 zheng-huanhuan
5 years ago
zheng-huanhuan
5 years ago
commit
96302d7f1b
100 changed files with 13385 additions and 0 deletions
Split View
Diff Options
-
+25 -0.gitee/PULL_REQUEST_TEMPLATE.md
-
+28 -0.gitignore
-
+201 -0LICENSE
-
+2 -0NOTICE
-
+74 -0README.md
-
+11 -0RELEASE.md
-
+3 -0docs/README.md
-
BINdocs/mindarmour_architecture.png
-
+62 -0example/data_processing.py
-
+46 -0example/mnist_demo/README.md
-
+64 -0example/mnist_demo/lenet5_net.py
-
+118 -0example/mnist_demo/mnist_attack_cw.py
-
+120 -0example/mnist_demo/mnist_attack_deepfool.py
-
+119 -0example/mnist_demo/mnist_attack_fgsm.py
-
+138 -0example/mnist_demo/mnist_attack_genetic.py
-
+150 -0example/mnist_demo/mnist_attack_hsja.py
-
+124 -0example/mnist_demo/mnist_attack_jsma.py
-
+132 -0example/mnist_demo/mnist_attack_lbfgs.py
-
+168 -0example/mnist_demo/mnist_attack_nes.py
-
+119 -0example/mnist_demo/mnist_attack_pgd.py
-
+138 -0example/mnist_demo/mnist_attack_pointwise.py
-
+131 -0example/mnist_demo/mnist_attack_pso.py
-
+142 -0example/mnist_demo/mnist_attack_salt_and_pepper.py
-
+144 -0example/mnist_demo/mnist_defense_nad.py
-
+326 -0example/mnist_demo/mnist_evaluation.py
-
+182 -0example/mnist_demo/mnist_similarity_detector.py
-
+88 -0example/mnist_demo/mnist_train.py
-
+13 -0mindarmour/__init__.py
-
+39 -0mindarmour/attacks/__init__.py
-
+97 -0mindarmour/attacks/attack.py
-
+0 -0mindarmour/attacks/black/__init__.py
-
+75 -0mindarmour/attacks/black/black_model.py
-
+230 -0mindarmour/attacks/black/genetic_attack.py
-
+510 -0mindarmour/attacks/black/hop_skip_jump_attack.py
-
+432 -0mindarmour/attacks/black/natural_evolutionary_strategy.py
-
+326 -0mindarmour/attacks/black/pointwise_attack.py
-
+302 -0mindarmour/attacks/black/pso_attack.py
-
+166 -0mindarmour/attacks/black/salt_and_pepper_attack.py
-
+419 -0mindarmour/attacks/carlini_wagner.py
-
+154 -0mindarmour/attacks/deep_fool.py
-
+402 -0mindarmour/attacks/gradient_method.py
-
+432 -0mindarmour/attacks/iterative_gradient_method.py
-
+196 -0mindarmour/attacks/jsma.py
-
+224 -0mindarmour/attacks/lbfgs.py
-
+15 -0mindarmour/defenses/__init__.py
-
+169 -0mindarmour/defenses/adversarial_defense.py
-
+86 -0mindarmour/defenses/defense.py
-
+56 -0mindarmour/defenses/natural_adversarial_defense.py
-
+69 -0mindarmour/defenses/projected_adversarial_defense.py
-
+18 -0mindarmour/detectors/__init__.py
-
+0 -0mindarmour/detectors/black/__init__.py
-
+284 -0mindarmour/detectors/black/similarity_detector.py
-
+101 -0mindarmour/detectors/detector.py
-
+126 -0mindarmour/detectors/ensemble_detector.py
-
+228 -0mindarmour/detectors/mag_net.py
-
+235 -0mindarmour/detectors/region_based_detector.py
-
+171 -0mindarmour/detectors/spatial_smoothing.py
-
+14 -0mindarmour/evaluations/__init__.py
-
+275 -0mindarmour/evaluations/attack_evaluation.py
-
+0 -0mindarmour/evaluations/black/__init__.py
-
+204 -0mindarmour/evaluations/black/defense_evaluation.py
-
+152 -0mindarmour/evaluations/defense_evaluation.py
-
+141 -0mindarmour/evaluations/visual_metrics.py
-
+7 -0mindarmour/utils/__init__.py
-
+269 -0mindarmour/utils/_check_param.py
-
+154 -0mindarmour/utils/logger.py
-
+147 -0mindarmour/utils/util.py
-
+38 -0package.sh
-
+7 -0requirements.txt
-
+102 -0setup.py
-
+311 -0tests/st/resnet50/resnet_cifar10.py
-
+76 -0tests/st/resnet50/test_cifar10_attack_fgsm.py
-
+144 -0tests/ut/python/attacks/black/test_genetic_attack.py
-
+166 -0tests/ut/python/attacks/black/test_hsja.py
-
+217 -0tests/ut/python/attacks/black/test_nes.py
-
+90 -0tests/ut/python/attacks/black/test_pointwise_attack.py
-
+166 -0tests/ut/python/attacks/black/test_pso_attack.py
-
+123 -0tests/ut/python/attacks/black/test_salt_and_pepper_attack.py
-
+74 -0tests/ut/python/attacks/test_batch_generate_attack.py
-
+90 -0tests/ut/python/attacks/test_cw.py
-
+119 -0tests/ut/python/attacks/test_deep_fool.py
-
+242 -0tests/ut/python/attacks/test_gradient_method.py
-
+136 -0tests/ut/python/attacks/test_iterative_gradient_method.py
-
+161 -0tests/ut/python/attacks/test_jsma.py
-
+72 -0tests/ut/python/attacks/test_lbfgs.py
-
+107 -0tests/ut/python/defenses/mock_net.py
-
+66 -0tests/ut/python/defenses/test_ad.py
-
+70 -0tests/ut/python/defenses/test_ead.py
-
+65 -0tests/ut/python/defenses/test_nad.py
-
+66 -0tests/ut/python/defenses/test_pad.py
-
+101 -0tests/ut/python/detectors/black/test_similarity_detector.py
-
+112 -0tests/ut/python/detectors/test_ensemble_detector.py
-
+164 -0tests/ut/python/detectors/test_mag_net.py
-
+115 -0tests/ut/python/detectors/test_region_based_detector.py
-
+116 -0tests/ut/python/detectors/test_spatial_smoothing.py
-
+73 -0tests/ut/python/evaluations/black/test_black_defense_eval.py
-
+95 -0tests/ut/python/evaluations/test_attack_eval.py
-
+51 -0tests/ut/python/evaluations/test_defense_eval.py
-
+57 -0tests/ut/python/evaluations/test_radar_metric.py
-
BINtests/ut/python/test_data/test_images.npy
+ 25
- 0
.gitee/PULL_REQUEST_TEMPLATE.md
View File
| @@ -0,0 +1,25 @@ | |||
| <!-- Thanks for sending a pull request! Here are some tips for you: | |||
| If this is your first time, please read our contributor guidelines: https://gitee.com/mindspore/mindspore/blob/master/CONTRIBUTING.md | |||
| --> | |||
| **What type of PR is this?** | |||
| > Uncomment only one ` /kind <>` line, hit enter to put that in a new line, and remove leading whitespaces from that line: | |||
| > | |||
| > /kind bug | |||
| > /kind task | |||
| > /kind feature | |||
| **What this PR does / why we need it**: | |||
| **Which issue(s) this PR fixes**: | |||
| <!-- | |||
| *Automatically closes linked issue when PR is merged. | |||
| Usage: `Fixes #<issue number>`, or `Fixes (paste link of issue)`. | |||
| --> | |||
| Fixes # | |||
| **Special notes for your reviewer**: | |||
+ 28
- 0
.gitignore
View File
| @@ -0,0 +1,28 @@ | |||
| *.dot | |||
| *.ir | |||
| *.dat | |||
| *.pyc | |||
| *.csv | |||
| *.gz | |||
| *.tar | |||
| *.zip | |||
| *.rar | |||
| *.ipynb | |||
| .idea/ | |||
| build/ | |||
| dist/ | |||
| local_script/ | |||
| example/dataset/ | |||
| example/mnist_demo/MNIST_unzip/ | |||
| example/mnist_demo/trained_ckpt_file/ | |||
| example/mnist_demo/model/ | |||
| example/cifar_demo/model/ | |||
| example/dog_cat_demo/model/ | |||
| mindarmour.egg-info/ | |||
| *model/ | |||
| *MNIST/ | |||
| *out.data/ | |||
| *defensed_model/ | |||
| *pre_trained_model/ | |||
| *__pycache__/ | |||
| *kernel_meta | |||
+ 201
- 0
LICENSE
View File
| @@ -0,0 +1,201 @@ | |||
| Apache License | |||
| Version 2.0, January 2004 | |||
| http://www.apache.org/licenses/ | |||
| TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION | |||
| 1. Definitions. | |||
| "License" shall mean the terms and conditions for use, reproduction, | |||
| and distribution as defined by Sections 1 through 9 of this document. | |||
| "Licensor" shall mean the copyright owner or entity authorized by | |||
| the copyright owner that is granting the License. | |||
| "Legal Entity" shall mean the union of the acting entity and all | |||
| other entities that control, are controlled by, or are under common | |||
| control with that entity. For the purposes of this definition, | |||
| "control" means (i) the power, direct or indirect, to cause the | |||
| direction or management of such entity, whether by contract or | |||
| otherwise, or (ii) ownership of fifty percent (50%) or more of the | |||
| outstanding shares, or (iii) beneficial ownership of such entity. | |||
| "You" (or "Your") shall mean an individual or Legal Entity | |||
| exercising permissions granted by this License. | |||
| "Source" form shall mean the preferred form for making modifications, | |||
| including but not limited to software source code, documentation | |||
| source, and configuration files. | |||
| "Object" form shall mean any form resulting from mechanical | |||
| transformation or translation of a Source form, including but | |||
| not limited to compiled object code, generated documentation, | |||
| and conversions to other media types. | |||
| "Work" shall mean the work of authorship, whether in Source or | |||
| Object form, made available under the License, as indicated by a | |||
| copyright notice that is included in or attached to the work | |||
| (an example is provided in the Appendix below). | |||
| "Derivative Works" shall mean any work, whether in Source or Object | |||
| form, that is based on (or derived from) the Work and for which the | |||
| editorial revisions, annotations, elaborations, or other modifications | |||
| represent, as a whole, an original work of authorship. For the purposes | |||
| of this License, Derivative Works shall not include works that remain | |||
| separable from, or merely link (or bind by name) to the interfaces of, | |||
| the Work and Derivative Works thereof. | |||
| "Contribution" shall mean any work of authorship, including | |||
| the original version of the Work and any modifications or additions | |||
| to that Work or Derivative Works thereof, that is intentionally | |||
| submitted to Licensor for inclusion in the Work by the copyright owner | |||
| or by an individual or Legal Entity authorized to submit on behalf of | |||
| the copyright owner. For the purposes of this definition, "submitted" | |||
| means any form of electronic, verbal, or written communication sent | |||
| to the Licensor or its representatives, including but not limited to | |||
| communication on electronic mailing lists, source code control systems, | |||
| and issue tracking systems that are managed by, or on behalf of, the | |||
| Licensor for the purpose of discussing and improving the Work, but | |||
| excluding communication that is conspicuously marked or otherwise | |||
| designated in writing by the copyright owner as "Not a Contribution." | |||
| "Contributor" shall mean Licensor and any individual or Legal Entity | |||
| on behalf of whom a Contribution has been received by Licensor and | |||
| subsequently incorporated within the Work. | |||
| 2. Grant of Copyright License. Subject to the terms and conditions of | |||
| this License, each Contributor hereby grants to You a perpetual, | |||
| worldwide, non-exclusive, no-charge, royalty-free, irrevocable | |||
| copyright license to reproduce, prepare Derivative Works of, | |||
| publicly display, publicly perform, sublicense, and distribute the | |||
| Work and such Derivative Works in Source or Object form. | |||
| 3. Grant of Patent License. Subject to the terms and conditions of | |||
| this License, each Contributor hereby grants to You a perpetual, | |||
| worldwide, non-exclusive, no-charge, royalty-free, irrevocable | |||
| (except as stated in this section) patent license to make, have made, | |||
| use, offer to sell, sell, import, and otherwise transfer the Work, | |||
| where such license applies only to those patent claims licensable | |||
| by such Contributor that are necessarily infringed by their | |||
| Contribution(s) alone or by combination of their Contribution(s) | |||
| with the Work to which such Contribution(s) was submitted. If You | |||
| institute patent litigation against any entity (including a | |||
| cross-claim or counterclaim in a lawsuit) alleging that the Work | |||
| or a Contribution incorporated within the Work constitutes direct | |||
| or contributory patent infringement, then any patent licenses | |||
| granted to You under this License for that Work shall terminate | |||
| as of the date such litigation is filed. | |||
| 4. Redistribution. You may reproduce and distribute copies of the | |||
| Work or Derivative Works thereof in any medium, with or without | |||
| modifications, and in Source or Object form, provided that You | |||
| meet the following conditions: | |||
| (a) You must give any other recipients of the Work or | |||
| Derivative Works a copy of this License; and | |||
| (b) You must cause any modified files to carry prominent notices | |||
| stating that You changed the files; and | |||
| (c) You must retain, in the Source form of any Derivative Works | |||
| that You distribute, all copyright, patent, trademark, and | |||
| attribution notices from the Source form of the Work, | |||
| excluding those notices that do not pertain to any part of | |||
| the Derivative Works; and | |||
| (d) If the Work includes a "NOTICE" text file as part of its | |||
| distribution, then any Derivative Works that You distribute must | |||
| include a readable copy of the attribution notices contained | |||
| within such NOTICE file, excluding those notices that do not | |||
| pertain to any part of the Derivative Works, in at least one | |||
| of the following places: within a NOTICE text file distributed | |||
| as part of the Derivative Works; within the Source form or | |||
| documentation, if provided along with the Derivative Works; or, | |||
| within a display generated by the Derivative Works, if and | |||
| wherever such third-party notices normally appear. The contents | |||
| of the NOTICE file are for informational purposes only and | |||
| do not modify the License. You may add Your own attribution | |||
| notices within Derivative Works that You distribute, alongside | |||
| or as an addendum to the NOTICE text from the Work, provided | |||
| that such additional attribution notices cannot be construed | |||
| as modifying the License. | |||
| You may add Your own copyright statement to Your modifications and | |||
| may provide additional or different license terms and conditions | |||
| for use, reproduction, or distribution of Your modifications, or | |||
| for any such Derivative Works as a whole, provided Your use, | |||
| reproduction, and distribution of the Work otherwise complies with | |||
| the conditions stated in this License. | |||
| 5. Submission of Contributions. Unless You explicitly state otherwise, | |||
| any Contribution intentionally submitted for inclusion in the Work | |||
| by You to the Licensor shall be under the terms and conditions of | |||
| this License, without any additional terms or conditions. | |||
| Notwithstanding the above, nothing herein shall supersede or modify | |||
| the terms of any separate license agreement you may have executed | |||
| with Licensor regarding such Contributions. | |||
| 6. Trademarks. This License does not grant permission to use the trade | |||
| names, trademarks, service marks, or product names of the Licensor, | |||
| except as required for reasonable and customary use in describing the | |||
| origin of the Work and reproducing the content of the NOTICE file. | |||
| 7. Disclaimer of Warranty. Unless required by applicable law or | |||
| agreed to in writing, Licensor provides the Work (and each | |||
| Contributor provides its Contributions) on an "AS IS" BASIS, | |||
| WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or | |||
| implied, including, without limitation, any warranties or conditions | |||
| of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A | |||
| PARTICULAR PURPOSE. You are solely responsible for determining the | |||
| appropriateness of using or redistributing the Work and assume any | |||
| risks associated with Your exercise of permissions under this License. | |||
| 8. Limitation of Liability. In no event and under no legal theory, | |||
| whether in tort (including negligence), contract, or otherwise, | |||
| unless required by applicable law (such as deliberate and grossly | |||
| negligent acts) or agreed to in writing, shall any Contributor be | |||
| liable to You for damages, including any direct, indirect, special, | |||
| incidental, or consequential damages of any character arising as a | |||
| result of this License or out of the use or inability to use the | |||
| Work (including but not limited to damages for loss of goodwill, | |||
| work stoppage, computer failure or malfunction, or any and all | |||
| other commercial damages or losses), even if such Contributor | |||
| has been advised of the possibility of such damages. | |||
| 9. Accepting Warranty or Additional Liability. While redistributing | |||
| the Work or Derivative Works thereof, You may choose to offer, | |||
| and charge a fee for, acceptance of support, warranty, indemnity, | |||
| or other liability obligations and/or rights consistent with this | |||
| License. However, in accepting such obligations, You may act only | |||
| on Your own behalf and on Your sole responsibility, not on behalf | |||
| of any other Contributor, and only if You agree to indemnify, | |||
| defend, and hold each Contributor harmless for any liability | |||
| incurred by, or claims asserted against, such Contributor by reason | |||
| of your accepting any such warranty or additional liability. | |||
| END OF TERMS AND CONDITIONS | |||
| APPENDIX: How to apply the Apache License to your work. | |||
| To apply the Apache License to your work, attach the following | |||
| boilerplate notice, with the fields enclosed by brackets "[]" | |||
| replaced with your own identifying information. (Don't include | |||
| the brackets!) The text should be enclosed in the appropriate | |||
| comment syntax for the file format. We also recommend that a | |||
| file or class name and description of purpose be included on the | |||
| same "printed page" as the copyright notice for easier | |||
| identification within third-party archives. | |||
| Copyright [yyyy] [name of copyright owner] | |||
| Licensed under the Apache License, Version 2.0 (the "License"); | |||
| you may not use this file except in compliance with the License. | |||
| You may obtain a copy of the License at | |||
| http://www.apache.org/licenses/LICENSE-2.0 | |||
| Unless required by applicable law or agreed to in writing, software | |||
| distributed under the License is distributed on an "AS IS" BASIS, | |||
| WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| See the License for the specific language governing permissions and | |||
| limitations under the License. | |||
+ 2
- 0
NOTICE
View File
| @@ -0,0 +1,2 @@ | |||
| MindSpore MindArmour | |||
| Copyright 2019-2020 Huawei Technologies Co., Ltd | |||
+ 74
- 0
README.md
View File
| @@ -0,0 +1,74 @@ | |||
| # MindArmour | |||
| - [What is MindArmour](#what-is-mindarmour) | |||
| - [Setting up](#setting-up-mindarmour) | |||
| - [Docs](#docs) | |||
| - [Community](#community) | |||
| - [Contributing](#contributing) | |||
| - [Release Notes](#release-notes) | |||
| - [License](#license) | |||
| ## What is MindArmour | |||
| A tool box for MindSpore users to enhance model security and trustworthiness. | |||
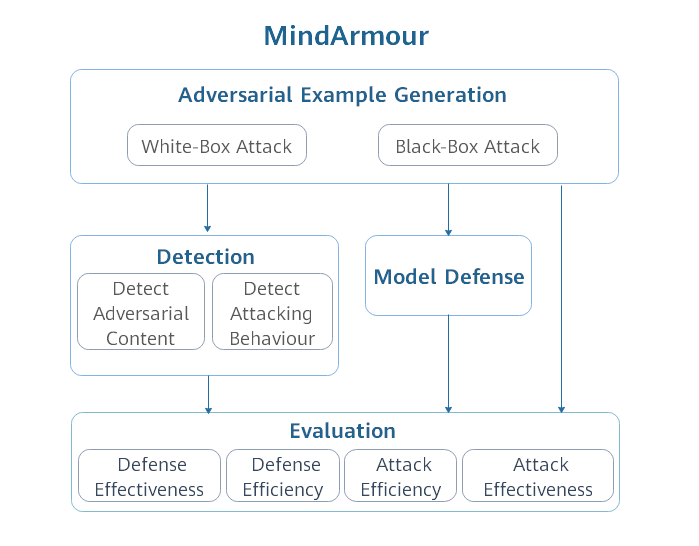
| MindArmour is designed for adversarial examples, including four submodule: adversarial examples generation, adversarial example detection, model defense and evaluation. The architecture is shown as follow: | |||
|  | |||
| ## Setting up MindArmour | |||
| ### Dependencies | |||
| This library uses MindSpore to accelerate graph computations performed by many machine learning models. Therefore, installing MindSpore is a pre-requisite. All other dependencies are included in `setup.py`. | |||
| ### Installation | |||
| #### Installation for development | |||
| 1. Download source code from Gitee. | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| 2. Compile and install in MindArmour directory. | |||
| ```bash | |||
| $ cd mindarmour | |||
| $ python setup.py install | |||
| ``` | |||
| #### `Pip` installation | |||
| 1. Download whl package from [MindSpore website](https://www.mindspore.cn/versions/en), then run the following command: | |||
| ``` | |||
| pip install mindarmour-{version}-cp37-cp37m-linux_{arch}.whl | |||
| ``` | |||
| 2. Successfully installed, if there is no error message such as `No module named 'mindarmour'` when execute the following command: | |||
| ```bash | |||
| python -c 'import mindarmour' | |||
| ``` | |||
| ## Docs | |||
| Guidance on installation, tutorials, API, see our [User Documentation](https://gitee.com/mindspore/docs). | |||
| ## Community | |||
| - [MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ) - Ask questions and find answers. | |||
| ## Contributing | |||
| Welcome contributions. See our [Contributor Wiki](https://gitee.com/mindspore/mindspore/blob/master/CONTRIBUTING.md) for more details. | |||
| ## Release Notes | |||
| The release notes, see our [RELEASE](RELEASE.md). | |||
| ## License | |||
| [Apache License 2.0](LICENSE) | |||
+ 11
- 0
RELEASE.md
View File
| @@ -0,0 +1,11 @@ | |||
| # Release 0.1.0-alpha | |||
| Initial release of MindArmour. | |||
| ## Major Features | |||
| - Support adversarial attack and defense on the platform of MindSpore. | |||
| - Include 13 white-box and 7 black-box attack methods. | |||
| - Provide 5 detection algorithms to detect attacking in multiple way. | |||
| - Provide adversarial training to enhance model security. | |||
| - Provide 6 evaluation metrics for attack methods and 9 evaluation metrics for defense methods. | |||
+ 3
- 0
docs/README.md
View File
| @@ -0,0 +1,3 @@ | |||
| # MindArmour Documentation | |||
| The MindArmour documentation is in the [MindSpore Docs](https://gitee.com/mindspore/docs) repository. | |||
BIN
docs/mindarmour_architecture.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 699 | Height: 546 | Size: 28 kB |
+ 62
- 0
example/data_processing.py
View File
| @@ -0,0 +1,62 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.transforms.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.transforms.vision import Inter | |||
| import mindspore.common.dtype as mstype | |||
| def generate_mnist_dataset(data_path, batch_size=32, repeat_size=1, | |||
| num_parallel_workers=1, sparse=True): | |||
| """ | |||
| create dataset for training or testing | |||
| """ | |||
| # define dataset | |||
| ds1 = ds.MnistDataset(data_path) | |||
| # define operation parameters | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), | |||
| interpolation=Inter.LINEAR) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| one_hot_enco = C.OneHot(10) | |||
| # apply map operations on images | |||
| if not sparse: | |||
| ds1 = ds1.map(input_columns="label", operations=one_hot_enco, | |||
| num_parallel_workers=num_parallel_workers) | |||
| type_cast_op = C.TypeCast(mstype.float32) | |||
| ds1 = ds1.map(input_columns="label", operations=type_cast_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=resize_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=rescale_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=hwc2chw_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| ds1 = ds1.shuffle(buffer_size=buffer_size) | |||
| ds1 = ds1.batch(batch_size, drop_remainder=True) | |||
| ds1 = ds1.repeat(repeat_size) | |||
| return ds1 | |||
+ 46
- 0
example/mnist_demo/README.md
View File
| @@ -0,0 +1,46 @@ | |||
| # mnist demo | |||
| ## Introduction | |||
| The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from MNIST. The digits have been size-normalized and centered in a fixed-size image. | |||
| ## run demo | |||
| ### 1. download dataset | |||
| ```sh | |||
| $ cd example/mnist_demo | |||
| $ mkdir MNIST_unzip | |||
| $ cd MNIST_unzip | |||
| $ mkdir train | |||
| $ mkdir test | |||
| $ cd train | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz" | |||
| $ gzip train-images-idx3-ubyte.gz -d | |||
| $ gzip train-labels-idx1-ubyte.gz -d | |||
| $ cd ../test | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz" | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ cd ../../ | |||
| ``` | |||
| ### 1. trian model | |||
| ```sh | |||
| $ python mnist_train.py | |||
| ``` | |||
| ### 2. run attack test | |||
| ```sh | |||
| $ mkdir out.data | |||
| $ python mnist_attack_jsma.py | |||
| ``` | |||
| ### 3. run defense/detector test | |||
| ```sh | |||
| $ python mnist_defense_nad.py | |||
| $ python mnist_similarity_detector.py | |||
| ``` | |||
+ 64
- 0
example/mnist_demo/lenet5_net.py
View File
| @@ -0,0 +1,64 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import mindspore.nn as nn | |||
| import mindspore.ops.operations as P | |||
| from mindspore.common.initializer import TruncatedNormal | |||
| def conv(in_channels, out_channels, kernel_size, stride=1, padding=0): | |||
| weight = weight_variable() | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=kernel_size, stride=stride, padding=padding, | |||
| weight_init=weight, has_bias=False, pad_mode="valid") | |||
| def fc_with_initialize(input_channels, out_channels): | |||
| weight = weight_variable() | |||
| bias = weight_variable() | |||
| return nn.Dense(input_channels, out_channels, weight, bias) | |||
| def weight_variable(): | |||
| return TruncatedNormal(0.2) | |||
| class LeNet5(nn.Cell): | |||
| """ | |||
| Lenet network | |||
| """ | |||
| def __init__(self): | |||
| super(LeNet5, self).__init__() | |||
| self.conv1 = conv(1, 6, 5) | |||
| self.conv2 = conv(6, 16, 5) | |||
| self.fc1 = fc_with_initialize(16*5*5, 120) | |||
| self.fc2 = fc_with_initialize(120, 84) | |||
| self.fc3 = fc_with_initialize(84, 10) | |||
| self.relu = nn.ReLU() | |||
| self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) | |||
| self.reshape = P.Reshape() | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.conv2(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.reshape(x, (-1, 16*5*5)) | |||
| x = self.fc1(x) | |||
| x = self.relu(x) | |||
| x = self.fc2(x) | |||
| x = self.relu(x) | |||
| x = self.fc3(x) | |||
| return x | |||
+ 118
- 0
example/mnist_demo/mnist_attack_cw.py
View File
| @@ -0,0 +1,118 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.carlini_wagner import CarliniWagnerL2Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'CW_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_carlini_wagner_attack(): | |||
| """ | |||
| CW-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| num_classes = 10 | |||
| attack = CarliniWagnerL2Attack(net, num_classes, targeted=False) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| accuracy_adv) | |||
| test_labels = np.eye(10)[np.concatenate(test_labels)] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| test_labels, adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_carlini_wagner_attack() | |||
