 1e-2, 0.9) # 使用的动量参数为 0.9,学习率 0.01 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| losses.append(loss.data[0]) | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| # 可以看到,加完动量之后 loss 能下降非常快,但是一定要小心学习率和动量参数,这两个值会直接影响到参数每次更新的幅度,所以可以多试几个值 | |||
| # 当然,pytorch 内置了动量法的实现,非常简单,直接在 `torch.optim.SGD(momentum=0.9)` 即可,下面实现一下 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) # 加动量 | |||
| # 开始训练 | |||
| losses = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: # 30 步记录一次 | |||
| losses.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses), endpoint=True) | |||
| plt.semilogy(x_axis, losses, label='momentum: 0.9') | |||
| plt.legend(loc='best') | |||
| # 我们可以对比一下不加动量的随机梯度下降法 | |||
| # + | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=1e-2) # 不加动量 | |||
| # 开始训练 | |||
| losses1 = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: # 30 步记录一次 | |||
| losses1.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses), endpoint=True) | |||
| plt.semilogy(x_axis, losses, label='momentum: 0.9') | |||
| plt.semilogy(x_axis, losses1, label='no momentum') | |||
| plt.legend(loc='best') | |||
| # 可以看到加完动量之后的 loss 下降的程度更低了,可以将动量理解为一种惯性作用,所以每次更新的幅度都会比不加动量的情况更多 | |||
+ 347
- 0
2_pytorch/1_NN/optimizer/rmsprop.ipynb
File diff suppressed because it is too large
View File
+ 198
- 0
2_pytorch/1_NN/optimizer/rmsprop.py
View File
| @@ -0,0 +1,198 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # RMSProp | |||
| # RMSprop 是由 Geoff Hinton 在他 Coursera 课程中提出的一种适应性学习率方法,至今仍未被公开发表。前面我们提到了 Adagrad 算法有一个问题,就是学习率分母上的变量 s 不断被累加增大,最后会导致学习率除以一个比较大的数之后变得非常小,这不利于我们找到最后的最优解,所以 RMSProp 的提出就是为了解决这个问题。 | |||
| # | |||
| # ## RMSProp 算法 | |||
| # RMSProp 仍然会使用梯度的平方量,不同于 Adagrad,其会使用一个指数加权移动平均来计算这个 s,也就是 | |||
| # | |||
| # $$ | |||
| # s_i = \alpha s_{i-1} + (1 - \alpha) \ g^2 | |||
| # $$ | |||
| # | |||
| # 这里 g 表示当前求出的参数梯度,然后最终更新和 Adagrad 是一样的,学习率变成了 | |||
| # | |||
| # $$ | |||
| # \frac{\eta}{\sqrt{s + \epsilon}} | |||
| # $$ | |||
| # | |||
| # 这里 $\alpha$ 是一个移动平均的系数,也是因为这个系数,导致了 RMSProp 和 Adagrad 不同的地方,这个系数使得 RMSProp 更新到后期累加的梯度平方较小,从而保证 s 不会太大,也就使得模型后期依然能够找到比较优的结果 | |||
| # | |||
| # 实现上和 Adagrad 非常像 | |||
| def rmsprop(parameters, sqrs, lr, alpha): | |||
| eps = 1e-10 | |||
| for param, sqr in zip(parameters, sqrs): | |||
| sqr[:] = alpha * sqr + (1 - alpha) * param.grad.data ** 2 | |||
| div = lr / torch.sqrt(sqr + eps) * param.grad.data | |||
| param.data = param.data - div | |||
| # + | |||
| import numpy as np | |||
| import torch | |||
| from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 | |||
| from torch.utils.data import DataLoader | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| import time | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 | |||
| x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到 | |||
| x = x.reshape((-1,)) # 拉平 | |||
| x = torch.from_numpy(x) | |||
| return x | |||
| train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换 | |||
| test_set = MNIST('./data', train=False, transform=data_tf, download=True) | |||
| # 定义 loss 函数 | |||
| criterion = nn.CrossEntropyLoss() | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 初始化梯度平方项 | |||
| sqrs = [] | |||
| for param in net.parameters(): | |||
| sqrs.append(torch.zeros_like(param.data)) | |||
| # 开始训练 | |||
| losses = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| rmsprop(net.parameters(), sqrs, 1e-3, 0.9) # 学习率设为 0.001,alpha 设为 0.9 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses), endpoint=True) | |||
| plt.semilogy(x_axis, losses, label='alpha=0.9') | |||
| plt.legend(loc='best') | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 初始化梯度平方项 | |||
| sqrs = [] | |||
| for param in net.parameters(): | |||
| sqrs.append(torch.zeros_like(param.data)) | |||
| # 开始训练 | |||
| losses = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| rmsprop(net.parameters(), sqrs, 1e-3, 0.999) # 学习率设为 0.001,alpha 设为 0.999 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses), endpoint=True) | |||
| plt.semilogy(x_axis, losses, label='alpha=0.999') | |||
| plt.legend(loc='best') | |||
| # **小练习:可以看到使用了不同的 alpha 会使得 loss 在下降过程中的震荡程度不同,想想为什么** | |||
| # 当然 pytorch 也内置了 rmsprop 的方法,非常简单,只需要调用 `torch.optim.RMSprop()` 就可以了,下面是例子 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| optimizer = torch.optim.RMSprop(net.parameters(), lr=1e-3, alpha=0.9) | |||
| # 开始训练 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
+ 441
- 0
2_pytorch/1_NN/optimizer/sgd.ipynb
File diff suppressed because it is too large
View File
+ 222
- 0
2_pytorch/1_NN/optimizer/sgd.py
View File
| @@ -0,0 +1,222 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # 随机梯度下降法 | |||
| # 前面我们介绍了梯度下降法的数学原理,下面我们通过例子来说明一下随机梯度下降法,我们分别从 0 自己实现,以及使用 pytorch 中自带的优化器 | |||
| # + | |||
| import numpy as np | |||
| import torch | |||
| from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据 | |||
| from torch.utils.data import DataLoader | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| import time | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 # 将数据变到 0 ~ 1 之间 | |||
| x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到 | |||
| x = x.reshape((-1,)) # 拉平 | |||
| x = torch.from_numpy(x) | |||
| return x | |||
| train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换 | |||
| test_set = MNIST('./data', train=False, transform=data_tf, download=True) | |||
| # 定义 loss 函数 | |||
| criterion = nn.CrossEntropyLoss() | |||
| # - | |||
| # 随机梯度下降法非常简单,公式就是 | |||
| # $$ | |||
| # \theta_{i+1} = \theta_i - \eta \nabla L(\theta) | |||
| # $$ | |||
| # 非常简单,我们可以从 0 开始自己实现 | |||
| def sgd_update(parameters, lr): | |||
| for param in parameters: | |||
| param.data = param.data - lr * param.grad.data | |||
| # 我们可以将 batch size 先设置为 1,看看有什么效果 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=1, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 开始训练 | |||
| losses1 = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| sgd_update(net.parameters(), 1e-2) # 使用 0.01 的学习率 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses1.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses1), endpoint=True) | |||
| plt.semilogy(x_axis, losses1, label='batch_size=1') | |||
| plt.legend(loc='best') | |||
| # 可以看到,loss 在剧烈震荡,因为每次都是只对一个样本点做计算,每一层的梯度都具有很高的随机性,而且需要耗费了大量的时间 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 开始训练 | |||
| losses2 = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| sgd_update(net.parameters(), 1e-2) | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses2.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses2), endpoint=True) | |||
| plt.semilogy(x_axis, losses2, label='batch_size=64') | |||
| plt.legend(loc='best') | |||
| # 通过上面的结果可以看到 loss 没有 batch 等于 1 震荡那么距离,同时也可以降到一定的程度了,时间上也比之前快了非常多,因为按照 batch 的数据量计算上更快,同时梯度对比于 batch size = 1 的情况也跟接近真实的梯度,所以 batch size 的值越大,梯度也就越稳定,而 batch size 越小,梯度具有越高的随机性,这里 batch size 为 64,可以看到 loss 仍然存在震荡,但这并没有关系,如果 batch size 太大,对于内存的需求就更高,同时也不利于网络跳出局部极小点,所以现在普遍使用基于 batch 的随机梯度下降法,而 batch 的多少基于实际情况进行考虑 | |||
