 bushuhui
3 years ago
bushuhui
3 years ago
19 changed files with 1140 additions and 268 deletions
Unified View
Diff Options
-
+28 -264_logistic_regression/1-Least_squares.ipynb
-
+968 -04_logistic_regression/ls.ipynb
-
BIN4_logistic_regression/missle_est.pdf
-
BIN4_logistic_regression/missle_taj.pdf
-
BIN4_logistic_regression/sklearn_linear_fitting.pdf
-
+17 -97_deep_learning/1_CNN/1-basic_conv.ipynb
-
+18 -97_deep_learning/1_CNN/2-vgg.ipynb
-
+28 -137_deep_learning/1_CNN/3-googlenet.ipynb
-
+28 -207_deep_learning/1_CNN/4-data-augumentation.ipynb
-
+0 -1517_deep_learning/1_CNN/4-regularization.ipynb
-
+0 -07_deep_learning/1_CNN/4-resnet.ipynb
-
+0 -07_deep_learning/1_CNN/5-densenet.ipynb
-
+42 -237_deep_learning/1_CNN/6-batch-normalization.ipynb
-
+10 -167_deep_learning/1_CNN/7-lr-decay.ipynb
-
+1 -17_deep_learning/1_CNN/8-regularization.ipynb
-
+0 -07_deep_learning/1_CNN/9-data-augumentation.ipynb
-
BIN7_deep_learning/1_CNN/CNN_Introduction.pptx
-
BIN7_deep_learning/1_CNN/images/inception2_improved.jpeg
-
BIN7_deep_learning/1_CNN/images/inception2_naive.jpeg
+ 28
- 26
4_logistic_regression/1-Least_squares.ipynb
File diff suppressed because it is too large
View File
+ 968
- 0
4_logistic_regression/ls.ipynb
File diff suppressed because it is too large
View File
BIN
4_logistic_regression/missle_est.pdf
View File
BIN
4_logistic_regression/missle_taj.pdf
View File
BIN
4_logistic_regression/sklearn_linear_fitting.pdf
View File
+ 17
- 9
7_deep_learning/1_CNN/1-basic_conv.ipynb
View File
| @@ -12,10 +12,10 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "## 卷积\n", | |||||
| "卷积在 pytorch 中有两种方式,一种是 `torch.nn.Conv2d()`,一种是 `torch.nn.functional.conv2d()`,这两种形式本质都是使用一个卷积操作\n", | |||||
| "## 1. 卷积\n", | |||||
| "卷积在 PyTorch 中有两种方式,一种是 `torch.nn.Conv2d()`,一种是 `torch.nn.functional.conv2d()`,这两种形式本质都是使用一个卷积操作。\n", | |||||
| "\n", | "\n", | ||||
| "这两种形式的卷积对于输入的要求都是一样的,首先需要输入是一个 `torch.autograd.Variable()` 的类型,大小是 (batch, channel, H, W),其中 batch 表示输入的一批数据的数目,第二个是输入的通道数,一般一张彩色的图片是 3,灰度图是 1,而卷积网络过程中的通道数比较大,会出现几十到几百的通道数,H 和 W 表示输入图片的高度和宽度,比如一个 batch 是 32 张图片,每张图片是 3 通道,高和宽分别是 50 和 100,那么输入的大小就是 (32, 3, 50, 100)\n", | |||||
| "这两种形式的卷积对于输入的要求都是一样的,首先需要输入是一个 `torch.autograd.Variable()` 的类型,大小是 `(batch, channel, H, W)`,其中 `batch` 表示输入的一批数据的数目,第二个是输入的通道数,一般一张彩色的图片是 3,灰度图是 1,而卷积网络过程中的通道数比较大,会出现几十到几百的通道数,`H` 和 `W` 表示输入图片的高度和宽度,比如一个 `batch` 是 32 张图片,每张图片是 3 通道,高和宽分别是 50 和 100,那么输入的大小就是 `(32, 3, 50, 100)`\n", | |||||
| "\n", | "\n", | ||||
| "下面举例来说明一下这两种卷积方式" | "下面举例来说明一下这两种卷积方式" | ||||
| ] | ] | ||||
| @@ -23,7 +23,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 1, | "execution_count": 1, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "import numpy as np\n", | "import numpy as np\n", | ||||
| @@ -39,7 +41,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 2, | "execution_count": 2, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "im = Image.open('./cat.png').convert('L') # 读入一张灰度图的图片\n", | "im = Image.open('./cat.png').convert('L') # 读入一张灰度图的图片\n", | ||||
| @@ -82,7 +86,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 4, | "execution_count": 4, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "# 将图片矩阵转化为 pytorch tensor,并适配卷积输入的要求\n", | "# 将图片矩阵转化为 pytorch tensor,并适配卷积输入的要求\n", | ||||
| @@ -99,7 +105,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 6, | "execution_count": 6, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "# 使用 nn.Conv2d\n", | "# 使用 nn.Conv2d\n", | ||||
| @@ -204,7 +212,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "## 池化层\n", | |||||
| "## 2. 池化层\n", | |||||
| "卷积网络中另外一个非常重要的结构就是池化,这是利用了图片的下采样不变性,即一张图片变小了还是能够看出了这张图片的内容,而使用池化层能够将图片大小降低,非常好地提高了计算效率,同时池化层也没有参数。池化的方式有很多种,比如最大值池化,均值池化等等,在卷积网络中一般使用最大值池化。\n", | "卷积网络中另外一个非常重要的结构就是池化,这是利用了图片的下采样不变性,即一张图片变小了还是能够看出了这张图片的内容,而使用池化层能够将图片大小降低,非常好地提高了计算效率,同时池化层也没有参数。池化的方式有很多种,比如最大值池化,均值池化等等,在卷积网络中一般使用最大值池化。\n", | ||||
| "\n", | "\n", | ||||
| "在 pytorch 中最大值池化的方式也有两种,一种是 `nn.MaxPool2d()`,一种是 `torch.nn.functional.max_pool2d()`,他们对于图片的输入要求跟卷积对于图片的输入要求是一样了,就不再赘述,下面我们也举例说明" | "在 pytorch 中最大值池化的方式也有两种,一种是 `nn.MaxPool2d()`,一种是 `torch.nn.functional.max_pool2d()`,他们对于图片的输入要求跟卷积对于图片的输入要求是一样了,就不再赘述,下面我们也举例说明" | ||||
| @@ -355,7 +363,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.7.9" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
7_deep_learning/1_CNN/6-vgg.ipynb → 7_deep_learning/1_CNN/2-vgg.ipynb
View File
| @@ -5,8 +5,13 @@ | |||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "# VGG\n", | "# VGG\n", | ||||
| "计算机视觉是一直深度学习的主战场,从这里我们将接触到近几年非常流行的卷积网络结构,网络结构由浅变深,参数越来越多,网络有着更多的跨层链接,首先我们先介绍一个数据集 cifar10,我们将以此数据集为例介绍各种卷积网络的结构。\n", | |||||