+ 120
- 0
example/mnist_demo/mnist_attack_deepfool.py
View File
| @@ -0,0 +1,120 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.deep_fool import DeepFool | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'DeepFool_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_deepfool_attack(): | |||
| """ | |||
| DeepFool-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| classes = 10 | |||
| attack = DeepFool(net, classes, norm_level=2, | |||
| bounds=(0.0, 1.0)) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| accuracy_adv) | |||
| test_labels = np.eye(10)[np.concatenate(test_labels)] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| test_labels, adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_deepfool_attack() | |||
+ 119
- 0
example/mnist_demo/mnist_attack_fgsm.py
View File
| @@ -0,0 +1,119 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'FGSM_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_sign_method(): | |||
| """ | |||
| FGSM-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| np.save('./adv_data', adv_data) | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_fast_gradient_sign_method() | |||
+ 138
- 0
example/mnist_demo/mnist_attack_genetic.py
View File
| @@ -0,0 +1,138 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Genetic_Attack' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_genetic_attack_on_mnist(): | |||
| """ | |||
| Genetic-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = ModelToBeAttacked(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %g", accuracy) | |||
| # attacking | |||
| attack = GeneticAttack(model=model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=True) | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| start_time = time.clock() | |||
| success_list, adv_data, query_list = attack.generate( | |||
| np.concatenate(test_images), targeted_labels) | |||
| stop_time = time.clock() | |||
| LOGGER.info(TAG, 'success_list: %s', success_list) | |||
| LOGGER.info(TAG, 'average of query times is : %s', np.mean(query_list)) | |||
| pred_logits_adv = model.predict(adv_data) | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| test_labels_onehot = np.eye(10)[true_labels] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| pred_logits_adv, targeted=True, | |||
| target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_genetic_attack_on_mnist() | |||
+ 150
- 0
example/mnist_demo/mnist_attack_hsja.py
View File
| @@ -0,0 +1,150 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.hop_skip_jump_attack import HopSkipJumpAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'HopSkipJumpAttack' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| if len(inputs.shape) == 3: | |||
| inputs = inputs[np.newaxis, :] | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| def random_target_labels(true_labels): | |||
| target_labels = [] | |||
| for label in true_labels: | |||
| while True: | |||
| target_label = np.random.randint(0, 10) | |||
| if target_label != label: | |||
| target_labels.append(target_label) | |||
| break | |||
| return target_labels | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_hsja_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = ModelToBeAttacked(net) | |||
| batch_num = 5 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", | |||
| accuracy) | |||
| test_images = np.concatenate(test_images) | |||
| # attacking | |||
| norm = 'l2' | |||
| search = 'grid_search' | |||
| target = False | |||
| attack = HopSkipJumpAttack(model, constraint=norm, stepsize_search=search) | |||
| if target: | |||
| target_labels = random_target_labels(true_labels) | |||
| target_images = create_target_images(test_images, predict_labels, | |||
| target_labels) | |||
| attack.set_target_images(target_images) | |||
| success_list, adv_data, query_list = attack.generate(test_images, target_labels) | |||
| else: | |||
| success_list, adv_data, query_list = attack.generate(test_images, None) | |||
| adv_datas = [] | |||
| gts = [] | |||
| for success, adv, gt in zip(success_list, adv_data, true_labels): | |||
| if success: | |||
| adv_datas.append(adv) | |||
| gts.append(gt) | |||
| if len(gts) > 0: | |||
| adv_datas = np.concatenate(np.asarray(adv_datas), axis=0) | |||
| gts = np.asarray(gts) | |||
| pred_logits_adv = model.predict(adv_datas) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, gts)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| accuracy_adv) | |||
| if __name__ == '__main__': | |||
| test_hsja_mnist_attack() | |||
+ 124
- 0
example/mnist_demo/mnist_attack_jsma.py
View File
| @@ -0,0 +1,124 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.jsma import JSMAAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'JSMA_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %g", accuracy) | |||
| # attacking | |||
| classes = 10 | |||
| attack = JSMAAttack(net, classes) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| targeted_labels, batch_size=32) | |||
| stop_time = time.clock() | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| test_labels = np.eye(10)[np.concatenate(test_labels)] | |||
| attack_evaluate = AttackEvaluate( | |||
| np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| test_labels, adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv, targeted=True, target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time) / (batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_jsma_attack() | |||
+ 132
- 0
example/mnist_demo/mnist_attack_lbfgs.py
View File
| @@ -0,0 +1,132 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.lbfgs import LBFGS | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'LBFGS_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_lbfgs_attack(): | |||
| """ | |||
| LBFGS-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| is_targeted = True | |||
| if is_targeted: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)).astype(np.int32) | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels.astype(np.int32) | |||
| targeted_labels = np.eye(10)[targeted_labels].astype(np.float32) | |||
| attack = LBFGS(net, is_targeted=is_targeted) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| targeted_labels, | |||
| batch_size=batch_size) | |||
| stop_time = time.clock() | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv, | |||
| targeted=is_targeted, | |||
| target_label=np.argmax(targeted_labels, | |||
| axis=1)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_lbfgs_attack() | |||
+ 168
- 0
example/mnist_demo/mnist_attack_nes.py
View File
| @@ -0,0 +1,168 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.natural_evolutionary_strategy import NES | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'HopSkipJumpAttack' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| if len(inputs.shape) == 3: | |||
| inputs = inputs[np.newaxis, :] | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| def random_target_labels(true_labels, labels_list): | |||
| target_labels = [] | |||
| for label in true_labels: | |||
| while True: | |||
| target_label = np.random.choice(labels_list) | |||
| if target_label != label: | |||
| target_labels.append(target_label) | |||
| break | |||
| return target_labels | |||
| def _pseudorandom_target(index, total_indices, true_class): | |||
| """ pseudo random_target """ | |||
| rng = np.random.RandomState(index) | |||
| target = true_class | |||
| while target == true_class: | |||
| target = rng.randint(0, total_indices) | |||
| return target | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nes_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = ModelToBeAttacked(net) | |||
| # the number of batches of attacking samples | |||
| batch_num = 5 | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", | |||
| accuracy) | |||
| test_images = np.concatenate(test_images) | |||
| # attacking | |||
| scene = 'Query_Limit' | |||
| if scene == 'Query_Limit': | |||
| top_k = -1 | |||
| elif scene == 'Partial_Info': | |||
| top_k = 5 | |||
| elif scene == 'Label_Only': | |||
| top_k = 5 | |||
| success = 0 | |||
| queries_num = 0 | |||
| nes_instance = NES(model, scene, top_k=top_k) | |||
| test_length = 32 | |||
| advs = [] | |||
| for img_index in range(test_length): | |||
| # Initial image and class selection | |||
| initial_img = test_images[img_index] | |||
| orig_class = true_labels[img_index] | |||
| initial_img = [initial_img] | |||
| target_class = random_target_labels([orig_class], true_labels) | |||
| target_image = create_target_images(test_images, true_labels, | |||
| target_class) | |||
| nes_instance.set_target_images(target_image) | |||
| tag, adv, queries = nes_instance.generate(initial_img, target_class) | |||
| if tag[0]: | |||
| success += 1 | |||
| queries_num += queries[0] | |||
| advs.append(adv) | |||
| advs = np.reshape(advs, (len(advs), 1, 32, 32)) | |||
| adv_pred = np.argmax(model.predict(advs), axis=1) | |||
| adv_accuracy = np.mean(np.equal(adv_pred, true_labels[:test_length])) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| adv_accuracy) | |||
| if __name__ == '__main__': | |||
| test_nes_mnist_attack() | |||
+ 119
- 0
example/mnist_demo/mnist_attack_pgd.py
View File
| @@ -0,0 +1,119 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.iterative_gradient_method import ProjectedGradientDescent | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'PGD_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_projected_gradient_descent_method(): | |||
| """ | |||
| PGD-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 32 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| attack = ProjectedGradientDescent(net, eps=0.3) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| np.save('./adv_data', adv_data) | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_projected_gradient_descent_method() | |||
+ 138
- 0
example/mnist_demo/mnist_attack_pointwise.py
View File
| @@ -0,0 +1,138 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.pointwise_attack import PointWiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Pointwise_Attack' | |||
| LOGGER.set_level('INFO') | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| if len(inputs.shape) == 3: | |||
| inputs = inputs[np.newaxis, :] | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pointwise_attack_on_mnist(): | |||
| """ | |||
| Salt-and-Pepper-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = ModelToBeAttacked(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %g", accuracy) | |||
| # attacking | |||
| is_target = False | |||
| attack = PointWiseAttack(model=model, is_targeted=is_target) | |||
| if is_target: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels | |||
| success_list, adv_data, query_list = attack.generate( | |||
| np.concatenate(test_images), targeted_labels) | |||
| success_list = np.arange(success_list.shape[0])[success_list] | |||
| LOGGER.info(TAG, 'success_list: %s', success_list) | |||
| LOGGER.info(TAG, 'average of query times is : %s', np.mean(query_list)) | |||
| adv_preds = [] | |||
| for ite_data in adv_data: | |||
| pred_logits_adv = model.predict(ite_data) | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| adv_preds.extend(pred_logits_adv) | |||
| accuracy_adv = np.mean(np.equal(np.max(adv_preds, axis=1), true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| test_labels_onehot = np.eye(10)[true_labels] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| adv_preds, targeted=is_target, | |||
| target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| if __name__ == '__main__': | |||
| test_pointwise_attack_on_mnist() | |||
+ 131
- 0
example/mnist_demo/mnist_attack_pso.py
View File
| @@ -0,0 +1,131 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'PSO_Attack' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack_on_mnist(): | |||
| """ | |||
| PSO-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = ModelToBeAttacked(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| attack = PSOAttack(model, bounds=(0.0, 1.0), pm=0.5, sparse=True) | |||
| start_time = time.clock() | |||
| success_list, adv_data, query_list = attack.generate( | |||
| np.concatenate(test_images), np.concatenate(test_labels)) | |||
| stop_time = time.clock() | |||
| LOGGER.info(TAG, 'success_list: %s', success_list) | |||
| LOGGER.info(TAG, 'average of query times is : %s', np.mean(query_list)) | |||
| pred_logits_adv = model.predict(adv_data) | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| accuracy_adv) | |||
| test_labels_onehot = np.eye(10)[np.concatenate(test_labels)] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| test_pso_attack_on_mnist() | |||
+ 142
- 0
example/mnist_demo/mnist_attack_salt_and_pepper.py
View File
| @@ -0,0 +1,142 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.salt_and_pepper_attack import SaltAndPepperNoiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Salt_and_Pepper_Attack' | |||
| LOGGER.set_level('DEBUG') | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| if len(inputs.shape) == 3: | |||
| inputs = inputs[np.newaxis, :] | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_salt_and_pepper_attack_on_mnist(): | |||
| """ | |||
| Salt-and-Pepper-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| # prediction accuracy before attack | |||
| model = ModelToBeAttacked(net) | |||
| batch_num = 3 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| LOGGER.debug(TAG, 'model input image shape is: {}'.format(np.array(test_images).shape)) | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %g", accuracy) | |||
| # attacking | |||
| is_target = False | |||
| attack = SaltAndPepperNoiseAttack(model=model, | |||
| is_targeted=is_target, | |||
| sparse=True) | |||
| if is_target: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels | |||
| LOGGER.debug(TAG, 'input shape is: {}'.format(np.concatenate(test_images).shape)) | |||
| success_list, adv_data, query_list = attack.generate( | |||
| np.concatenate(test_images), targeted_labels) | |||
| success_list = np.arange(success_list.shape[0])[success_list] | |||
| LOGGER.info(TAG, 'success_list: %s', success_list) | |||
| LOGGER.info(TAG, 'average of query times is : %s', np.mean(query_list)) | |||
| adv_preds = [] | |||
| for ite_data in adv_data: | |||
| pred_logits_adv = model.predict(ite_data) | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| adv_preds.extend(pred_logits_adv) | |||
| accuracy_adv = np.mean(np.equal(np.max(adv_preds, axis=1), true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| test_labels_onehot = np.eye(10)[true_labels] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| adv_preds, targeted=is_target, | |||
| target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| if __name__ == '__main__': | |||
| test_salt_and_pepper_attack_on_mnist() | |||
+ 144
- 0
example/mnist_demo/mnist_defense_nad.py
View File
| @@ -0,0 +1,144 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """defense example using nad""" | |||
| import sys | |||
| import logging | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| from mindarmour.defenses import NaturalAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Nad_Example' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nad_method(): | |||
| """ | |||
| NAD-Defense test. | |||
| """ | |||
| # 1. load trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| opt = nn.Momentum(net.trainable_params(), 0.01, 0.09) | |||
| nad = NaturalAdversarialDefense(net, loss_fn=loss, optimizer=opt, | |||
| bounds=(0.0, 1.0), eps=0.3) | |||
| # 2. get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size, | |||
| sparse=False) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs) | |||
| labels = np.concatenate(labels) | |||
| # 3. get accuracy of test data on original model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = inputs.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = inputs[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of TEST data on original model is : %s', | |||
| np.mean(acc_list)) | |||
| # 4. get adv of test data | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| adv_data = attack.batch_generate(inputs, labels) | |||
| LOGGER.debug(TAG, 'adv_data.shape is : %s', adv_data.shape) | |||
| # 5. get accuracy of adv data on original model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = adv_data.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = adv_data[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of adv data on original model is : %s', | |||
| np.mean(acc_list)) | |||
| # 6. defense | |||
| net.set_train() | |||
| nad.batch_defense(inputs, labels, batch_size=32, epochs=10) | |||
| # 7. get accuracy of test data on defensed model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = inputs.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = inputs[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of TEST data on defensed model is : %s', | |||
| np.mean(acc_list)) | |||
| # 8. get accuracy of adv data on defensed model | |||
| acc_list = [] | |||
| batchs = adv_data.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = adv_data[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of adv data on defensed model is : %s', | |||
| np.mean(acc_list)) | |||
| if __name__ == '__main__': | |||
| LOGGER.set_level(logging.DEBUG) | |||
| test_nad_method() | |||
+ 326
- 0
example/mnist_demo/mnist_evaluation.py
View File
| @@ -0,0 +1,326 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """evaluate example""" | |||
| import sys | |||
| import os | |||
| import time | |||
| import numpy as np | |||
| from scipy.special import softmax | |||
| from lenet5_net import LeNet5 | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| from mindarmour.attacks import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.defenses import NaturalAdversarialDefense | |||
| from mindarmour.evaluations import BlackDefenseEvaluate | |||
| from mindarmour.evaluations import DefenseEvaluate | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Defense_Evaluate_Example' | |||
| def get_detector(train_images): | |||
| encoder = Model(EncoderNet(encode_dim=256)) | |||
| detector = SimilarityDetector(max_k_neighbor=50, trans_model=encoder) | |||
| detector.fit(inputs=train_images) | |||
| return detector | |||
| class EncoderNet(Cell): | |||
| """ | |||
| Similarity encoder for input data | |||
| """ | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| construct the neural network | |||
| Args: | |||
| inputs (Tensor): input data to neural network. | |||
| Returns: | |||
| Tensor, output of neural network. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| def get_encode_dim(self): | |||
| """ | |||
| Get the dimension of encoded inputs | |||
| Returns: | |||
| int, dimension of encoded inputs. | |||
| """ | |||
| return self._encode_dim | |||
| class ModelToBeAttacked(BlackModel): | |||
| """ | |||
| model to be attack | |||
| """ | |||
| def __init__(self, network, defense=False, train_images=None): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| self._queries = [] | |||
| self._defense = defense | |||
| self._detector = None | |||
| self._detected_res = [] | |||
| if self._defense: | |||
| self._detector = get_detector(train_images) | |||
| def predict(self, inputs): | |||
| """ | |||
| predict function | |||
| """ | |||
| query_num = inputs.shape[0] | |||
| results = [] | |||
| if self._detector: | |||
| for i in range(query_num): | |||
| query = np.expand_dims(inputs[i].astype(np.float32), axis=0) | |||
| result = self._network(Tensor(query)).asnumpy() | |||
| det_num = len(self._detector.get_detected_queries()) | |||
| self._detector.detect([query]) | |||
| new_det_num = len(self._detector.get_detected_queries()) | |||
| # If attack query detected, return random predict result | |||
| if new_det_num > det_num: | |||
| results.append(result + np.random.rand(*result.shape)) | |||
| self._detected_res.append(True) | |||
| else: | |||
| results.append(result) | |||
| self._detected_res.append(False) | |||
| results = np.concatenate(results) | |||
| else: | |||
| results = self._network(Tensor(inputs.astype(np.float32))).asnumpy() | |||
| return results | |||
| def get_detected_result(self): | |||
| return self._detected_res | |||
| def test_black_defense(): | |||
| # load trained network | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| ckpt_name = os.path.abspath(os.path.join( | |||
| current_dir, './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt')) | |||
| # ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| wb_net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(wb_net, load_dict) | |||
| # get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size, | |||
| sparse=False) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs).astype(np.float32) | |||
| labels = np.concatenate(labels).astype(np.float32) | |||
| labels_sparse = np.argmax(labels, axis=1) | |||
| target_label = np.random.randint(0, 10, size=labels_sparse.shape[0]) | |||
| for idx in range(labels_sparse.shape[0]): | |||
| while target_label[idx] == labels_sparse[idx]: | |||
| target_label[idx] = np.random.randint(0, 10) | |||
| target_label = np.eye(10)[target_label].astype(np.float32) | |||
| attacked_size = 50 | |||
| benign_size = 500 | |||
| attacked_sample = inputs[:attacked_size] | |||
| attacked_true_label = labels[:attacked_size] | |||
| benign_sample = inputs[attacked_size:attacked_size + benign_size] | |||
| wb_model = ModelToBeAttacked(wb_net) | |||
| # gen white-box adversarial examples of test data | |||
| wb_attack = FastGradientSignMethod(wb_net, eps=0.3) | |||
| wb_adv_sample = wb_attack.generate(attacked_sample, | |||
| attacked_true_label) | |||
| wb_raw_preds = softmax(wb_model.predict(wb_adv_sample), axis=1) | |||
| accuracy_test = np.mean( | |||
| np.equal(np.argmax(wb_model.predict(attacked_sample), axis=1), | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy before white-box attack is : %s", | |||
| accuracy_test) | |||
| accuracy_adv = np.mean(np.equal(np.argmax(wb_raw_preds, axis=1), | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy after white-box attack is : %s", | |||
| accuracy_adv) | |||
| # improve the robustness of model with white-box adversarial examples | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| opt = nn.Momentum(wb_net.trainable_params(), 0.01, 0.09) | |||
| nad = NaturalAdversarialDefense(wb_net, loss_fn=loss, optimizer=opt, | |||
| bounds=(0.0, 1.0), eps=0.3) | |||
| wb_net.set_train(False) | |||
| nad.batch_defense(inputs[:5000], labels[:5000], batch_size=32, epochs=10) | |||
| wb_def_preds = wb_net(Tensor(wb_adv_sample)).asnumpy() | |||
| wb_def_preds = softmax(wb_def_preds, axis=1) | |||
| accuracy_def = np.mean(np.equal(np.argmax(wb_def_preds, axis=1), | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy after defense is : %s", accuracy_def) | |||
| # calculate defense evaluation metrics for defense against white-box attack | |||
| wb_def_evaluate = DefenseEvaluate(wb_raw_preds, wb_def_preds, | |||
| np.argmax(attacked_true_label, axis=1)) | |||
| LOGGER.info(TAG, 'defense evaluation for white-box adversarial attack') | |||
| LOGGER.info(TAG, | |||
| 'classification accuracy variance (CAV) is : {:.2f}'.format( | |||
| wb_def_evaluate.cav())) | |||
| LOGGER.info(TAG, 'classification rectify ratio (CRR) is : {:.2f}'.format( | |||
| wb_def_evaluate.crr())) | |||
| LOGGER.info(TAG, 'classification sacrifice ratio (CSR) is : {:.2f}'.format( | |||
| wb_def_evaluate.csr())) | |||
| LOGGER.info(TAG, | |||
| 'classification confidence variance (CCV) is : {:.2f}'.format( | |||
| wb_def_evaluate.ccv())) | |||
| LOGGER.info(TAG, 'classification output stability is : {:.2f}'.format( | |||
| wb_def_evaluate.cos())) | |||
| # calculate defense evaluation metrics for defense against black-box attack | |||
| LOGGER.info(TAG, 'defense evaluation for black-box adversarial attack') | |||
| bb_raw_preds = [] | |||
| bb_def_preds = [] | |||
| raw_query_counts = [] | |||
| raw_query_time = [] | |||
| def_query_counts = [] | |||
| def_query_time = [] | |||
| def_detection_counts = [] | |||
| # gen black-box adversarial examples of test data | |||
| bb_net = LeNet5() | |||
| load_param_into_net(bb_net, load_dict) | |||
| bb_model = ModelToBeAttacked(bb_net, defense=False) | |||
| attack_rm = GeneticAttack(model=bb_model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| attack_target_label = target_label[:attacked_size] | |||
| true_label = labels_sparse[:attacked_size + benign_size] | |||
| # evaluate robustness of original model | |||
| # gen black-box adversarial examples of test data | |||
| for idx in range(attacked_size): | |||
| raw_st = time.time() | |||
| raw_sl, raw_a, raw_qc = attack_rm.generate( | |||
| np.expand_dims(attacked_sample[idx], axis=0), | |||
| np.expand_dims(attack_target_label[idx], axis=0)) | |||
| raw_t = time.time() - raw_st | |||
| bb_raw_preds.extend(softmax(bb_model.predict(raw_a), axis=1)) | |||
| raw_query_counts.extend(raw_qc) | |||
| raw_query_time.append(raw_t) | |||
| for idx in range(benign_size): | |||
| raw_st = time.time() | |||
| bb_raw_pred = softmax( | |||
| bb_model.predict(np.expand_dims(benign_sample[idx], axis=0)), | |||
| axis=1) | |||
| raw_t = time.time() - raw_st | |||
| bb_raw_preds.extend(bb_raw_pred) | |||
| raw_query_counts.extend([0]) | |||
| raw_query_time.append(raw_t) | |||
| accuracy_test = np.mean( | |||
| np.equal(np.argmax(bb_raw_preds[0:len(attack_target_label)], axis=1), | |||
| np.argmax(attack_target_label, axis=1))) | |||
| LOGGER.info(TAG, "attack success before adv defense is : %s", | |||
| accuracy_test) | |||
| # improve the robustness of model with similarity-based detector | |||
| bb_def_model = ModelToBeAttacked(bb_net, defense=True, | |||
| train_images=inputs[0:6000]) | |||
| # attack defensed model | |||
| attack_dm = GeneticAttack(model=bb_def_model, pop_size=6, | |||
| mutation_rate=0.05, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| for idx in range(attacked_size): | |||
| def_st = time.time() | |||
| def_sl, def_a, def_qc = attack_dm.generate( | |||
| np.expand_dims(attacked_sample[idx], axis=0), | |||