| # 下面我们调高学习率,看看有什么样的结果 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| # 开始训练 | |||
| losses3 = [] | |||
| idx = 0 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| net.zero_grad() | |||
| loss.backward() | |||
| sgd_update(net.parameters(), 1) # 使用 1.0 的学习率 | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| if idx % 30 == 0: | |||
| losses3.append(loss.data[0]) | |||
| idx += 1 | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
| # - | |||
| x_axis = np.linspace(0, 5, len(losses3), endpoint=True) | |||
| plt.semilogy(x_axis, losses3, label='lr = 1') | |||
| plt.legend(loc='best') | |||
| # 可以看到,学习率太大会使得损失函数不断回跳,从而无法让损失函数较好降低,所以我们一般都是用一个比较小的学习率 | |||
| # 实际上我们并不用自己造轮子,因为 pytorch 中已经为我们内置了随机梯度下降发,而且之前我们一直在使用,下面我们来使用 pytorch 自带的优化器来实现随机梯度下降 | |||
| # + | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| # 使用 Sequential 定义 3 层神经网络 | |||
| net = nn.Sequential( | |||
| nn.Linear(784, 200), | |||
| nn.ReLU(), | |||
| nn.Linear(200, 10), | |||
| ) | |||
| optimzier = torch.optim.SGD(net.parameters(), 1e-2) | |||
| # 开始训练 | |||
| start = time.time() # 记时开始 | |||
| for e in range(5): | |||
| train_loss = 0 | |||
| for im, label in train_data: | |||
| im = Variable(im) | |||
| label = Variable(label) | |||
| # 前向传播 | |||
| out = net(im) | |||
| loss = criterion(out, label) | |||
| # 反向传播 | |||
| optimzier.zero_grad() | |||
| loss.backward() | |||
| optimzier.step() | |||
| # 记录误差 | |||
| train_loss += loss.data[0] | |||
| print('epoch: {}, Train Loss: {:.6f}' | |||
| .format(e, train_loss / len(train_data))) | |||
| end = time.time() # 计时结束 | |||
| print('使用时间: {:.5f} s'.format(end - start)) | |||
+ 476
- 0
2_pytorch/1_NN/param_initialize.ipynb
View File
| @@ -0,0 +1,476 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "# 参数初始化\n", | |||
| "参数初始化对模型具有较大的影响,不同的初始化方式可能会导致截然不同的结果,所幸的是很多深度学习的先驱们已经帮我们探索了各种各样的初始化方式,所以我们只需要学会如何对模型的参数进行初始化的赋值即可。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "PyTorch 的初始化方式并没有那么显然,如果你使用最原始的方式创建模型,那么你需要定义模型中的所有参数,当然这样你可以非常方便地定义每个变量的初始化方式,但是对于复杂的模型,这并不容易,而且我们推崇使用 Sequential 和 Module 来定义模型,所以这个时候我们就需要知道如何来自定义初始化方式" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 使用 NumPy 来初始化\n", | |||
| "因为 PyTorch 是一个非常灵活的框架,理论上能够对所有的 Tensor 进行操作,所以我们能够通过定义新的 Tensor 来初始化,直接看下面的例子" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import numpy as np\n", | |||
| "import torch\n", | |||
| "from torch import nn" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 定义一个 Sequential 模型\n", | |||
| "net1 = nn.Sequential(\n", | |||
| " nn.Linear(30, 40),\n", | |||
| " nn.ReLU(),\n", | |||
| " nn.Linear(40, 50),\n", | |||
| " nn.ReLU(),\n", | |||
| " nn.Linear(50, 10)\n", | |||
| ")" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 访问第一层的参数\n", | |||
| "w1 = net1[0].weight\n", | |||
| "b1 = net1[0].bias" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Parameter containing:\n", | |||
| " 0.1236 -0.1731 -0.0479 ... 0.0031 0.0784 0.1239\n", | |||
| " 0.0713 0.1615 0.0500 ... -0.1757 -0.1274 -0.1625\n", | |||
| " 0.0638 -0.1543 -0.0362 ... 0.0316 -0.1774 -0.1242\n", | |||
| " ... ⋱ ... \n", | |||
| " 0.1551 0.1772 0.1537 ... 0.0730 0.0950 0.0627\n", | |||
| " 0.0495 0.0896 0.0243 ... -0.1302 -0.0256 -0.0326\n", | |||
| "-0.1193 -0.0989 -0.1795 ... 0.0939 0.0774 -0.0751\n", | |||
| "[torch.FloatTensor of size 40x30]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(w1)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "注意,这是一个 Parameter,也就是一个特殊的 Variable,我们可以访问其 `.data`属性得到其中的数据,然后直接定义一个新的 Tensor 对其进行替换,我们可以使用 PyTorch 中的一些随机数据生成的方式,比如 `torch.randn`,如果要使用更多 PyTorch 中没有的随机化方式,可以使用 numpy" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 定义一个 Tensor 直接对其进行替换\n", | |||
| "net1[0].weight.data = torch.from_numpy(np.random.uniform(3, 5, size=(40, 30)))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Parameter containing:\n", | |||
| " 4.5768 3.6175 3.3098 ... 4.7374 4.0164 3.3037\n", | |||
| " 4.1809 3.5624 3.1452 ... 3.0305 4.4444 4.1058\n", | |||
| " 3.5277 4.3712 3.7859 ... 3.5760 4.8559 4.3252\n", | |||
| " ... ⋱ ... \n", | |||
| " 4.8983 3.9855 3.2842 ... 4.7683 4.7590 3.3498\n", | |||
| " 4.9168 4.5723 3.5870 ... 3.2032 3.9842 3.2484\n", | |||
| " 4.2532 4.6352 4.4857 ... 3.7543 3.9885 4.4211\n", | |||
| "[torch.DoubleTensor of size 40x30]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(net1[0].weight)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到这个参数的值已经被改变了,也就是说已经被定义成了我们需要的初始化方式,如果模型中某一层需要我们手动去修改,那么我们可以直接用这种方式去访问,但是更多的时候是模型中相同类型的层都需要初始化成相同的方式,这个时候一种更高效的方式是使用循环去访问,比如" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "for layer in net1:\n", | |||
| " if isinstance(layer, nn.Linear): # 判断是否是线性层\n", | |||
| " param_shape = layer.weight.shape\n", | |||
| " layer.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape)) \n", | |||
| " # 定义为均值为 0,方差为 0.5 的正态分布" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "**小练习:一种非常流行的初始化方式叫 Xavier,方法来源于 2010 年的一篇论文 [Understanding the difficulty of training deep feedforward neural networks](http://proceedings.mlr.press/v9/glorot10a.html),其通过数学的推到,证明了这种初始化方式可以使得每一层的输出方差是尽可能相等的,有兴趣的同学可以去看看论文**\n", | |||
| "\n", | |||
| "我们给出这种初始化的公式\n", | |||
| "\n", | |||
| "$$\n", | |||
| "w\\ \\sim \\ Uniform[- \\frac{\\sqrt{6}}{\\sqrt{n_j + n_{j+1}}}, \\frac{\\sqrt{6}}{\\sqrt{n_j + n_{j+1}}}]\n", | |||
| "$$\n", | |||
| "\n", | |||
| "其中 $n_j$ 和 $n_{j+1}$ 表示该层的输入和输出数目,所以请尝试实现以下这种初始化方式" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "对于 Module 的参数初始化,其实也非常简单,如果想对其中的某层进行初始化,可以直接像 Sequential 一样对其 Tensor 进行重新定义,其唯一不同的地方在于,如果要用循环的方式访问,需要介绍两个属性,children 和 modules,下面我们举例来说明" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "class sim_net(nn.Module):\n", | |||
| " def __init__(self):\n", | |||
| " super(sim_net, self).__init__()\n", | |||
| " self.l1 = nn.Sequential(\n", | |||
| " nn.Linear(30, 40),\n", | |||
| " nn.ReLU()\n", | |||
| " )\n", | |||
| " \n", | |||
| " self.l1[0].weight.data = torch.randn(40, 30) # 直接对某一层初始化\n", | |||
| " \n", | |||
| " self.l2 = nn.Sequential(\n", | |||
| " nn.Linear(40, 50),\n", | |||
| " nn.ReLU()\n", | |||
| " )\n", | |||
| " \n", | |||
| " self.l3 = nn.Sequential(\n", | |||
| " nn.Linear(50, 10),\n", | |||
| " nn.ReLU()\n", | |||
| " )\n", | |||
| " \n", | |||
| " def forward(self, x):\n", | |||
| " x = self.l1(x)\n", | |||
| " x =self.l2(x)\n", | |||
| " x = self.l3(x)\n", | |||
| " return x" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "net2 = sim_net()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 10, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Sequential(\n", | |||
| " (0): Linear(in_features=30, out_features=40)\n", | |||
| " (1): ReLU()\n", | |||
| ")\n", | |||
| "Sequential(\n", | |||
| " (0): Linear(in_features=40, out_features=50)\n", | |||
| " (1): ReLU()\n", | |||
| ")\n", | |||
| "Sequential(\n", | |||
| " (0): Linear(in_features=50, out_features=10)\n", | |||
| " (1): ReLU()\n", | |||