| "\n", | |||||
| "计算机视觉是一直深度学习的主战场,从这里我们将接触到近几年非常流行的卷积网络结构,网络结构由浅变深,参数越来越多,网络有着更多的跨层链接,首先我们先介绍一个数据集 cifar10,我们将以此数据集为例介绍各种卷积网络的结构。\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "## CIFAR 10\n", | "## CIFAR 10\n", | ||||
| "cifar 10 这个数据集一共有 50000 张训练集,10000 张测试集,两个数据集里面的图片都是 png 彩色图片,图片大小是 32 x 32 x 3,一共是 10 分类问题,分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。这个数据集是对网络性能测试一个非常重要的指标,可以说如果一个网络在这个数据集上超过另外一个网络,那么这个网络性能上一定要比另外一个网络好,目前这个数据集最好的结果是 95% 左右的测试集准确率。\n", | "cifar 10 这个数据集一共有 50000 张训练集,10000 张测试集,两个数据集里面的图片都是 png 彩色图片,图片大小是 32 x 32 x 3,一共是 10 分类问题,分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。这个数据集是对网络性能测试一个非常重要的指标,可以说如果一个网络在这个数据集上超过另外一个网络,那么这个网络性能上一定要比另外一个网络好,目前这个数据集最好的结果是 95% 左右的测试集准确率。\n", | ||||
| "\n", | "\n", | ||||
| @@ -40,7 +45,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-22T09:01:51.296457Z", | "end_time": "2017-12-22T09:01:51.296457Z", | ||||
| "start_time": "2017-12-22T09:01:50.883050Z" | "start_time": "2017-12-22T09:01:50.883050Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -68,7 +74,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-22T09:01:51.312500Z", | "end_time": "2017-12-22T09:01:51.312500Z", | ||||
| "start_time": "2017-12-22T09:01:51.298777Z" | "start_time": "2017-12-22T09:01:51.298777Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -162,7 +169,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-22T09:01:54.497712Z", | "end_time": "2017-12-22T09:01:54.497712Z", | ||||
| "start_time": "2017-12-22T09:01:54.489255Z" | "start_time": "2017-12-22T09:01:54.489255Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -292,7 +300,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-22T09:01:57.323034Z", | "end_time": "2017-12-22T09:01:57.323034Z", | ||||
| "start_time": "2017-12-22T09:01:57.306864Z" | "start_time": "2017-12-22T09:01:57.306864Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -342,7 +351,7 @@ | |||||
| " \n", | " \n", | ||||
| "train_set = CIFAR10('../../data', train=True, transform=data_tf)\n", | "train_set = CIFAR10('../../data', train=True, transform=data_tf)\n", | ||||
| "train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)\n", | "train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)\n", | ||||
| "test_set = CIFAR10('../../data', train=False, transform=data_tf)\n", | |||||
| "test_set = CIFAR10('../../data', train=False, transform=data_tf)\n", | |||||
| "test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)\n", | "test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)\n", | ||||
| "\n", | "\n", | ||||
| "net = vgg()\n", | "net = vgg()\n", | ||||
| @@ -401,7 +410,7 @@ | |||||
| ], | ], | ||||
| "metadata": { | "metadata": { | ||||
| "kernelspec": { | "kernelspec": { | ||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "display_name": "Python 3", | |||||
| "language": "python", | "language": "python", | ||||
| "name": "python3" | "name": "python3" | ||||
| }, | }, | ||||
| @@ -415,7 +424,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.9.7" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
7_deep_learning/1_CNN/7-googlenet.ipynb → 7_deep_learning/1_CNN/3-googlenet.ipynb
View File
| @@ -7,7 +7,7 @@ | |||||
| "# GoogLeNet\n", | "# GoogLeNet\n", | ||||
| "前面我们讲的 VGG 是 2014 年 ImageNet 比赛的亚军,那么冠军是谁呢?就是我们马上要讲的 GoogLeNet,这是 Google 的研究人员提出的网络结构,在当时取得了非常大的影响,因为网络的结构变得前所未有,它颠覆了大家对卷积网络的串联的印象和固定做法,采用了一种非常有效的 inception 模块,得到了比 VGG 更深的网络结构,但是却比 VGG 的参数更少,因为其去掉了后面的全连接层,所以参数大大减少,同时有了很高的计算效率。\n", | "前面我们讲的 VGG 是 2014 年 ImageNet 比赛的亚军,那么冠军是谁呢?就是我们马上要讲的 GoogLeNet,这是 Google 的研究人员提出的网络结构,在当时取得了非常大的影响,因为网络的结构变得前所未有,它颠覆了大家对卷积网络的串联的印象和固定做法,采用了一种非常有效的 inception 模块,得到了比 VGG 更深的网络结构,但是却比 VGG 的参数更少,因为其去掉了后面的全连接层,所以参数大大减少,同时有了很高的计算效率。\n", | ||||
| "\n", | "\n", | ||||
| "\n", | |||||
| "\n", | |||||
| "\n", | "\n", | ||||
| "这是 googlenet 的网络示意图,下面我们介绍一下其作为创新的 inception 模块。" | "这是 googlenet 的网络示意图,下面我们介绍一下其作为创新的 inception 模块。" | ||||
| ] | ] | ||||
| @@ -27,10 +27,10 @@ | |||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
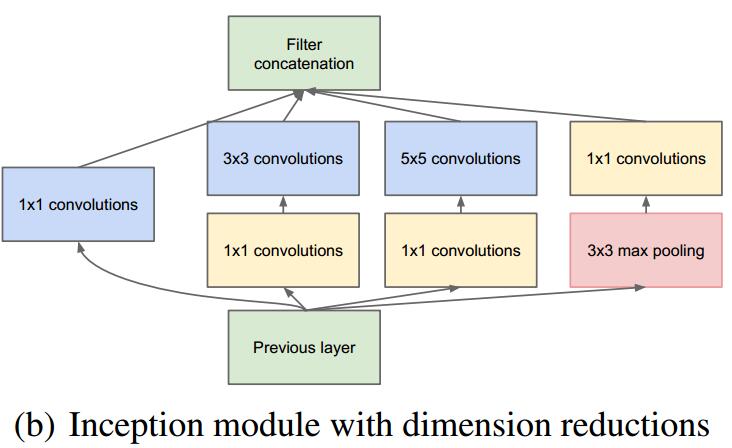
| "一个 inception 模块的四个并行线路如下:\n", | "一个 inception 模块的四个并行线路如下:\n", | ||||
| "1.一个 1 x 1 的卷积,一个小的感受野进行卷积提取特征\n", | |||||
| "2.一个 1 x 1 的卷积加上一个 3 x 3 的卷积,1 x 1 的卷积降低输入的特征通道,减少参数计算量,然后接一个 3 x 3 的卷积做一个较大感受野的卷积\n", | |||||
| "3.一个 1 x 1 的卷积加上一个 5 x 5 的卷积,作用和第二个一样\n", | |||||
| "4.一个 3 x 3 的最大池化加上 1 x 1 的卷积,最大池化改变输入的特征排列,1 x 1 的卷积进行特征提取\n", | |||||
| "1. 一个 1 x 1 的卷积,一个小的感受野进行卷积提取特征\n", | |||||
| "2. 一个 1 x 1 的卷积加上一个 3 x 3 的卷积,1 x 1 的卷积降低输入的特征通道,减少参数计算量,然后接一个 3 x 3 的卷积做一个较大感受野的卷积\n", | |||||