| np.expand_dims(attack_target_label[idx], axis=0)) | |||
| def_t = time.time() - def_st | |||
| det_res = bb_def_model.get_detected_result() | |||
| def_detection_counts.append(np.sum(det_res[-def_qc[0]:])) | |||
| bb_def_preds.extend(softmax(bb_def_model.predict(def_a), axis=1)) | |||
| def_query_counts.extend(def_qc) | |||
| def_query_time.append(def_t) | |||
| for idx in range(benign_size): | |||
| def_st = time.time() | |||
| bb_def_pred = softmax( | |||
| bb_def_model.predict(np.expand_dims(benign_sample[idx], axis=0)), | |||
| axis=1) | |||
| def_t = time.time() - def_st | |||
| det_res = bb_def_model.get_detected_result() | |||
| def_detection_counts.append(np.sum(det_res[-1])) | |||
| bb_def_preds.extend(bb_def_pred) | |||
| def_query_counts.extend([0]) | |||
| def_query_time.append(def_t) | |||
| accuracy_adv = np.mean( | |||
| np.equal(np.argmax(bb_def_preds[0:len(attack_target_label)], axis=1), | |||
| np.argmax(attack_target_label, axis=1))) | |||
| LOGGER.info(TAG, "attack success rate after adv defense is : %s", | |||
| accuracy_adv) | |||
| bb_raw_preds = np.array(bb_raw_preds).astype(np.float32) | |||
| bb_def_preds = np.array(bb_def_preds).astype(np.float32) | |||
| # check evaluate data | |||
| max_queries = 6000 | |||
| def_evaluate = BlackDefenseEvaluate(bb_raw_preds, bb_def_preds, | |||
| np.array(raw_query_counts), | |||
| np.array(def_query_counts), | |||
| np.array(raw_query_time), | |||
| np.array(def_query_time), | |||
| np.array(def_detection_counts), | |||
| true_label, max_queries) | |||
| LOGGER.info(TAG, 'query count variance of adversaries is : {:.2f}'.format( | |||
| def_evaluate.qcv())) | |||
| LOGGER.info(TAG, 'attack success rate variance of adversaries ' | |||
| 'is : {:.2f}'.format(def_evaluate.asv())) | |||
| LOGGER.info(TAG, 'false positive rate (FPR) of the query-based detector ' | |||
| 'is : {:.2f}'.format(def_evaluate.fpr())) | |||
| LOGGER.info(TAG, 'the benign query response time variance (QRV) ' | |||
| 'is : {:.2f}'.format(def_evaluate.qrv())) | |||
| if __name__ == '__main__': | |||
| test_black_defense() | |||
+ 182
- 0
example/mnist_demo/mnist_similarity_detector.py
View File
| @@ -0,0 +1,182 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Similarity Detector test' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """ | |||
| model to be attack | |||
| """ | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| self._queries = [] | |||
| def predict(self, inputs): | |||
| """ | |||
| predict function | |||
| """ | |||
| query_num = inputs.shape[0] | |||
| for i in range(query_num): | |||
| self._queries.append(inputs[i].astype(np.float32)) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| def get_queries(self): | |||
| return self._queries | |||
| class EncoderNet(Cell): | |||
| """ | |||
| Similarity encoder for input data | |||
| """ | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| construct the neural network | |||
| Args: | |||
| inputs (Tensor): input data to neural network. | |||
| Returns: | |||
| Tensor, output of neural network. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| def get_encode_dim(self): | |||
| """ | |||
| Get the dimension of encoded inputs | |||
| Returns: | |||
| int, dimension of encoded inputs. | |||
| """ | |||
| return self._encode_dim | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_similarity_detector(): | |||
| """ | |||
| Similarity Detector test. | |||
| """ | |||
| # load trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get mnist data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 1000 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| model = ModelToBeAttacked(net) | |||
| batch_num = 10 # the number of batches of input samples | |||
| all_images = [] | |||
| true_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| all_images.append(images) | |||
| true_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(images), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| all_images = np.concatenate(all_images) | |||
| true_labels = np.concatenate(true_labels) | |||
| predict_labels = np.concatenate(predict_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| train_images = all_images[0:6000, :, :, :] | |||
| attacked_images = all_images[0:10, :, :, :] | |||
| attacked_labels = true_labels[0:10] | |||
| # generate malicious query sequence of black attack | |||
| attack = PSOAttack(model, bounds=(0.0, 1.0), pm=0.5, sparse=True, | |||
| t_max=1000) | |||
| success_list, adv_data, query_list = attack.generate(attacked_images, | |||
| attacked_labels) | |||
| LOGGER.info(TAG, 'pso attack success_list: %s', success_list) | |||
| LOGGER.info(TAG, 'average of query counts is : %s', np.mean(query_list)) | |||
| pred_logits_adv = model.predict(adv_data) | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, attacked_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| benign_queries = all_images[6000:10000, :, :, :] | |||
| suspicious_queries = model.get_queries() | |||
| # explicit threshold not provided, calculate threshold for K | |||
| encoder = Model(EncoderNet(encode_dim=256)) | |||
| detector = SimilarityDetector(max_k_neighbor=50, trans_model=encoder) | |||
| detector.fit(inputs=train_images) | |||
| # test benign queries | |||
| detector.detect(benign_queries) | |||
| fpr = len(detector.get_detected_queries()) / benign_queries.shape[0] | |||
| LOGGER.info(TAG, 'Number of false positive of attack detector is : %s', | |||
| len(detector.get_detected_queries())) | |||
| LOGGER.info(TAG, 'False positive rate of attack detector is : %s', fpr) | |||
| # test attack queries | |||
| detector.clear_buffer() | |||
| detector.detect(suspicious_queries) | |||
| LOGGER.info(TAG, 'Number of detected attack queries is : %s', | |||
| len(detector.get_detected_queries())) | |||
| LOGGER.info(TAG, 'The detected attack query indexes are : %s', | |||
| detector.get_detected_queries()) | |||
| if __name__ == '__main__': | |||
| test_similarity_detector() | |||
+ 88
- 0
example/mnist_demo/mnist_train.py
View File
| @@ -0,0 +1,88 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| import os | |||
| import sys | |||
| import mindspore.nn as nn | |||
| from mindspore import context, Tensor | |||
| from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.train import Model | |||
| import mindspore.ops.operations as P | |||
| from mindspore.nn.metrics import Accuracy | |||
| from mindspore.ops import functional as F | |||
| from mindspore.common import dtype as mstype | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Lenet5_train' | |||
| class CrossEntropyLoss(nn.Cell): | |||
| """ | |||
| Define loss for network | |||
| """ | |||
| def __init__(self): | |||
| super(CrossEntropyLoss, self).__init__() | |||
| self.cross_entropy = P.SoftmaxCrossEntropyWithLogits() | |||
| self.mean = P.ReduceMean() | |||
| self.one_hot = P.OneHot() | |||
| self.on_value = Tensor(1.0, mstype.float32) | |||
| self.off_value = Tensor(0.0, mstype.float32) | |||
| def construct(self, logits, label): | |||
| label = self.one_hot(label, F.shape(logits)[1], self.on_value, self.off_value) | |||
| loss = self.cross_entropy(logits, label)[0] | |||
| loss = self.mean(loss, (-1,)) | |||
| return loss | |||
| def mnist_train(epoch_size, batch_size, lr, momentum): | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", | |||
| enable_mem_reuse=False) | |||
| lr = lr | |||
| momentum = momentum | |||
| epoch_size = epoch_size | |||
| mnist_path = "./MNIST_unzip/" | |||
| ds = generate_mnist_dataset(os.path.join(mnist_path, "train"), | |||
| batch_size=batch_size, repeat_size=1) | |||
| network = LeNet5() | |||
| network.set_train() | |||
| net_loss = CrossEntropyLoss() | |||
| net_opt = nn.Momentum(network.trainable_params(), lr, momentum) | |||
| config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10) | |||
| ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory='./trained_ckpt_file/', config=config_ck) | |||
| model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()}) | |||
| LOGGER.info(TAG, "============== Starting Training ==============") | |||
| model.train(epoch_size, ds, callbacks=[ckpoint_cb, LossMonitor()], dataset_sink_mode=False) # train | |||
| LOGGER.info(TAG, "============== Starting Testing ==============") | |||
| param_dict = load_checkpoint("trained_ckpt_file/checkpoint_lenet-10_1875.ckpt") | |||
| load_param_into_net(network, param_dict) | |||
| ds_eval = generate_mnist_dataset(os.path.join(mnist_path, "test"), batch_size=batch_size) | |||
| acc = model.eval(ds_eval) | |||
| LOGGER.info(TAG, "============== Accuracy: %s ==============", acc) | |||
| if __name__ == '__main__': | |||
| mnist_train(10, 32, 0.001, 0.9) | |||
+ 13
- 0
mindarmour/__init__.py
View File
| @@ -0,0 +1,13 @@ | |||
| """ | |||
| MindArmour, a tool box of MindSpore to enhance model security and | |||
| trustworthiness against adversarial examples. | |||
| """ | |||
| from .attacks import Attack | |||
| from .attacks.black.black_model import BlackModel | |||
| from .defenses.defense import Defense | |||
| from .detectors.detector import Detector | |||
| __all__ = ['Attack', | |||
| 'BlackModel', | |||
| 'Detector', | |||
| 'Defense'] | |||
+ 39
- 0
mindarmour/attacks/__init__.py
View File
| @@ -0,0 +1,39 @@ | |||
| """ | |||
| This module includes classical black-box and white-box attack algorithms | |||
| in making adversarial examples. | |||
| """ | |||
| from .gradient_method import * | |||
| from .iterative_gradient_method import * | |||
| from .deep_fool import DeepFool | |||
| from .jsma import JSMAAttack | |||
| from .carlini_wagner import CarliniWagnerL2Attack | |||
| from .lbfgs import LBFGS | |||
| from . import black | |||
| from .black.hop_skip_jump_attack import HopSkipJumpAttack | |||
| from .black.genetic_attack import GeneticAttack | |||
| from .black.natural_evolutionary_strategy import NES | |||
| from .black.pointwise_attack import PointWiseAttack | |||
| from .black.pso_attack import PSOAttack | |||
| from .black.salt_and_pepper_attack import SaltAndPepperNoiseAttack | |||
| __all__ = ['FastGradientMethod', | |||
| 'RandomFastGradientMethod', | |||
| 'FastGradientSignMethod', | |||
| 'RandomFastGradientSignMethod', | |||
| 'LeastLikelyClassMethod', | |||
| 'RandomLeastLikelyClassMethod', | |||
| 'IterativeGradientMethod', | |||
| 'BasicIterativeMethod', | |||
| 'MomentumIterativeMethod', | |||
| 'ProjectedGradientDescent', | |||
| 'DeepFool', | |||
| 'CarliniWagnerL2Attack', | |||
| 'JSMAAttack', | |||
| 'LBFGS', | |||
| 'GeneticAttack', | |||
| 'HopSkipJumpAttack', | |||
| 'NES', | |||
| 'PointWiseAttack', | |||
| 'PSOAttack', | |||
| 'SaltAndPepperNoiseAttack' | |||
| ] | |||
+ 97
- 0
mindarmour/attacks/attack.py
View File
| @@ -0,0 +1,97 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Base Class of Attack. | |||
| """ | |||
| from abc import abstractmethod | |||
| import numpy as np | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, \ | |||
| check_int_positive | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Attack' | |||
| class Attack: | |||
| """ | |||
| The abstract base class for all attack classes creating adversarial examples. | |||
| """ | |||
| def __init__(self): | |||
| pass | |||
| def batch_generate(self, inputs, labels, batch_size=64): | |||
| """ | |||
| Generate adversarial examples in batch, based on input samples and | |||
| their labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Samples based on which adversarial | |||
| examples are generated. | |||
| labels (numpy.ndarray): Labels of samples, whose values determined | |||
| by specific attacks. | |||
| batch_size (int): The number of samples in one batch. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples | |||
| Examples: | |||
| >>> inputs = Tensor([[0.2, 0.4, 0.5, 0.2], [0.7, 0.2, 0.4, 0.3]]) | |||
| >>> labels = [3, 0] | |||
| >>> advs = attack.batch_generate(inputs, labels, batch_size=2) | |||
| """ | |||
| arr_x, arr_y = check_pair_numpy_param('inputs', inputs, 'labels', labels) | |||
| len_x = arr_x.shape[0] | |||
| batch_size = check_int_positive('batch_size', batch_size) | |||
| batchs = int(len_x / batch_size) | |||
| rest = len_x - batchs*batch_size | |||
| res = [] | |||
| for i in range(batchs): | |||
| x_batch = arr_x[i*batch_size: (i + 1)*batch_size] | |||
| y_batch = arr_y[i*batch_size: (i + 1)*batch_size] | |||
| adv_x = self.generate(x_batch, y_batch) | |||
| # Black-attack methods will return 3 values, just get the second. | |||
| res.append(adv_x[1] if isinstance(adv_x, tuple) else adv_x) | |||
| if rest != 0: | |||
| x_batch = arr_x[batchs*batch_size:] | |||
| y_batch = arr_y[batchs*batch_size:] | |||
| adv_x = self.generate(x_batch, y_batch) | |||
| # Black-attack methods will return 3 values, just get the second. | |||
| res.append(adv_x[1] if isinstance(adv_x, tuple) else adv_x) | |||
| adv_x = np.concatenate(res, axis=0) | |||
| return adv_x | |||
| @abstractmethod | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on normal samples and their labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Samples based on which adversarial | |||
| examples are generated. | |||
| labels (numpy.ndarray): Labels of samples, whose values determined | |||
| by specific attacks. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function generate() is an abstract function in class ' \ | |||
| '`Attack` and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
+ 0
- 0
mindarmour/attacks/black/__init__.py
View File
+ 75
- 0
mindarmour/attacks/black/black_model.py
View File
| @@ -0,0 +1,75 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Black model. | |||
| """ | |||
| from abc import abstractmethod | |||
| import numpy as np | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'BlackModel' | |||
| class BlackModel: | |||
| """ | |||
| The abstract class which treats the target model as a black box. The model | |||
| should be defined by users. | |||
| """ | |||
| def __init__(self): | |||
| pass | |||
| @abstractmethod | |||
| def predict(self, inputs): | |||
| """ | |||
| Predict using the user specified model. The shape of predict results | |||
| should be (m, n), where n represents the number of classes this model | |||
| classifies. | |||
| Args: | |||
| inputs (numpy.ndarray): The input samples to be predicted. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function predict() is an abstract function in class ' \ | |||
| '`BlackModel` and should be implemented in child class by user.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| def is_adversarial(self, data, label, is_targeted): | |||
| """ | |||
| Check if input sample is adversarial example or not. | |||
| Args: | |||
| data (numpy.ndarray): The input sample to be check, typically some | |||
| maliciously perturbed examples. | |||
| label (numpy.ndarray): For targeted attacks, label is intended | |||
| label of perturbed example. For untargeted attacks, label is | |||
| original label of corresponding unperturbed sample. | |||
| is_targeted (bool): For targeted/untargeted attacks, select True/False. | |||
| Returns: | |||
| bool. | |||
| - If True, the input sample is adversarial. | |||
| - If False, the input sample is not adversarial. | |||
| """ | |||
| logits = self.predict(np.expand_dims(data, axis=0))[0] | |||
| predicts = np.argmax(logits) | |||
| if is_targeted: | |||
| return predicts == label | |||
| return predicts != label | |||
+ 230
- 0
mindarmour/attacks/black/genetic_attack.py
View File
| @@ -0,0 +1,230 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Genetic-Attack. | |||
| """ | |||
| import numpy as np | |||
| from scipy.special import softmax | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils._check_param import check_numpy_param, check_model, \ | |||
| check_pair_numpy_param, check_param_type, check_value_positive, \ | |||
| check_int_positive, check_param_multi_types | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'GeneticAttack' | |||
| def _mutation(cur_pop, step_noise=0.01, prob=0.005): | |||
| """ | |||
| Generate mutation samples in genetic_attack. | |||
| Args: | |||
| cur_pop (numpy.ndarray): Samples before mutation. | |||
| step_noise (float): Noise range. Default: 0.01. | |||
| prob (float): Mutation probability. Default: 0.005. | |||
| Returns: | |||
| numpy.ndarray, samples after mutation operation in genetic_attack. | |||
| Examples: | |||
| >>> mul_pop = self._mutation_op([0.2, 0.3, 0.4], step_noise=0.03, | |||
| >>> prob=0.01) | |||
| """ | |||
| cur_pop = check_numpy_param('cur_pop', cur_pop) | |||
| perturb_noise = np.clip(np.random.random(cur_pop.shape) - 0.5, | |||
| -step_noise, step_noise) | |||
| mutated_pop = perturb_noise*( | |||
| np.random.random(cur_pop.shape) < prob) + cur_pop | |||
| return mutated_pop | |||
| class GeneticAttack(Attack): | |||
| """ | |||
| The Genetic Attack represents the black-box attack based on the genetic algorithm, | |||
| which belongs to differential evolution algorithms. | |||
| This attack was proposed by Moustafa Alzantot et al. (2018). | |||
| References: `Moustafa Alzantot, Yash Sharma, Supriyo Chakraborty, | |||
| "GeneticAttack: Practical Black-box Attacks with | |||
| Gradient-FreeOptimization" <https://arxiv.org/abs/1805.11090>`_ | |||
| Args: | |||
| model (BlackModel): Target model. | |||
| pop_size (int): The number of particles, which should be greater than | |||
| zero. Default: 6. | |||
| mutation_rate (float): The probability of mutations. Default: 0.005. | |||
| per_bounds (float): Maximum L_inf distance. | |||
| max_steps (int): The maximum round of iteration for each adversarial | |||
| example. Default: 1000. | |||
| step_size (float): Attack step size. Default: 0.2. | |||
| temp (float): Sampling temperature for selection. Default: 0.3. | |||
| bounds (tuple): Upper and lower bounds of data. In form of (clip_min, | |||
| clip_max). Default: (0, 1.0) | |||
| adaptive (bool): If True, turns on dynamic scaling of mutation | |||
| parameters. If false, turns on static mutation parameters. | |||
| Default: False. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: True. | |||
| Examples: | |||
| >>> attack = GeneticAttack(model) | |||
| """ | |||
| def __init__(self, model, pop_size=6, | |||
| mutation_rate=0.005, per_bounds=0.15, max_steps=1000, | |||
| step_size=0.20, temp=0.3, bounds=(0, 1.0), adaptive=False, | |||
| sparse=True): | |||
| super(GeneticAttack, self).__init__() | |||
| self._model = check_model('model', model, BlackModel) | |||
| self._per_bounds = check_value_positive('per_bounds', per_bounds) | |||
| self._pop_size = check_int_positive('pop_size', pop_size) | |||
| self._step_size = check_value_positive('step_size', step_size) | |||
| self._temp = check_value_positive('temp', temp) | |||
| self._max_steps = check_int_positive('max_steps', max_steps) | |||
| self._mutation_rate = check_value_positive('mutation_rate', | |||
| mutation_rate) | |||
| self._adaptive = check_param_type('adaptive', adaptive, bool) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [list, tuple]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| # initial global optimum fitness value | |||
| self._best_fit = -1 | |||
| # count times of no progress | |||
| self._plateau_times = 0 | |||
| # count times of changing attack step | |||
| self._adap_times = 0 | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input data and targeted | |||
| labels (or ground_truth labels). | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Targeted labels. | |||
| Returns: | |||
| - numpy.ndarray, bool values for each attack result. | |||
| - numpy.ndarray, generated adversarial examples. | |||
| - numpy.ndarray, query times for each sample. | |||
| Examples: | |||
| >>> advs = attack.generate([[0.2, 0.3, 0.4], | |||
| >>> [0.3, 0.3, 0.2]], | |||
| >>> [1, 2]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| # if input is one-hot encoded, get sparse format value | |||
| if not self._sparse: | |||
| if labels.ndim != 2: | |||
| raise ValueError('labels must be 2 dims, ' | |||
| 'but got {} dims.'.format(labels.ndim)) | |||
| labels = np.argmax(labels, axis=1) | |||
| adv_list = [] | |||
| success_list = [] | |||
| query_times_list = [] | |||
| for i in range(inputs.shape[0]): | |||
| is_success = False | |||
| target_label = labels[i] | |||
| iters = 0 | |||
| x_ori = inputs[i] | |||
| # generate particles | |||
| ori_copies = np.repeat( | |||
| x_ori[np.newaxis, :], self._pop_size, axis=0) | |||
| # initial perturbations | |||
| cur_pert = np.clip(np.random.random(ori_copies.shape)*self._step_size, | |||
| (0 - self._per_bounds), | |||
| self._per_bounds) | |||
| query_times = 0 | |||
| while iters < self._max_steps: | |||
| iters += 1 | |||
| cur_pop = np.clip( | |||
| ori_copies + cur_pert, self._bounds[0], self._bounds[1]) | |||
| pop_preds = self._model.predict(cur_pop) | |||
| query_times += cur_pop.shape[0] | |||
| all_preds = np.argmax(pop_preds, axis=1) | |||
| success_pop = np.equal(target_label, all_preds).astype(np.int32) | |||
| success = max(success_pop) | |||
| if success == 1: | |||
| is_success = True | |||
| adv = cur_pop[np.argmax(success_pop)] | |||
| break | |||
| target_preds = pop_preds[:, target_label] | |||
| others_preds_sum = np.sum(pop_preds, axis=1) - target_preds | |||
| fit_vals = target_preds - others_preds_sum | |||
| best_fit = max(target_preds - np.max(pop_preds)) | |||
| if best_fit > self._best_fit: | |||
| self._best_fit = best_fit | |||
| self._plateau_times = 0 | |||
| else: | |||
| self._plateau_times += 1 | |||
| adap_threshold = (lambda z: 100 if z > -0.4 else 300)(best_fit) | |||
| if self._plateau_times > adap_threshold: | |||
| self._adap_times += 1 | |||
| self._plateau_times = 0 | |||
| if self._adaptive: | |||
| step_noise = max(self._step_size, 0.4*(0.9**self._adap_times)) | |||
| step_p = max(self._step_size, 0.5*(0.9**self._adap_times)) | |||
| else: | |||
| step_noise = self._step_size | |||
| step_p = self._mutation_rate | |||
| step_temp = self._temp | |||
| elite = cur_pert[np.argmax(fit_vals)] | |||
| select_probs = softmax(fit_vals/step_temp) | |||
| select_args = np.arange(self._pop_size) | |||
| parents_arg = np.random.choice( | |||
| a=select_args, size=2*(self._pop_size - 1), | |||
| replace=True, p=select_probs) | |||
| parent1 = cur_pert[parents_arg[:self._pop_size - 1]] | |||
| parent2 = cur_pert[parents_arg[self._pop_size - 1:]] | |||
| parent1_probs = select_probs[parents_arg[:self._pop_size - 1]] | |||
| parent2_probs = select_probs[parents_arg[self._pop_size - 1:]] | |||
| parent2_probs = parent2_probs / (parent1_probs + parent2_probs) | |||
| # duplicate the probabilities to all features of each particle. | |||
| dims = len(x_ori.shape) | |||
| for _ in range(dims): | |||
| parent2_probs = parent2_probs[:, np.newaxis] | |||
| parent2_probs = np.tile(parent2_probs, ((1,) + x_ori.shape)) | |||
| cross_probs = (np.random.random(parent1.shape) > | |||
| parent2_probs).astype(np.int32) | |||
| childs = parent1*cross_probs + parent2*(1 - cross_probs) | |||
| mutated_childs = _mutation( | |||
| childs, step_noise=self._per_bounds*step_noise, | |||
| prob=step_p) | |||
| cur_pert = np.concatenate((mutated_childs, elite[np.newaxis, :])) | |||
| if is_success: | |||
| LOGGER.debug(TAG, 'successfully find one adversarial sample ' | |||
| 'and start Reduction process.') | |||
| adv_list.append(adv) | |||
| else: | |||
| LOGGER.debug(TAG, 'fail to find adversarial sample.') | |||
| adv_list.append(elite + x_ori) | |||
| LOGGER.debug(TAG, | |||
| 'iteration times is: %d and query times is: %d', | |||
| iters, | |||
| query_times) | |||
| success_list.append(is_success) | |||
| query_times_list.append(query_times) | |||
| del ori_copies, cur_pert, cur_pop | |||
| return np.asarray(success_list), \ | |||
| np.asarray(adv_list), \ | |||
| np.asarray(query_times_list) | |||
+ 510
- 0
mindarmour/attacks/black/hop_skip_jump_attack.py
View File
| @@ -0,0 +1,510 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Hop-skip-jump attack. | |||
| """ | |||
| import numpy as np | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| check_numpy_param, check_int_positive, check_value_positive, \ | |||
| check_value_non_negative, check_param_type | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'HopSkipJumpAttack' | |||
| def _clip_image(image, clip_min, clip_max): | |||
| """ | |||
| Clip an image, or an image batch, with upper and lower threshold. | |||
| """ | |||
| return np.clip(image, clip_min, clip_max) | |||
| class HopSkipJumpAttack(Attack): | |||
| """ | |||
| HopSkipJumpAttack proposed by Chen, Jordan and Wainwright is a | |||
| decision-based attack. The attack requires access to output labels of | |||
| target model. | |||
| References: `Chen J, Michael I. Jordan, Martin J. Wainwright. | |||
| HopSkipJumpAttack: A Query-Efficient Decision-Based Attack. 2019. | |||
| arXiv:1904.02144 <https://arxiv.org/abs/1904.02144>`_ | |||
| Args: | |||
| model (BlackModel): Target model. | |||
| init_num_evals (int): The initial number of evaluations for gradient | |||
| estimation. Default: 100. | |||
| max_num_evals (int): The maximum number of evaluations for gradient | |||
| estimation. Default: 1000. | |||
| stepsize_search (str): Indicating how to search for stepsize; Possible | |||
| values are 'geometric_progression', 'grid_search', 'geometric_progression'. | |||
| num_iterations (int): The number of iterations. Default: 64. | |||
| gamma (float): Used to set binary search threshold theta. Default: 1.0. | |||
| For l2 attack the binary search threshold `theta` is: | |||
| math:`gamma / d^{3/2}`. For linf attack is math:`gamma / d^2`. | |||
| constraint (str): The norm distance to optimize. Possible values are 'l2', | |||
| 'linf'. Default: l2. | |||
| batch_size (int): Batch size. Default: 32. | |||
| clip_min (float, optional): The minimum image component value. | |||
| Default: 0. | |||
| clip_max (float, optional): The maximum image component value. | |||
| Default: 1. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: True. | |||
| Raises: | |||
| ValueError: If stepsize_search not in ['geometric_progression', | |||