| ")\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 访问 children\n", | |||
| "for i in net2.children():\n", | |||
| " print(i)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "sim_net(\n", | |||
| " (l1): Sequential(\n", | |||
| " (0): Linear(in_features=30, out_features=40)\n", | |||
| " (1): ReLU()\n", | |||
| " )\n", | |||
| " (l2): Sequential(\n", | |||
| " (0): Linear(in_features=40, out_features=50)\n", | |||
| " (1): ReLU()\n", | |||
| " )\n", | |||
| " (l3): Sequential(\n", | |||
| " (0): Linear(in_features=50, out_features=10)\n", | |||
| " (1): ReLU()\n", | |||
| " )\n", | |||
| ")\n", | |||
| "Sequential(\n", | |||
| " (0): Linear(in_features=30, out_features=40)\n", | |||
| " (1): ReLU()\n", | |||
| ")\n", | |||
| "Linear(in_features=30, out_features=40)\n", | |||
| "ReLU()\n", | |||
| "Sequential(\n", | |||
| " (0): Linear(in_features=40, out_features=50)\n", | |||
| " (1): ReLU()\n", | |||
| ")\n", | |||
| "Linear(in_features=40, out_features=50)\n", | |||
| "ReLU()\n", | |||
| "Sequential(\n", | |||
| " (0): Linear(in_features=50, out_features=10)\n", | |||
| " (1): ReLU()\n", | |||
| ")\n", | |||
| "Linear(in_features=50, out_features=10)\n", | |||
| "ReLU()\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 访问 modules\n", | |||
| "for i in net2.modules():\n", | |||
| " print(i)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "通过上面的例子,看到区别了吗?\n", | |||
| "\n", | |||
| "children 只会访问到模型定义中的第一层,因为上面的模型中定义了三个 Sequential,所以只会访问到三个 Sequential,而 modules 会访问到最后的结构,比如上面的例子,modules 不仅访问到了 Sequential,也访问到了 Sequential 里面,这就对我们做初始化非常方便,比如" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 12, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "for layer in net2.modules():\n", | |||
| " if isinstance(layer, nn.Linear):\n", | |||
| " param_shape = layer.weight.shape\n", | |||
| " layer.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape)) " | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "这上面实现了和 Sequential 相同的初始化,同样非常简便" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## torch.nn.init\n", | |||
| "因为 PyTorch 灵活的特性,我们可以直接对 Tensor 进行操作从而初始化,PyTorch 也提供了初始化的函数帮助我们快速初始化,就是 `torch.nn.init`,其操作层面仍然在 Tensor 上,下面我们举例说明" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 13, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from torch.nn import init" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 14, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Parameter containing:\n", | |||
| " 0.8453 0.2891 -0.5276 ... -0.1530 -0.4474 -0.5470\n", | |||
| "-0.1983 -0.4530 -0.1950 ... 0.4107 -0.4889 0.3654\n", | |||
| " 0.9149 -0.5641 -0.6594 ... 0.0734 0.1354 -0.4152\n", | |||
| " ... ⋱ ... \n", | |||
| "-0.4718 -0.5125 -0.5572 ... 0.0824 -0.6551 0.0840\n", | |||
| "-0.2374 -0.0036 0.6497 ... 0.7856 -0.1367 -0.8795\n", | |||
| " 0.0774 0.2609 -0.2358 ... -0.8196 0.1696 0.5976\n", | |||
| "[torch.DoubleTensor of size 40x30]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(net1[0].weight)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 15, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "Parameter containing:\n", | |||
| "-0.2114 0.2704 -0.2186 ... 0.1727 0.2158 0.0775\n", | |||
| "-0.0736 -0.0565 0.0844 ... 0.1793 0.2520 -0.0047\n", | |||
| " 0.1331 -0.1843 0.2426 ... -0.2199 -0.0689 0.1756\n", | |||
| " ... ⋱ ... \n", | |||
| " 0.2751 -0.1404 0.1225 ... 0.1926 0.0175 -0.2099\n", | |||
| " 0.0970 -0.0733 -0.2461 ... 0.0605 0.1915 -0.1220\n", | |||
| " 0.0199 0.1283 -0.1384 ... -0.0344 -0.0560 0.2285\n", | |||
| "[torch.DoubleTensor of size 40x30]" | |||
| ] | |||
| }, | |||
| "execution_count": 15, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "init.xavier_uniform(net1[0].weight) # 这就是上面我们讲过的 Xavier 初始化方法,PyTorch 直接内置了其实现" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 16, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Parameter containing:\n", | |||
| "-0.2114 0.2704 -0.2186 ... 0.1727 0.2158 0.0775\n", | |||
| "-0.0736 -0.0565 0.0844 ... 0.1793 0.2520 -0.0047\n", | |||
| " 0.1331 -0.1843 0.2426 ... -0.2199 -0.0689 0.1756\n", | |||
| " ... ⋱ ... \n", | |||
| " 0.2751 -0.1404 0.1225 ... 0.1926 0.0175 -0.2099\n", | |||
| " 0.0970 -0.0733 -0.2461 ... 0.0605 0.1915 -0.1220\n", | |||
| " 0.0199 0.1283 -0.1384 ... -0.0344 -0.0560 0.2285\n", | |||
| "[torch.DoubleTensor of size 40x30]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(net1[0].weight)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到参数已经被修改了\n", | |||
| "\n", | |||
| "`torch.nn.init` 为我们提供了更多的内置初始化方式,避免了我们重复去实现一些相同的操作" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "上面讲了两种初始化方式,其实它们的本质都是一样的,就是去修改某一层参数的实际值,而 `torch.nn.init` 提供了更多成熟的深度学习相关的初始化方式,非常方便\n", | |||
| "\n", | |||
| "下一节课,我们将讲一下目前流行的各种基于梯度的优化算法" | |||
| ] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python 3", | |||
| "language": "python", | |||
| "name": "python3" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.5.2" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 2 | |||
| } | |||
+ 355
- 0
2_pytorch/2_CNN/basic_conv.ipynb
File diff suppressed because it is too large
View File
+ 109
- 0
2_pytorch/2_CNN/basic_conv.py
View File
| @@ -0,0 +1,109 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # 卷积模块介绍 | |||
| # 前面我们介绍了卷积网络的基本知识,其在计算机视觉领域被应用得非常广泛,那么常见的卷机网络中用到的模块能够使用 pytorch 非常轻松地实现,下面我们来讲一下 pytorch 中的卷积模块 | |||
| # ## 卷积 | |||
| # 卷积在 pytorch 中有两种方式,一种是 `torch.nn.Conv2d()`,一种是 `torch.nn.functional.conv2d()`,这两种形式本质都是使用一个卷积操作 | |||
| # | |||
| # 这两种形式的卷积对于输入的要求都是一样的,首先需要输入是一个 `torch.autograd.Variable()` 的类型,大小是 (batch, channel, H, W),其中 batch 表示输入的一批数据的数目,第二个是输入的通道数,一般一张彩色的图片是 3,灰度图是 1,而卷积网络过程中的通道数比较大,会出现几十到几百的通道数,H 和 W 表示输入图片的高度和宽度,比如一个 batch 是 32 张图片,每张图片是 3 通道,高和宽分别是 50 和 100,那么输入的大小就是 (32, 3, 50, 100) | |||
| # | |||
| # 下面举例来说明一下这两种卷积方式 | |||
| import numpy as np | |||
| import torch | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| import torch.nn.functional as F | |||
| from PIL import Image | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| im = Image.open('./cat.png').convert('L') # 读入一张灰度图的图片 | |||
| im = np.array(im, dtype='float32') # 将其转换为一个矩阵 | |||
| # 可视化图片 | |||
| plt.imshow(im.astype('uint8'), cmap='gray') | |||
| # 将图片矩阵转化为 pytorch tensor,并适配卷积输入的要求 | |||
| im = torch.from_numpy(im.reshape((1, 1, im.shape[0], im.shape[1]))) | |||
| # 下面我们定义一个算子对其进行轮廓检测 | |||
| # + | |||
| # 使用 nn.Conv2d | |||
| conv1 = nn.Conv2d(1, 1, 3, bias=False) # 定义卷积 | |||
| sobel_kernel = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]], dtype='float32') # 定义轮廓检测算子 | |||
| sobel_kernel = sobel_kernel.reshape((1, 1, 3, 3)) # 适配卷积的输入输出 | |||
| conv1.weight.data = torch.from_numpy(sobel_kernel) # 给卷积的 kernel 赋值 | |||
| edge1 = conv1(Variable(im)) # 作用在图片上 | |||
| edge1 = edge1.data.squeeze().numpy() # 将输出转换为图片的格式 | |||
| # - | |||
| # 下面我们可视化边缘检测之后的结果 | |||
| plt.imshow(edge1, cmap='gray') | |||
| # + | |||
| # 使用 F.conv2d | |||
| sobel_kernel = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]], dtype='float32') # 定义轮廓检测算子 | |||