| "3. 一个 1 x 1 的卷积加上一个 5 x 5 的卷积,作用和第二个一样\n", | |||||
| "4. 一个 3 x 3 的最大池化加上 1 x 1 的卷积,最大池化改变输入的特征排列,1 x 1 的卷积进行特征提取\n", | |||||
| "\n", | "\n", | ||||
| "最后将四个并行线路得到的特征在通道这个维度上拼接在一起,下面我们可以实现一下" | "最后将四个并行线路得到的特征在通道这个维度上拼接在一起,下面我们可以实现一下" | ||||
| ] | ] | ||||
| @@ -352,18 +352,33 @@ | |||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "GoogLeNet 加入了更加结构化的 Inception 块使得我们能够使用更大的通道,更多的层,同时也控制了计算量。\n", | "GoogLeNet 加入了更加结构化的 Inception 块使得我们能够使用更大的通道,更多的层,同时也控制了计算量。\n", | ||||
| "\n", | |||||
| "**小练习:GoogLeNet 有很多后续的版本,尝试看看论文,看看有什么不同,实现一下: \n", | |||||
| "v1:最早的版本 \n", | |||||
| "v2:加入 batch normalization 加快训练 \n", | |||||
| "v3:对 inception 模块做了调整 \n", | |||||
| "v4:基于 ResNet 加入了 残差连接 **" | |||||
| "\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "## 练习\n", | |||||
| "GoogLeNet 有很多后续的版本,尝试看看论文,并亲自实现,看看有什么不同\n", | |||||
| "* v1:最早的版本 \n", | |||||
| "* v2:加入 batch normalization 加快训练 \n", | |||||
| "* v3:对 inception 模块做了调整 \n", | |||||
| "* v4:基于 ResNet 加入了 残差连接\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "## 参考资料\n", | |||||
| "* [深入理解GoogLeNet结构](https://zhuanlan.zhihu.com/p/32702031)" | |||||
| ] | ] | ||||
| } | } | ||||
| ], | ], | ||||
| "metadata": { | "metadata": { | ||||
| "kernelspec": { | "kernelspec": { | ||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "display_name": "Python 3", | |||||
| "language": "python", | "language": "python", | ||||
| "name": "python3" | "name": "python3" | ||||
| }, | }, | ||||
| @@ -377,7 +392,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.9.7" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
+ 28
- 20
7_deep_learning/1_CNN/4-data-augumentation.ipynb
View File
| @@ -7,14 +7,14 @@ | |||||
| "# 数据增强\n", | "# 数据增强\n", | ||||
| "前面我们已经讲了几个非常著名的卷积网络的结构,但是单单只靠这些网络并不能取得 state-of-the-art 的结果,现实问题往往更加复杂,非常容易出现过拟合的问题,而数据增强的方法是对抗过拟合问题的一个重要方法。\n", | "前面我们已经讲了几个非常著名的卷积网络的结构,但是单单只靠这些网络并不能取得 state-of-the-art 的结果,现实问题往往更加复杂,非常容易出现过拟合的问题,而数据增强的方法是对抗过拟合问题的一个重要方法。\n", | ||||
| "\n", | "\n", | ||||
| "2012 年 AlexNet 在 ImageNet 上大获全胜,图片增强方法功不可没,因为有了图片增强,使得训练的数据集比实际数据集多了很多'新'样本,减少了过拟合的问题,下面我们来具体解释一下。" | |||||
| "2012 年 AlexNet 在 ImageNet 上大获全胜,图片增强方法功不可没,因为有了图片增强,使得训练的数据集比实际数据集多了很多'新'样本,减少了过拟合的问题,下面具体解释数据增强的方法。" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "## 常用的数据增强方法\n", | |||||
| "## 1. 常用的数据增强方法\n", | |||||
| "常用的数据增强方法如下: \n", | "常用的数据增强方法如下: \n", | ||||
| "1.对图片进行一定比例缩放 \n", | "1.对图片进行一定比例缩放 \n", | ||||
| "2.对图片进行随机位置的截取 \n", | "2.对图片进行随机位置的截取 \n", | ||||
| @@ -22,13 +22,15 @@ | |||||
| "4.对图片进行随机角度的旋转 \n", | "4.对图片进行随机角度的旋转 \n", | ||||
| "5.对图片进行亮度、对比度和颜色的随机变化\n", | "5.对图片进行亮度、对比度和颜色的随机变化\n", | ||||
| "\n", | "\n", | ||||
| "这些方法 pytorch 都已经为我们内置在了 torchvision 里面,我们在安装 pytorch 的时候也安装了 torchvision,下面我们来依次展示一下这些数据增强方法" | |||||
| "这些方法已经内置在了 torchvision 里面,在安装 pytorch 的时候,可以安装 torchvision库,下面依次展示一下这些数据增强方法" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 1, | "execution_count": 1, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "import sys\n", | "import sys\n", | ||||
| @@ -65,7 +67,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "### 随机比例放缩\n", | |||||
| "### 1.1 随机比例放缩\n", | |||||
| "随机比例缩放主要使用的是 `torchvision.transforms.Resize()` 这个函数,第一个参数可以是一个整数,那么图片会保存现在的宽和高的比例,并将更短的边缩放到这个整数的大小,第一个参数也可以是一个 tuple,那么图片会直接把宽和高缩放到这个大小;第二个参数表示放缩图片使用的方法,比如最邻近法,或者双线性差值等,一般双线性差值能够保留图片更多的信息,所以 pytorch 默认使用的是双线性差值,你可以手动去改这个参数,更多的信息可以看看[文档](http://pytorch.org/docs/0.3.0/torchvision/transforms.html)" | "随机比例缩放主要使用的是 `torchvision.transforms.Resize()` 这个函数,第一个参数可以是一个整数,那么图片会保存现在的宽和高的比例,并将更短的边缩放到这个整数的大小,第一个参数也可以是一个 tuple,那么图片会直接把宽和高缩放到这个大小;第二个参数表示放缩图片使用的方法,比如最邻近法,或者双线性差值等,一般双线性差值能够保留图片更多的信息,所以 pytorch 默认使用的是双线性差值,你可以手动去改这个参数,更多的信息可以看看[文档](http://pytorch.org/docs/0.3.0/torchvision/transforms.html)" | ||||
| ] | ] | ||||
| }, | }, | ||||
| @@ -106,7 +108,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "### 随机位置截取\n", | |||||
| "### 1.2 随机位置截取\n", | |||||
| "随机位置截取能够提取出图片中局部的信息,使得网络接受的输入具有多尺度的特征,所以能够有较好的效果。在 torchvision 中主要有下面两种方式,一个是 `torchvision.transforms.RandomCrop()`,传入的参数就是截取出的图片的长和宽,对图片在随机位置进行截取;第二个是 `torchvision.transforms.CenterCrop()`,同样传入介曲初的图片的大小作为参数,会在图片的中心进行截取" | "随机位置截取能够提取出图片中局部的信息,使得网络接受的输入具有多尺度的特征,所以能够有较好的效果。在 torchvision 中主要有下面两种方式,一个是 `torchvision.transforms.RandomCrop()`,传入的参数就是截取出的图片的长和宽,对图片在随机位置进行截取;第二个是 `torchvision.transforms.CenterCrop()`,同样传入介曲初的图片的大小作为参数,会在图片的中心进行截取" | ||||
| ] | ] | ||||
| }, | }, | ||||
| @@ -183,7 +185,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "### 随机的水平和竖直方向翻转\n", | |||||
| "### 1.3 随机的水平和竖直方向翻转\n", | |||||