| 'grid_search'] | |||
| ValueError: If constraint not in ['l2', 'linf'] | |||
| Examples: | |||
| >>> x_test = np.asarray(np.random.random((sample_num, | |||
| >>> sample_length)), np.float32) | |||
| >>> y_test = np.random.randint(0, class_num, size=sample_num) | |||
| >>> instance = HopSkipJumpAttack(user_model) | |||
| >>> adv_x = instance.generate(x_test, y_test) | |||
| """ | |||
| def __init__(self, model, init_num_evals=100, max_num_evals=1000, | |||
| stepsize_search='geometric_progression', num_iterations=20, | |||
| gamma=1.0, constraint='l2', batch_size=32, clip_min=0.0, | |||
| clip_max=1.0, sparse=True): | |||
| super(HopSkipJumpAttack, self).__init__() | |||
| self._model = check_model('model', model, BlackModel) | |||
| self._init_num_evals = check_int_positive('initial_num_evals', | |||
| init_num_evals) | |||
| self._max_num_evals = check_int_positive('max_num_evals', max_num_evals) | |||
| self._batch_size = check_int_positive('batch_size', batch_size) | |||
| self._clip_min = check_value_non_negative('clip_min', clip_min) | |||
| self._clip_max = check_value_non_negative('clip_max', clip_max) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| self._np_dtype = np.dtype('float32') | |||
| if stepsize_search in ['geometric_progression', 'grid_search']: | |||
| self._stepsize_search = stepsize_search | |||
| else: | |||
| msg = "stepsize_search must be in ['geometric_progression'," \ | |||
| " 'grid_search'], but got {}".format(stepsize_search) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| self._num_iterations = check_int_positive('num_iterations', | |||
| num_iterations) | |||
| self._gamma = check_value_positive('gamma', gamma) | |||
| if constraint in ['l2', 'linf']: | |||
| self._constraint = constraint | |||
| else: | |||
| msg = "constraint must be in ['l2', 'linf'], " \ | |||
| "but got {}".format(constraint) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| self.queries = 0 | |||
| self.is_adv = True | |||
| self.y_targets = None | |||
| self.image_targets = None | |||
| self.y_target = None | |||
| self.image_target = None | |||
| def _generate_one(self, sample): | |||
| """ | |||
| Return a tensor that constructs adversarial examples for the given | |||
| input. | |||
| Args: | |||
| sample (Tensor): Input samples. | |||
| Returns: | |||
| Tensor, generated adversarial examples. | |||
| """ | |||
| shape = list(np.shape(sample)) | |||
| dim = int(np.prod(shape)) | |||
| # Set binary search threshold. | |||
| if self._constraint == 'l2': | |||
| theta = self._gamma / (np.sqrt(dim)*dim) | |||
| else: | |||
| theta = self._gamma / (dim*dim) | |||
| wrap = self._hsja(sample, self.y_target, self.image_target, dim, theta) | |||
| if wrap is None: | |||
| self.is_adv = False | |||
| else: | |||
| self.is_adv = True | |||
| return self.is_adv, wrap, self.queries | |||
| def set_target_images(self, target_images): | |||
| """ | |||
| Setting target images for target attack. | |||
| Args: | |||
| target_images (numpy.ndarray): Target images. | |||
| """ | |||
| self.image_targets = check_numpy_param('target_images', target_images) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial images in a for loop. | |||
| Args: | |||
| inputs (numpy.ndarray): Origin images. | |||
| labels (numpy.ndarray): Target labels. | |||
| Returns: | |||
| - numpy.ndarray, bool values for each attack result. | |||
| - numpy.ndarray, generated adversarial examples. | |||
| - numpy.ndarray, query times for each sample. | |||
| Examples: | |||
| >>> generate([[0.1,0.2,0.2],[0.2,0.3,0.4]],[2,6]) | |||
| """ | |||
| if labels is not None: | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| x_adv = [] | |||
| is_advs = [] | |||
| queries_times = [] | |||
| if labels is not None: | |||
| self.y_targets = labels | |||
| for i, x_single in enumerate(inputs): | |||
| self.queries = 0 | |||
| if self.image_targets is not None: | |||
| self.image_target = self.image_targets[i] | |||
| if self.y_targets is not None: | |||
| self.y_target = self.y_targets[i] | |||
| is_adv, adv_img, query_time = self._generate_one(x_single) | |||
| x_adv.append(adv_img) | |||
| is_advs.append(is_adv) | |||
| queries_times.append(query_time) | |||
| return np.asarray(is_advs), \ | |||
| np.asarray(x_adv), \ | |||
| np.asarray(queries_times) | |||
| def _hsja(self, sample, target_label, target_image, dim, theta): | |||
| """ | |||
| The main algorithm for HopSkipJumpAttack. | |||
| Args: | |||
| sample (numpy.ndarray): Input image. Without the batchsize | |||
| dimension. | |||
| target_label (int): Integer for targeted attack, None for | |||
| nontargeted attack. Without the batchsize dimension. | |||
| target_image (numpy.ndarray): An array with the same size as | |||
| input sample, or None. Without the batchsize dimension. | |||
| Returns: | |||
| numpy.ndarray, perturbed images. | |||
| """ | |||
| original_label = None | |||
| # Original label for untargeted attack. | |||
| if target_label is None: | |||
| original_label = self._model.predict(sample) | |||
| original_label = np.argmax(original_label) | |||
| # Initialize perturbed image. | |||
| # untarget attack | |||
| if target_image is None: | |||
| perturbed = self._initialize(sample, original_label, target_label) | |||
| if perturbed is None: | |||
| msg = 'Can not find an initial adversarial example' | |||
| LOGGER.info(TAG, msg) | |||
| return perturbed | |||
| else: | |||
| # Target attack | |||
| perturbed = target_image | |||
| # Project the initial perturbed image to the decision boundary. | |||
| perturbed, dist_post_update = self._binary_search_batch(sample, | |||
| np.expand_dims(perturbed, 0), | |||
| original_label, | |||
| target_label, | |||
| theta) | |||
| # Calculate the distance of perturbed image and original sample | |||
| dist = self._compute_distance(perturbed, sample) | |||
| for j in np.arange(self._num_iterations): | |||
| current_iteration = j + 1 | |||
| # Select delta. | |||
| delta = self._select_delta(dist_post_update, current_iteration, dim, | |||
| theta) | |||
| # Choose number of evaluations. | |||
| num_evals = int(min([self._init_num_evals*np.sqrt(j + 1), | |||
| self._max_num_evals])) | |||
| # approximate gradient. | |||
| gradf = self._approximate_gradient(perturbed, num_evals, | |||
| original_label, target_label, | |||
| delta, theta) | |||
| if self._constraint == 'linf': | |||
| update = np.sign(gradf) | |||
| else: | |||
| update = gradf | |||
| # search step size. | |||
| if self._stepsize_search == 'geometric_progression': | |||
| # find step size. | |||
| epsilon = self._geometric_progression_for_stepsize( | |||
| perturbed, | |||
| update, | |||
| dist, | |||
| current_iteration, | |||
| original_label, | |||
| target_label) | |||
| # Update the sample. | |||
| perturbed = _clip_image(perturbed + epsilon*update, | |||
| self._clip_min, self._clip_max) | |||
| # Binary search to return to the boundary. | |||
| perturbed, dist_post_update = self._binary_search_batch( | |||
| sample, | |||
| perturbed[None], | |||
| original_label, | |||
| target_label, | |||
| theta) | |||
| elif self._stepsize_search == 'grid_search': | |||
| epsilons = np.logspace(-4, 0, num=20, endpoint=True)*dist | |||
| epsilons_shape = [20] + len(np.shape(sample))*[1] | |||
| perturbeds = perturbed + epsilons.reshape( | |||
| epsilons_shape)*update | |||
| perturbeds = _clip_image(perturbeds, self._clip_min, | |||
| self._clip_max) | |||
| idx_perturbed = self._decision_function(perturbeds, | |||
| original_label, | |||
| target_label) | |||
| if np.sum(idx_perturbed) > 0: | |||
| # Select the perturbation that yields the minimum distance | |||
| # after binary search. | |||
| perturbed, dist_post_update = self._binary_search_batch( | |||
| sample, perturbeds[idx_perturbed], | |||
| original_label, target_label, theta) | |||
| # compute new distance. | |||
| dist = self._compute_distance(perturbed, sample) | |||
| LOGGER.debug(TAG, | |||
| 'iteration: %d, %s distance %4f', | |||
| j + 1, | |||
| self._constraint, dist) | |||
| perturbed = np.expand_dims(perturbed, 0) | |||
| return perturbed | |||
| def _decision_function(self, images, original_label, target_label): | |||
| """ | |||
| Decision function returns 1 if the input sample is on the desired | |||
| side of the boundary, and 0 otherwise. | |||
| """ | |||
| images = _clip_image(images, self._clip_min, self._clip_max) | |||
| prob = [] | |||
| self.queries += len(images) | |||
| for i in range(0, len(images), self._batch_size): | |||
| batch = images[i:i + self._batch_size] | |||
| length = len(batch) | |||
| prob_i = self._model.predict(batch)[:length] | |||
| prob.append(prob_i) | |||
| prob = np.concatenate(prob) | |||
| if target_label is None: | |||
| res = np.argmax(prob, axis=1) != original_label | |||
| else: | |||
| res = np.argmax(prob, axis=1) == target_label | |||
| return res | |||
| def _compute_distance(self, original_img, perturbation_img): | |||
| """ | |||
| Compute the distance between original image and perturbation images. | |||
| """ | |||
| if self._constraint == 'l2': | |||
| distance = np.linalg.norm(original_img - perturbation_img) | |||
| else: | |||
| distance = np.max(abs(original_img - perturbation_img)) | |||
| return distance | |||
| def _approximate_gradient(self, sample, num_evals, original_label, | |||
| target_label, delta, theta): | |||
| """ | |||
| Gradient direction estimation. | |||
| """ | |||
| # Generate random noise based on constraint. | |||
| noise_shape = [num_evals] + list(np.shape(sample)) | |||
| if self._constraint == 'l2': | |||
| random_noise = np.random.randn(*noise_shape) | |||
| else: | |||
| random_noise = np.random.uniform(low=-1, high=1, size=noise_shape) | |||
| axis = tuple(range(1, 1 + len(np.shape(sample)))) | |||
| random_noise = random_noise / np.sqrt( | |||
| np.sum(random_noise**2, axis=axis, keepdims=True)) | |||
| # perturbed images | |||
| perturbed = sample + delta*random_noise | |||
| perturbed = _clip_image(perturbed, self._clip_min, self._clip_max) | |||
| random_noise = (perturbed - sample) / theta | |||
| # Whether the perturbed images are on the desired side of the boundary. | |||
| decisions = self._decision_function(perturbed, original_label, | |||
| target_label) | |||
| decision_shape = [len(decisions)] + [1]*len(np.shape(sample)) | |||
| # transform decisions value from 1, 0 to 1, -2 | |||
| re_decision = 2*np.array(decisions).astype(self._np_dtype).reshape( | |||
| decision_shape) - 1.0 | |||
| if np.mean(re_decision) == 1.0: | |||
| grad_direction = np.mean(random_noise, axis=0) | |||
| elif np.mean(re_decision) == -1.0: | |||
| grad_direction = - np.mean(random_noise, axis=0) | |||
| else: | |||
| re_decision = re_decision - np.mean(re_decision) | |||
| grad_direction = np.mean(re_decision*random_noise, axis=0) | |||
| # The gradient direction. | |||
| grad_direction = grad_direction / (np.linalg.norm(grad_direction) + 1e-10) | |||
| return grad_direction | |||
| def _project(self, original_image, perturbed_images, alphas): | |||
| """ | |||
| Projection input samples onto given l2 or linf balls. | |||
| """ | |||
| alphas_shape = [len(alphas)] + [1]*len(np.shape(original_image)) | |||
| alphas = alphas.reshape(alphas_shape) | |||
| if self._constraint == 'l2': | |||
| projected = (1 - alphas)*original_image + alphas*perturbed_images | |||
| else: | |||
| projected = _clip_image(perturbed_images, original_image - alphas, | |||
| original_image + alphas) | |||
| return projected | |||
| def _binary_search_batch(self, original_image, perturbed_images, | |||
| original_label, target_label, theta): | |||
| """ | |||
| Binary search to approach the model decision boundary. | |||
| """ | |||
| # Compute distance between perturbed image and original image. | |||
| dists_post_update = np.array([self._compute_distance(original_image, | |||
| perturbed_image,) | |||
| for perturbed_image in perturbed_images]) | |||
| # Get higher thresholds | |||
| if self._constraint == 'l2': | |||
| highs = np.ones(len(perturbed_images)) | |||
| thresholds = theta | |||
| else: | |||
| highs = dists_post_update | |||
| thresholds = np.minimum(dists_post_update*theta, theta) | |||
| # Get lower thresholds | |||
| lows = np.zeros(len(perturbed_images)) | |||
| # Update thresholds. | |||
| while np.max((highs - lows) / thresholds) > 1: | |||
| mids = (highs + lows) / 2.0 | |||
| mid_images = self._project(original_image, perturbed_images, mids) | |||
| decisions = self._decision_function(mid_images, original_label, | |||
| target_label) | |||
| lows = np.where(decisions == [0], mids, lows) | |||
| highs = np.where(decisions == [1], mids, highs) | |||
| out_images = self._project(original_image, perturbed_images, highs) | |||
| # Select the best choice based on the distance of the output image. | |||
| dists = np.array( | |||
| [self._compute_distance(original_image, out_image) for out_image in | |||
| out_images]) | |||
| idx = np.argmin(dists) | |||
| dist = dists_post_update[idx] | |||
| out_image = out_images[idx] | |||
| return out_image, dist | |||
| def _initialize(self, sample, original_label, target_label): | |||
| """ | |||
| Implementation of BlendedUniformNoiseAttack | |||
| """ | |||
| num_evals = 0 | |||
| while True: | |||
| random_noise = np.random.uniform(self._clip_min, self._clip_max, | |||
| size=np.shape(sample)) | |||
| success = self._decision_function(random_noise[None], | |||
| original_label, | |||
| target_label) | |||
| if success: | |||
| break | |||
| num_evals += 1 | |||
| if num_evals > 1e3: | |||
| return None | |||
| # Binary search. | |||
| low = 0.0 | |||
| high = 1.0 | |||
| while high - low > 0.001: | |||
| mid = (high + low) / 2.0 | |||
| blended = (1 - mid)*sample + mid*random_noise | |||
| success = self._decision_function(blended[None], original_label, | |||
| target_label) | |||
| if success: | |||
| high = mid | |||
| else: | |||
| low = mid | |||
| initialization = (1 - high)*sample + high*random_noise | |||
| return initialization | |||
| def _geometric_progression_for_stepsize(self, perturbed, update, dist, | |||
| current_iteration, original_label, | |||
| target_label): | |||
| """ | |||
| Search for stepsize in the way of Geometric progression. | |||
| Keep decreasing stepsize by half until reaching the desired side of | |||
| the decision boundary. | |||
| """ | |||
| epsilon = dist / np.sqrt(current_iteration) | |||
| while True: | |||
| updated = perturbed + epsilon*update | |||
| success = self._decision_function(updated, original_label, | |||
| target_label) | |||
| if success: | |||
| break | |||
| epsilon = epsilon / 2.0 | |||
| return epsilon | |||
| def _select_delta(self, dist_post_update, current_iteration, dim, theta): | |||
| """ | |||
| Choose the delta based on the distance between the input sample | |||
| and the perturbed sample. | |||
| """ | |||
| if current_iteration == 1: | |||
| delta = 0.1*(self._clip_max - self._clip_min) | |||
| else: | |||
| if self._constraint == 'l2': | |||
| delta = np.sqrt(dim)*theta*dist_post_update | |||
| else: | |||
| delta = dim*theta*dist_post_update | |||
| return delta | |||
+ 432
- 0
mindarmour/attacks/black/natural_evolutionary_strategy.py
View File
| @@ -0,0 +1,432 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Natural-evolutionary-strategy Attack. | |||
| """ | |||
| import time | |||
| import numpy as np | |||
| from scipy.special import softmax | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| check_numpy_param, check_int_positive, check_value_positive, check_param_type | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'NES' | |||
| def _one_hot(index, total): | |||
| arr = np.zeros((total)) | |||
| arr[index] = 1.0 | |||
| return arr | |||
| def _bound(image, epislon): | |||
| lower = np.clip(image - epislon, 0, 1) | |||
| upper = np.clip(image + epislon, 0, 1) | |||
| return lower, upper | |||
| class NES(Attack): | |||
| """ | |||
| The class is an implementation of the Natural Evolutionary Strategies Attack, | |||
| including three settings: Query-Limited setting, Partial-Information setting | |||
| and Label-Only setting. | |||
| References: `Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. | |||
| Black-box adversarial attacks with limited queries and information. In | |||
| ICML, July 2018 <https://arxiv.org/abs/1804.08598>`_ | |||
| Args: | |||
| model (BlackModel): Target model. | |||
| scene (str): Scene in 'Label_Only', 'Partial_Info' or | |||
| 'Query_Limit'. | |||
| max_queries (int): Maximum query numbers to generate an adversarial | |||
| example. Default: 500000. | |||
| top_k (int): For Partial-Info or Label-Only setting, indicating how | |||
| much (Top-k) information is available for the attacker. For | |||
| Query-Limited setting, this input should be set as -1. Default: -1. | |||
| num_class (int): Number of classes in dataset. Default: 10. | |||
| batch_size (int): Batch size. Default: 96. | |||
| epsilon (float): Maximum perturbation allowed in attack. Default: 0.3. | |||
| samples_per_draw (int): Number of samples draw in antithetic sampling. | |||
| Default: 96. | |||
| momentum (float): Momentum. Default: 0.9. | |||
| learning_rate (float): Learning rate. Default: 1e-2. | |||
| max_lr (float): Max Learning rate. Default: 1e-2. | |||
| min_lr (float): Min Learning rate. Default: 5e-5. | |||
| sigma (float): Step size of random noise. Default: 1e-3. | |||
| plateau_length (int): Length of plateau used in Annealing algorithm. | |||
| Default: 20. | |||
| plateau_drop (float): Drop of plateau used in Annealing algorithm. | |||
| Default: 2.0. | |||
| adv_thresh (float): Threshold of adversarial. Default: 0.15. | |||
| zero_iters (int): Number of points to use for the proxy score. | |||
| Default: 10. | |||
| starting_eps (float): Starting epsilon used in Label-Only setting. | |||
| Default: 1.0. | |||
| starting_delta_eps (float): Delta epsilon used in Label-Only setting. | |||
| Default: 0.5. | |||
| label_only_sigma (float): Sigma used in Label-Only setting. | |||
| Default: 1e-3. | |||
| conservative (int): Conservation used in epsilon decay, it will | |||
| increase if no convergence. Default: 2. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: True. | |||
| Examples: | |||
| >>> SCENE = 'Label_Only' | |||
| >>> TOP_K = 5 | |||
| >>> num_class = 5 | |||
| >>> nes_instance = NES(user_model, SCENE, top_k=TOP_K) | |||
| >>> initial_img = np.asarray(np.random.random((32, 32)), np.float32) | |||
| >>> target_image = np.asarray(np.random.random((32, 32)), np.float32) | |||
| >>> orig_class = 0 | |||
| >>> target_class = 2 | |||
| >>> nes_instance.set_target_images(target_image) | |||
| >>> tag, adv, queries = nes_instance.generate([initial_img], [target_class]) | |||
| """ | |||
| def __init__(self, model, scene, max_queries=10000, top_k=-1, num_class=10, | |||
| batch_size=128, epsilon=0.3, samples_per_draw=128, | |||
| momentum=0.9, learning_rate=1e-3, max_lr=5e-2, min_lr=5e-4, | |||
| sigma=1e-3, plateau_length=20, plateau_drop=2.0, | |||
| adv_thresh=0.25, zero_iters=10, starting_eps=1.0, | |||
| starting_delta_eps=0.5, label_only_sigma=1e-3, conservative=2, | |||
| sparse=True): | |||
| super(NES, self).__init__() | |||
| self._model = check_model('model', model, BlackModel) | |||
| self._scene = scene | |||
| self._max_queries = check_int_positive('max_queries', max_queries) | |||
| self._num_class = check_int_positive('num_class', num_class) | |||
| self._batch_size = check_int_positive('batch_size', batch_size) | |||
| self._samples_per_draw = check_int_positive('samples_per_draw', | |||
| samples_per_draw) | |||
| self._goal_epsilon = check_value_positive('epsilon', epsilon) | |||
| self._momentum = check_value_positive('momentum', momentum) | |||
| self._learning_rate = check_value_positive('learning_rate', | |||
| learning_rate) | |||
| self._max_lr = check_value_positive('max_lr', max_lr) | |||
| self._min_lr = check_value_positive('min_lr', min_lr) | |||
| self._sigma = check_value_positive('sigma', sigma) | |||
| self._plateau_length = check_int_positive('plateau_length', | |||
| plateau_length) | |||
| self._plateau_drop = check_value_positive('plateau_drop', plateau_drop) | |||
| # partial information arguments | |||
| self._k = top_k | |||
| self._adv_thresh = check_value_positive('adv_thresh', adv_thresh) | |||
| # label only arguments | |||
| self._zero_iters = check_int_positive('zero_iters', zero_iters) | |||
| self._starting_eps = check_value_positive('starting_eps', starting_eps) | |||
| self._starting_delta_eps = check_value_positive('starting_delta_eps', | |||
| starting_delta_eps) | |||
| self._label_only_sigma = check_value_positive('label_only_sigma', | |||
| label_only_sigma) | |||
| self._conservative = check_int_positive('conservative', conservative) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| self.target_imgs = None | |||
| self.target_img = None | |||
| self.target_class = None | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Main algorithm for NES. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples. | |||
| labels (numpy.ndarray): Target labels. | |||
| Returns: | |||
| - numpy.ndarray, bool values for each attack result. | |||
| - numpy.ndarray, generated adversarial examples. | |||
| - numpy.ndarray, query times for each sample. | |||
| Raises: | |||
| ValueError: If the top_k less than 0 in Label-Only or Partial-Info | |||
| setting. | |||
| ValueError: If the target_imgs is None in Label-Only or | |||
| Partial-Info setting. | |||
| ValueError: If scene is not in ['Label_Only', 'Partial_Info', | |||
| 'Query_Limit'] | |||
| Examples: | |||
| >>> advs = attack.generate([[0.2, 0.3, 0.4], [0.3, 0.3, 0.2]], | |||
| >>> [1, 2]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| if self._scene == 'Label_Only' or self._scene == 'Partial_Info': | |||
| if self._k < 0: | |||
| msg = "In 'Label_Only' or 'Partial_Info' mode, " \ | |||
| "'top_k' must more than 0." | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| if self.target_imgs is None: | |||
| msg = "In 'Label_Only' or 'Partial_Info' mode, " \ | |||
| "'target_imgs' must be set." | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| elif self._scene == 'Query_Limit': | |||
| self._k = self._num_class | |||
| else: | |||
| msg = "scene must be string in 'Label_Only', " \ | |||
| "'Partial_Info' or 'Query_Limit' " | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| is_advs = [] | |||
| advs = [] | |||
| queries = [] | |||
| for sample, label, target_img in zip(inputs, labels, self.target_imgs): | |||
| is_adv, adv, query = self._generate_one(sample, label, target_img) | |||
| is_advs.append(is_adv) | |||
| advs.append(adv) | |||
| queries.append(query) | |||
| return is_advs, advs, queries | |||
| def set_target_images(self, target_images): | |||
| """ | |||
| Set target samples for target attack. | |||
| Args: | |||
| target_images (numpy.ndarray): Target samples for target attack. | |||
| """ | |||
| self.target_imgs = check_numpy_param('target_images', target_images) | |||
| def _generate_one(self, origin_image, target_label, target_image): | |||
| """ | |||
| Main algorithm for NES. | |||
| Args: | |||
| origin_image (numpy.ndarray): Benign input sample. | |||
| target_label (int): Target label. | |||
| Returns: | |||
| - bool. | |||
| - If True: successfully make an adversarial example. | |||
| - If False: unsuccessfully make an adversarial example. | |||
| - numpy.ndarray, an adversarial example. | |||
| - int, number of queries. | |||
| """ | |||
| self.target_class = target_label | |||
| origin_image = check_numpy_param('origin_image', origin_image) | |||
| self._epsilon = self._starting_eps | |||
| lower, upper = _bound(origin_image, self._epsilon) | |||
| goal_epsilon = self._goal_epsilon | |||
| delta_epsilon = self._starting_delta_eps | |||
| if self._scene == 'Label_Only' or self._scene == 'Partial_Info': | |||
| adv = target_image | |||
| else: | |||
| adv = origin_image.copy() | |||
| # for backtracking and momentum | |||
| num_queries = 0 | |||
| gradient = 0 | |||
| last_ls = [] | |||
| max_iters = int(np.ceil(self._max_queries // self._samples_per_draw)) | |||
| for i in range(max_iters): | |||
| start = time.time() | |||
| # early stop | |||
| eval_preds = self._model.predict(adv) | |||
| eval_preds = np.argmax(eval_preds, axis=1) | |||
| padv = np.equal(eval_preds, self.target_class) | |||
| if padv and self._epsilon <= goal_epsilon: | |||
| LOGGER.debug(TAG, 'early stopping at iteration %d', i) | |||
| return True, adv, num_queries | |||
| # antithetic sampling noise | |||
| noise_pos = np.random.normal( | |||
| size=(self._batch_size // 2,) + origin_image.shape) | |||
| noise = np.concatenate((noise_pos, -noise_pos), axis=0) | |||
| eval_points = adv + self._sigma*noise | |||
| prev_g = gradient | |||
| loss, gradient = self._get_grad(origin_image, eval_points, noise) | |||
| gradient = self._momentum*prev_g + (1.0 - self._momentum)*gradient | |||
| # plateau learning rate annealing | |||
| last_ls.append(loss) | |||
| last_ls = self._plateau_annealing(last_ls) | |||
| # search for learning rate and epsilon decay | |||
| current_lr = self._max_lr | |||
| prop_delta_eps = 0.0 | |||
| if loss < self._adv_thresh and self._epsilon > goal_epsilon: | |||
| prop_delta_eps = delta_epsilon | |||
| while current_lr >= self._min_lr: | |||
| # in partial information only or label only setting | |||
| if self._scene == 'Label_Only' or self._scene == 'Partial_Info': | |||
| proposed_epsilon = max(self._epsilon - prop_delta_eps, | |||
| goal_epsilon) | |||
| lower, upper = _bound(origin_image, proposed_epsilon) | |||
| proposed_adv = adv - current_lr*np.sign(gradient) | |||
| proposed_adv = np.clip(proposed_adv, lower, upper) | |||
| num_queries += 1 | |||
| if self._preds_in_top_k(self.target_class, proposed_adv): | |||
| # The predicted label of proposed adversarial examples is in | |||
| # the top k observations. | |||
| if prop_delta_eps > 0: | |||
| delta_epsilon = max(prop_delta_eps, 0.1) | |||
| last_ls = [] | |||
| adv = proposed_adv | |||
| self._epsilon = max( | |||