| sobel_kernel = sobel_kernel.reshape((1, 1, 3, 3)) # 适配卷积的输入输出 | |||
| weight = Variable(torch.from_numpy(sobel_kernel)) | |||
| edge2 = F.conv2d(Variable(im), weight) # 作用在图片上 | |||
| edge2 = edge2.data.squeeze().numpy() # 将输出转换为图片的格式 | |||
| plt.imshow(edge2, cmap='gray') | |||
| # - | |||
| # 可以看到两种形式能够得到相同的效果,不同的地方相信你也看到了,使用 `nn.Conv2d()` 相当于直接定义了一层卷积网络结构,而使用 `torch.nn.functional.conv2d()` 相当于定义了一个卷积的操作,所以使用后者需要再额外去定义一个 weight,而且这个 weight 也必须是一个 Variable,而使用 `nn.Conv2d()` 则会帮我们默认定义一个随机初始化的 weight,如果我们需要修改,那么取出其中的值对其修改,如果不想修改,那么可以直接使用这个默认初始化的值,非常方便 | |||
| # | |||
| # **实际使用中我们基本都使用 `nn.Conv2d()` 这种形式** | |||
| # ## 池化层 | |||
| # 卷积网络中另外一个非常重要的结构就是池化,这是利用了图片的下采样不变性,即一张图片变小了还是能够看出了这张图片的内容,而使用池化层能够将图片大小降低,非常好地提高了计算效率,同时池化层也没有参数。池化的方式有很多种,比如最大值池化,均值池化等等,在卷积网络中一般使用最大值池化。 | |||
| # | |||
| # 在 pytorch 中最大值池化的方式也有两种,一种是 `nn.MaxPool2d()`,一种是 `torch.nn.functional.max_pool2d()`,他们对于图片的输入要求跟卷积对于图片的输入要求是一样了,就不再赘述,下面我们也举例说明 | |||
| # 使用 nn.MaxPool2d | |||
| pool1 = nn.MaxPool2d(2, 2) | |||
| print('before max pool, image shape: {} x {}'.format(im.shape[2], im.shape[3])) | |||
| small_im1 = pool1(Variable(im)) | |||
| small_im1 = small_im1.data.squeeze().numpy() | |||
| print('after max pool, image shape: {} x {} '.format(small_im1.shape[0], small_im1.shape[1])) | |||
| # 可以看到图片的大小减小了一半,那么图片是不是变了呢?我们可以可视化一下 | |||
| plt.imshow(small_im1, cmap='gray') | |||
| # 可以看到图片几乎没有变化,说明池化层只是减小了图片的尺寸,并不会影响图片的内容 | |||
| # F.max_pool2d | |||
| print('before max pool, image shape: {} x {}'.format(im.shape[2], im.shape[3])) | |||
| small_im2 = F.max_pool2d(Variable(im), 2, 2) | |||
| small_im2 = small_im2.data.squeeze().numpy() | |||
| print('after max pool, image shape: {} x {} '.format(small_im1.shape[0], small_im1.shape[1])) | |||
| plt.imshow(small_im2, cmap='gray') | |||
| # **跟卷积层一样,实际使用中,我们一般使用 `nn.MaxPool2d()`** | |||
| # 以上我们介绍了如何在 pytorch 中使用卷积网络中的卷积模块和池化模块,接下来我们会开始讲卷积网络中几个非常著名的网络结构 | |||
+ 582
- 0
2_pytorch/2_CNN/batch-normalization.ipynb
View File
| @@ -0,0 +1,582 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "# 批标准化\n", | |||
| "在我们正式进入模型的构建和训练之前,我们会先讲一讲数据预处理和批标准化,因为模型训练并不容易,特别是一些非常复杂的模型,并不能非常好的训练得到收敛的结果,所以对数据增加一些预处理,同时使用批标准化能够得到非常好的收敛结果,这也是卷积网络能够训练到非常深的层的一个重要原因。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## 数据预处理\n", | |||
| "目前数据预处理最常见的方法就是中心化和标准化,中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征。标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间,下面是一个简单的图示\n", | |||
| "\n", | |||
| "\n", | |||
| "\n", | |||
| "这两种方法非常的常见,如果你还记得,前面我们在神经网络的部分就已经使用了这个方法实现了数据标准化,至于另外一些方法,比如 PCA 或者 白噪声已经用得非常少了。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "## Batch Normalization\n", | |||
| "前面在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好。但是对于很深的网路结构,网路的非线性层会使得输出的结果变得相关,且不再满足一个标准的 N(0, 1) 的分布,甚至输出的中心已经发生了偏移,这对于模型的训练,特别是深层的模型训练非常的困难。\n", | |||
| "\n", | |||
| "所以在 2015 年一篇论文提出了这个方法,批标准化,简而言之,就是对于每一层网络的输出,对其做一个归一化,使其服从标准的正态分布,这样后一层网络的输入也是一个标准的正态分布,所以能够比较好的进行训练,加快收敛速度。" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "batch normalization 的实现非常简单,对于给定的一个 batch 的数据 $B = \\{x_1, x_2, \\cdots, x_m\\}$算法的公式如下\n", | |||
| "\n", | |||
| "$$\n", | |||
| "\\mu_B = \\frac{1}{m} \\sum_{i=1}^m x_i\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "\\sigma^2_B = \\frac{1}{m} \\sum_{i=1}^m (x_i - \\mu_B)^2\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "\\hat{x}_i = \\frac{x_i - \\mu_B}{\\sqrt{\\sigma^2_B + \\epsilon}}\n", | |||
| "$$\n", | |||
| "$$\n", | |||
| "y_i = \\gamma \\hat{x}_i + \\beta\n", | |||
| "$$" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "第一行和第二行是计算出一个 batch 中数据的均值和方差,接着使用第三个公式对 batch 中的每个数据点做标准化,$\\epsilon$ 是为了计算稳定引入的一个小的常数,通常取 $10^{-5}$,最后利用权重修正得到最后的输出结果,非常的简单,下面我们可以实现一下简单的一维的情况,也就是神经网络中的情况" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "metadata": { | |||
| "ExecuteTime": { | |||
| "end_time": "2017-12-23T06:50:51.579067Z", | |||
| "start_time": "2017-12-23T06:50:51.575693Z" | |||
| }, | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import sys\n", | |||
| "sys.path.append('..')\n", | |||
| "\n", | |||
| "import torch" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "metadata": { | |||
| "ExecuteTime": { | |||
| "end_time": "2017-12-23T07:14:11.077807Z", | |||
| "start_time": "2017-12-23T07:14:11.060849Z" | |||
| }, | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def simple_batch_norm_1d(x, gamma, beta):\n", | |||
| " eps = 1e-5\n", | |||
| " x_mean = torch.mean(x, dim=0, keepdim=True) # 保留维度进行 broadcast\n", | |||
| " x_var = torch.mean((x - x_mean) ** 2, dim=0, keepdim=True)\n", | |||
| " x_hat = (x - x_mean) / torch.sqrt(x_var + eps)\n", | |||
| " return gamma.view_as(x_mean) * x_hat + beta.view_as(x_mean)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "我们来验证一下是否对于任意的输入,输出会被标准化" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "metadata": { | |||
| "ExecuteTime": { | |||
| "end_time": "2017-12-23T07:14:20.610603Z", | |||
| "start_time": "2017-12-23T07:14:20.597682Z" | |||
| } | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "before bn: \n", | |||
| "\n", | |||
| " 0 1 2\n", | |||
| " 3 4 5\n", | |||
| " 6 7 8\n", | |||
| " 9 10 11\n", | |||
| " 12 13 14\n", | |||
| "[torch.FloatTensor of size 5x3]\n", | |||
| "\n", | |||
| "after bn: \n", | |||
| "\n", | |||
| "-1.4142 -1.4142 -1.4142\n", | |||
| "-0.7071 -0.7071 -0.7071\n", | |||
| " 0.0000 0.0000 0.0000\n", | |||
| " 0.7071 0.7071 0.7071\n", | |||
| " 1.4142 1.4142 1.4142\n", | |||
| "[torch.FloatTensor of size 5x3]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "x = torch.arange(15).view(5, 3)\n", | |||
| "gamma = torch.ones(x.shape[1])\n", | |||
| "beta = torch.zeros(x.shape[1])\n", | |||
| "print('before bn: ')\n", | |||
| "print(x)\n", | |||
| "y = simple_batch_norm_1d(x, gamma, beta)\n", | |||
| "print('after bn: ')\n", | |||
| "print(y)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到这里一共是 5 个数据点,三个特征,每一列表示一个特征的不同数据点,使用批标准化之后,每一列都变成了标准的正态分布\n", | |||
| "\n", | |||
| "这个时候会出现一个问题,就是测试的时候该使用批标准化吗?\n", | |||
| "\n", | |||
| "答案是肯定的,因为训练的时候使用了,而测试的时候不使用肯定会导致结果出现偏差,但是测试的时候如果只有一个数据集,那么均值不就是这个值,方差为 0 吗?这显然是随机的,所以测试的时候不能用测试的数据集去算均值和方差,而是用训练的时候算出的移动平均均值和方差去代替\n", | |||
| "\n", | |||
| "下面我们实现以下能够区分训练状态和测试状态的批标准化方法" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "metadata": { | |||
| "ExecuteTime": { | |||
| "end_time": "2017-12-23T07:32:48.025709Z", | |||
| "start_time": "2017-12-23T07:32:48.005892Z" | |||
| }, | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def batch_norm_1d(x, gamma, beta, is_training, moving_mean, moving_var, moving_momentum=0.1):\n", | |||
| " eps = 1e-5\n", | |||
| " x_mean = torch.mean(x, dim=0, keepdim=True) # 保留维度进行 broadcast\n", | |||
| " x_var = torch.mean((x - x_mean) ** 2, dim=0, keepdim=True)\n", | |||
| " if is_training:\n", | |||
| " x_hat = (x - x_mean) / torch.sqrt(x_var + eps)\n", | |||
| " moving_mean[:] = moving_momentum * moving_mean + (1. - moving_momentum) * x_mean\n", | |||