| "对于上面这一张猫的图片,如果我们将它翻转一下,它仍然是一张猫,但是图片就有了更多的多样性,所以随机翻转也是一种非常有效的手段。在 torchvision 中,随机翻转使用的是 `torchvision.transforms.RandomHorizontalFlip()` 和 `torchvision.transforms.RandomVerticalFlip()`" | "对于上面这一张猫的图片,如果我们将它翻转一下,它仍然是一张猫,但是图片就有了更多的多样性,所以随机翻转也是一种非常有效的手段。在 torchvision 中,随机翻转使用的是 `torchvision.transforms.RandomHorizontalFlip()` 和 `torchvision.transforms.RandomVerticalFlip()`" | ||||
| ] | ] | ||||
| }, | }, | ||||
| @@ -237,7 +239,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "### 随机角度旋转\n", | |||||
| "### 1.4 随机角度旋转\n", | |||||
| "一些角度的旋转仍然是非常有用的数据增强方式,在 torchvision 中,使用 `torchvision.transforms.RandomRotation()` 来实现,其中第一个参数就是随机旋转的角度,比如填入 10,那么每次图片就会在 -10 ~ 10 度之间随机旋转" | "一些角度的旋转仍然是非常有用的数据增强方式,在 torchvision 中,使用 `torchvision.transforms.RandomRotation()` 来实现,其中第一个参数就是随机旋转的角度,比如填入 10,那么每次图片就会在 -10 ~ 10 度之间随机旋转" | ||||
| ] | ] | ||||
| }, | }, | ||||
| @@ -267,7 +269,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "### 亮度、对比度和颜色的变化\n", | |||||
| "### 1.5 亮度、对比度和颜色的变化\n", | |||||
| "除了形状变化外,颜色变化又是另外一种增强方式,其中可以设置亮度变化,对比度变化和颜色变化等,在 torchvision 中主要使用 `torchvision.transforms.ColorJitter()` 来实现的,第一个参数就是亮度的比例,第二个是对比度,第三个是饱和度,第四个是颜色" | "除了形状变化外,颜色变化又是另外一种增强方式,其中可以设置亮度变化,对比度变化和颜色变化等,在 torchvision 中主要使用 `torchvision.transforms.ColorJitter()` 来实现的,第一个参数就是亮度的比例,第二个是对比度,第三个是饱和度,第四个是颜色" | ||||
| ] | ] | ||||
| }, | }, | ||||
| @@ -344,15 +346,17 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "### 1.6 组合使用多种方法\n", | |||||
| "\n", | "\n", | ||||
| "\n", | |||||
| "上面我们讲了这么图片增强的方法,其实这些方法都不是孤立起来用的,可以联合起来用,比如先做随机翻转,然后随机截取,再做对比度增强等等,torchvision 里面有个非常方便的函数能够将这些变化合起来,就是 `torchvision.transforms.Compose()`,下面我们举个例子" | |||||
| "上面讲了几种图片增强的方法,其实这些方法都不是孤立起来用的,可以联合起来用,比如先做随机翻转,然后随机截取,再做对比度增强等等,torchvision 里面有个非常方便的函数能够将这些变化合起来,就是 `torchvision.transforms.Compose()`,下面举例说明" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 13, | "execution_count": 13, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "im_aug = tfs.Compose([\n", | "im_aug = tfs.Compose([\n", | ||||
| @@ -366,7 +370,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 14, | "execution_count": 14, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "import matplotlib.pyplot as plt\n", | "import matplotlib.pyplot as plt\n", | ||||
| @@ -408,9 +414,9 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "可以看到每次做完增强之后的图片都有一些变化,所以这就是我们前面讲的,增加了一些'新'数据\n", | |||||
| "可以看到每次做完增强之后的图片都有一些变化,所以这就是前面所讲的增加了一些'新'数据。\n", | |||||
| "\n", | "\n", | ||||
| "下面我们使用图像增强进行训练网络,看看具体的提升究竟在什么地方,使用前面讲的 ResNet 进行训练 " | |||||
| "下面使用图像增强进行训练网络,看看具体的提升究竟在什么地方,使用前面讲的 ResNet 进行训练 " | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -420,7 +426,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-23T05:04:03.407434Z", | "end_time": "2017-12-23T05:04:03.407434Z", | ||||
| "start_time": "2017-12-23T05:04:02.920639Z" | "start_time": "2017-12-23T05:04:02.920639Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -441,7 +448,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-23T05:04:04.743167Z", | "end_time": "2017-12-23T05:04:04.743167Z", | ||||
| "start_time": "2017-12-23T05:04:03.459562Z" | "start_time": "2017-12-23T05:04:03.459562Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -532,7 +540,7 @@ | |||||
| "\n", | "\n", | ||||
| "train_set = CIFAR10('../../data', train=True, transform=data_tf)\n", | "train_set = CIFAR10('../../data', train=True, transform=data_tf)\n", | ||||
| "train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)\n", | "train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)\n", | ||||
| "test_set = CIFAR10('../../data', train=False, transform=data_tf)\n", | |||||
| "test_set = CIFAR10('../../data', train=False, transform=data_tf)\n", | |||||
| "test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)\n", | "test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)\n", | ||||
| "\n", | "\n", | ||||
| "net = resnet(3, 10)\n", | "net = resnet(3, 10)\n", | ||||
| @@ -583,7 +591,7 @@ | |||||
| ], | ], | ||||
| "metadata": { | "metadata": { | ||||
| "kernelspec": { | "kernelspec": { | ||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "display_name": "Python 3", | |||||
| "language": "python", | "language": "python", | ||||
| "name": "python3" | "name": "python3" | ||||
| }, | }, | ||||
| @@ -597,7 +605,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.9.7" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
+ 0
- 151
7_deep_learning/1_CNN/4-regularization.ipynb
View File
| @@ -1,151 +0,0 @@ | |||||
| { | |||||
| "cells": [ | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "# 正则化\n", | |||||
| "前面我们讲了数据增强和 dropout,而在实际使用中,现在的网络往往不使用 dropout,而是用另外一个技术,叫正则化。\n", | |||||