| self._epsilon - prop_delta_eps / self._conservative, | |||
| goal_epsilon) | |||
| break | |||
| elif current_lr >= self._min_lr*2: | |||
| current_lr = current_lr / 2 | |||
| LOGGER.debug(TAG, "backtracking learning rate to %.3f", | |||
| current_lr) | |||
| else: | |||
| prop_delta_eps = prop_delta_eps / 2 | |||
| if prop_delta_eps < 2e-3: | |||
| LOGGER.debug(TAG, "Did not converge.") | |||
| return False, adv, num_queries | |||
| current_lr = self._max_lr | |||
| LOGGER.debug(TAG, | |||
| "backtracking epsilon to %.3f", | |||
| self._epsilon - prop_delta_eps) | |||
| # update the number of queries | |||
| if self._scene == 'Label_Only': | |||
| num_queries += self._samples_per_draw*self._zero_iters | |||
| else: | |||
| num_queries += self._samples_per_draw | |||
| LOGGER.debug(TAG, | |||
| 'Step %d: loss %.4f, lr %.2E, eps %.3f, time %.4f.', | |||
| i, | |||
| loss, | |||
| current_lr, | |||
| self._epsilon, | |||
| time.time() - start) | |||
| return False, adv, num_queries | |||
| def _plateau_annealing(self, last_loss): | |||
| last_loss = last_loss[-self._plateau_length:] | |||
| if last_loss[-1] > last_loss[0] and len( | |||
| last_loss) == self._plateau_length: | |||
| if self._max_lr > self._min_lr: | |||
| LOGGER.debug(TAG, "Annealing max learning rate.") | |||
| self._max_lr = max(self._max_lr / self._plateau_drop, | |||
| self._min_lr) | |||
| last_loss = [] | |||
| return last_loss | |||
| def _softmax_cross_entropy_with_logit(self, logit): | |||
| logit = softmax(logit, axis=1) | |||
| onehot_label = np.zeros(self._num_class) | |||
| onehot_label[self.target_class] = 1 | |||
| onehot_labels = np.tile(onehot_label, (len(logit), 1)) | |||
| entropy = -onehot_labels*np.log(logit) | |||
| loss = np.mean(entropy, axis=1) | |||
| return loss | |||
| def _query_limit_loss(self, eval_points, noise): | |||
| """ | |||
| Loss in Query-Limit setting. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter the function _query_limit_loss().') | |||
| loss = self._softmax_cross_entropy_with_logit( | |||
| self._model.predict(eval_points)) | |||
| return loss, noise | |||
| def _partial_info_loss(self, eval_points, noise): | |||
| """ | |||
| Loss in Partial-Info setting. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter the function _partial_info_loss.') | |||
| logit = self._model.predict(eval_points) | |||
| loss = np.sort(softmax(logit, axis=1))[:, -self._k:] | |||
| inds = np.argsort(logit)[:, -self._k:] | |||
| good_loss = np.where(np.equal(inds, self.target_class), loss, | |||
| np.zeros(np.shape(inds))) | |||
| good_loss = np.max(good_loss, axis=1) | |||
| losses = -np.log(good_loss) | |||
| return losses, noise | |||
| def _label_only_loss(self, origin_image, eval_points, noise): | |||
| """ | |||
| Loss in Label-Only setting. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter the function _label_only_loss().') | |||
| tiled_points = np.tile(np.expand_dims(eval_points, 0), | |||
| [self._zero_iters, | |||
| *[1]*len(eval_points.shape)]) | |||
| noised_eval_im = tiled_points \ | |||
| + np.random.randn(self._zero_iters, | |||
| self._batch_size, | |||
| *origin_image.shape) \ | |||
| *self._label_only_sigma | |||
| noised_eval_im = np.reshape(noised_eval_im, ( | |||
| self._zero_iters*self._batch_size, *origin_image.shape)) | |||
| logits = self._model.predict(noised_eval_im) | |||
| inds = np.argsort(logits)[:, -self._k:] | |||
| real_inds = np.reshape(inds, (self._zero_iters, self._batch_size, -1)) | |||
| rank_range = np.arange(1, self._k + 1, 1, dtype=np.float32) | |||
| tiled_rank_range = np.tile(np.reshape(rank_range, (1, 1, self._k)), | |||
| [self._zero_iters, self._batch_size, 1]) | |||
| batches_in = np.where(np.equal(real_inds, self.target_class), | |||
| tiled_rank_range, | |||
| np.zeros(np.shape(tiled_rank_range))) | |||
| loss = 1 - np.mean(batches_in) | |||
| return loss, noise | |||
| def _preds_in_top_k(self, target_class, prop_adv_): | |||
| # query limit setting | |||
| if self._k == self._num_class: | |||
| return True | |||
| # label only and partial information setting | |||
| eval_preds = self._model.predict(prop_adv_) | |||
| if not target_class in eval_preds.argsort()[:, -self._k:]: | |||
| return False | |||
| return True | |||
| def _get_grad(self, origin_image, eval_points, noise): | |||
| """Calculate gradient.""" | |||
| losses = [] | |||
| grads = [] | |||
| for _ in range(self._samples_per_draw // self._batch_size): | |||
| if self._scene == 'Label_Only': | |||
| loss, np_noise = self._label_only_loss(origin_image, | |||
| eval_points, | |||
| noise) | |||
| elif self._scene == 'Partial_Info': | |||
| loss, np_noise = self._partial_info_loss(eval_points, noise) | |||
| else: | |||
| loss, np_noise = self._query_limit_loss(eval_points, noise) | |||
| # only support three channel images | |||
| losses_tiled = np.tile(np.reshape(loss, (-1, 1, 1, 1)), | |||
| (1,) + origin_image.shape) | |||
| grad = np.mean(losses_tiled*np_noise, axis=0) / self._sigma | |||
| grads.append(grad) | |||
| losses.append(np.mean(loss)) | |||
| return np.array(losses).mean(), np.mean(np.array(grads), axis=0) | |||
+ 326
- 0
mindarmour/attacks/black/pointwise_attack.py
View File
| @@ -0,0 +1,326 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Pointwise-Attack. | |||
| """ | |||
| import numpy as np | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.attacks.black.salt_and_pepper_attack import \ | |||
| SaltAndPepperNoiseAttack | |||
| from mindarmour.utils._check_param import check_model, check_pair_numpy_param, \ | |||
| check_int_positive, check_param_type | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'PointWiseAttack' | |||
| class PointWiseAttack(Attack): | |||
| """ | |||
| The Pointwise Attack make sure use the minimum number of changed pixels | |||
| to generate adversarial sample for each original sample.Those changed pixels | |||
| will use binary seach to make sure the distance between adversarial sample | |||
| and original sample is as close as possible. | |||
| References: `L. Schott, J. Rauber, M. Bethge, W. Brendel: "Towards the | |||
| first adversarially robust neural network model on MNIST", ICLR (2019) | |||
| <https://arxiv.org/abs/1805.09190>`_ | |||
| Args: | |||
| model (BlackModel): Target model. | |||
| max_iter (int): Max rounds of iteration to generate adversarial image. | |||
| search_iter (int): Max rounds of binary search. | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| init_attack (Attack): Attack used to find a starting point. Default: | |||
| None. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: True. | |||
| Examples: | |||
| >>> attack = PointWiseAttack(model) | |||
| """ | |||
| def __init__(self, | |||
| model, | |||
| max_iter=1000, | |||
| search_iter=10, | |||
| is_targeted=False, | |||
| init_attack=None, | |||
| sparse=True): | |||
| super(PointWiseAttack, self).__init__() | |||
| self._model = check_model('model', model, BlackModel) | |||
| self._max_iter = check_int_positive('max_iter', max_iter) | |||
| self._search_iter = check_int_positive('search_iter', search_iter) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| if init_attack is None: | |||
| self._init_attack = SaltAndPepperNoiseAttack(model, | |||
| is_targeted=self._is_targeted) | |||
| else: | |||
| self._init_attack = init_attack | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input samples and targeted labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to create | |||
| adversarial examples. | |||
| labels (numpy.ndarray): For targeted attack, labels are adversarial | |||
| target labels. For untargeted attack, labels are ground-truth labels. | |||
| Returns: | |||
| - numpy.ndarray, bool values for each attack result. | |||
| - numpy.ndarray, generated adversarial examples. | |||
| - numpy.ndarray, query times for each sample. | |||
| Examples: | |||
| >>> is_adv_list, adv_list, query_times_each_adv = attack.generate( | |||
| >>> [[0.1, 0.2, 0.6], [0.3, 0, 0.4]], | |||
| >>> [2, 3]) | |||
| """ | |||
| arr_x, arr_y = check_pair_numpy_param('inputs', inputs, 'labels', | |||
| labels) | |||
| if not self._sparse: | |||
| arr_y = np.argmax(arr_y, axis=1) | |||
| ini_bool, ini_advs, ini_count = self._initialize_starting_point(arr_x, | |||
| arr_y) | |||
| is_adv_list = list() | |||
| adv_list = list() | |||
| query_times_each_adv = list() | |||
| for sample, sample_label, start_adv, ite_bool, ite_c in zip(arr_x, | |||
| arr_y, | |||
| ini_advs, | |||
| ini_bool, | |||
| ini_count): | |||
| if ite_bool: | |||
| LOGGER.info(TAG, 'Start optimizing.') | |||
| ori_label = np.argmax( | |||
| self._model.predict(np.expand_dims(sample, axis=0))[0]) | |||
| ini_label = np.argmax(self._model.predict(np.expand_dims(start_adv, axis=0))[0]) | |||
| is_adv, adv_x, query_times = self._decision_optimize(sample, | |||
| sample_label, | |||
| start_adv) | |||
| adv_label = np.argmax( | |||
| self._model.predict(np.expand_dims(adv_x, axis=0))[0]) | |||
| LOGGER.debug(TAG, 'before ini attack label is :{}'.format(ori_label)) | |||
| LOGGER.debug(TAG, 'after ini attack label is :{}'.format(ini_label)) | |||
| LOGGER.debug(TAG, 'INPUT optimize label is :{}'.format(sample_label)) | |||
| LOGGER.debug(TAG, 'after pointwise attack label is :{}'.format(adv_label)) | |||
| is_adv_list.append(is_adv) | |||
| adv_list.append(adv_x) | |||
| query_times_each_adv.append(query_times + ite_c) | |||
| else: | |||
| LOGGER.info(TAG, 'Initial sample is not adversarial, pass.') | |||
| is_adv_list.append(False) | |||
| adv_list.append(start_adv) | |||
| query_times_each_adv.append(ite_c) | |||
| is_adv_list = np.array(is_adv_list) | |||
| adv_list = np.array(adv_list) | |||
| query_times_each_adv = np.array(query_times_each_adv) | |||
| LOGGER.debug(TAG, 'ret list is: {}'.format(adv_list)) | |||
| return is_adv_list, adv_list, query_times_each_adv | |||
| def _decision_optimize(self, unperturbed_img, input_label, perturbed_img): | |||
| """ | |||
| Make the perturbed samples more similar to unperturbed samples, | |||
| while maintaining the perturbed_label. | |||
| Args: | |||
| unperturbed_img (numpy.ndarray): Input sample as reference to create | |||
| adversarial example. | |||
| input_label (numpy.ndarray): Input label. | |||
| perturbed_img (numpy.ndarray): Starting point to optimize. | |||
| Returns: | |||
| numpy.ndarray, a generated adversarial example. | |||
| Raises: | |||
| ValueError: if input unperturbed and perturbed samples have different size. | |||
| """ | |||
| query_count = 0 | |||
| img_size = unperturbed_img.size | |||
| img_shape = unperturbed_img.shape | |||
| perturbed_img = perturbed_img.reshape(-1) | |||
| unperturbed_img = unperturbed_img.reshape(-1) | |||
| recover = np.copy(perturbed_img) | |||
| if unperturbed_img.dtype != perturbed_img.dtype: | |||
| msg = 'unperturbed sample and perturbed sample must have the same' \ | |||
| ' dtype, but got dtype of unperturbed is: {}, dtype of perturbed ' \ | |||
| 'is: {}'.format(unperturbed_img.dtype, perturbed_img.dtype) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| LOGGER.debug(TAG, 'Before optimize, the mse distance between original ' | |||
| 'sample and adversarial sample is: {}' | |||
| .format(self._distance(perturbed_img, unperturbed_img))) | |||
| # recover pixel if image is adversarial | |||
| for _ in range(self._max_iter): | |||
| is_improve = False | |||
| # at the premise of adversarial feature, recover pixels | |||
| pixels_ind = np.arange(img_size) | |||
| mask = unperturbed_img != perturbed_img | |||
| np.random.shuffle(pixels_ind) | |||
| for ite_ind in pixels_ind: | |||
| if mask[ite_ind]: | |||
| recover[ite_ind] = unperturbed_img[ite_ind] | |||
| query_count += 1 | |||
| is_adv = self._model.is_adversarial( | |||
| recover.reshape(img_shape), input_label, self._is_targeted) | |||
| if is_adv: | |||
| is_improve = True | |||
| perturbed_img[ite_ind] = recover[ite_ind] | |||
| break | |||
| else: | |||
| recover[ite_ind] = perturbed_img[ite_ind] | |||
| if not is_improve or (self._distance( | |||
| perturbed_img, unperturbed_img) <= self._get_threthod()): | |||
| break | |||
| LOGGER.debug(TAG, 'first round: Query count {}'.format(query_count)) | |||
| LOGGER.debug(TAG, 'Starting binary searches.') | |||
| # tag the optimized pixels. | |||
| mask = unperturbed_img != perturbed_img | |||
| for _ in range(self._max_iter): | |||
| is_improve = False | |||
| pixels_ind = np.arange(img_size) | |||
| np.random.shuffle(pixels_ind) | |||
| for ite_ind in pixels_ind: | |||
| if not mask[ite_ind]: | |||
| continue | |||
| recover[ite_ind] = unperturbed_img[ite_ind] | |||
| query_count += 1 | |||
| is_adv = self._model.is_adversarial(recover.reshape(img_shape), | |||
| input_label, | |||
| self._is_targeted) | |||
| if is_adv: | |||
| is_improve = True | |||
| mask[ite_ind] = True | |||
| perturbed_img[ite_ind] = recover[ite_ind] | |||
| LOGGER.debug(TAG, | |||
| 'Reset {}th pixel value to original, ' | |||
| 'mse distance: {}.'.format( | |||
| ite_ind, | |||
| self._distance(perturbed_img, | |||
| unperturbed_img))) | |||
| break | |||
| else: | |||
| # use binary searches | |||
| optimized_value, b_query = self._binary_search( | |||
| perturbed_img, | |||
| unperturbed_img, | |||
| ite_ind, | |||
| input_label, img_shape) | |||
| query_count += b_query | |||
| if optimized_value != perturbed_img[ite_ind]: | |||
| is_improve = True | |||
| mask[ite_ind] = True | |||
| perturbed_img[ite_ind] = optimized_value | |||
| LOGGER.debug(TAG, | |||
| 'Reset {}th pixel value to original, ' | |||
| 'mse distance: {}.'.format( | |||
| ite_ind, | |||
| self._distance(perturbed_img, | |||
| unperturbed_img))) | |||
| break | |||
| if not is_improve or (self._distance( | |||
| perturbed_img, unperturbed_img) <= self._get_threthod()): | |||
| LOGGER.debug(TAG, 'second optimized finish.') | |||
| break | |||
| LOGGER.info(TAG, 'Optimized finished, query count is {}'.format(query_count)) | |||
| # this method use to optimized the adversarial sample | |||
| return True, perturbed_img.reshape(img_shape), query_count | |||
| def _binary_search(self, perturbed_img, unperturbed_img, ite_ind, | |||
| input_label, img_shape): | |||
| """ | |||
| For original pixel of inputs, use binary search to get the nearest pixel | |||
| value with original value with adversarial feature. | |||
| Args: | |||
| perturbed_img (numpy.ndarray): Adversarial sample. | |||
| unperturbed_img (numpy.ndarray): Input sample. | |||
| ite_ind (int): The index of pixel in inputs. | |||
| input_label (numpy.ndarray): Input labels. | |||
| img_shape (tuple): Shape of the original sample. | |||
| Returns: | |||
| float, adversarial pixel value. | |||
| """ | |||
| query_count = 0 | |||
| adv_value = perturbed_img[ite_ind] | |||
| non_adv_value = unperturbed_img[ite_ind] | |||
| for _ in range(self._search_iter): | |||
| next_value = (adv_value + non_adv_value) / 2 | |||
| recover = np.copy(perturbed_img) | |||
| recover[ite_ind] = next_value | |||
| query_count += 1 | |||
| is_adversarial = self._model.is_adversarial( | |||
| recover.reshape(img_shape), input_label, self._is_targeted) | |||
| if is_adversarial: | |||
| adv_value = next_value | |||
| else: | |||
| non_adv_value = next_value | |||
| return adv_value, query_count | |||
| def _initialize_starting_point(self, inputs, labels): | |||
| """ | |||
| Use init_attack to generate original adversarial inputs. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input sample used as references to create | |||
| adversarial examples. | |||
| labels (numpy.ndarray): If is targeted attack, labels is adversarial | |||
| labels, if is untargeted attack, labels is true labels. | |||
| Returns: | |||
| numpy.ndarray, adversarial image(s) generate by init_attack method. | |||
| """ | |||
| is_adv, start_adv, query_c = self._init_attack.generate(inputs, labels) | |||
| return is_adv, start_adv, query_c | |||
| def _distance(self, perturbed_img, unperturbed_img): | |||
| """ | |||
| Calculate Mean Squared Error (MSE) to evaluate the optimized process. | |||
| Args: | |||
| perturbed_img (numpy.ndarray): Adversarial sample to be optimized. | |||
| unperturbed_img (numpy.ndarray): As a reference benigh sample. | |||
| Returns: | |||
| float, Calculation of Mean Squared Error (MSE). | |||
| """ | |||
| return np.square(np.subtract(perturbed_img, unperturbed_img)).mean() | |||
| def _get_threthod(self, method='MSE'): | |||
| """ | |||
| Return a float number, when distance small than this number, | |||
| optimize will abort early. | |||
| Args: | |||
| method: distance method. Default: MSE. | |||
| Returns: | |||
| float, the optimized level, the smaller of number, the better | |||
| of adversarial sample. | |||
| """ | |||
| predefined_threshold = 0.01 | |||
| if method == 'MSE': | |||
| return predefined_threshold | |||
| return predefined_threshold | |||
+ 302
- 0
mindarmour/attacks/black/pso_attack.py
View File
| @@ -0,0 +1,302 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| PSO-Attack. | |||
| """ | |||
| import numpy as np | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils._check_param import check_model, check_pair_numpy_param, \ | |||
| check_numpy_param, check_value_positive, check_int_positive, \ | |||
| check_param_type, check_equal_shape, check_param_multi_types | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'PSOAttack' | |||
| class PSOAttack(Attack): | |||
| """ | |||
| The PSO Attack represents the black-box attack based on Particle Swarm | |||
| Optimization algorithm, which belongs to differential evolution algorithms. | |||
| This attack was proposed by Rayan Mosli et al. (2019). | |||
| References: `Rayan Mosli, Matthew Wright, Bo Yuan, Yin Pan, "They Might NOT | |||
| Be Giants: Crafting Black-Box Adversarial Examples with Fewer Queries | |||
| Using Particle Swarm Optimization", arxiv: 1909.07490, 2019. | |||
| <https://arxiv.org/abs/1909.07490>`_ | |||
| Args: | |||
| model (BlackModel): Target model. | |||
| step_size (float): Attack step size. Default: 0.5. | |||
| per_bounds (float): Relative variation range of perturbations. Default: 0.6. | |||
| c1 (float): Weight coefficient. Default: 2. | |||
| c2 (float): Weight coefficient. Default: 2. | |||
| c (float): Weight of perturbation loss. Default: 2. | |||
| pop_size (int): The number of particles, which should be greater | |||
| than zero. Default: 6. | |||
| t_max (int): The maximum round of iteration for each adversarial example, | |||
| which should be greater than zero. Default: 1000. | |||
| pm (float): The probability of mutations. Default: 0.5. | |||
| bounds (tuple): Upper and lower bounds of data. In form of (clip_min, | |||
| clip_max). Default: None. | |||
| targeted (bool): If True, turns on the targeted attack. If False, | |||
| turns on untargeted attack. Default: False. | |||
| reduction_iters (int): Cycle times in reduction process. Default: 3. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: True. | |||
| Examples: | |||
| >>> attack = PSOAttack(model) | |||
| """ | |||
| def __init__(self, model, step_size=0.5, per_bounds=0.6, c1=2.0, c2=2.0, | |||
| c=2.0, pop_size=6, t_max=1000, pm=0.5, bounds=None, | |||
| targeted=False, reduction_iters=3, sparse=True): | |||
| super(PSOAttack, self).__init__() | |||
| self._model = check_model('model', model, BlackModel) | |||
| self._step_size = check_value_positive('step_size', step_size) | |||
| self._per_bounds = check_value_positive('per_bounds', per_bounds) | |||
| self._c1 = check_value_positive('c1', c1) | |||
| self._c2 = check_value_positive('c2', c2) | |||
| self._c = check_value_positive('c', c) | |||
| self._pop_size = check_int_positive('pop_size', pop_size) | |||
| self._pm = check_value_positive('pm', pm) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [list, tuple]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| self._targeted = check_param_type('targeted', targeted, bool) | |||
| self._t_max = check_int_positive('t_max', t_max) | |||
| self._reduce_iters = check_int_positive('reduction_iters', | |||
| reduction_iters) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| def _fitness(self, confi_ori, confi_adv, x_ori, x_adv): | |||
| """ | |||
| Calculate the fitness value for each particle. | |||
| Args: | |||
| confi_ori (float): Maximum confidence or target label confidence of | |||
| the original benign inputs' prediction confidences. | |||
| confi_adv (float): Maximum confidence or target label confidence of | |||
| the adversarial samples' prediction confidences. | |||
| x_ori (numpy.ndarray): Benign samples. | |||
| x_adv (numpy.ndarray): Adversarial samples. | |||
| Returns: | |||
| - float, fitness values of adversarial particles. | |||
| - int, query times after reduction. | |||
| Examples: | |||
| >>> fitness = self._fitness(2.4, 1.2, [0.2, 0.3, 0.1], [0.21, | |||
| >>> 0.34, 0.13]) | |||
| """ | |||
| x_ori = check_numpy_param('x_ori', x_ori) | |||
| x_adv = check_numpy_param('x_adv', x_adv) | |||
| fit_value = abs( | |||
| confi_ori - confi_adv) - self._c / self._pop_size*np.linalg.norm( | |||
| (x_adv - x_ori).reshape(x_adv.shape[0], -1), axis=1) | |||
| return fit_value | |||
| def _mutation_op(self, cur_pop): | |||
| """ | |||
| Generate mutation samples. | |||
| """ | |||
| cur_pop = check_numpy_param('cur_pop', cur_pop) | |||
| perturb_noise = np.random.random(cur_pop.shape) - 0.5 | |||
| mutated_pop = perturb_noise*(np.random.random(cur_pop.shape) | |||
| < self._pm) + cur_pop | |||
| mutated_pop = np.clip(mutated_pop, cur_pop*(1 - self._per_bounds), | |||
| cur_pop*(1 + self._per_bounds)) | |||
| return mutated_pop | |||
| def _reduction(self, x_ori, q_times, label, best_position): | |||
| """ | |||
| Decrease the differences between the original samples and adversarial samples. | |||
| Args: | |||
| x_ori (numpy.ndarray): Original samples. | |||
| q_times (int): Query times. | |||
| label (int): Target label ot ground-truth label. | |||
| best_position (numpy.ndarray): Adversarial examples. | |||
| Returns: | |||
| numpy.ndarray, adversarial examples after reduction. | |||
| Examples: | |||
| >>> adv_reduction = self._reduction(self, [0.1, 0.2, 0.3], 20, 1, | |||
| >>> [0.12, 0.15, 0.25]) | |||
| """ | |||
| x_ori = check_numpy_param('x_ori', x_ori) | |||
| best_position = check_numpy_param('best_position', best_position) | |||
| x_ori, best_position = check_equal_shape('x_ori', x_ori, | |||
| 'best_position', best_position) | |||
| x_ori_fla = x_ori.flatten() | |||
| best_position_fla = best_position.flatten() | |||
| pixel_deep = self._bounds[1] - self._bounds[0] | |||
| nums_pixel = len(x_ori_fla) | |||
| for i in range(nums_pixel): | |||
| diff = x_ori_fla[i] - best_position_fla[i] | |||
| if abs(diff) > pixel_deep*0.1: | |||
| old_poi_fla = np.copy(best_position_fla) | |||
| best_position_fla[i] = np.clip( | |||
| best_position_fla[i] + diff*0.5, | |||
| self._bounds[0], self._bounds[1]) | |||
| cur_label = np.argmax( | |||
| self._model.predict(np.expand_dims( | |||
| best_position_fla.reshape(x_ori.shape), axis=0))[0]) | |||
| q_times += 1 | |||
| if self._targeted: | |||
| if cur_label != label: | |||
| best_position_fla = old_poi_fla | |||
| else: | |||
| if cur_label == label: | |||
| best_position_fla = old_poi_fla | |||
| return best_position_fla.reshape(x_ori.shape), q_times | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input data and targeted | |||
| labels (or ground_truth labels). | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Targeted labels or ground_truth labels. | |||
| Returns: | |||
| - numpy.ndarray, bool values for each attack result. | |||
| - numpy.ndarray, generated adversarial examples. | |||
| - numpy.ndarray, query times for each sample. | |||
| Examples: | |||
| >>> advs = attack.generate([[0.2, 0.3, 0.4], [0.3, 0.3, 0.2]], | |||
| >>> [1, 2]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| # generate one adversarial each time | |||
| if self._targeted: | |||
| target_labels = labels | |||
| adv_list = [] | |||
| success_list = [] | |||
| query_times_list = [] | |||
| pixel_deep = self._bounds[1] - self._bounds[0] | |||
| for i in range(inputs.shape[0]): | |||
| is_success = False | |||
| q_times = 0 | |||
| x_ori = inputs[i] | |||
| confidences = self._model.predict(np.expand_dims(x_ori, axis=0))[0] | |||
| q_times += 1 | |||
| true_label = labels[i] | |||
| if self._targeted: | |||
| t_label = target_labels[i] | |||
| confi_ori = confidences[t_label] | |||
| else: | |||
| confi_ori = max(confidences) | |||
| # step1, initializing | |||
| # initial global optimum fitness value, cannot set to be 0 | |||
| best_fitness = -np.inf | |||
| # initial global optimum position | |||
| best_position = x_ori | |||
| x_copies = np.repeat(x_ori[np.newaxis, :], self._pop_size, axis=0) | |||
| cur_noise = np.clip((np.random.random(x_copies.shape) - 0.5) | |||
| *self._step_size, | |||
| (0 - self._per_bounds)*(x_copies + 0.1), | |||
| self._per_bounds*(x_copies + 0.1)) | |||
| par = np.clip(x_copies + cur_noise, | |||
| x_copies*(1 - self._per_bounds), | |||
| x_copies*(1 + self._per_bounds)) | |||
| # initial advs | |||
| par_ori = np.copy(par) | |||
| # initial optimum positions for particles | |||
| par_best_poi = np.copy(par) | |||
| # initial optimum fitness values | |||
| par_best_fit = -np.inf*np.ones(self._pop_size) | |||
| # step2, optimization | |||
| # initial velocities for particles | |||
| v_particles = np.zeros(par.shape) | |||
| is_mutation = False | |||
| iters = 0 | |||
| while iters < self._t_max: | |||
| last_best_fit = best_fitness | |||
| ran_1 = np.random.random(par.shape) | |||
| ran_2 = np.random.random(par.shape) | |||
| v_particles = self._step_size*( | |||
| v_particles + self._c1*ran_1*(best_position - par)) \ | |||
| + self._c2*ran_2*(par_best_poi - par) | |||
| par = np.clip(par + v_particles, | |||
| (par_ori + 0.1*pixel_deep)*( | |||
| 1 - self._per_bounds), | |||
| (par_ori + 0.1*pixel_deep)*( | |||
| 1 + self._per_bounds)) | |||
| if iters > 30 and is_mutation: | |||
| par = self._mutation_op(par) | |||
| if self._targeted: | |||
| confi_adv = self._model.predict(par)[:, t_label] | |||