| " moving_var[:] = moving_momentum * moving_var + (1. - moving_momentum) * x_var\n", | |||
| " else:\n", | |||
| " x_hat = (x - moving_mean) / torch.sqrt(moving_var + eps)\n", | |||
| " return gamma.view_as(x_mean) * x_hat + beta.view_as(x_mean)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "下面我们使用上一节课将的深度神经网络分类 mnist 数据集的例子来试验一下批标准化是否有用" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import numpy as np\n", | |||
| "from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据\n", | |||
| "from torch.utils.data import DataLoader\n", | |||
| "from torch import nn\n", | |||
| "from torch.autograd import Variable" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 使用内置函数下载 mnist 数据集\n", | |||
| "train_set = mnist.MNIST('./data', train=True)\n", | |||
| "test_set = mnist.MNIST('./data', train=False)\n", | |||
| "\n", | |||
| "def data_tf(x):\n", | |||
| " x = np.array(x, dtype='float32') / 255\n", | |||
| " x = (x - 0.5) / 0.5 # 数据预处理,标准化\n", | |||
| " x = x.reshape((-1,)) # 拉平\n", | |||
| " x = torch.from_numpy(x)\n", | |||
| " return x\n", | |||
| "\n", | |||
| "train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换\n", | |||
| "test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True)\n", | |||
| "train_data = DataLoader(train_set, batch_size=64, shuffle=True)\n", | |||
| "test_data = DataLoader(test_set, batch_size=128, shuffle=False)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "class multi_network(nn.Module):\n", | |||
| " def __init__(self):\n", | |||
| " super(multi_network, self).__init__()\n", | |||
| " self.layer1 = nn.Linear(784, 100)\n", | |||
| " self.relu = nn.ReLU(True)\n", | |||
| " self.layer2 = nn.Linear(100, 10)\n", | |||
| " \n", | |||
| " self.gamma = nn.Parameter(torch.randn(100))\n", | |||
| " self.beta = nn.Parameter(torch.randn(100))\n", | |||
| " \n", | |||
| " self.moving_mean = Variable(torch.zeros(100))\n", | |||
| " self.moving_var = Variable(torch.zeros(100))\n", | |||
| " \n", | |||
| " def forward(self, x, is_train=True):\n", | |||
| " x = self.layer1(x)\n", | |||
| " x = batch_norm_1d(x, self.gamma, self.beta, is_train, self.moving_mean, self.moving_var)\n", | |||
| " x = self.relu(x)\n", | |||
| " x = self.layer2(x)\n", | |||
| " return x" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "net = multi_network()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 定义 loss 函数\n", | |||
| "criterion = nn.CrossEntropyLoss()\n", | |||
| "optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "为了方便,训练函数已经定义在外面的 utils.py 中,跟前面训练网络的操作是一样的,感兴趣的同学可以去看看" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 10, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Epoch 0. Train Loss: 0.308139, Train Acc: 0.912797, Valid Loss: 0.181375, Valid Acc: 0.948279, Time 00:00:07\n", | |||
| "Epoch 1. Train Loss: 0.174049, Train Acc: 0.949910, Valid Loss: 0.143940, Valid Acc: 0.958267, Time 00:00:09\n", | |||
| "Epoch 2. Train Loss: 0.134983, Train Acc: 0.961587, Valid Loss: 0.122489, Valid Acc: 0.963904, Time 00:00:08\n", | |||
| "Epoch 3. Train Loss: 0.111758, Train Acc: 0.968317, Valid Loss: 0.106595, Valid Acc: 0.966278, Time 00:00:09\n", | |||
| "Epoch 4. Train Loss: 0.096425, Train Acc: 0.971915, Valid Loss: 0.108423, Valid Acc: 0.967563, Time 00:00:10\n", | |||
| "Epoch 5. Train Loss: 0.084424, Train Acc: 0.974464, Valid Loss: 0.107135, Valid Acc: 0.969838, Time 00:00:09\n", | |||
| "Epoch 6. Train Loss: 0.076206, Train Acc: 0.977645, Valid Loss: 0.092725, Valid Acc: 0.971420, Time 00:00:09\n", | |||
| "Epoch 7. Train Loss: 0.069438, Train Acc: 0.979661, Valid Loss: 0.091497, Valid Acc: 0.971519, Time 00:00:09\n", | |||
| "Epoch 8. Train Loss: 0.062908, Train Acc: 0.980810, Valid Loss: 0.088797, Valid Acc: 0.972903, Time 00:00:08\n", | |||
| "Epoch 9. Train Loss: 0.058186, Train Acc: 0.982309, Valid Loss: 0.090830, Valid Acc: 0.972310, Time 00:00:08\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "from utils import train\n", | |||
| "train(net, train_data, test_data, 10, optimizer, criterion)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "这里的 $\\gamma$ 和 $\\beta$ 都作为参数进行训练,初始化为随机的高斯分布,`moving_mean` 和 `moving_var` 都初始化为 0,并不是更新的参数,训练完 10 次之后,我们可以看看移动平均和移动方差被修改为了多少" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "metadata": { | |||
| "scrolled": true | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Variable containing:\n", | |||
| " 0.5505\n", | |||
| " 2.0835\n", | |||
| " 0.0794\n", | |||
| "-0.1991\n", | |||
| "-0.9822\n", | |||
| "-0.5820\n", | |||
| " 0.6991\n", | |||
| "-0.1292\n", | |||
| " 2.9608\n", | |||
| " 1.0826\n", | |||
| "[torch.FloatTensor of size 10]\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "# 打出 moving_mean 的前 10 项\n", | |||
| "print(net.moving_mean[:10])" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到,这些值已经在训练的过程中进行了修改,在测试过程中,我们不需要再计算均值和方差,直接使用移动平均和移动方差即可" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "作为对比,我们看看不使用批标准化的结果" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 12, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Epoch 0. Train Loss: 0.402263, Train Acc: 0.873817, Valid Loss: 0.220468, Valid Acc: 0.932852, Time 00:00:07\n", | |||
| "Epoch 1. Train Loss: 0.181916, Train Acc: 0.945379, Valid Loss: 0.162440, Valid Acc: 0.953817, Time 00:00:08\n", | |||
| "Epoch 2. Train Loss: 0.136073, Train Acc: 0.958522, Valid Loss: 0.264888, Valid Acc: 0.918216, Time 00:00:08\n", | |||
| "Epoch 3. Train Loss: 0.111658, Train Acc: 0.966551, Valid Loss: 0.149704, Valid Acc: 0.950752, Time 00:00:08\n", | |||
| "Epoch 4. Train Loss: 0.096433, Train Acc: 0.970732, Valid Loss: 0.116364, Valid Acc: 0.963311, Time 00:00:07\n", | |||
| "Epoch 5. Train Loss: 0.083800, Train Acc: 0.973914, Valid Loss: 0.105775, Valid Acc: 0.968058, Time 00:00:08\n", | |||
| "Epoch 6. Train Loss: 0.074534, Train Acc: 0.977129, Valid Loss: 0.094511, Valid Acc: 0.970728, Time 00:00:08\n", | |||
| "Epoch 7. Train Loss: 0.067365, Train Acc: 0.979311, Valid Loss: 0.130495, Valid Acc: 0.960146, Time 00:00:09\n", | |||
| "Epoch 8. Train Loss: 0.061585, Train Acc: 0.980894, Valid Loss: 0.089632, Valid Acc: 0.974090, Time 00:00:08\n", | |||
| "Epoch 9. Train Loss: 0.055352, Train Acc: 0.982892, Valid Loss: 0.091508, Valid Acc: 0.970431, Time 00:00:08\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "no_bn_net = nn.Sequential(\n", | |||
| " nn.Linear(784, 100),\n", | |||
| " nn.ReLU(True),\n", | |||
| " nn.Linear(100, 10)\n", | |||
| ")\n", | |||
| "\n", | |||
| "optimizer = torch.optim.SGD(no_bn_net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1\n", | |||
| "train(no_bn_net, train_data, test_data, 10, optimizer, criterion)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "可以看到虽然最后的结果两种情况一样,但是如果我们看前几次的情况,可以看到使用批标准化的情况能够更快的收敛,因为这只是一个小网络,所以用不用批标准化都能够收敛,但是对于更加深的网络,使用批标准化在训练的时候能够很快地收敛" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "从上面可以看到,我们自己实现了 2 维情况的批标准化,对应于卷积的 4 维情况的标准化是类似的,只需要沿着通道的维度进行均值和方差的计算,但是我们自己实现批标准化是很累的,pytorch 当然也为我们内置了批标准化的函数,一维和二维分别是 `torch.nn.BatchNorm1d()` 和 `torch.nn.BatchNorm2d()`,不同于我们的实现,pytorch 不仅将 $\\gamma$ 和 $\\beta$ 作为训练的参数,也将 `moving_mean` 和 `moving_var` 也作为参数进行训练" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "下面我们在卷积网络下试用一下批标准化看看效果" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def data_tf(x):\n", | |||