| "\n", | |||||
| "正则化是机器学习中提出来的一种方法,有 L1 和 L2 正则化,目前使用较多的是 L2 正则化,引入正则化相当于在 loss 函数上面加上一项,比如\n", | |||||
| "\n", | |||||
| "$$\n", | |||||
| "f = loss + \\lambda \\sum_{p \\in params} ||p||_2^2\n", | |||||
| "$$\n", | |||||
| "\n", | |||||
| "就是在 loss 的基础上加上了参数的二范数作为一个正则化,我们在训练网络的时候,不仅要最小化 loss 函数,同时还要最小化参数的二范数,也就是说我们会对参数做一些限制,不让它变得太大。" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "如果我们对新的损失函数 f 求导进行梯度下降,就有\n", | |||||
| "\n", | |||||
| "$$\n", | |||||
| "\\frac{\\partial f}{\\partial p_j} = \\frac{\\partial loss}{\\partial p_j} + 2 \\lambda p_j\n", | |||||
| "$$\n", | |||||
| "\n", | |||||
| "那么在更新参数的时候就有\n", | |||||
| "\n", | |||||
| "$$\n", | |||||
| "p_j \\rightarrow p_j - \\eta (\\frac{\\partial loss}{\\partial p_j} + 2 \\lambda p_j) = p_j - \\eta \\frac{\\partial loss}{\\partial p_j} - 2 \\eta \\lambda p_j \n", | |||||
| "$$\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "可以看到 $p_j - \\eta \\frac{\\partial loss}{\\partial p_j}$ 和没加正则项要更新的部分一样,而后面的 $2\\eta \\lambda p_j$ 就是正则项的影响,可以看到加完正则项之后会对参数做更大程度的更新,这也被称为权重衰减(weight decay),在 pytorch 中正则项就是通过这种方式来加入的,比如想在随机梯度下降法中使用正则项,或者说权重衰减,`torch.optim.SGD(net.parameters(), lr=0.1, weight_decay=1e-4)` 就可以了,这个 `weight_decay` 系数就是上面公式中的 $\\lambda$,非常方便\n", | |||||
| "\n", | |||||
| "注意正则项的系数的大小非常重要,如果太大,会极大的抑制参数的更新,导致欠拟合,如果太小,那么正则项这个部分基本没有贡献,所以选择一个合适的权重衰减系数非常重要,这个需要根据具体的情况去尝试,初步尝试可以使用 `1e-4` 或者 `1e-3` \n", | |||||
| "\n", | |||||
| "下面我们在训练 cifar 10 中添加正则项" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 1, | |||||
| "metadata": { | |||||
| "ExecuteTime": { | |||||
| "end_time": "2017-12-24T08:02:11.903459Z", | |||||
| "start_time": "2017-12-24T08:02:11.383170Z" | |||||
| } | |||||
| }, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "import sys\n", | |||||
| "sys.path.append('..')\n", | |||||
| "\n", | |||||
| "import numpy as np\n", | |||||
| "import torch\n", | |||||
| "from torch import nn\n", | |||||
| "import torch.nn.functional as F\n", | |||||
| "from torch.autograd import Variable\n", | |||||
| "from torchvision.datasets import CIFAR10\n", | |||||
| "from utils import train, resnet\n", | |||||
| "from torchvision import transforms as tfs" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 2, | |||||
| "metadata": { | |||||
| "ExecuteTime": { | |||||
| "end_time": "2017-12-24T08:02:13.120502Z", | |||||
| "start_time": "2017-12-24T08:02:11.905617Z" | |||||
| } | |||||
| }, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "def data_tf(x):\n", | |||||
| " im_aug = tfs.Compose([\n", | |||||
| " tfs.Resize(96),\n", | |||||
| " tfs.ToTensor(),\n", | |||||
| " tfs.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])\n", | |||||
| " ])\n", | |||||
| " x = im_aug(x)\n", | |||||
| " return x\n", | |||||
| "\n", | |||||
| "train_set = CIFAR10('../../data', train=True, transform=data_tf)\n", | |||||
| "train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True, num_workers=4)\n", | |||||
| "test_set = CIFAR10('../../data', train=False, transform=data_tf)\n", | |||||
| "test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False, num_workers=4)\n", | |||||
| "\n", | |||||
| "net = resnet(3, 10)\n", | |||||
| "optimizer = torch.optim.SGD(net.parameters(), lr=0.01, weight_decay=1e-4) # 增加正则项\n", | |||||
| "criterion = nn.CrossEntropyLoss()" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 4, | |||||
| "metadata": { | |||||
| "ExecuteTime": { | |||||
| "end_time": "2017-12-24T08:11:36.106177Z", | |||||
| "start_time": "2017-12-24T08:02:13.122785Z" | |||||
| } | |||||
| }, | |||||
| "outputs": [ | |||||
| { | |||||
| "ename": "IndexError", | |||||
| "evalue": "invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number", | |||||
| "output_type": "error", | |||||
| "traceback": [ | |||||
| "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", | |||||
| "\u001b[0;31mIndexError\u001b[0m Traceback (most recent call last)", | |||||
| "\u001b[0;32m/tmp/ipykernel_10317/3705871991.py\u001b[0m in \u001b[0;36m<module>\u001b[0;34m\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mfrom\u001b[0m \u001b[0mutils\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0mtrain\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 2\u001b[0;31m \u001b[0mtrain\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mnet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtrain_data\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtest_data\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m20\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0moptimizer\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mcriterion\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m", | |||||