| else: | |||
| confi_adv = np.max(self._model.predict(par), axis=1) | |||
| q_times += self._pop_size | |||
| fit_value = self._fitness(confi_ori, confi_adv, x_ori, par) | |||
| for k in range(self._pop_size): | |||
| if fit_value[k] > par_best_fit[k]: | |||
| par_best_fit[k] = fit_value[k] | |||
| par_best_poi[k] = par[k] | |||
| if fit_value[k] > best_fitness: | |||
| best_fitness = fit_value[k] | |||
| best_position = par[k] | |||
| iters += 1 | |||
| cur_pre = self._model.predict(np.expand_dims(best_position, | |||
| axis=0))[0] | |||
| is_mutation = False | |||
| if (best_fitness - last_best_fit) < last_best_fit*0.05: | |||
| is_mutation = True | |||
| cur_label = np.argmax(cur_pre) | |||
| q_times += 1 | |||
| if self._targeted: | |||
| if cur_label == t_label: | |||
| is_success = True | |||
| else: | |||
| if cur_label != true_label: | |||
| is_success = True | |||
| if is_success: | |||
| LOGGER.debug(TAG, 'successfully find one adversarial ' | |||
| 'sample and start Reduction process') | |||
| # step3, reduction | |||
| if self._targeted: | |||
| best_position, q_times = self._reduction( | |||
| x_ori, q_times, t_label, best_position) | |||
| else: | |||
| best_position, q_times = self._reduction( | |||
| x_ori, q_times, true_label, best_position) | |||
| break | |||
| if not is_success: | |||
| LOGGER.debug(TAG, | |||
| 'fail to find adversarial sample, iteration ' | |||
| 'times is: %d and query times is: %d', | |||
| iters, | |||
| q_times) | |||
| adv_list.append(best_position) | |||
| success_list.append(is_success) | |||
| query_times_list.append(q_times) | |||
| del x_copies, cur_noise, par, par_ori, par_best_poi | |||
| return np.asarray(success_list), \ | |||
| np.asarray(adv_list), \ | |||
| np.asarray(query_times_list) | |||
+ 166
- 0
mindarmour/attacks/black/salt_and_pepper_attack.py
View File
| @@ -0,0 +1,166 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| SaltAndPepperNoise-Attack. | |||
| """ | |||
| import time | |||
| import numpy as np | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils._check_param import check_model, check_pair_numpy_param, \ | |||
| check_param_type, check_int_positive, check_param_multi_types | |||
| from mindarmour.utils._check_param import normalize_value | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'SaltAndPepperNoise-Attack' | |||
| class SaltAndPepperNoiseAttack(Attack): | |||
| """ | |||
| Increases the amount of salt and pepper noise to generate adversarial | |||
| samples. | |||
| Args: | |||
| model (BlackModel): Target model. | |||
| bounds (tuple): Upper and lower bounds of data. In form of (clip_min, | |||
| clip_max). Default: (0.0, 1.0) | |||
| max_iter (int): Max iteration to generate an adversarial example. | |||
| Default: 100 | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: True. | |||
| Examples: | |||
| >>> attack = SaltAndPepperNoiseAttack(model) | |||
| """ | |||
| def __init__(self, model, bounds=(0.0, 1.0), max_iter=100, | |||
| is_targeted=False, sparse=True): | |||
| super(SaltAndPepperNoiseAttack, self).__init__() | |||
| self._model = check_model('model', model, BlackModel) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [tuple, list]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| self._max_iter = check_int_positive('max_iter', max_iter) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input data and target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): The original, unperturbed inputs. | |||
| labels (numpy.ndarray): The target labels. | |||
| Returns: | |||
| - numpy.ndarray, bool values for each attack result. | |||
| - numpy.ndarray, generated adversarial examples. | |||
| - numpy.ndarray, query times for each sample. | |||
| Examples: | |||
| >>> adv_list = attack.generate(([[0.1, 0.2, 0.6], | |||
| >>> [0.3, 0, 0.4]], | |||
| >>> [[0, 1, 0, 0, 0, 0, 0, 0, 0, 0], | |||
| >>> [0, , 0, 1, 0, 0, 0, 0, 0, 0, 0]]) | |||
| """ | |||
| arr_x, arr_y = check_pair_numpy_param('inputs', inputs, 'labels', | |||
| labels) | |||
| if not self._sparse: | |||
| arr_y = np.argmax(arr_y, axis=1) | |||
| is_adv_list = list() | |||
| adv_list = list() | |||
| query_times_each_adv = list() | |||
| for sample, label in zip(arr_x, arr_y): | |||
| start_t = time.time() | |||
| is_adv, perturbed, query_times = self._generate_one(sample, label) | |||
| is_adv_list.append(is_adv) | |||
| adv_list.append(perturbed) | |||
| query_times_each_adv.append(query_times) | |||
| LOGGER.info(TAG, 'Finished one sample, adversarial is {}, ' | |||
| 'cost time {:.2}s' | |||
| .format(is_adv, time.time() - start_t)) | |||
| is_adv_list = np.array(is_adv_list) | |||
| adv_list = np.array(adv_list) | |||
| query_times_each_adv = np.array(query_times_each_adv) | |||
| return is_adv_list, adv_list, query_times_each_adv | |||
| def _generate_one(self, one_input, label, epsilons=10): | |||
| """ | |||
| Increases the amount of salt and pepper noise to generate adversarial | |||
| samples. | |||
| Args: | |||
| one_input (numpy.ndarray): The original, unperturbed input. | |||
| label (numpy.ndarray): The target label. | |||
| epsilons (int) : Number of steps to try probability between 0 | |||
| and 1. Default: 10 | |||
| Returns: | |||
| - numpy.ndarray, bool values for result. | |||
| - numpy.ndarray, adversarial example. | |||
| - numpy.ndarray, query times for this sample. | |||
| Examples: | |||
| >>> one_adv = self._generate_one(input, label) | |||
| """ | |||
| # use binary search to get epsilons | |||
| low_ = 0.0 | |||
| high_ = 1.0 | |||
| query_count = 0 | |||
| input_shape = one_input.shape | |||
| input_dtype = one_input.dtype | |||
| one_input = one_input.reshape(-1) | |||
| depth = np.abs(np.subtract(self._bounds[0], self._bounds[1])) | |||
| best_adv = np.copy(one_input) | |||
| best_eps = high_ | |||
| find_adv = False | |||
| for _ in range(self._max_iter): | |||
| min_eps = low_ | |||
| max_eps = (low_ + high_) / 2 | |||
| for _ in range(epsilons): | |||
| adv = np.copy(one_input) | |||
| noise = np.random.uniform(low=low_, high=high_, size=one_input.size) | |||
| eps = (min_eps + max_eps) / 2 | |||
| # add salt | |||
| adv[noise < eps] = -depth | |||
| # add pepper | |||
| adv[noise >= (high_ - eps)] = depth | |||
| # normalized sample | |||
| adv = normalize_value(np.expand_dims(adv, axis=0), 'l2').astype(input_dtype) | |||
| query_count += 1 | |||
| ite_bool = self._model.is_adversarial(adv.reshape(input_shape), | |||
| label, | |||
| is_targeted=self._is_targeted) | |||
| if ite_bool: | |||
| find_adv = True | |||
| if best_eps > eps: | |||
| best_adv = adv | |||
| best_eps = eps | |||
| max_eps = eps | |||
| LOGGER.debug(TAG, 'Attack succeed, epsilon is {}'.format(eps)) | |||
| else: | |||
| min_eps = eps | |||
| if find_adv: | |||
| break | |||
| return find_adv, best_adv.reshape(input_shape), query_count | |||
+ 419
- 0
mindarmour/attacks/carlini_wagner.py
View File
| @@ -0,0 +1,419 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Carlini-wagner Attack. | |||
| """ | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_numpy_param, check_model, \ | |||
| check_pair_numpy_param, check_int_positive, check_param_type, \ | |||
| check_param_multi_types, check_value_positive, check_equal_shape | |||
| from mindarmour.utils.util import GradWrap | |||
| from mindarmour.utils.util import jacobian_matrix | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'CW' | |||
| def _best_logits_of_other_class(logits, target_class, value=1): | |||
| """ | |||
| Choose the index of the largest logits exclude target class. | |||
| Args: | |||
| logits (numpy.ndarray): Predict logits of samples. | |||
| target_class (numpy.ndarray): Target labels. | |||
| value (float): Maximum value of output logits. Default: 1. | |||
| Returns: | |||
| numpy.ndarray, the index of the largest logits exclude the target | |||
| class. | |||
| Examples: | |||
| >>> other_class = _best_logits_of_other_class([[0.2, 0.3, 0.5], | |||
| >>> [0.3, 0.4, 0.3]], [2, 1]) | |||
| """ | |||
| LOGGER.debug(TAG, "enter the func _best_logits_of_other_class.") | |||
| logits, target_class = check_pair_numpy_param('logits', logits, | |||
| 'target_class', target_class) | |||
| res = np.zeros_like(logits) | |||
| for i in range(logits.shape[0]): | |||
| res[i][target_class[i]] = value | |||
| return np.argmax(logits - res, axis=1) | |||
| class CarliniWagnerL2Attack(Attack): | |||
| """ | |||
| The Carlini & Wagner attack using L2 norm. | |||
| References: `Nicholas Carlini, David Wagner: "Towards Evaluating | |||
| the Robustness of Neural Networks" <https://arxiv.org/abs/1608.04644>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| num_classes (int): Number of labels of model output, which should be | |||
| greater than zero. | |||
| box_min (float): Lower bound of input of the target model. Default: 0. | |||
| box_max (float): Upper bound of input of the target model. Default: 1.0. | |||
| bin_search_steps (int): The number of steps for the binary search | |||
| used to find the optimal trade-off constant between distance | |||
| and confidence. Default: 5. | |||
| max_iterations (int): The maximum number of iterations, which should be | |||
| greater than zero. Default: 1000. | |||
| confidence (float): Confidence of the output of adversarial examples. | |||
| Default: 0. | |||
| learning_rate (float): The learning rate for the attack algorithm. | |||
| Default: 5e-3. | |||
| initial_const (float): The initial trade-off constant to use to balance | |||
| the relative importance of perturbation norm and confidence | |||
| difference. Default: 1e-2. | |||
| abort_early_check_ratio (float): Check loss progress every ratio of | |||
| all iteration. Default: 5e-2. | |||
| targeted (bool): If True, targeted attack. If False, untargeted attack. | |||
| Default: False. | |||
| fast (bool): If True, return the first found adversarial example. | |||
| If False, return the adversarial samples with smaller | |||
| perturbations. Default: True. | |||
| abort_early (bool): If True, Adam will be aborted if the loss hasn't | |||
| decreased for some time. If False, Adam will continue work until the | |||
| max iterations is arrived. Default: True. | |||
| sparse (bool): If True, input labels are sparse-coded. If False, | |||
| input labels are onehot-coded. Default: True. | |||
| Examples: | |||
| >>> attack = CarliniWagnerL2Attack(network) | |||
| """ | |||
| def __init__(self, network, num_classes, box_min=0.0, box_max=1.0, | |||
| bin_search_steps=5, max_iterations=1000, confidence=0, | |||
| learning_rate=5e-3, initial_const=1e-2, | |||
| abort_early_check_ratio=5e-2, targeted=False, | |||
| fast=True, abort_early=True, sparse=True): | |||
| LOGGER.info(TAG, "init CW object.") | |||
| super(CarliniWagnerL2Attack, self).__init__() | |||
| self._network = check_model('network', network, Cell) | |||
| self._num_classes = check_int_positive('num_classes', num_classes) | |||
| self._min = check_param_type('box_min', box_min, float) | |||
| self._max = check_param_type('box_max', box_max, float) | |||
| self._bin_search_steps = check_int_positive('search_steps', | |||
| bin_search_steps) | |||
| self._max_iterations = check_int_positive('max_iterations', | |||
| max_iterations) | |||
| self._confidence = check_param_multi_types('confidence', confidence, | |||
| [int, float]) | |||
| self._learning_rate = check_value_positive('learning_rate', | |||
| learning_rate) | |||
| self._initial_const = check_value_positive('initial_const', | |||
| initial_const) | |||
| self._abort_early = check_param_type('abort_early', abort_early, bool) | |||
| self._fast = check_param_type('fast', fast, bool) | |||
| self._abort_early_check_ratio = check_value_positive('abort_early_check_ratio', | |||
| abort_early_check_ratio) | |||
| self._targeted = check_param_type('targeted', targeted, bool) | |||
| self._net_grad = GradWrap(self._network) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| self._dtype = None | |||
| def _loss_function(self, logits, new_x, org_x, org_or_target_class, | |||
| constant, confidence): | |||
| """ | |||
| Calculate the value of loss function and gradients of loss w.r.t inputs. | |||
| Args: | |||
| logits (numpy.ndarray): The output of network before softmax. | |||
| new_x (numpy.ndarray): Adversarial examples. | |||
| org_x (numpy.ndarray): Original benign input samples. | |||
| org_or_target_class (numpy.ndarray): Original/target labels. | |||
| constant (float): A trade-off constant to use to balance loss | |||
| and perturbation norm. | |||
| confidence (float): Confidence level of the output of adversarial | |||
| examples. | |||
| Returns: | |||
| numpy.ndarray, norm of perturbation, sum of the loss and the | |||
| norm, and gradients of the sum w.r.t inputs. | |||
| Raises: | |||
| ValueError: If loss is less than 0. | |||
| Examples: | |||
| >>> L2_loss, total_loss, dldx = self._loss_function([0.2 , 0.3, | |||
| >>> 0.5], [0.1, 0.2, 0.2, 0.4], [0.12, 0.2, 0.25, 0.4], [1], 2, 0) | |||
| """ | |||
| LOGGER.debug(TAG, "enter the func _loss_function.") | |||
| logits = check_numpy_param('logits', logits) | |||
| org_x = check_numpy_param('org_x', org_x) | |||
| new_x, org_or_target_class = check_pair_numpy_param('new_x', | |||
| new_x, | |||
| 'org_or_target_class', | |||
| org_or_target_class) | |||
| new_x, org_x = check_equal_shape('new_x', new_x, 'org_x', org_x) | |||
| other_class_index = _best_logits_of_other_class( | |||
| logits, org_or_target_class, value=np.inf) | |||
| loss1 = np.sum((new_x - org_x)**2, | |||
| axis=tuple(range(len(new_x.shape))[1:])) | |||
| loss2 = np.zeros_like(loss1, dtype=self._dtype) | |||
| loss2_grade = np.zeros_like(new_x, dtype=self._dtype) | |||
| jaco_grad = jacobian_matrix(self._net_grad, new_x, self._num_classes) | |||
| if self._targeted: | |||
| for i in range(org_or_target_class.shape[0]): | |||
| loss2[i] = max(0, logits[i][other_class_index[i]] | |||
| - logits[i][org_or_target_class[i]] | |||
| + confidence) | |||
| loss2_grade[i] = constant[i]*(jaco_grad[other_class_index[ | |||
| i]][i] - jaco_grad[org_or_target_class[i]][i]) | |||
| else: | |||
| for i in range(org_or_target_class.shape[0]): | |||
| loss2[i] = max(0, logits[i][org_or_target_class[i]] | |||
| - logits[i][other_class_index[i]] + confidence) | |||
| loss2_grade[i] = constant[i]*(jaco_grad[org_or_target_class[ | |||
| i]][i] - jaco_grad[other_class_index[i]][i]) | |||
| total_loss = loss1 + constant*loss2 | |||
| loss1_grade = 2*(new_x - org_x) | |||
| for i in range(org_or_target_class.shape[0]): | |||
| if loss2[i] < 0: | |||
| msg = 'loss value should greater than or equal to 0, ' \ | |||
| 'but got loss2 {}'.format(loss2[i]) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| if loss2[i] == 0: | |||
| loss2_grade[i, ...] = 0 | |||
| total_loss_grade = loss1_grade + loss2_grade | |||
| return loss1, total_loss, total_loss_grade | |||
| def _to_attack_space(self, inputs): | |||
| """ | |||
| Transform input data into attack space. | |||
| Args: | |||
| inputs (numpy.ndarray): Input data. | |||
| Returns: | |||
| numpy.ndarray, transformed data which belongs to attack space. | |||
| Examples: | |||
| >>> x_att = self._to_attack_space([0.2, 0.3, 0.3]) | |||
| """ | |||
| LOGGER.debug(TAG, "enter the func _to_attack_space.") | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| mean = (self._min + self._max) / 2 | |||
| diff = (self._max - self._min) / 2 | |||
| inputs = (inputs - mean) / diff | |||
| inputs = inputs*0.999999 | |||
| return np.arctanh(inputs) | |||
| def _to_model_space(self, inputs): | |||
| """ | |||
| Transform input data into model space. | |||
| Args: | |||
| inputs (numpy.ndarray): Input data. | |||
| Returns: | |||
| numpy.ndarray, transformed data which belongs to model space | |||
| and the gradient of x_model w.r.t. x_att. | |||
| Examples: | |||
| >>> x_att = self._to_model_space([10, 21, 9]) | |||
| """ | |||
| LOGGER.debug(TAG, "enter the func _to_model_space.") | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| inputs = np.tanh(inputs) | |||
| the_grad = 1 - np.square(inputs) | |||
| mean = (self._min + self._max) / 2 | |||
| diff = (self._max - self._min) / 2 | |||
| inputs = inputs*diff + mean | |||
| the_grad = the_grad*diff | |||
| return inputs, the_grad | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input data and targeted labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): The ground truth label of input samples | |||
| or target labels. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples. | |||
| Examples: | |||
| >>> advs = attack.generate([[0.1, 0.2, 0.6], [0.3, 0, 0.4]], [1, 2]] | |||
| """ | |||
| LOGGER.debug(TAG, "enter the func generate.") | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| self._dtype = inputs.dtype | |||
| att_original = self._to_attack_space(inputs) | |||
| reconstructed_original, _ = self._to_model_space(att_original) | |||
| # find an adversarial sample | |||
| const = np.ones_like(labels, dtype=self._dtype)*self._initial_const | |||
| lower_bound = np.zeros_like(labels, dtype=self._dtype) | |||
| upper_bound = np.ones_like(labels, dtype=self._dtype)*np.inf | |||
| adversarial_res = inputs.copy() | |||
| adversarial_loss = np.ones_like(labels, dtype=self._dtype)*np.inf | |||
| samples_num = labels.shape[0] | |||
| adv_flag = np.zeros_like(labels) | |||
| for binary_search_step in range(self._bin_search_steps): | |||
| if (binary_search_step == self._bin_search_steps - 1) and \ | |||
| (self._bin_search_steps >= 10): | |||
| const = min(1e10, upper_bound) | |||
| LOGGER.debug(TAG, | |||
| 'starting optimization with const = %s', | |||
| str(const)) | |||
| att_perturbation = np.zeros_like(att_original, dtype=self._dtype) | |||
| loss_at_previous_check = np.ones_like(labels, dtype=self._dtype)*np.inf | |||
| # create a new optimizer to minimize the perturbation | |||
| optimizer = _AdamOptimizer(att_perturbation.shape) | |||
| for iteration in range(self._max_iterations): | |||
| x_input, dxdp = self._to_model_space( | |||
| att_original + att_perturbation) | |||
| logits = self._network(Tensor(x_input)).asnumpy() | |||
| current_l2_loss, current_loss, dldx = self._loss_function( | |||
| logits, x_input, reconstructed_original, | |||
| labels, const, self._confidence) | |||
| # check if attack success (include all examples) | |||
| if self._targeted: | |||
| is_adv = (np.argmax(logits, axis=1) == labels) | |||
| else: | |||
| is_adv = (np.argmax(logits, axis=1) != labels) | |||
| for i in range(samples_num): | |||
| if is_adv[i]: | |||
| adv_flag[i] = True | |||
| if current_l2_loss[i] < adversarial_loss[i]: | |||
| adversarial_res[i] = x_input[i] | |||
| adversarial_loss[i] = current_l2_loss[i] | |||
| if np.all(adv_flag): | |||
| if self._fast: | |||
| LOGGER.debug(TAG, "succeed find adversarial examples.") | |||
| msg = 'iteration: {}, logits_att: {}, ' \ | |||
| 'loss: {}, l2_dist: {}' \ | |||
| .format(iteration, | |||
| np.argmax(logits, axis=1), | |||
| current_loss, current_l2_loss) | |||
| LOGGER.debug(TAG, msg) | |||
| return adversarial_res | |||
| dldx, inputs = check_equal_shape('dldx', dldx, 'inputs', inputs) | |||
| gradient = dldx*dxdp | |||
| att_perturbation += \ | |||
| optimizer(gradient, self._learning_rate) | |||
| # check if should stop iteration early | |||
| flag = True | |||
| iter_check = iteration % (np.ceil( | |||
| self._max_iterations*self._abort_early_check_ratio)) | |||
| if self._abort_early and iter_check == 0: | |||
| # check progress | |||
| for i in range(inputs.shape[0]): | |||
| if current_loss[i] <= .9999*loss_at_previous_check[i]: | |||
| flag = False | |||
| # stop Adam if all samples has no progress | |||
| if flag: | |||
| LOGGER.debug(TAG, | |||
| 'step:%d, no progress yet, stop iteration', | |||
| binary_search_step) | |||
| break | |||
| loss_at_previous_check = current_loss | |||
| for i in range(samples_num): | |||
| # update bound based on search result | |||
| if adv_flag[i]: | |||
| LOGGER.debug(TAG, | |||
| 'example %d, found adversarial with const=%f', | |||
| i, const[i]) | |||
| upper_bound[i] = const[i] | |||
| else: | |||
| LOGGER.debug(TAG, | |||
| 'example %d, failed to find adversarial' | |||
| ' with const=%f', | |||
| i, const[i]) | |||
| lower_bound[i] = const[i] | |||
| if upper_bound[i] == np.inf: | |||
| const[i] *= 10 | |||
| else: | |||
| const[i] = (lower_bound[i] + upper_bound[i]) / 2 | |||
| return adversarial_res | |||
| class _AdamOptimizer: | |||
| """ | |||
| AdamOptimizer is used to calculate the optimum attack step. | |||
| Args: | |||
| shape (tuple): The shape of perturbations. | |||
| Examples: | |||
| >>> optimizer = _AdamOptimizer(att_perturbation.shape) | |||
| """ | |||
| def __init__(self, shape): | |||
| self._m = np.zeros(shape) | |||
| self._v = np.zeros(shape) | |||
| self._t = 0 | |||
| def __call__(self, gradient, learning_rate=0.001, | |||
| beta1=0.9, beta2=0.999, epsilon=1e-8): | |||
| """ | |||
| Calculate the optimum perturbation for each iteration. | |||
| Args: | |||
| gradient (numpy.ndarray): The gradient of the loss w.r.t. to the | |||
| variable. | |||
| learning_rate (float): The learning rate in the current iteration. | |||
| Default: 0.001. | |||
| beta1 (float): Decay rate for calculating the exponentially | |||
| decaying average of past gradients. Default: 0.9. | |||
| beta2 (float): Decay rate for calculating the exponentially | |||
| decaying average of past squared gradients. Default: 0.999. | |||
| epsilon (float): Small value to avoid division by zero. | |||
| Default: 1e-8. | |||
| Returns: | |||
| numpy.ndarray, perturbations. | |||
| Examples: | |||
| >>> perturbs = optimizer([0.2, 0.1, 0.15], 0.005) | |||
| """ | |||
| gradient = check_numpy_param('gradient', gradient) | |||
| self._t += 1 | |||
| self._m = beta1*self._m + (1 - beta1)*gradient | |||
| self._v = beta2*self._v + (1 - beta2)*gradient**2 | |||
| alpha = learning_rate*np.sqrt(1 - beta2**self._t) / (1 - beta1**self._t) | |||
| pertur = -alpha*self._m / (np.sqrt(self._v) + epsilon) | |||
| return pertur | |||
+ 154
- 0
mindarmour/attacks/deep_fool.py
View File
| @@ -0,0 +1,154 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| DeepFool Attack. | |||
| """ | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils.util import GradWrap | |||
| from mindarmour.utils.util import jacobian_matrix | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| check_value_positive, check_int_positive, check_norm_level, \ | |||
| check_param_multi_types, check_param_type | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'DeepFool' | |||
| class DeepFool(Attack): | |||
| """ | |||
| DeepFool is an untargeted & iterative attack achieved by moving the benign | |||
| sample to the nearest classification boundary and crossing the boundary. | |||
| Reference: `DeepFool: a simple and accurate method to fool deep neural | |||
| networks <https://arxiv.org/abs/1511.04599>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| num_classes (int): Number of labels of model output, which should be | |||
| greater than zero. | |||
| max_iters (int): Max iterations, which should be | |||
| greater than zero. Default: 50. | |||
| overshoot (float): Overshoot parameter. Default: 0.02. | |||
| norm_level (int): Order of the vector norm. Possible values: np.inf | |||
| or 2. Default: 2. | |||
| bounds (tuple): Upper and lower bounds of data range. In form of (clip_min, | |||
| clip_max). Default: None. | |||
| sparse (bool): If True, input labels are sparse-coded. If False, | |||
| input labels are onehot-coded. Default: True. | |||
| Examples: | |||
| >>> attack = DeepFool(network) | |||
| """ | |||
| def __init__(self, network, num_classes, max_iters=50, overshoot=0.02, | |||
| norm_level=2, bounds=None, sparse=True): | |||
| super(DeepFool, self).__init__() | |||
| self._network = check_model('network', network, Cell) | |||
| self._max_iters = check_int_positive('max_iters', max_iters) | |||
| self._overshoot = check_value_positive('overshoot', overshoot) | |||
| self._norm_level = check_norm_level(norm_level) | |||
| self._num_classes = check_int_positive('num_classes', num_classes) | |||
| self._net_grad = GradWrap(self._network) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [list, tuple]) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input samples and original labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Original labels. | |||
| Returns: | |||
| numpy.ndarray, adversarial examples. | |||
| Raises: | |||
| NotImplementedError: If norm_level is not in [2, np.inf, '2', 'inf']. | |||
| Examples: | |||
| >>> advs = generate([[0.2, 0.3, 0.4], [0.3, 0.4, 0.5]], [1, 2]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| inputs_dtype = inputs.dtype | |||
| iteration = 0 | |||
| origin_labels = labels | |||
| cur_labels = origin_labels.copy() | |||
| weight = np.squeeze(np.zeros(inputs.shape[1:])) | |||
| r_tot = np.zeros(inputs.shape) | |||
| x_origin = inputs | |||
| while np.any(cur_labels == origin_labels) and iteration < self._max_iters: | |||
| preds = self._network(Tensor(inputs)).asnumpy() | |||
| grads = jacobian_matrix(self._net_grad, inputs, self._num_classes) | |||
| for idx in range(inputs.shape[0]): | |||
| diff_w = np.inf | |||
| label = origin_labels[idx] | |||
| if cur_labels[idx] != label: | |||
| continue | |||
| for k in range(self._num_classes): | |||
| if k == label: | |||
| continue | |||
| w_k = grads[k, idx, ...] - grads[label, idx, ...] | |||
| f_k = preds[idx, k] - preds[idx, label] | |||
| if self._norm_level == 2 or self._norm_level == '2': | |||
| diff_w_k = abs(f_k) / (np.linalg.norm(w_k) + 1e-8) | |||
| elif self._norm_level == np.inf \ | |||
| or self._norm_level == 'inf': | |||
| diff_w_k = abs(f_k) / (np.linalg.norm(w_k, ord=1) + 1e-8) | |||
| else: | |||
| msg = 'ord {} is not available.' \ | |||
| .format(str(self._norm_level)) | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| if diff_w_k < diff_w: | |||
| diff_w = diff_w_k | |||
| weight = w_k | |||
| if self._norm_level == 2 or self._norm_level == '2': | |||
| r_i = diff_w*weight / (np.linalg.norm(weight) + 1e-8) | |||
