|
|
@@ -0,0 +1,144 @@ |
|
|
|
|
|
{ |
|
|
|
|
|
"cells": [ |
|
|
|
|
|
{ |
|
|
|
|
|
"cell_type": "markdown", |
|
|
|
|
|
"metadata": {}, |
|
|
|
|
|
"source": [ |
|
|
|
|
|
"# Word2Vec\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"众所周知,机器处理原始文本数据。实际上,机器几乎不可能处理数据文本之外的其它文本。因此,以向量的形式表示文本一直是所有NLP任务的重要步骤。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"其中非常关键的一步是word2vec词嵌入的使用。该方法在2013年被引入NLP领域,完全改变了NLP的前景。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"这些嵌入法代表了处理词类比和相似度等任务可达到的最高水准。word2vec嵌入法也能实现King – man +woman ~= Queen(国王–男性 + 女性 ~= 女王等任务),近乎神迹。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"现在有两种word2vec模型——连续词袋模型与Skip-Gram模型。本文将使用后者。首先要了解如何计算word2vec向量或嵌入。" |
|
|
|
|
|
] |
|
|
|
|
|
}, |
|
|
|
|
|
{ |
|
|
|
|
|
"cell_type": "markdown", |
|
|
|
|
|
"metadata": {}, |
|
|
|
|
|
"source": [ |
|
|
|
|
|
"## 1. 如何生成word2vec词嵌入?\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"word2vec模型是一个单个简单隐藏层的神经网络模型。模型任务用于预测语句中每个单词的临近单词。然而,我们的目标与此完全无关。我们想做的只是知道模型被训练后隐藏层所学习的权重。这些权重可做被用做词嵌入。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"下面的例子用于理解word2vec模型是如何工作的。思考以下句子:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"假设“teleport(传输)”这个词作为输入词。该词拥有规格为2的上下文窗口。这意味着只将此词左右两侧的两个单词作为相近单词。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"注意:上下文窗口的规格非固定,可根据需要改变。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"现在,任务是逐一选择相近单词(上下文窗口中的单词)并确定词汇表中每个单词被选中的可能性。听起来很容易,对吗?\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"通过另一个例子来理解这个过程。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"### 1.1 训练数据\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"需要一个标签数据集来训练神经网络模型。这意味着数据集需要有一组输入,每组都会有相应输出。这时你可能会想问以下问题:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"* 何处寻找这样的数据集?\n", |
|
|
|
|
|
"* 该数据集需要包含什么内容?\n", |
|
|
|
|
|
"* 这组数据有多大?\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"好消息!可以很容易地创建自己的标签数据来训练word2vec模型。如下阐述了如何从文本生成数据集。应用其中的一个句子并创建训练数据。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"第一步:黄色高亮单词作为输入,绿色高亮单词为输出。窗口规格为2个单词。将首单词作为输入词。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"因此,该输入词的训练样本如下所示:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"第二步:将第二个单词作为输入词。上下文窗口将同时改变。现在的相近单词变成了“we”、“become”和“what”。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"新的训练样本将附于之前的样本后面,如下所示:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
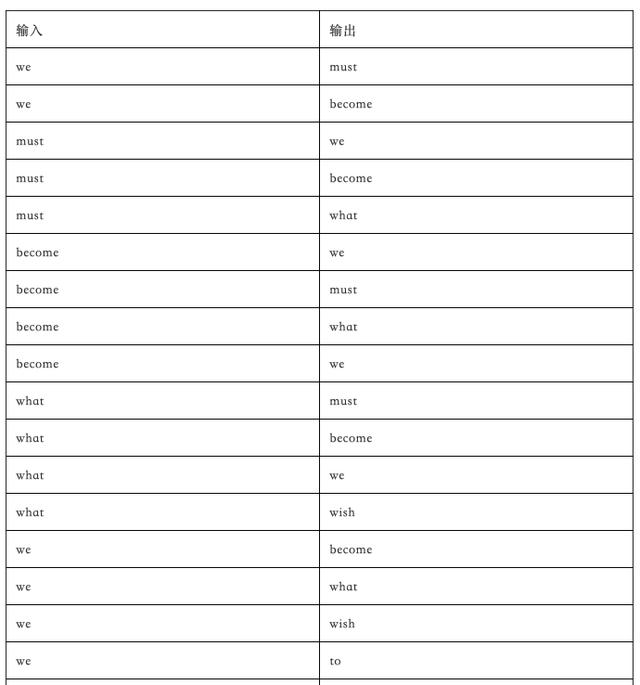
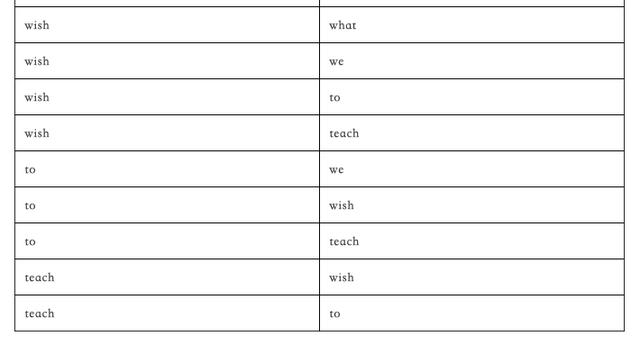
"重复以上步骤直至最后一个单词。最后,完整的训练数据如下所示:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"一个句子能生成27个训练样本。太赞了!这是我喜欢处理非结构化数据的原因之一——能让标签数据集从无到有。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"### 1.2 生成word2vec词嵌入\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"现在假设存在一组句子,用同样的方法提取出一组训练样本。将会得到大量训练数据。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