| "\u001b[0;32m~-data/msdk/my_progs/pi-lab/courses/machine_learning/machinelearning_notebook/6_pytorch/2_CNN/utils.py\u001b[0m in \u001b[0;36mtrain\u001b[0;34m(net, train_data, valid_data, num_epochs, optimizer, criterion)\u001b[0m\n\u001b[1;32m 37\u001b[0m \u001b[0moptimizer\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mstep\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 38\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 39\u001b[0;31m \u001b[0mtrain_loss\u001b[0m \u001b[0;34m+=\u001b[0m \u001b[0mloss\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mitem\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 40\u001b[0m \u001b[0mtrain_acc\u001b[0m \u001b[0;34m+=\u001b[0m \u001b[0mget_acc\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0moutput\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlabel\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 41\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n", | |||||
| "\u001b[0;31mIndexError\u001b[0m: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "from utils import train\n", | |||||
| "train(net, train_data, test_data, 20, optimizer, criterion)" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "metadata": { | |||||
| "kernelspec": { | |||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "language": "python", | |||||
| "name": "python3" | |||||
| }, | |||||
| "language_info": { | |||||
| "codemirror_mode": { | |||||
| "name": "ipython", | |||||
| "version": 3 | |||||
| }, | |||||
| "file_extension": ".py", | |||||
| "mimetype": "text/x-python", | |||||
| "name": "python", | |||||
| "nbconvert_exporter": "python", | |||||
| "pygments_lexer": "ipython3", | |||||
| "version": "3.9.7" | |||||
| } | |||||
| }, | |||||
| "nbformat": 4, | |||||
| "nbformat_minor": 2 | |||||
| } | |||||
7_deep_learning/1_CNN/8-resnet.ipynb → 7_deep_learning/1_CNN/4-resnet.ipynb
View File
7_deep_learning/1_CNN/9-densenet.ipynb → 7_deep_learning/1_CNN/5-densenet.ipynb
View File
7_deep_learning/1_CNN/2-batch-normalization.ipynb → 7_deep_learning/1_CNN/6-batch-normalization.ipynb
View File
| @@ -5,17 +5,17 @@ | |||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "# 批标准化\n", | "# 批标准化\n", | ||||
| "在我们正式进入模型的构建和训练之前,我们会先讲一讲数据预处理和批标准化,因为模型训练并不容易,特别是一些非常复杂的模型,并不能非常好的训练得到收敛的结果,所以对数据增加一些预处理,同时使用批标准化能够得到非常好的收敛结果,这也是卷积网络能够训练到非常深的层的一个重要原因。" | |||||
| "在正式进入模型的构建和训练之前,先讲一下数据预处理和批标准化。因为模型训练并不容易,特别是一些非常复杂的模型,并不能非常好的训练得到收敛的结果,所以对数据增加一些预处理,同时使用批标准化能够得到非常好的收敛结果,这也是卷积网络能够训练到非常深的层的一个重要原因。" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "## 数据预处理\n", | |||||
| "目前数据预处理最常见的方法就是中心化和标准化\n", | |||||
| "* 中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征。\n", | |||||
| "* 标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间\n", | |||||
| "## 1. 数据预处理\n", | |||||
| "目前数据预处理最常见的方法就是 `中心化` 和 `标准化`\n", | |||||
| "* **中心化** 相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征。\n", | |||||
| "* **标准化** 也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间\n", | |||||
| "\n", | "\n", | ||||
| "下图是处理的的示例:\n", | "下图是处理的的示例:\n", | ||||
| "\n", | "\n", | ||||
| @@ -27,7 +27,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "## Batch Normalization\n", | |||||
| "## 2. Batch Normalization\n", | |||||
| "前面在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好。但是对于很深的网路结构,网路的非线性层会使得输出的结果变得相关,且不再满足一个标准的 N(0, 1) 的分布,甚至输出的中心已经发生了偏移,这对于模型的训练,特别是深层的模型训练非常的困难。\n", | "前面在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好。但是对于很深的网路结构,网路的非线性层会使得输出的结果变得相关,且不再满足一个标准的 N(0, 1) 的分布,甚至输出的中心已经发生了偏移,这对于模型的训练,特别是深层的模型训练非常的困难。\n", | ||||
| "\n", | "\n", | ||||
| "所以在 2015 年一篇论文提出了这个方法,批标准化,简而言之,就是对于每一层网络的输出,对其做一个归一化,使其服从标准的正态分布,这样后一层网络的输入也是一个标准的正态分布,所以能够比较好的进行训练,加快收敛速度。" | "所以在 2015 年一篇论文提出了这个方法,批标准化,简而言之,就是对于每一层网络的输出,对其做一个归一化,使其服从标准的正态分布,这样后一层网络的输入也是一个标准的正态分布,所以能够比较好的进行训练,加快收敛速度。" | ||||
| @@ -67,7 +67,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-23T06:50:51.579067Z", | "end_time": "2017-12-23T06:50:51.579067Z", | ||||
| "start_time": "2017-12-23T06:50:51.575693Z" | "start_time": "2017-12-23T06:50:51.575693Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -84,7 +85,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-23T07:14:11.077807Z", | "end_time": "2017-12-23T07:14:11.077807Z", | ||||
| "start_time": "2017-12-23T07:14:11.060849Z" | "start_time": "2017-12-23T07:14:11.060849Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -169,7 +171,8 @@ | |||||
| "ExecuteTime": { | "ExecuteTime": { | ||||