| " x = np.array(x, dtype='float32') / 255\n", | |||
| " x = (x - 0.5) / 0.5 # 数据预处理,标准化\n", | |||
| " x = torch.from_numpy(x)\n", | |||
| " x = x.unsqueeze(0)\n", | |||
| " return x\n", | |||
| "\n", | |||
| "train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换\n", | |||
| "test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True)\n", | |||
| "train_data = DataLoader(train_set, batch_size=64, shuffle=True)\n", | |||
| "test_data = DataLoader(test_set, batch_size=128, shuffle=False)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 78, | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 使用批标准化\n", | |||
| "class conv_bn_net(nn.Module):\n", | |||
| " def __init__(self):\n", | |||
| " super(conv_bn_net, self).__init__()\n", | |||
| " self.stage1 = nn.Sequential(\n", | |||
| " nn.Conv2d(1, 6, 3, padding=1),\n", | |||
| " nn.BatchNorm2d(6),\n", | |||
| " nn.ReLU(True),\n", | |||
| " nn.MaxPool2d(2, 2),\n", | |||
| " nn.Conv2d(6, 16, 5),\n", | |||
| " nn.BatchNorm2d(16),\n", | |||
| " nn.ReLU(True),\n", | |||
| " nn.MaxPool2d(2, 2)\n", | |||
| " )\n", | |||
| " \n", | |||
| " self.classfy = nn.Linear(400, 10)\n", | |||
| " def forward(self, x):\n", | |||
| " x = self.stage1(x)\n", | |||
| " x = x.view(x.shape[0], -1)\n", | |||
| " x = self.classfy(x)\n", | |||
| " return x\n", | |||
| "\n", | |||
| "net = conv_bn_net()\n", | |||
| "optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 79, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Epoch 0. Train Loss: 0.160329, Train Acc: 0.952842, Valid Loss: 0.063328, Valid Acc: 0.978441, Time 00:00:33\n", | |||
| "Epoch 1. Train Loss: 0.067862, Train Acc: 0.979361, Valid Loss: 0.068229, Valid Acc: 0.979430, Time 00:00:37\n", | |||
| "Epoch 2. Train Loss: 0.051867, Train Acc: 0.984625, Valid Loss: 0.044616, Valid Acc: 0.985265, Time 00:00:37\n", | |||
| "Epoch 3. Train Loss: 0.044797, Train Acc: 0.986141, Valid Loss: 0.042711, Valid Acc: 0.986056, Time 00:00:38\n", | |||
| "Epoch 4. Train Loss: 0.039876, Train Acc: 0.987690, Valid Loss: 0.042499, Valid Acc: 0.985067, Time 00:00:41\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "train(net, train_data, test_data, 5, optimizer, criterion)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 76, | |||
| "metadata": { | |||
| "collapsed": true | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# 不使用批标准化\n", | |||
| "class conv_no_bn_net(nn.Module):\n", | |||
| " def __init__(self):\n", | |||
| " super(conv_no_bn_net, self).__init__()\n", | |||
| " self.stage1 = nn.Sequential(\n", | |||
| " nn.Conv2d(1, 6, 3, padding=1),\n", | |||
| " nn.ReLU(True),\n", | |||
| " nn.MaxPool2d(2, 2),\n", | |||
| " nn.Conv2d(6, 16, 5),\n", | |||
| " nn.ReLU(True),\n", | |||
| " nn.MaxPool2d(2, 2)\n", | |||
| " )\n", | |||
| " \n", | |||
| " self.classfy = nn.Linear(400, 10)\n", | |||
| " def forward(self, x):\n", | |||
| " x = self.stage1(x)\n", | |||
| " x = x.view(x.shape[0], -1)\n", | |||
| " x = self.classfy(x)\n", | |||
| " return x\n", | |||
| "\n", | |||
| "net = conv_no_bn_net()\n", | |||
| "optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1 " | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 77, | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "Epoch 0. Train Loss: 0.211075, Train Acc: 0.935934, Valid Loss: 0.062950, Valid Acc: 0.980123, Time 00:00:27\n", | |||
| "Epoch 1. Train Loss: 0.066763, Train Acc: 0.978778, Valid Loss: 0.050143, Valid Acc: 0.984375, Time 00:00:29\n", | |||
| "Epoch 2. Train Loss: 0.050870, Train Acc: 0.984292, Valid Loss: 0.039761, Valid Acc: 0.988034, Time 00:00:29\n", | |||
| "Epoch 3. Train Loss: 0.041476, Train Acc: 0.986924, Valid Loss: 0.041925, Valid Acc: 0.986155, Time 00:00:29\n", | |||
| "Epoch 4. Train Loss: 0.036118, Train Acc: 0.988523, Valid Loss: 0.042703, Valid Acc: 0.986452, Time 00:00:29\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "train(net, train_data, test_data, 5, optimizer, criterion)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "之后介绍一些著名的网络结构的时候,我们会慢慢认识到批标准化的重要性,使用 pytorch 能够非常方便地添加批标准化层" | |||
| ] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python 3", | |||
| "language": "python", | |||
| "name": "python3" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.5.2" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 2 | |||
| } | |||
+ 257
- 0
2_pytorch/2_CNN/batch-normalization.py
View File
| @@ -0,0 +1,257 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # 批标准化 | |||
| # 在我们正式进入模型的构建和训练之前,我们会先讲一讲数据预处理和批标准化,因为模型训练并不容易,特别是一些非常复杂的模型,并不能非常好的训练得到收敛的结果,所以对数据增加一些预处理,同时使用批标准化能够得到非常好的收敛结果,这也是卷积网络能够训练到非常深的层的一个重要原因。 | |||
| # ## 数据预处理 | |||
| # 目前数据预处理最常见的方法就是中心化和标准化,中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征。标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间,下面是一个简单的图示 | |||
| # | |||
| #  | |||
| # | |||
| # 这两种方法非常的常见,如果你还记得,前面我们在神经网络的部分就已经使用了这个方法实现了数据标准化,至于另外一些方法,比如 PCA 或者 白噪声已经用得非常少了。 | |||
| # ## Batch Normalization | |||
| # 前面在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好。但是对于很深的网路结构,网路的非线性层会使得输出的结果变得相关,且不再满足一个标准的 N(0, 1) 的分布,甚至输出的中心已经发生了偏移,这对于模型的训练,特别是深层的模型训练非常的困难。 | |||
| # | |||
| # 所以在 2015 年一篇论文提出了这个方法,批标准化,简而言之,就是对于每一层网络的输出,对其做一个归一化,使其服从标准的正态分布,这样后一层网络的输入也是一个标准的正态分布,所以能够比较好的进行训练,加快收敛速度。 | |||
| # batch normalization 的实现非常简单,对于给定的一个 batch 的数据 $B = \{x_1, x_2, \cdots, x_m\}$算法的公式如下 | |||
| # | |||
| # $$ | |||
| # \mu_B = \frac{1}{m} \sum_{i=1}^m x_i | |||
| # $$ | |||
| # $$ | |||
| # \sigma^2_B = \frac{1}{m} \sum_{i=1}^m (x_i - \mu_B)^2 | |||
| # $$ | |||
| # $$ | |||
| # \hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma^2_B + \epsilon}} | |||
| # $$ | |||
| # $$ | |||
| # y_i = \gamma \hat{x}_i + \beta | |||
| # $$ | |||
| # 第一行和第二行是计算出一个 batch 中数据的均值和方差,接着使用第三个公式对 batch 中的每个数据点做标准化,$\epsilon$ 是为了计算稳定引入的一个小的常数,通常取 $10^{-5}$,最后利用权重修正得到最后的输出结果,非常的简单,下面我们可以实现一下简单的一维的情况,也就是神经网络中的情况 | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T06:50:51.575693Z", "end_time": "2017-12-23T06:50:51.579067Z"}} | |||
| import sys | |||
| sys.path.append('..') | |||
| import torch | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T07:14:11.060849Z", "end_time": "2017-12-23T07:14:11.077807Z"}} | |||
| def simple_batch_norm_1d(x, gamma, beta): | |||
| eps = 1e-5 | |||
| x_mean = torch.mean(x, dim=0, keepdim=True) # 保留维度进行 broadcast | |||
| x_var = torch.mean((x - x_mean) ** 2, dim=0, keepdim=True) | |||
| x_hat = (x - x_mean) / torch.sqrt(x_var + eps) | |||
| return gamma.view_as(x_mean) * x_hat + beta.view_as(x_mean) | |||
| # - | |||
| # 我们来验证一下是否对于任意的输入,输出会被标准化 | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T07:14:20.597682Z", "end_time": "2017-12-23T07:14:20.610603Z"}} | |||