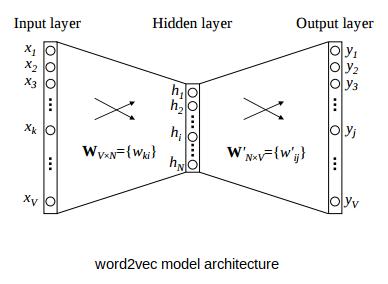
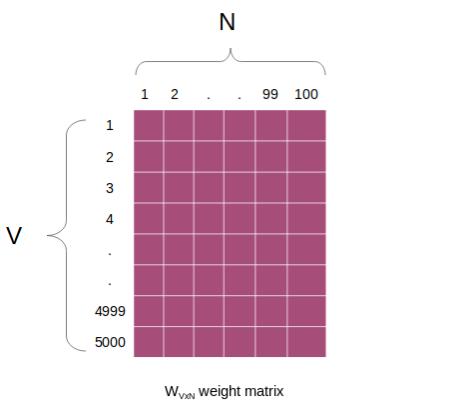
"假设该数据集中唯一单词(即只出现一次的单词)的数量是5000,并且希望为每一个单词创建规格为100的单词向量。同时word2vec架构如下所示:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"* V=5000(词汇表规格)\n", |
|
|
|
|
|
"* N=100(隐藏单元数量或词嵌入长度)\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"输入是独热编码向量,**输出层是词汇表中各单词成为相近单词的概率**。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"为了将事物置于上下文中,词嵌入是文本的向量表示形式,它们捕获上下文信息。让我们看看下面的句子:\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"* 我乘**巴士**去孟买\n", |
|
|
|
|
|
"* 我乘**火车**去孟买\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"粗体字(公共汽车和火车)的向量将非常相似,因为它们出现在相同的上下文中,即粗体文本之前和之后的词。该信息对于许多NLP任务非常有用,例如文本分类,命名实体识别,语言建模,机器翻译等等。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"一旦模型被训练,很容易提取$W_V x N$ 矩阵的学习权重,并用以提取单词。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"如上所示,权重矩阵的规格为5000x100。第一行对应词汇表中的第一个单词,第二行对应第二个,以此类推。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
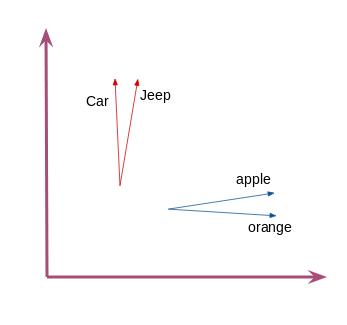
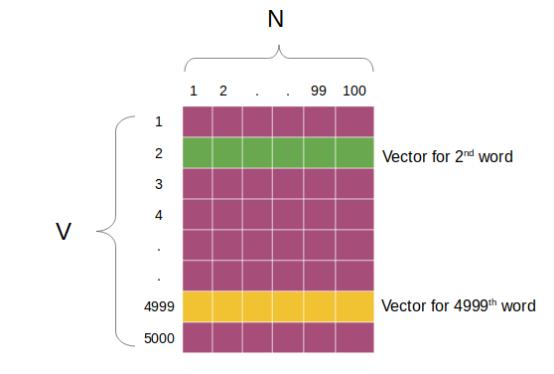
"这就是通过word2vec生成固定规格的单词向量或单词嵌入的方法。数据集中的相似词会有相似向量,如指向同一方向的向量。比如,“car”和“jeep”两个词有着相似的向量。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"这是对于NLP中如何应用word2vec模型的简要介绍。\n", |
|
|
|
|
|
"\n", |
|
|
|
|
|
"\n" |
|
|
|
|
|
] |
|
|
|
|
|
}, |
|
|
|
|
|
{ |
|
|
|
|
|
"cell_type": "markdown", |
|
|
|
|
|
"metadata": {}, |
|
|
|
|
|
"source": [ |
|
|
|
|
|
"## References\n", |
|
|
|
|
|
"* 用Word2Vec建立你的私人购物助手 https://www.toutiao.com/a6730445169444782606\n", |
|
|
|
|
|
"* 使用DeepWalk从图中提取特征 https://www.toutiao.com/a6766104546411282947\n", |
|
|
|
|
|
"* 词向量详解:从word2vec、glove、ELMo到BERT https://www.toutiao.com/a6746020414075437579" |
|
|
|
|
|
] |
|
|
|
|
|
} |
|
|
|
|
|
], |
|
|
|
|
|
"metadata": { |
|
|
|
|
|
"kernelspec": { |
|
|
|
|
|
"display_name": "Python 3", |
|
|
|
|
|
"language": "python", |
|
|
|
|
|
"name": "python3" |
|
|
|
|
|
}, |
|
|
|
|
|
"language_info": { |
|
|
|
|
|
"codemirror_mode": { |
|
|
|
|
|
"name": "ipython", |
|
|
|
|
|
"version": 3 |
|
|
|
|
|
}, |
|
|
|
|
|
"file_extension": ".py", |
|
|
|
|
|
"mimetype": "text/x-python", |
|
|
|
|
|
"name": "python", |
|
|
|
|
|
"nbconvert_exporter": "python", |
|
|
|
|
|
"pygments_lexer": "ipython3", |
|
|
|
|
|
"version": "3.5.2" |
|
|
|
|
|
} |
|
|
|
|
|
}, |
|
|
|
|
|
"nbformat": 4, |
|
|
|
|
|
"nbformat_minor": 2 |
|
|
|
|
|
} |
 bushuhui
5 years ago
bushuhui
5 years ago
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}