| "end_time": "2017-12-23T07:32:48.025709Z", | "end_time": "2017-12-23T07:32:48.025709Z", | ||||
| "start_time": "2017-12-23T07:32:48.005892Z" | "start_time": "2017-12-23T07:32:48.005892Z" | ||||
| } | |||||
| }, | |||||
| "collapsed": true | |||||
| }, | }, | ||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| @@ -196,7 +199,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 5, | "execution_count": 5, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "import numpy as np\n", | "import numpy as np\n", | ||||
| @@ -209,12 +214,14 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 6, | "execution_count": 6, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "# 使用内置函数下载 mnist 数据集\n", | "# 使用内置函数下载 mnist 数据集\n", | ||||
| "train_set = mnist.MNIST('../../data/mnist', train=True)\n", | "train_set = mnist.MNIST('../../data/mnist', train=True)\n", | ||||
| "test_set = mnist.MNIST('../../data/mnist', train=False)\n", | |||||
| "test_set = mnist.MNIST('../../data/mnist', train=False)\n", | |||||
| "\n", | "\n", | ||||
| "def data_tf(x):\n", | "def data_tf(x):\n", | ||||
| " x = np.array(x, dtype='float32') / 255\n", | " x = np.array(x, dtype='float32') / 255\n", | ||||
| @@ -223,8 +230,8 @@ | |||||
| " x = torch.from_numpy(x)\n", | " x = torch.from_numpy(x)\n", | ||||
| " return x\n", | " return x\n", | ||||
| "\n", | "\n", | ||||
| "train_set = mnist.MNIST('../../data/mnist', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换\n", | |||||
| "test_set = mnist.MNIST('../../data/mnist', train=False, transform=data_tf, download=True)\n", | |||||
| "train_set = mnist.MNIST('../../data/mnist', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换\n", | |||||
| "test_set = mnist.MNIST('../../data/mnist', train=False, transform=data_tf, download=True)\n", | |||||
| "train_data = DataLoader(train_set, batch_size=64, shuffle=True)\n", | "train_data = DataLoader(train_set, batch_size=64, shuffle=True)\n", | ||||
| "test_data = DataLoader(test_set, batch_size=128, shuffle=False)" | "test_data = DataLoader(test_set, batch_size=128, shuffle=False)" | ||||
| ] | ] | ||||
| @@ -232,7 +239,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 7, | "execution_count": 7, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "class multi_network(nn.Module):\n", | "class multi_network(nn.Module):\n", | ||||
| @@ -259,7 +268,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 8, | "execution_count": 8, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "net = multi_network()" | "net = multi_network()" | ||||
| @@ -268,7 +279,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 9, | "execution_count": 9, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "# 定义 loss 函数\n", | "# 定义 loss 函数\n", | ||||
| @@ -420,7 +433,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": null, | "execution_count": null, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "def data_tf(x):\n", | "def data_tf(x):\n", | ||||
| @@ -430,7 +445,7 @@ | |||||
| " x = x.unsqueeze(0)\n", | " x = x.unsqueeze(0)\n", | ||||
| " return x\n", | " return x\n", | ||||
| "\n", | "\n", | ||||
| "train_set = mnist.MNIST('../../data/mnist', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换\n", | |||||
| "train_set = mnist.MNIST('../../data/mnist', train=True, transform=data_tf, download=True) # 重新载入数据集,申明定义的数据变换\n", | |||||
| "test_set = mnist.MNIST('../../data/mnist', train=False, transform=data_tf, download=True)\n", | "test_set = mnist.MNIST('../../data/mnist', train=False, transform=data_tf, download=True)\n", | ||||
| "train_data = DataLoader(train_set, batch_size=64, shuffle=True)\n", | "train_data = DataLoader(train_set, batch_size=64, shuffle=True)\n", | ||||
| "test_data = DataLoader(test_set, batch_size=128, shuffle=False)" | "test_data = DataLoader(test_set, batch_size=128, shuffle=False)" | ||||
| @@ -439,7 +454,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 78, | "execution_count": 78, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "# 使用批标准化\n", | "# 使用批标准化\n", | ||||
| @@ -492,7 +509,9 @@ | |||||
| { | { | ||||
| "cell_type": "code", | "cell_type": "code", | ||||
| "execution_count": 76, | "execution_count": 76, | ||||
| "metadata": {}, | |||||
| "metadata": { | |||||
| "collapsed": true | |||||
| }, | |||||
| "outputs": [], | "outputs": [], | ||||
| "source": [ | "source": [ | ||||
| "# 不使用批标准化\n", | "# 不使用批标准化\n", | ||||
| @@ -558,7 +577,7 @@ | |||||
| ], | ], | ||||
| "metadata": { | "metadata": { | ||||
| "kernelspec": { | "kernelspec": { | ||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "display_name": "Python 3", | |||||