| x = torch.arange(15).view(5, 3) | |||
| gamma = torch.ones(x.shape[1]) | |||
| beta = torch.zeros(x.shape[1]) | |||
| print('before bn: ') | |||
| print(x) | |||
| y = simple_batch_norm_1d(x, gamma, beta) | |||
| print('after bn: ') | |||
| print(y) | |||
| # - | |||
| # 可以看到这里一共是 5 个数据点,三个特征,每一列表示一个特征的不同数据点,使用批标准化之后,每一列都变成了标准的正态分布 | |||
| # | |||
| # 这个时候会出现一个问题,就是测试的时候该使用批标准化吗? | |||
| # | |||
| # 答案是肯定的,因为训练的时候使用了,而测试的时候不使用肯定会导致结果出现偏差,但是测试的时候如果只有一个数据集,那么均值不就是这个值,方差为 0 吗?这显然是随机的,所以测试的时候不能用测试的数据集去算均值和方差,而是用训练的时候算出的移动平均均值和方差去代替 | |||
| # | |||
| # 下面我们实现以下能够区分训练状态和测试状态的批标准化方法 | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T07:32:48.005892Z", "end_time": "2017-12-23T07:32:48.025709Z"}} | |||
| def batch_norm_1d(x, gamma, beta, is_training, moving_mean, moving_var, moving_momentum=0.1): | |||
| eps = 1e-5 | |||
| x_mean = torch.mean(x, dim=0, keepdim=True) # 保留维度进行 broadcast | |||
| x_var = torch.mean((x - x_mean) ** 2, dim=0, keepdim=True) | |||
| if is_training: | |||
| x_hat = (x - x_mean) / torch.sqrt(x_var + eps) | |||
| moving_mean[:] = moving_momentum * moving_mean + (1. - moving_momentum) * x_mean | |||
| moving_var[:] = moving_momentum * moving_var + (1. - moving_momentum) * x_var | |||
| else: | |||
| x_hat = (x - moving_mean) / torch.sqrt(moving_var + eps) | |||
| return gamma.view_as(x_mean) * x_hat + beta.view_as(x_mean) | |||
| # - | |||
| # 下面我们使用上一节课将的深度神经网络分类 mnist 数据集的例子来试验一下批标准化是否有用 | |||
| import numpy as np | |||
| from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据 | |||
| from torch.utils.data import DataLoader | |||
| from torch import nn | |||
| from torch.autograd import Variable | |||
| # + | |||
| # 使用内置函数下载 mnist 数据集 | |||
| train_set = mnist.MNIST('./data', train=True) | |||
| test_set = mnist.MNIST('./data', train=False) | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 | |||
| x = (x - 0.5) / 0.5 # 数据预处理,标准化 | |||
| x = x.reshape((-1,)) # 拉平 | |||
| x = torch.from_numpy(x) | |||
| return x | |||
| train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换 | |||
| test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True) | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| test_data = DataLoader(test_set, batch_size=128, shuffle=False) | |||
| # - | |||
| class multi_network(nn.Module): | |||
| def __init__(self): | |||
| super(multi_network, self).__init__() | |||
| self.layer1 = nn.Linear(784, 100) | |||
| self.relu = nn.ReLU(True) | |||
| self.layer2 = nn.Linear(100, 10) | |||
| self.gamma = nn.Parameter(torch.randn(100)) | |||
| self.beta = nn.Parameter(torch.randn(100)) | |||
| self.moving_mean = Variable(torch.zeros(100)) | |||
| self.moving_var = Variable(torch.zeros(100)) | |||
| def forward(self, x, is_train=True): | |||
| x = self.layer1(x) | |||
| x = batch_norm_1d(x, self.gamma, self.beta, is_train, self.moving_mean, self.moving_var) | |||
| x = self.relu(x) | |||
| x = self.layer2(x) | |||
| return x | |||
| net = multi_network() | |||
| # 定义 loss 函数 | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1 | |||
| # 为了方便,训练函数已经定义在外面的 utils.py 中,跟前面训练网络的操作是一样的,感兴趣的同学可以去看看 | |||
| from utils import train | |||
| train(net, train_data, test_data, 10, optimizer, criterion) | |||
| # 这里的 $\gamma$ 和 $\beta$ 都作为参数进行训练,初始化为随机的高斯分布,`moving_mean` 和 `moving_var` 都初始化为 0,并不是更新的参数,训练完 10 次之后,我们可以看看移动平均和移动方差被修改为了多少 | |||
| # + {"scrolled": true} | |||
| # 打出 moving_mean 的前 10 项 | |||
| print(net.moving_mean[:10]) | |||
| # - | |||
| # 可以看到,这些值已经在训练的过程中进行了修改,在测试过程中,我们不需要再计算均值和方差,直接使用移动平均和移动方差即可 | |||
| # 作为对比,我们看看不使用批标准化的结果 | |||
| # + | |||
| no_bn_net = nn.Sequential( | |||
| nn.Linear(784, 100), | |||
| nn.ReLU(True), | |||
| nn.Linear(100, 10) | |||
| ) | |||
| optimizer = torch.optim.SGD(no_bn_net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1 | |||
| train(no_bn_net, train_data, test_data, 10, optimizer, criterion) | |||
| # - | |||
| # 可以看到虽然最后的结果两种情况一样,但是如果我们看前几次的情况,可以看到使用批标准化的情况能够更快的收敛,因为这只是一个小网络,所以用不用批标准化都能够收敛,但是对于更加深的网络,使用批标准化在训练的时候能够很快地收敛 | |||
| # 从上面可以看到,我们自己实现了 2 维情况的批标准化,对应于卷积的 4 维情况的标准化是类似的,只需要沿着通道的维度进行均值和方差的计算,但是我们自己实现批标准化是很累的,pytorch 当然也为我们内置了批标准化的函数,一维和二维分别是 `torch.nn.BatchNorm1d()` 和 `torch.nn.BatchNorm2d()`,不同于我们的实现,pytorch 不仅将 $\gamma$ 和 $\beta$ 作为训练的参数,也将 `moving_mean` 和 `moving_var` 也作为参数进行训练 | |||
| # 下面我们在卷积网络下试用一下批标准化看看效果 | |||
| # + | |||
| def data_tf(x): | |||
| x = np.array(x, dtype='float32') / 255 | |||
| x = (x - 0.5) / 0.5 # 数据预处理,标准化 | |||
| x = torch.from_numpy(x) | |||
| x = x.unsqueeze(0) | |||
| return x | |||
| train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换 | |||
| test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True) | |||
| train_data = DataLoader(train_set, batch_size=64, shuffle=True) | |||
| test_data = DataLoader(test_set, batch_size=128, shuffle=False) | |||
| # + | |||
| # 使用批标准化 | |||
| class conv_bn_net(nn.Module): | |||
| def __init__(self): | |||
| super(conv_bn_net, self).__init__() | |||
| self.stage1 = nn.Sequential( | |||
| nn.Conv2d(1, 6, 3, padding=1), | |||
| nn.BatchNorm2d(6), | |||
| nn.ReLU(True), | |||
| nn.MaxPool2d(2, 2), | |||
| nn.Conv2d(6, 16, 5), | |||
| nn.BatchNorm2d(16), | |||
| nn.ReLU(True), | |||
| nn.MaxPool2d(2, 2) | |||
| ) | |||
| self.classfy = nn.Linear(400, 10) | |||
| def forward(self, x): | |||
| x = self.stage1(x) | |||
| x = x.view(x.shape[0], -1) | |||
| x = self.classfy(x) | |||
| return x | |||
| net = conv_bn_net() | |||
| optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1 | |||
| # - | |||
| train(net, train_data, test_data, 5, optimizer, criterion) | |||
| # + | |||
| # 不使用批标准化 | |||
| class conv_no_bn_net(nn.Module): | |||
| def __init__(self): | |||
| super(conv_no_bn_net, self).__init__() | |||
| self.stage1 = nn.Sequential( | |||
| nn.Conv2d(1, 6, 3, padding=1), | |||
| nn.ReLU(True), | |||
| nn.MaxPool2d(2, 2), | |||
| nn.Conv2d(6, 16, 5), | |||
| nn.ReLU(True), | |||
| nn.MaxPool2d(2, 2) | |||
| ) | |||
| self.classfy = nn.Linear(400, 10) | |||
| def forward(self, x): | |||
| x = self.stage1(x) | |||
| x = x.view(x.shape[0], -1) | |||
| x = self.classfy(x) | |||
| return x | |||
| net = conv_no_bn_net() | |||
| optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用随机梯度下降,学习率 0.1 | |||
| # - | |||
| train(net, train_data, test_data, 5, optimizer, criterion) | |||
| # 之后介绍一些著名的网络结构的时候,我们会慢慢认识到批标准化的重要性,使用 pytorch 能够非常方便地添加批标准化层 | |||
BIN
2_pytorch/2_CNN/cat.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 224 | Height: 224 | Size: 97 kB |
+ 611
- 0
2_pytorch/2_CNN/data-augumentation.ipynb
File diff suppressed because it is too large
View File
+ 204
- 0
2_pytorch/2_CNN/data-augumentation.py
View File
| @@ -0,0 +1,204 @@ | |||
| # -*- coding: utf-8 -*- | |||
| # --- | |||
| # jupyter: | |||
| # jupytext_format_version: '1.2' | |||
| # kernelspec: | |||
| # display_name: Python 3 | |||
| # language: python | |||
| # name: python3 | |||
| # language_info: | |||
| # codemirror_mode: | |||
| # name: ipython | |||
| # version: 3 | |||