| elif self._norm_level == np.inf or self._norm_level == 'inf': | |||
| r_i = diff_w*np.sign(weight) \ | |||
| / (np.linalg.norm(weight, ord=1) + 1e-8) | |||
| else: | |||
| msg = 'ord {} is not available in normalization.' \ | |||
| .format(str(self._norm_level)) | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| r_tot[idx, ...] = r_tot[idx, ...] + r_i | |||
| if self._bounds is not None: | |||
| clip_min, clip_max = self._bounds | |||
| inputs = x_origin + (1 + self._overshoot)*r_tot*(clip_max | |||
| - clip_min) | |||
| inputs = np.clip(inputs, clip_min, clip_max) | |||
| else: | |||
| inputs = x_origin + (1 + self._overshoot)*r_tot | |||
| cur_labels = np.argmax( | |||
| self._network(Tensor(inputs.astype(inputs_dtype))).asnumpy(), | |||
| axis=1) | |||
| iteration += 1 | |||
| inputs = inputs.astype(inputs_dtype) | |||
| del preds, grads | |||
| return inputs | |||
+ 402
- 0
mindarmour/attacks/gradient_method.py
View File
| @@ -0,0 +1,402 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Gradient-method Attack. | |||
| """ | |||
| from abc import abstractmethod | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.util import WithLossCell | |||
| from mindarmour.utils.util import GradWrapWithLoss | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| normalize_value, check_value_positive, check_param_multi_types, \ | |||
| check_norm_level, check_param_type | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'SingleGrad' | |||
| class GradientMethod(Attack): | |||
| """ | |||
| Abstract base class for all single-step gradient-based attacks. | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: None. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: None. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=None, bounds=None, | |||
| loss_fn=None): | |||
| super(GradientMethod, self).__init__() | |||
| self._network = check_model('network', network, Cell) | |||
| self._eps = check_value_positive('eps', eps) | |||
| self._dtype = None | |||
| if bounds is not None: | |||
| self._bounds = check_param_multi_types('bounds', bounds, | |||
| [list, tuple]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| else: | |||
| self._bounds = bounds | |||
| if alpha is not None: | |||
| self._alpha = check_value_positive('alpha', alpha) | |||
| else: | |||
| self._alpha = alpha | |||
| if loss_fn is None: | |||
| loss_fn = SoftmaxCrossEntropyWithLogits(is_grad=False, | |||
| sparse=False) | |||
| with_loss_cell = WithLossCell(self._network, loss_fn) | |||
| self._grad_all = GradWrapWithLoss(with_loss_cell) | |||
| self._grad_all.set_train() | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input samples and original/target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to create | |||
| adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples. | |||
| Examples: | |||
| >>> adv_x = attack.generate([[0.1, 0.2, 0.6], [0.3, 0, 0.4]], | |||
| >>> [[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],[0, , 0, 1, 0, 0, 0, 0, 0, 0, | |||
| >>> 0]]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| self._dtype = inputs.dtype | |||
| gradient = self._gradient(inputs, labels) | |||
| # use random method or not | |||
| if self._alpha is not None: | |||
| random_part = self._alpha*np.sign(np.random.normal( | |||
| size=inputs.shape)).astype(self._dtype) | |||
| perturbation = (self._eps - self._alpha)*gradient + random_part | |||
| else: | |||
| perturbation = self._eps*gradient | |||
| if self._bounds is not None: | |||
| clip_min, clip_max = self._bounds | |||
| perturbation = perturbation*(clip_max - clip_min) | |||
| adv_x = inputs + perturbation | |||
| adv_x = np.clip(adv_x, clip_min, clip_max) | |||
| else: | |||
| adv_x = inputs + perturbation | |||
| return adv_x | |||
| @abstractmethod | |||
| def _gradient(self, inputs, labels): | |||
| """ | |||
| Calculate gradients based on input samples and original/target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to | |||
| create adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function _gradient() is an abstract method in class ' \ | |||
| '`GradientMethod`, and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| class FastGradientMethod(GradientMethod): | |||
| """ | |||
| This attack is a one-step attack based on gradients calculation, and | |||
| the norm of perturbations includes L1, L2 and Linf. | |||
| References: `I. J. Goodfellow, J. Shlens, and C. Szegedy, "Explaining | |||
| and harnessing adversarial examples," in ICLR, 2015. | |||
| <https://arxiv.org/abs/1412.6572>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: None. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| norm_level (Union[int, numpy.inf]): Order of the norm. | |||
| Possible values: np.inf, 1 or 2. Default: 2. | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| Examples: | |||
| >>> attack = FastGradientMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=None, bounds=(0.0, 1.0), | |||
| norm_level=2, is_targeted=False, loss_fn=None): | |||
| super(FastGradientMethod, self).__init__(network, | |||
| eps=eps, | |||
| alpha=alpha, | |||
| bounds=bounds, | |||
| loss_fn=loss_fn) | |||
| self._norm_level = check_norm_level(norm_level) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| def _gradient(self, inputs, labels): | |||
| """ | |||
| Calculate gradients based on input samples and original/target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Input sample. | |||
| labels (numpy.ndarray): Original/target label. | |||
| Returns: | |||
| numpy.ndarray, gradient of inputs. | |||
| Examples: | |||
| >>> grad = self._gradient([[0.2, 0.3, 0.4]], | |||
| >>> [[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]) | |||
| """ | |||
| sens = Tensor(np.array([1.0], self._dtype)) | |||
| out_grad = self._grad_all(Tensor(inputs), Tensor(labels), sens) | |||
| if isinstance(out_grad, tuple): | |||
| out_grad = out_grad[0] | |||
| gradient = out_grad.asnumpy() | |||
| if self._is_targeted: | |||
| gradient = -gradient | |||
| return normalize_value(gradient, self._norm_level) | |||
| class RandomFastGradientMethod(FastGradientMethod): | |||
| """ | |||
| Fast Gradient Method use Random perturbation. | |||
| References: `Florian Tramer, Alexey Kurakin, Nicolas Papernot, "Ensemble | |||
| adversarial training: Attacks and defenses" in ICLR, 2018 | |||
| <https://arxiv.org/abs/1705.07204>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: 0.035. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| norm_level (Union[int, numpy.inf]): Order of the norm. | |||
| Possible values: np.inf, 1 or 2. Default: 2. | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| Raises: | |||
| ValueError: eps is smaller than alpha! | |||
| Examples: | |||
| >>> attack = RandomFastGradientMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=0.035, bounds=(0.0, 1.0), | |||
| norm_level=2, is_targeted=False, loss_fn=None): | |||
| if eps < alpha: | |||
| raise ValueError('eps must be larger than alpha!') | |||
| super(RandomFastGradientMethod, self).__init__(network, | |||
| eps=eps, | |||
| alpha=alpha, | |||
| bounds=bounds, | |||
| norm_level=norm_level, | |||
| is_targeted=is_targeted, | |||
| loss_fn=loss_fn) | |||
| class FastGradientSignMethod(GradientMethod): | |||
| """ | |||
| Use the sign instead of the value of the gradient to the input. This attack is | |||
| often referred to as Fast Gradient Sign Method and was introduced previously. | |||
| References: `Ian J. Goodfellow, J. Shlens, and C. Szegedy, "Explaining | |||
| and harnessing adversarial examples," in ICLR, 2015 | |||
| <https://arxiv.org/abs/1412.6572>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: None. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| Examples: | |||
| >>> attack = FastGradientSignMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=None, bounds=(0.0, 1.0), | |||
| is_targeted=False, loss_fn=None): | |||
| super(FastGradientSignMethod, self).__init__(network, | |||
| eps=eps, | |||
| alpha=alpha, | |||
| bounds=bounds, | |||
| loss_fn=loss_fn) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| def _gradient(self, inputs, labels): | |||
| """ | |||
| Calculate gradients based on input samples and original/target | |||
| labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, gradient of inputs. | |||
| Examples: | |||
| >>> grad = self._gradient([[0.2, 0.3, 0.4]], | |||
| >>> [[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]) | |||
| """ | |||
| sens = Tensor(np.array([1.0], self._dtype)) | |||
| out_grad = self._grad_all(Tensor(inputs), Tensor(labels), sens) | |||
| if isinstance(out_grad, tuple): | |||
| out_grad = out_grad[0] | |||
| gradient = out_grad.asnumpy() | |||
| if self._is_targeted: | |||
| gradient = -gradient | |||
| gradient = np.sign(gradient) | |||
| return gradient | |||
| class RandomFastGradientSignMethod(FastGradientSignMethod): | |||
| """ | |||
| Fast Gradient Sign Method using random perturbation. | |||
| References: `F. Tramer, et al., "Ensemble adversarial training: Attacks | |||
| and defenses," in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: 0.035. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| is_targeted (bool): True: targeted attack. False: untargeted attack. | |||
| Default: False. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| Raises: | |||
| ValueError: eps is smaller than alpha! | |||
| Examples: | |||
| >>> attack = RandomFastGradientSignMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=0.035, bounds=(0.0, 1.0), | |||
| is_targeted=False, loss_fn=None): | |||
| if eps < alpha: | |||
| raise ValueError('eps must be larger than alpha!') | |||
| super(RandomFastGradientSignMethod, self).__init__(network, | |||
| eps=eps, | |||
| alpha=alpha, | |||
| bounds=bounds, | |||
| is_targeted=is_targeted, | |||
| loss_fn=loss_fn) | |||
| class LeastLikelyClassMethod(FastGradientSignMethod): | |||
| """ | |||
| Least-Likely Class Method. | |||
| References: `F. Tramer, et al., "Ensemble adversarial training: Attacks | |||
| and defenses," in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: None. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| loss_fn (Loss): Loss function for optimization. | |||
| Examples: | |||
| >>> attack = LeastLikelyClassMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=None, bounds=(0.0, 1.0), | |||
| loss_fn=None): | |||
| super(LeastLikelyClassMethod, self).__init__(network, | |||
| eps=eps, | |||
| alpha=alpha, | |||
| bounds=bounds, | |||
| is_targeted=True, | |||
| loss_fn=loss_fn) | |||
| class RandomLeastLikelyClassMethod(FastGradientSignMethod): | |||
| """ | |||
| Least-Likely Class Method use Random perturbation. | |||
| References: `F. Tramer, et al., "Ensemble adversarial training: Attacks | |||
| and defenses," in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of single-step adversarial perturbation generated | |||
| by the attack to data range. Default: 0.07. | |||
| alpha (float): Proportion of single-step random perturbation to data range. | |||
| Default: 0.035. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| loss_fn (Loss): Loss function for optimization. | |||
| Raises: | |||
| ValueError: eps is smaller than alpha! | |||
| Examples: | |||
| >>> attack = RandomLeastLikelyClassMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.07, alpha=0.035, bounds=(0.0, 1.0), | |||
| loss_fn=None): | |||
| if eps < alpha: | |||
| raise ValueError('eps must be larger than alpha!') | |||
| super(RandomLeastLikelyClassMethod, self).__init__(network, | |||
| eps=eps, | |||
| alpha=alpha, | |||
| bounds=bounds, | |||
| is_targeted=True, | |||
| loss_fn=loss_fn) | |||
+ 432
- 0
mindarmour/attacks/iterative_gradient_method.py
View File
| @@ -0,0 +1,432 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ Iterative gradient method attack. """ | |||
| from abc import abstractmethod | |||
| import numpy as np | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils.util import WithLossCell | |||
| from mindarmour.utils.util import GradWrapWithLoss | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, \ | |||
| normalize_value, check_model, check_value_positive, check_int_positive, \ | |||
| check_param_type, check_norm_level, check_param_multi_types | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'IterGrad' | |||
| def _reshape_l1_projection(values, eps=3): | |||
| """ | |||
| `Implementation of L1 ball projection from:`_. | |||
| .. _`Implementation of L1 ball projection from:`: | |||
| https://stanford.edu/~jduchi/projects/DuchiShSiCh08.pdf | |||
| Args: | |||
| values (numpy.ndarray): Input data reshape into 2-dims. | |||
| eps (float): L1 radius. Default: 3. | |||
| Returns: | |||
| numpy.ndarray, containing the projection. | |||
| """ | |||
| abs_x = np.abs(values) | |||
| abs_x = np.sum(abs_x, axis=1) | |||
| indexes_b = (abs_x > eps) | |||
| x_b = values[indexes_b] | |||
| batch_size_b = x_b.shape[0] | |||
| if batch_size_b == 0: | |||
| return values | |||
| # make the projection on l1 ball for elements outside the ball | |||
| b_mu = -np.sort(-np.abs(x_b), axis=1) | |||
| b_vv = np.arange(x_b.shape[1]).astype(np.float) | |||
| b_st = (np.cumsum(b_mu, axis=1)-eps)/(b_vv+1) | |||
| selected = (b_mu - b_st) > 0 | |||
| rho = np.sum((np.cumsum((1-selected), axis=1) == 0), axis=1)-1 | |||
| theta = np.take_along_axis(b_st, np.expand_dims(rho, axis=1), axis=1) | |||
| proj_x_b = np.maximum(0, np.abs(x_b)-theta)*np.sign(x_b) | |||
| # gather all the projected batch | |||
| proj_x = np.copy(values) | |||
| proj_x[indexes_b] = proj_x_b | |||
| return proj_x | |||
| def _projection(values, eps, norm_level): | |||
| """ | |||
| Implementation of values normalization within eps. | |||
| Args: | |||
| values (numpy.ndarray): Input data. | |||
| eps (float): Project radius. | |||
| norm_level (Union[int, char, numpy.inf]): Order of the norm. Possible | |||
| values: np.inf, 1 or 2. | |||
| Returns: | |||
| numpy.ndarray, normalized values. | |||
| Raises: | |||
| NotImplementedError: If the norm_level is not in [1, 2, np.inf, '1', | |||
| '2', 'inf']. | |||
| """ | |||
| if norm_level in (1, '1'): | |||
| sample_batch = values.shape[0] | |||
| x_flat = values.reshape(sample_batch, -1) | |||
| proj_flat = _reshape_l1_projection(x_flat, eps) | |||
| return proj_flat.reshape(values.shape) | |||
| if norm_level in (2, '2'): | |||
| return eps*normalize_value(values, norm_level) | |||
| if norm_level in (np.inf, 'inf'): | |||
| return eps*np.sign(values) | |||
| msg = 'Values of `norm_level` different from 1, 2 and `np.inf` are ' \ | |||
| 'currently not supported.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| class IterativeGradientMethod(Attack): | |||
| """ | |||
| Abstract base class for all iterative gradient based attacks. | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of adversarial perturbation generated by the | |||
| attack to data range. Default: 0.3. | |||
| eps_iter (float): Proportion of single-step adversarial perturbation | |||
| generated by the attack to data range. Default: 0.1. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| nb_iter (int): Number of iteration. Default: 5. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| """ | |||
| def __init__(self, network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), nb_iter=5, | |||
| loss_fn=None): | |||
| super(IterativeGradientMethod, self).__init__() | |||
| self._network = check_model('network', network, Cell) | |||
| self._eps = check_value_positive('eps', eps) | |||
| self._eps_iter = check_value_positive('eps_iter', eps_iter) | |||
| self._nb_iter = check_int_positive('nb_iter', nb_iter) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [list, tuple]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| if loss_fn is None: | |||
| loss_fn = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| self._loss_grad = GradWrapWithLoss(WithLossCell(self._network, loss_fn)) | |||
| self._loss_grad.set_train() | |||
| @abstractmethod | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input samples and original/target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to create | |||
| adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Raises: | |||
| NotImplementedError: This function is not available in | |||
| IterativeGradientMethod. | |||
| Examples: | |||
| >>> adv_x = attack.generate([[0.1, 0.9, 0.6], | |||
| >>> [0.3, 0, 0.3]], | |||
| >>> [[0, , 1, 0, 0, 0, 0, 0, 0, 0], | |||
| >>> [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0]]) | |||
| """ | |||
| msg = 'The function generate() is an abstract method in class ' \ | |||
| '`IterativeGradientMethod`, and should be implemented ' \ | |||
| 'in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| class BasicIterativeMethod(IterativeGradientMethod): | |||
| """ | |||
| The Basic Iterative Method attack, an iterative FGSM method to generate | |||
| adversarial examples. | |||
| References: `A. Kurakin, I. Goodfellow, and S. Bengio, "Adversarial examples | |||
| in the physical world," in ICLR, 2017 <https://arxiv.org/abs/1607.02533>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of adversarial perturbation generated by the | |||
| attack to data range. Default: 0.3. | |||
| eps_iter (float): Proportion of single-step adversarial perturbation | |||
| generated by the attack to data range. Default: 0.1. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| nb_iter (int): Number of iteration. Default: 5. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| attack (class): The single step gradient method of each iteration. In | |||
| this class, FGSM is used. | |||
| Examples: | |||
| >>> attack = BasicIterativeMethod(network) | |||
| """ | |||
| def __init__(self, network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), | |||
| is_targeted=False, nb_iter=5, loss_fn=None): | |||
| super(BasicIterativeMethod, self).__init__(network, | |||
| eps=eps, | |||
| eps_iter=eps_iter, | |||
| bounds=bounds, | |||
| nb_iter=nb_iter, | |||
| loss_fn=loss_fn) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| self._attack = FastGradientSignMethod(self._network, | |||
| eps=self._eps_iter, | |||
| bounds=self._bounds, | |||
| is_targeted=self._is_targeted, | |||
| loss_fn=loss_fn) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Simple iterative FGSM method to generate adversarial examples. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to | |||
| create adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples. | |||
| Examples: | |||
| >>> adv_x = attack.generate([[0.3, 0.2, 0.6], | |||
| >>> [0.3, 0.2, 0.4]], | |||
| >>> [[0, 0, 1, 0, 0, 0, 0, 0, 0, 0], | |||
| >>> [0, 0, 0, 0, 0, 0, 1, 0, 0, 0]]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| arr_x = inputs | |||
| if self._bounds is not None: | |||
| clip_min, clip_max = self._bounds | |||
| clip_diff = clip_max - clip_min | |||
| for _ in range(self._nb_iter): | |||
| adv_x = self._attack.generate(inputs, labels) | |||
| perturs = np.clip(adv_x - arr_x, (0 - self._eps)*clip_diff, | |||
| self._eps*clip_diff) | |||
| adv_x = arr_x + perturs | |||
| inputs = adv_x | |||
| else: | |||
| for _ in range(self._nb_iter): | |||
| adv_x = self._attack.generate(inputs, labels) | |||
| adv_x = np.clip(adv_x, arr_x - self._eps, arr_x + self._eps) | |||
| inputs = adv_x | |||
| return adv_x | |||
| class MomentumIterativeMethod(IterativeGradientMethod): | |||
| """ | |||
| The Momentum Iterative Method attack. | |||
| References: `Y. Dong, et al., "Boosting adversarial attacks with | |||
| momentum," arXiv:1710.06081, 2017 <https://arxiv.org/abs/1710.06081>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of adversarial perturbation generated by the | |||
| attack to data range. Default: 0.3. | |||
| eps_iter (float): Proportion of single-step adversarial perturbation | |||
| generated by the attack to data range. Default: 0.1. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| nb_iter (int): Number of iteration. Default: 5. | |||
| decay_factor (float): Decay factor in iterations. Default: 1.0. | |||
| norm_level (Union[int, numpy.inf]): Order of the norm. Possible values: | |||
| np.inf, 1 or 2. Default: 'inf'. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| """ | |||
| def __init__(self, network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), | |||
| is_targeted=False, nb_iter=5, decay_factor=1.0, | |||
| norm_level='inf', loss_fn=None): | |||
| super(MomentumIterativeMethod, self).__init__(network, | |||
| eps=eps, | |||
| eps_iter=eps_iter, | |||
| bounds=bounds, | |||
| nb_iter=nb_iter, | |||
| loss_fn=loss_fn) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| self._decay_factor = check_value_positive('decay_factor', decay_factor) | |||
| self._norm_level = check_norm_level(norm_level) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input data and origin/target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to | |||
| create adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples. | |||
| Examples: | |||
| >>> adv_x = attack.generate([[0.5, 0.2, 0.6], | |||
| >>> [0.3, 0, 0.2]], | |||
| >>> [[0, 0, 0, 0, 0, 0, 0, 0, 1, 0], | |||
| >>> [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| arr_x = inputs | |||
| momentum = 0 | |||
| if self._bounds is not None: | |||
| clip_min, clip_max = self._bounds | |||
| clip_diff = clip_max - clip_min | |||
| for _ in range(self._nb_iter): | |||
| gradient = self._gradient(inputs, labels) | |||
| momentum = self._decay_factor*momentum + gradient | |||
| adv_x = inputs + self._eps_iter*np.sign(momentum) | |||
| perturs = np.clip(adv_x - arr_x, (0 - self._eps)*clip_diff, | |||
| self._eps*clip_diff) | |||
| adv_x = arr_x + perturs | |||
| adv_x = np.clip(adv_x, clip_min, clip_max) | |||
| inputs = adv_x | |||
| else: | |||
| for _ in range(self._nb_iter): | |||
| gradient = self._gradient(inputs, labels) | |||
| momentum = self._decay_factor*momentum + gradient | |||
| adv_x = inputs + self._eps_iter*np.sign(momentum) | |||
| adv_x = np.clip(adv_x, arr_x - self._eps, arr_x + self._eps) | |||
| inputs = adv_x | |||
| return adv_x | |||
| def _gradient(self, inputs, labels): | |||
| """ | |||
| Calculate the gradient of input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, gradient of labels w.r.t inputs. | |||
| Examples: | |||
| >>> grad = self._gradient([[0.5, 0.3, 0.4]], | |||
| >>> [[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]) | |||
| """ | |||
| sens = Tensor(np.array([1.0], inputs.dtype)) | |||
| # get grad of loss over x | |||
| out_grad = self._loss_grad(Tensor(inputs), Tensor(labels), sens) | |||
| if isinstance(out_grad, tuple): | |||
| out_grad = out_grad[0] | |||
| gradient = out_grad.asnumpy() | |||
| if self._is_targeted: | |||
| gradient = -gradient | |||
| return normalize_value(gradient, self._norm_level) | |||
| class ProjectedGradientDescent(BasicIterativeMethod): | |||
| """ | |||
| The Projected Gradient Descent attack is a variant of the Basic Iterative | |||
| Method in which, after each iteration, the perturbation is projected on an | |||
| lp-ball of specified radius (in addition to clipping the values of the | |||
| adversarial sample so that it lies in the permitted data range). This is | |||
| the attack proposed by Madry et al. for adversarial training. | |||
| References: `A. Madry, et al., "Towards deep learning models resistant to | |||
| adversarial attacks," in ICLR, 2018 <https://arxiv.org/abs/1706.06083>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| eps (float): Proportion of adversarial perturbation generated by the | |||
| attack to data range. Default: 0.3. | |||
| eps_iter (float): Proportion of single-step adversarial perturbation | |||
| generated by the attack to data range. Default: 0.1. | |||
| bounds (tuple): Upper and lower bounds of data, indicating the data range. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: False. | |||
| nb_iter (int): Number of iteration. Default: 5. | |||
| norm_level (Union[int, numpy.inf]): Order of the norm. Possible values: | |||
| np.inf, 1 or 2. Default: 'inf'. | |||
| loss_fn (Loss): Loss function for optimization. | |||
| """ | |||
| def __init__(self, network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), | |||
| is_targeted=False, nb_iter=5, norm_level='inf', loss_fn=None): | |||
| super(ProjectedGradientDescent, self).__init__(network, | |||
| eps=eps, | |||
| eps_iter=eps_iter, | |||
| bounds=bounds, | |||
| is_targeted=is_targeted, | |||
| nb_iter=nb_iter, | |||
| loss_fn=loss_fn) | |||
| self._norm_level = check_norm_level(norm_level) | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Iteratively generate adversarial examples based on BIM method. The | |||
| perturbation is normalized by projected method with parameter norm_level . | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to | |||
| create adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples. | |||
| Examples: | |||
| >>> adv_x = attack.generate([[0.6, 0.2, 0.6], | |||
| >>> [0.3, 0.3, 0.4]], | |||
| >>> [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1], | |||
| >>> [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| arr_x = inputs | |||
| if self._bounds is not None: | |||
| clip_min, clip_max = self._bounds | |||
| clip_diff = clip_max - clip_min | |||
| for _ in range(self._nb_iter): | |||
| adv_x = self._attack.generate(inputs, labels) | |||
| perturs = _projection(adv_x - arr_x, | |||
| self._eps, | |||
| norm_level=self._norm_level) | |||
| perturs = np.clip(perturs, (0 - self._eps)*clip_diff, | |||
| self._eps*clip_diff) | |||
| adv_x = arr_x + perturs | |||
| inputs = adv_x | |||
| else: | |||
| for _ in range(self._nb_iter): | |||
| adv_x = self._attack.generate(inputs, labels) | |||
| perturs = _projection(adv_x - arr_x, | |||
| self._eps, | |||
| norm_level=self._norm_level) | |||
| adv_x = arr_x + perturs | |||
| adv_x = np.clip(adv_x, arr_x - self._eps, arr_x + self._eps) | |||
| inputs = adv_x | |||
| return adv_x | |||
+ 196
- 0
mindarmour/attacks/jsma.py
View File
| @@ -0,0 +1,196 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| JSMA-Attack. | |||