| "language": "python", | "language": "python", | ||||
| "name": "python3" | "name": "python3" | ||||
| }, | }, | ||||
| @@ -572,7 +591,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.9.7" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
7_deep_learning/1_CNN/3-lr-decay.ipynb → 7_deep_learning/1_CNN/7-lr-decay.ipynb
View File
| @@ -5,9 +5,7 @@ | |||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "# 学习率衰减\n", | "# 学习率衰减\n", | ||||
| "对于基于一阶梯度进行优化的方法而言,开始的时候更新的幅度是比较大的,也就是说开始的学习率可以设置大一点,但是当训练集的 loss 下降到一定程度之后,继续使用这个太大的学习率就会导致 loss 一直来回震荡,比如\n", | |||||
| "\n", | |||||
| "" | |||||
| "对于基于一阶梯度进行优化的方法而言,开始的时候更新的幅度是比较大的,也就是说开始的学习率可以设置大一点,但是当训练集的 loss 下降到一定程度之后,继续使用这个太大的学习率就会导致 loss 一直来回震荡。" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -16,9 +14,9 @@ | |||||
| "source": [ | "source": [ | ||||
| "这个时候就需要对学习率进行衰减已达到 loss 的充分下降,而是用学习率衰减的办法能够解决这个矛盾,学习率衰减就是随着训练的进行不断的减小学习率。\n", | "这个时候就需要对学习率进行衰减已达到 loss 的充分下降,而是用学习率衰减的办法能够解决这个矛盾,学习率衰减就是随着训练的进行不断的减小学习率。\n", | ||||
| "\n", | "\n", | ||||
| "在 pytorch 中学习率衰减非常方便,使用 `torch.optim.lr_scheduler`,更多的信息可以直接查看[文档](http://pytorch.org/docs/0.3.0/optim.html#how-to-adjust-learning-rate)\n", | |||||
| "在 PyTorch 中学习率衰减非常方便,使用 `torch.optim.lr_scheduler`,更多的信息可以直接查看[文档](http://pytorch.org/docs/0.3.0/optim.html#how-to-adjust-learning-rate)\n", | |||||
| "\n", | "\n", | ||||
| "但是我推荐大家使用下面这种方式来做学习率衰减,更加直观,下面我们直接举例子来说明" | |||||
| "推荐大家使用下面这种方式来做学习率衰减,更加直观,下面举例子来说明" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -67,9 +65,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "这里我们定义好了模型和优化器,可以通过 `optimizer.param_groups` 来得到所有的参数组和其对应的属性,参数组是什么意思呢?就是我们可以将模型的参数分成几个组,每个组定义一个学习率,这里比较复杂,一般来讲如果不做特别修改,就只有一个参数组\n", | |||||
| "\n", | |||||
| "这个参数组是一个字典,里面有很多属性,比如学习率,权重衰减等等,我们可以访问以下" | |||||
| "这里定义好了模型和优化器,可以通过 `optimizer.param_groups` 来得到所有的参数组和其对应的属性,参数组是什么意思呢?就是将模型的参数分成几个组,每个组定义一个学习率。这个参数组是一个字典,里面有很多属性,比如学习率,权重衰减等等,可以通过如下方式访问属性值:" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -100,7 +96,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "所以我们可以通过修改这个属性来改变我们训练过程中的学习率,非常简单" | |||||
| "可以通过修改这个属性来改变训练过程中的学习率:" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -122,7 +118,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "为了防止有多个参数组,我们可以使用一个循环" | |||||
| "为了使用多个参数组,可以使用一个循环" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -145,9 +141,7 @@ | |||||
| "cell_type": "markdown", | "cell_type": "markdown", | ||||
| "metadata": {}, | "metadata": {}, | ||||
| "source": [ | "source": [ | ||||
| "方法就是这样,非常简单,我们可以在任意的位置改变我们的学习率\n", | |||||
| "\n", | |||||
| "下面我们具体来看看学习率衰减的好处" | |||||
| "方法就是这样,非常简单,可以在任意的位置改变学习率。下面具体来看看学习率衰减的好处" | |||||
| ] | ] | ||||
| }, | }, | ||||
| { | { | ||||
| @@ -383,13 +377,13 @@ | |||||
| "source": [ | "source": [ | ||||
| "这里我们只训练了 30 次,在 20 次的时候进行了学习率衰减,可以看 loss 曲线在 20 次的时候不管是 train loss 还是 valid loss,都有了一个陡降。\n", | "这里我们只训练了 30 次,在 20 次的时候进行了学习率衰减,可以看 loss 曲线在 20 次的时候不管是 train loss 还是 valid loss,都有了一个陡降。\n", | ||||
| "\n", | "\n", | ||||
| "当然这里我们只是作为举例,在实际应用中,做学习率衰减之前应该经过充分的训练,比如训练 80 次或者 100 次,然后再做学习率衰减得到更好的结果,有的时候甚至需要做多次学习率衰减" | |||||
| "当然这里我们只是作为举例,在实际应用中,做学习率衰减之前应该经过充分的训练,比如训练 80 次或者 100 次,然后再做学习率衰减得到更好的结果,有的时候甚至需要做多次学习率衰减。" | |||||
| ] | ] | ||||
| } | } | ||||
| ], | ], | ||||
| "metadata": { | "metadata": { | ||||
| "kernelspec": { | "kernelspec": { | ||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "display_name": "Python 3", | |||||
| "language": "python", | "language": "python", | ||||
| "name": "python3" | "name": "python3" | ||||
| }, | }, | ||||
| @@ -403,7 +397,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.9.7" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
7_deep_learning/1_CNN/5-regularization.ipynb → 7_deep_learning/1_CNN/8-regularization.ipynb
View File
| @@ -159,7 +159,7 @@ | |||||
| "name": "python", | "name": "python", | ||||
| "nbconvert_exporter": "python", | "nbconvert_exporter": "python", | ||||
| "pygments_lexer": "ipython3", | "pygments_lexer": "ipython3", | ||||
| "version": "3.5.2" | |||||
| "version": "3.5.4" | |||||
| } | } | ||||
| }, | }, | ||||
| "nbformat": 4, | "nbformat": 4, | ||||
7_deep_learning/1_CNN/5-data-augumentation.ipynb → 7_deep_learning/1_CNN/9-data-augumentation.ipynb
View File
BIN
7_deep_learning/1_CNN/CNN_Introduction.pptx
View File
BIN
7_deep_learning/1_CNN/images/inception2_improved.jpeg
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 732 | Height: 448 | Size: 32 kB |
BIN
7_deep_learning/1_CNN/images/inception2_naive.jpeg
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 768 | Height: 427 | Size: 25 kB |