| # file_extension: .py | |||
| # mimetype: text/x-python | |||
| # name: python | |||
| # nbconvert_exporter: python | |||
| # pygments_lexer: ipython3 | |||
| # version: 3.5.2 | |||
| # --- | |||
| # # 数据增强 | |||
| # 前面我们已经讲了几个非常著名的卷积网络的结构,但是单单只靠这些网络并不能取得 state-of-the-art 的结果,现实问题往往更加复杂,非常容易出现过拟合的问题,而数据增强的方法是对抗过拟合问题的一个重要方法。 | |||
| # | |||
| # 2012 年 AlexNet 在 ImageNet 上大获全胜,图片增强方法功不可没,因为有了图片增强,使得训练的数据集比实际数据集多了很多'新'样本,减少了过拟合的问题,下面我们来具体解释一下。 | |||
| # ## 常用的数据增强方法 | |||
| # 常用的数据增强方法如下: | |||
| # 1.对图片进行一定比例缩放 | |||
| # 2.对图片进行随机位置的截取 | |||
| # 3.对图片进行随机的水平和竖直翻转 | |||
| # 4.对图片进行随机角度的旋转 | |||
| # 5.对图片进行亮度、对比度和颜色的随机变化 | |||
| # | |||
| # 这些方法 pytorch 都已经为我们内置在了 torchvision 里面,我们在安装 pytorch 的时候也安装了 torchvision,下面我们来依次展示一下这些数据增强方法 | |||
| # + | |||
| import sys | |||
| sys.path.append('..') | |||
| from PIL import Image | |||
| from torchvision import transforms as tfs | |||
| # - | |||
| # 读入一张图片 | |||
| im = Image.open('./cat.png') | |||
| im | |||
| # ### 随机比例放缩 | |||
| # 随机比例缩放主要使用的是 `torchvision.transforms.Resize()` 这个函数,第一个参数可以是一个整数,那么图片会保存现在的宽和高的比例,并将更短的边缩放到这个整数的大小,第一个参数也可以是一个 tuple,那么图片会直接把宽和高缩放到这个大小;第二个参数表示放缩图片使用的方法,比如最邻近法,或者双线性差值等,一般双线性差值能够保留图片更多的信息,所以 pytorch 默认使用的是双线性差值,你可以手动去改这个参数,更多的信息可以看看[文档](http://pytorch.org/docs/0.3.0/torchvision/transforms.html) | |||
| # 比例缩放 | |||
| print('before scale, shape: {}'.format(im.size)) | |||
| new_im = tfs.Resize((100, 200))(im) | |||
| print('after scale, shape: {}'.format(new_im.size)) | |||
| new_im | |||
| # ### 随机位置截取 | |||
| # 随机位置截取能够提取出图片中局部的信息,使得网络接受的输入具有多尺度的特征,所以能够有较好的效果。在 torchvision 中主要有下面两种方式,一个是 `torchvision.transforms.RandomCrop()`,传入的参数就是截取出的图片的长和宽,对图片在随机位置进行截取;第二个是 `torchvision.transforms.CenterCrop()`,同样传入介曲初的图片的大小作为参数,会在图片的中心进行截取 | |||
| # 随机裁剪出 100 x 100 的区域 | |||
| random_im1 = tfs.RandomCrop(100)(im) | |||
| random_im1 | |||
| # 随机裁剪出 150 x 100 的区域 | |||
| random_im2 = tfs.RandomCrop((150, 100))(im) | |||
| random_im2 | |||
| # 中心裁剪出 100 x 100 的区域 | |||
| center_im = tfs.CenterCrop(100)(im) | |||
| center_im | |||
| # ### 随机的水平和竖直方向翻转 | |||
| # 对于上面这一张猫的图片,如果我们将它翻转一下,它仍然是一张猫,但是图片就有了更多的多样性,所以随机翻转也是一种非常有效的手段。在 torchvision 中,随机翻转使用的是 `torchvision.transforms.RandomHorizontalFlip()` 和 `torchvision.transforms.RandomVerticalFlip()` | |||
| # 随机水平翻转 | |||
| h_filp = tfs.RandomHorizontalFlip()(im) | |||
| h_filp | |||
| # 随机竖直翻转 | |||
| v_flip = tfs.RandomVerticalFlip()(im) | |||
| v_flip | |||
| # ### 随机角度旋转 | |||
| # 一些角度的旋转仍然是非常有用的数据增强方式,在 torchvision 中,使用 `torchvision.transforms.RandomRotation()` 来实现,其中第一个参数就是随机旋转的角度,比如填入 10,那么每次图片就会在 -10 ~ 10 度之间随机旋转 | |||
| rot_im = tfs.RandomRotation(45)(im) | |||
| rot_im | |||
| # ### 亮度、对比度和颜色的变化 | |||
| # 除了形状变化外,颜色变化又是另外一种增强方式,其中可以设置亮度变化,对比度变化和颜色变化等,在 torchvision 中主要使用 `torchvision.transforms.ColorJitter()` 来实现的,第一个参数就是亮度的比例,第二个是对比度,第三个是饱和度,第四个是颜色 | |||
| # 亮度 | |||
| bright_im = tfs.ColorJitter(brightness=1)(im) # 随机从 0 ~ 2 之间亮度变化,1 表示原图 | |||
| bright_im | |||
| # 对比度 | |||
| contrast_im = tfs.ColorJitter(contrast=1)(im) # 随机从 0 ~ 2 之间对比度变化,1 表示原图 | |||
| contrast_im | |||
| # 颜色 | |||
| color_im = tfs.ColorJitter(hue=0.5)(im) # 随机从 -0.5 ~ 0.5 之间对颜色变化 | |||
| color_im | |||
| # | |||
| # | |||
| # 上面我们讲了这么图片增强的方法,其实这些方法都不是孤立起来用的,可以联合起来用,比如先做随机翻转,然后随机截取,再做对比度增强等等,torchvision 里面有个非常方便的函数能够将这些变化合起来,就是 `torchvision.transforms.Compose()`,下面我们举个例子 | |||
| im_aug = tfs.Compose([ | |||
| tfs.Resize(120), | |||
| tfs.RandomHorizontalFlip(), | |||
| tfs.RandomCrop(96), | |||
| tfs.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5) | |||
| ]) | |||
| import matplotlib.pyplot as plt | |||
| # %matplotlib inline | |||
| nrows = 3 | |||
| ncols = 3 | |||
| figsize = (8, 8) | |||
| _, figs = plt.subplots(nrows, ncols, figsize=figsize) | |||
| for i in range(nrows): | |||
| for j in range(ncols): | |||
| figs[i][j].imshow(im_aug(im)) | |||
| figs[i][j].axes.get_xaxis().set_visible(False) | |||
| figs[i][j].axes.get_yaxis().set_visible(False) | |||
| plt.show() | |||
| # 可以看到每次做完增强之后的图片都有一些变化,所以这就是我们前面讲的,增加了一些'新'数据 | |||
| # | |||
| # 下面我们使用图像增强进行训练网络,看看具体的提升究竟在什么地方,使用前面讲的 ResNet 进行训练 | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T05:04:02.920639Z", "end_time": "2017-12-23T05:04:03.407434Z"}} | |||
| import numpy as np | |||
| import torch | |||
| from torch import nn | |||
| import torch.nn.functional as F | |||
| from torch.autograd import Variable | |||
| from torchvision.datasets import CIFAR10 | |||
| from utils import train, resnet | |||
| from torchvision import transforms as tfs | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T05:04:03.459562Z", "end_time": "2017-12-23T05:04:04.743167Z"}} | |||
| # 使用数据增强 | |||
| def train_tf(x): | |||
| im_aug = tfs.Compose([ | |||
| tfs.Resize(120), | |||
| tfs.RandomHorizontalFlip(), | |||
| tfs.RandomCrop(96), | |||
| tfs.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5), | |||
| tfs.ToTensor(), | |||
| tfs.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) | |||
| ]) | |||
| x = im_aug(x) | |||
| return x | |||
| def test_tf(x): | |||
| im_aug = tfs.Compose([ | |||
| tfs.Resize(96), | |||
| tfs.ToTensor(), | |||
| tfs.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) | |||
| ]) | |||
| x = im_aug(x) | |||
| return x | |||
| train_set = CIFAR10('./data', train=True, transform=train_tf) | |||
| train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True) | |||
| test_set = CIFAR10('./data', train=False, transform=test_tf) | |||
| test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False) | |||
| net = resnet(3, 10) | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01) | |||
| criterion = nn.CrossEntropyLoss() | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T05:04:04.745540Z", "end_time": "2017-12-23T05:08:51.433955Z"}} | |||
| train(net, train_data, test_data, 10, optimizer, criterion) | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T05:09:21.756986Z", "end_time": "2017-12-23T05:09:22.997927Z"}} | |||
| # 不使用数据增强 | |||
| def data_tf(x): | |||
| im_aug = tfs.Compose([ | |||
| tfs.Resize(96), | |||
| tfs.ToTensor(), | |||
| tfs.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) | |||
| ]) | |||
| x = im_aug(x) | |||
| return x | |||
| train_set = CIFAR10('./data', train=True, transform=data_tf) | |||
| train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True) | |||
| test_set = CIFAR10('./data', train=False, transform=data_tf) | |||
| test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False) | |||
| net = resnet(3, 10) | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01) | |||
| criterion = nn.CrossEntropyLoss() | |||
| # + {"ExecuteTime": {"start_time": "2017-12-23T05:09:23.000573Z", "end_time": "2017-12-23T05:13:57.898751Z"}} | |||
| train(net, train_data, test_data, 10, optimizer, criterion) | |||
| # - | |||
| # 从上面可以看出,对于训练集,不做数据增强跑 10 次,准确率已经到了 95%,而使用了数据增强,跑 10 次准确率只有 75%,说明数据增强之后变得更难了。 | |||
| # | |||
| # 而对于测试集,使用数据增强进行训练的时候,准确率会比不使用更高,因为数据增强提高了模型应对于更多的不同数据集的泛化能力,所以有更好的效果。 | |||