| """ | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.util import GradWrap | |||
| from mindarmour.utils.util import jacobian_matrix | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| check_param_type, check_int_positive, check_value_positive, \ | |||
| check_value_non_negative | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'JSMA' | |||
| class JSMAAttack(Attack): | |||
| """ | |||
| JSMA is an targeted & iterative attack based on saliency map of | |||
| input features. | |||
| Reference: `The limitations of deep learning in adversarial settings | |||
| <https://arxiv.org/abs/1511.07528>`_ | |||
| Args: | |||
| network (Cell): Target model. | |||
| num_classes (int): Number of labels of model output, which should be | |||
| greater than zero. | |||
| box_min (float): Lower bound of input of the target model. Default: 0. | |||
| box_max (float): Upper bound of input of the target model. Default: 1.0. | |||
| theta (float): Change ratio of one pixel (relative to | |||
| input data range). Default: 1.0. | |||
| max_iteration (int): Maximum round of iteration. Default: 100. | |||
| max_count (int): Maximum times to change each pixel. Default: 3. | |||
| increase (bool): If True, increase perturbation. If False, decrease | |||
| perturbation. Default: True. | |||
| sparse (bool): If True, input labels are sparse-coded. If False, | |||
| input labels are onehot-coded. Default: True. | |||
| Examples: | |||
| >>> attack = JSMAAttack(network) | |||
| """ | |||
| def __init__(self, network, num_classes, box_min=0.0, box_max=1.0, | |||
| theta=1.0, max_iteration=1000, max_count=3, increase=True, | |||
| sparse=True): | |||
| super(JSMAAttack).__init__() | |||
| LOGGER.debug(TAG, "init jsma class.") | |||
| self._network = check_model('network', network, Cell) | |||
| self._min = check_value_non_negative('box_min', box_min) | |||
| self._max = check_value_non_negative('box_max', box_max) | |||
| self._num_classes = check_int_positive('num_classes', num_classes) | |||
| self._theta = check_value_positive('theta', theta) | |||
| self._max_iter = check_int_positive('max_iteration', max_iteration) | |||
| self._max_count = check_int_positive('max_count', max_count) | |||
| self._increase = check_param_type('increase', increase, bool) | |||
| self._net_grad = GradWrap(self._network) | |||
| self._bit_map = None | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| def _saliency_map(self, data, bit_map, target): | |||
| """ | |||
| Compute the saliency map of all pixels. | |||
| Args: | |||
| data (numpy.ndarray): Input sample. | |||
| bit_map (numpy.ndarray): Bit map to control modify frequency of | |||
| each pixel. | |||
| target (int): Target class. | |||
| Returns: | |||
| tuple, indices of selected pixel to modify. | |||
| Examples: | |||
| >>> p1_ind, p2_ind = self._saliency_map([0.2, 0.3, 0.5], | |||
| >>> [1, 0, 1], 1) | |||
| """ | |||
| jaco_grad = jacobian_matrix(self._net_grad, data, self._num_classes) | |||
| jaco_grad = jaco_grad.reshape(self._num_classes, -1) | |||
| alpha = jaco_grad[target]*bit_map | |||
| alpha_trans = np.reshape(alpha, (alpha.shape[0], 1)) | |||
| alpha_two_dim = alpha + alpha_trans | |||
| # pixel influence on other classes except target class | |||
| other_grads = [jaco_grad[class_ind] for class_ind in range( | |||
| self._num_classes)] | |||
| beta = np.sum(other_grads, axis=0)*bit_map - alpha | |||
| beta_trans = np.reshape(beta, (beta.shape[0], 1)) | |||
| beta_two_dim = beta + beta_trans | |||
| if self._increase: | |||
| alpha_two_dim = (alpha_two_dim > 0)*alpha_two_dim | |||
| beta_two_dim = (beta_two_dim < 0)*beta_two_dim | |||
| else: | |||
| alpha_two_dim = (alpha_two_dim < 0)*alpha_two_dim | |||
| beta_two_dim = (beta_two_dim > 0)*beta_two_dim | |||
| sal_map = (-1*alpha_two_dim*beta_two_dim) | |||
| two_dim_index = np.argmax(sal_map) | |||
| p1_ind = two_dim_index % len(data.flatten()) | |||
| p2_ind = two_dim_index // len(data.flatten()) | |||
| return p1_ind, p2_ind | |||
| def _generate_one(self, data, target): | |||
| """ | |||
| Generate one adversarial example. | |||
| Args: | |||
| data (numpy.ndarray): Input sample (only one). | |||
| target (int): Target label. | |||
| Returns: | |||
| numpy.ndarray, adversarial example or zeros (if failed). | |||
| Examples: | |||
| >>> adv = self._generate_one([0.2, 0.3 ,0.4], 1) | |||
| """ | |||
| ori_shape = data.shape | |||
| temp = data.flatten() | |||
| bit_map = np.ones_like(temp) | |||
| fake_res = np.zeros_like(data) | |||
| counter = np.zeros_like(temp) | |||
| perturbed = np.copy(temp) | |||
| for _ in range(self._max_iter): | |||
| pre_logits = self._network(Tensor(np.expand_dims( | |||
| perturbed.reshape(ori_shape), axis=0))) | |||
| per_pred = np.argmax(pre_logits.asnumpy()) | |||
| if per_pred == target: | |||
| LOGGER.debug(TAG, 'find one adversarial sample successfully.') | |||
| return perturbed.reshape(ori_shape) | |||
| if np.all(bit_map == 0): | |||
| LOGGER.debug(TAG, 'fail to find adversarial sample') | |||
| return perturbed.reshape(ori_shape) | |||
| p1_ind, p2_ind = self._saliency_map(perturbed.reshape( | |||
| ori_shape)[np.newaxis, :], bit_map, target) | |||
| if self._increase: | |||
| perturbed[p1_ind] += self._theta*(self._max - self._min) | |||
| perturbed[p2_ind] += self._theta*(self._max - self._min) | |||
| else: | |||
| perturbed[p1_ind] -= self._theta*(self._max - self._min) | |||
| perturbed[p2_ind] -= self._theta*(self._max - self._min) | |||
| counter[p1_ind] += 1 | |||
| counter[p2_ind] += 1 | |||
| if (perturbed[p1_ind] >= self._max) or ( | |||
| perturbed[p1_ind] <= self._min) \ | |||
| or (counter[p1_ind] > self._max_count): | |||
| bit_map[p1_ind] = 0 | |||
| if (perturbed[p2_ind] >= self._max) or ( | |||
| perturbed[p2_ind] <= self._min) \ | |||
| or (counter[p2_ind] > self._max_count): | |||
| bit_map[p2_ind] = 0 | |||
| perturbed = np.clip(perturbed, self._min, self._max) | |||
| LOGGER.debug(TAG, 'fail to find adversarial sample.') | |||
| return fake_res | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples in batch. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Target labels. | |||
| Returns: | |||
| numpy.ndarray, adversarial samples. | |||
| Examples: | |||
| >>> advs = generate([[0.2, 0.3, 0.4], [0.3, 0.4, 0.5]], [1, 2]) | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| LOGGER.debug(TAG, 'start to generate adversarial samples.') | |||
| res = [] | |||
| for i in range(inputs.shape[0]): | |||
| res.append(self._generate_one(inputs[i], labels[i])) | |||
| LOGGER.debug(TAG, 'finished.') | |||
| return np.asarray(res) | |||
+ 224
- 0
mindarmour/attacks/lbfgs.py
View File
| @@ -0,0 +1,224 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| LBFGS-Attack. | |||
| """ | |||
| import numpy as np | |||
| import scipy.optimize as so | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.attacks.attack import Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils.util import WithLossCell | |||
| from mindarmour.utils.util import GradWrapWithLoss | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| check_int_positive, check_value_positive, check_param_type, \ | |||
| check_param_multi_types | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'LBFGS' | |||
| class LBFGS(Attack): | |||
| """ | |||
| Uses L-BFGS-B to minimize the distance between the input and the adversarial example. | |||
| References: `Pedro Tabacof, Eduardo Valle. "Exploring the Space of | |||
| Adversarial Images" <https://arxiv.org/abs/1510.05328>`_ | |||
| Args: | |||
| network (Cell): The network of attacked model. | |||
| eps (float): Attack step size. Default: 1e-5. | |||
| bounds (tuple): Upper and lower bounds of data. Default: (0.0, 1.0) | |||
| is_targeted (bool): If True, targeted attack. If False, untargeted | |||
| attack. Default: True. | |||
| nb_iter (int): Number of iteration of lbfgs-optimizer, which should be | |||
| greater than zero. Default: 150. | |||
| search_iters (int): Number of changes in step size, which should be | |||
| greater than zero. Default: 30. | |||
| loss_fn (Functions): Loss function of substitute model. Default: None. | |||
| sparse (bool): If True, input labels are sparse-coded. If False, | |||
| input labels are onehot-coded. Default: False. | |||
| Examples: | |||
| >>> attack = LBFGS(network) | |||
| """ | |||
| def __init__(self, network, eps=1e-5, bounds=(0.0, 1.0), is_targeted=True, | |||
| nb_iter=150, search_iters=30, loss_fn=None, sparse=False): | |||
| super(LBFGS, self).__init__() | |||
| self._network = check_model('network', network, Cell) | |||
| self._eps = check_value_positive('eps', eps) | |||
| self._is_targeted = check_param_type('is_targeted', is_targeted, bool) | |||
| self._nb_iter = check_int_positive('nb_iter', nb_iter) | |||
| self._search_iters = check_int_positive('search_iters', search_iters) | |||
| if loss_fn is None: | |||
| loss_fn = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| with_loss_cell = WithLossCell(self._network, loss_fn) | |||
| self._grad_all = GradWrapWithLoss(with_loss_cell) | |||
| self._dtype = None | |||
| self._bounds = check_param_multi_types('bounds', bounds, [list, tuple]) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| box_max, box_min = bounds | |||
| if box_max < box_min: | |||
| self._box_min = box_max | |||
| self._box_max = box_min | |||
| else: | |||
| self._box_min = box_min | |||
| self._box_max = box_max | |||
| def generate(self, inputs, labels): | |||
| """ | |||
| Generate adversarial examples based on input data and target labels. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign input samples used as references to create | |||
| adversarial examples. | |||
| labels (numpy.ndarray): Original/target labels. | |||
| Returns: | |||
| numpy.ndarray, generated adversarial examples. | |||
| Examples: | |||
| >>> adv = attack.generate([[0.1, 0.2, 0.6], [0.3, 0, 0.4]], [2, 2]) | |||
| """ | |||
| LOGGER.debug(TAG, 'start to generate adv image.') | |||
| arr_x, arr_y = check_pair_numpy_param('inputs', inputs, 'labels', labels) | |||
| self._dtype = arr_x.dtype | |||
| adv_list = list() | |||
| for original_x, label_y in zip(arr_x, arr_y): | |||
| adv_list.append(self._optimize( | |||
| original_x, label_y, epsilon=self._eps)) | |||
| return np.array(adv_list) | |||
| def _forward_one(self, cur_input): | |||
| """Forward one sample in model.""" | |||
| cur_input = np.expand_dims(cur_input, axis=0) | |||
| out_logits = self._network(Tensor(cur_input)).asnumpy() | |||
| return out_logits | |||
| def _gradient(self, cur_input, labels, shape): | |||
| """ Return model gradient to minimize loss in l-bfgs-b.""" | |||
| label_dtype = labels.dtype | |||
| sens = Tensor(np.array([1], self._dtype)) | |||
| labels = np.expand_dims(labels, axis=0).astype(label_dtype) | |||
| # input shape should like original shape | |||
| reshape_input = np.expand_dims(cur_input.reshape(shape), | |||
| axis=0) | |||
| out_grad = self._grad_all(Tensor(reshape_input), Tensor(labels), sens) | |||
| if isinstance(out_grad, tuple): | |||
| out_grad = out_grad[0] | |||
| return out_grad.asnumpy() | |||
| def _loss(self, cur_input, start_input, cur_eps, shape, labels): | |||
| """ | |||
| The l-bfgs-b loss used is Mean Square Error distance from original | |||
| input plus crossentropy loss. | |||
| """ | |||
| cur_input = cur_input.astype(self._dtype) | |||
| mse_distance = np.mean(np.square(start_input - cur_input)) / \ | |||
| ((self._box_max - self._box_min)**2) | |||
| logits = self._forward_one(cur_input.reshape(shape)).flatten() | |||
| logits = logits - np.max(logits) | |||
| if self._sparse: | |||
| target_class = labels | |||
| else: | |||
| target_class = np.argmax(labels) | |||
| if self._is_targeted: | |||
| crossentropy = np.log(np.sum(np.exp(logits))) - logits[target_class] | |||
| gradient = self._gradient(cur_input, labels, shape).flatten() | |||
| else: | |||
| crossentropy = logits[target_class] - np.log(np.sum(np.exp(logits))) | |||
| gradient = -self._gradient(cur_input, labels, shape).flatten() | |||
| return (mse_distance + cur_eps*crossentropy).astype(self._dtype), \ | |||
| gradient.astype(np.float64) | |||
| def _lbfgsb(self, start_input, cur_eps, shape, labels, bounds): | |||
| """ | |||
| A wrapper. | |||
| Method reference to `scipy.optimize.fmin_l_bfgs_b`_ | |||
| .. _`scipy.optimize.fmin_l_bfgs_b`: https://docs.scipy.org/doc/scipy/ | |||
| reference/generated/scipy.optimize.fmin_l_bfgs_b.html | |||
| """ | |||
| approx_grad_eps = (self._box_max - self._box_min) / 100 | |||
| max_matrix_variable = 15 | |||
| cur_input, _, detail_info = so.fmin_l_bfgs_b( | |||
| self._loss, | |||
| start_input, | |||
| args=(start_input, cur_eps, shape, labels), | |||
| approx_grad=False, | |||
| bounds=bounds, | |||
| m=max_matrix_variable, | |||
| maxiter=self._nb_iter, | |||
| epsilon=approx_grad_eps) | |||
| LOGGER.debug(TAG, str(detail_info)) | |||
| # LBFGS-B does not always exactly respect the boundaries | |||
| if np.amax(cur_input) > self._box_max or np.amin( | |||
| cur_input) < self._box_min: # pragma: no coverage | |||
| LOGGER.debug(TAG, | |||
| 'Input out of bounds (min, max = %s, %s).' | |||
| ' Performing manual clip.', | |||
| np.amin(cur_input), | |||
| np.amax(cur_input)) | |||
| cur_input = np.clip(cur_input, self._box_min, self._box_max) | |||
| cur_input = cur_input.astype(self._dtype) | |||
| cur_input = cur_input.reshape(shape) | |||
| adv_prediction = self._forward_one(cur_input) | |||
| LOGGER.debug(TAG, 'input one sample label is :{}'.format(labels)) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels) | |||
| if self._is_targeted: | |||
| return cur_input, np.argmax(adv_prediction) == labels | |||
| return cur_input, np.argmax(adv_prediction) != labels | |||
| def _optimize(self, start_input, labels, epsilon): | |||
| """ | |||
| Given loss fuction and gradient, use l_bfgs_b algorithm to update input | |||
| sample. The epsilon will be doubled until an adversarial example is found. | |||
| Args: | |||
| start_input (numpy.ndarray): Benign input samples used as references | |||
| to create adversarial examples. | |||
| labels (numpy.ndarray): Target labels. | |||
| epsilon: (float): Attack step size. | |||
| max_iter (int): Number of iteration. | |||
| """ | |||
| # store the shape for later and operate on the flattened input | |||
| ori_shape = start_input.shape | |||
| start_input = start_input.flatten().astype(self._dtype) | |||
| bounds = [self._bounds]*len(start_input) | |||
| # finding initial cur_eps | |||
| iter_c = epsilon | |||
| for _ in range(self._search_iters): | |||
| iter_c = 2*iter_c | |||
| generate_x, is_adversarial = self._lbfgsb(start_input, | |||
| iter_c, | |||
| ori_shape, | |||
| labels, | |||
| bounds) | |||
| LOGGER.debug(TAG, 'Tested iter_c = %f', iter_c) | |||
| if is_adversarial: | |||
| LOGGER.debug(TAG, 'find adversarial successfully.') | |||
| return generate_x | |||
| LOGGER.debug(TAG, 'failed to not adversarial.') | |||
| return generate_x | |||
+ 15
- 0
mindarmour/defenses/__init__.py
View File
| @@ -0,0 +1,15 @@ | |||
| """ | |||
| This module includes classical defense algorithms in defencing adversarial | |||
| examples and enhancing model security and trustworthy. | |||
| """ | |||
| from .adversarial_defense import AdversarialDefense | |||
| from .adversarial_defense import AdversarialDefenseWithAttacks | |||
| from .adversarial_defense import EnsembleAdversarialDefense | |||
| from .natural_adversarial_defense import NaturalAdversarialDefense | |||
| from .projected_adversarial_defense import ProjectedAdversarialDefense | |||
| __all__ = ['AdversarialDefense', | |||
| 'AdversarialDefenseWithAttacks', | |||
| 'NaturalAdversarialDefense', | |||
| 'ProjectedAdversarialDefense', | |||
| 'EnsembleAdversarialDefense'] | |||
+ 169
- 0
mindarmour/defenses/adversarial_defense.py
View File
| @@ -0,0 +1,169 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Adversarial Defense. | |||
| """ | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.nn import WithLossCell, TrainOneStepCell | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, check_model, \ | |||
| check_param_in_range, check_param_type, check_param_multi_types | |||
| from mindarmour.defenses.defense import Defense | |||
| class AdversarialDefense(Defense): | |||
| """ | |||
| Adversarial training using given adversarial examples. | |||
| Args: | |||
| network (Cell): A MindSpore network to be defensed. | |||
| loss_fn (Functions): Loss function. Default: None. | |||
| optimizer (Cell): Optimizer used to train the network. Default: None. | |||
| Examples: | |||
| >>> class Net(Cell): | |||
| >>> def __init__(self): | |||
| >>> super(Net, self).__init__() | |||
| >>> self._reshape = P.Reshape() | |||
| >>> self._full_con_1 = Dense(28*28, 120) | |||
| >>> self._full_con_2 = Dense(120, 84) | |||
| >>> self._full_con_3 = Dense(84, 10) | |||
| >>> self._relu = ReLU() | |||
| >>> | |||
| >>> def construct(self, x): | |||
| >>> out = self._reshape(x, (-1, 28*28)) | |||
| >>> out = self._full_con_1(out) | |||
| >>> out = self.relu(out) | |||
| >>> out = self._full_con_2(out) | |||
| >>> out = self.relu(out) | |||
| >>> out = self._full_con_3(out) | |||
| >>> return out | |||
| >>> | |||
| >>> net = Net() | |||
| >>> lr = 0.0001 | |||
| >>> momentum = 0.9 | |||
| >>> loss_fn = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=True) | |||
| >>> optimizer = Momentum(net.trainable_params(), lr, momentum) | |||
| >>> adv_defense = AdversarialDefense(net, loss_fn, optimizer) | |||
| >>> inputs = np.random.rand(32, 1, 28, 28).astype(np.float32) | |||
| >>> labels = np.random.randint(0, 10).astype(np.int32) | |||
| >>> adv_defense.defense(inputs, labels) | |||
| """ | |||
| def __init__(self, network, loss_fn=None, optimizer=None): | |||
| super(AdversarialDefense, self).__init__(network) | |||
| network = check_model('network', network, Cell) | |||
| if loss_fn is None: | |||
| loss_fn = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=True) | |||
| if optimizer is None: | |||
| optimizer = Momentum( | |||
| params=network.trainable_params(), | |||
| learning_rate=0.01, | |||
| momentum=0.9) | |||
| loss_net = WithLossCell(network, loss_fn) | |||
| self._train_net = TrainOneStepCell(loss_net, optimizer) | |||
| self._train_net.set_train() | |||
| def defense(self, inputs, labels): | |||
| """ | |||
| Enhance model via training with input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Labels of input samples. | |||
| Returns: | |||
| numpy.ndarray, loss of defense operation. | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, 'labels', | |||
| labels) | |||
| loss = self._train_net(Tensor(inputs), Tensor(labels)) | |||
| return loss.asnumpy() | |||
| class AdversarialDefenseWithAttacks(AdversarialDefense): | |||
| """ | |||
| Adversarial defense with attacks. | |||
| Args: | |||
| network (Cell): A MindSpore network to be defensed. | |||
| attacks (list[Attack]): List of attack method. | |||
| loss_fn (Functions): Loss function. Default: None. | |||
| optimizer (Cell): Optimizer used to train the network. Default: None. | |||
| bounds (tuple): Upper and lower bounds of data. In form of (clip_min, | |||
| clip_max). Default: (0.0, 1.0). | |||
| replace_ratio (float): Ratio of replacing original samples with | |||
| adversarial, which must be between 0 and 1. Default: 0.5. | |||
| Raises: | |||
| ValueError: If replace_ratio is not between 0 and 1. | |||
| Examples: | |||
| >>> net = Net() | |||
| >>> fgsm = FastGradientSignMethod(net) | |||
| >>> pgd = ProjectedGradientDescent(net) | |||
| >>> ead = AdversarialDefenseWithAttacks(net, [fgsm, pgd]) | |||
| >>> ead.defense(inputs, labels) | |||
| """ | |||
| def __init__(self, network, attacks, loss_fn=None, optimizer=None, | |||
| bounds=(0.0, 1.0), replace_ratio=0.5): | |||
| super(AdversarialDefenseWithAttacks, self).__init__(network, | |||
| loss_fn, | |||
| optimizer) | |||
| self._attacks = check_param_type('attacks', attacks, list) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [tuple, list]) | |||
| for elem in self._bounds: | |||
| _ = check_param_multi_types('bound', elem, [int, float]) | |||
| self._replace_ratio = check_param_in_range('replace_ratio', | |||
| replace_ratio, | |||
| 0, 1) | |||
| def defense(self, inputs, labels): | |||
| """ | |||
| Enhance model via training with adversarial examples generated from input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Labels of input samples. | |||
| Returns: | |||
| numpy.ndarray, loss of adversarial defense operation. | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, 'labels', | |||
| labels) | |||
| x_len = inputs.shape[0] | |||
| n_adv = int(np.ceil(self._replace_ratio*x_len)) | |||
| n_adv_per_attack = int(n_adv / len(self._attacks)) | |||
| adv_ids = np.random.choice(x_len, size=n_adv, replace=False) | |||
| start = 0 | |||
| for attack in self._attacks: | |||
| idx = adv_ids[start:start + n_adv_per_attack] | |||
| inputs[idx] = attack.generate(inputs[idx], labels[idx]) | |||
| start += n_adv_per_attack | |||
| loss = self._train_net(Tensor(inputs), Tensor(labels)) | |||
| return loss.asnumpy() | |||
| EnsembleAdversarialDefense = AdversarialDefenseWithAttacks | |||
+ 86
- 0
mindarmour/defenses/defense.py
View File
| @@ -0,0 +1,86 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Base Class of Defense. | |||
| """ | |||
| from abc import abstractmethod | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, \ | |||
| check_int_positive | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Defense' | |||
| class Defense: | |||
| """ | |||
| The abstract base class for all defense classes defending adversarial | |||
| examples. | |||
| Args: | |||
| network (Cell): A MindSpore-style deep learning model to be defensed. | |||
| """ | |||
| def __init__(self, network): | |||
| self._network = network | |||
| @abstractmethod | |||
| def defense(self, inputs, labels): | |||
| """ | |||
| Defense model with samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Samples based on which adversarial | |||
| examples are generated. | |||
| labels (numpy.ndarray): Labels of input samples. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function defense() is an abstract function in class ' \ | |||
| '`Defense` and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| def batch_defense(self, inputs, labels, batch_size=32, epochs=5): | |||
| """ | |||
| Defense model with samples in batch. | |||
| Args: | |||
| inputs (numpy.ndarray): Samples based on which adversarial | |||
| examples are generated. | |||
| labels (numpy.ndarray): Labels of input samples. | |||
| batch_size (int): Number of samples in one batch. | |||
| epochs (int): Number of epochs. | |||
| Returns: | |||
| numpy.ndarray, loss of batch_defense operation. | |||
| Raises: | |||
| ValueError: If batch_size is 0. | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, 'labels', | |||
| labels) | |||
| x_len = len(inputs) | |||
| batch_size = check_int_positive('batch_size', batch_size) | |||
| iters_per_epoch = int(x_len / batch_size) | |||
| loss = None | |||
| for _ in range(epochs): | |||
| for step in range(iters_per_epoch): | |||
| x_batch = inputs[step*batch_size:(step + 1)*batch_size] | |||
| y_batch = labels[step*batch_size:(step + 1)*batch_size] | |||
| loss = self.defense(x_batch, y_batch) | |||
| return loss | |||
+ 56
- 0
mindarmour/defenses/natural_adversarial_defense.py
View File
| @@ -0,0 +1,56 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Natural Adversarial Defense. | |||
| """ | |||
| from mindarmour.defenses.adversarial_defense import \ | |||
| AdversarialDefenseWithAttacks | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| class NaturalAdversarialDefense(AdversarialDefenseWithAttacks): | |||
| """ | |||
| Adversarial training based on FGSM. | |||
| Reference: `A. Kurakin, et al., "Adversarial machine learning at scale," in | |||
| ICLR, 2017. <https://arxiv.org/abs/1611.01236>`_ | |||
| Args: | |||
| network (Cell): A MindSpore network to be defensed. | |||
| loss_fn (Functions): Loss function. Default: None. | |||
| optimizer (Cell): Optimizer used to train the network. Default: None. | |||
| bounds (tuple): Upper and lower bounds of data. In form of (clip_min, | |||
| clip_max). Default: (0.0, 1.0). | |||
| replace_ratio (float): Ratio of replacing original samples with | |||
| adversarial samples. Default: 0.5. | |||
| eps (float): Step size of the attack method(FGSM). Default: 0.1. | |||
| Examples: | |||
| >>> net = Net() | |||
| >>> adv_defense = NaturalAdversarialDefense(net) | |||
| >>> adv_defense.defense(inputs, labels) | |||
| """ | |||
| def __init__(self, network, loss_fn=None, optimizer=None, | |||
| bounds=(0.0, 1.0), replace_ratio=0.5, eps=0.1): | |||
| attack = FastGradientSignMethod(network, | |||
| eps=eps, | |||
| alpha=None, | |||
| bounds=bounds) | |||
| super(NaturalAdversarialDefense, self).__init__( | |||
| network, | |||
| [attack], | |||
| loss_fn=loss_fn, | |||
| optimizer=optimizer, | |||
| bounds=bounds, | |||
| replace_ratio=replace_ratio) | |||
+ 69
- 0
mindarmour/defenses/projected_adversarial_defense.py
View File
| @@ -0,0 +1,69 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Projected Adversarial Defense. | |||
| """ | |||
| from mindarmour.defenses.adversarial_defense import \ | |||
| AdversarialDefenseWithAttacks | |||
| from mindarmour.attacks.iterative_gradient_method import \ | |||
| ProjectedGradientDescent | |||
| class ProjectedAdversarialDefense(AdversarialDefenseWithAttacks): | |||
| """ | |||
| Adversarial training based on PGD. | |||
| Reference: `A. Madry, et al., "Towards deep learning models resistant to | |||
| adversarial attacks," in ICLR, 2018. <https://arxiv.org/abs/1611.01236>`_ | |||
| Args: | |||
| network (Cell): A MindSpore network to be defensed. | |||
| loss_fn (Functions): Loss function. Default: None. | |||
| optimizer (Cell): Optimizer used to train the nerwork. Default: None. | |||
| bounds (tuple): Upper and lower bounds of input data. In form of | |||
| (clip_min, clip_max). Default: (0.0, 1.0). | |||
| replace_ratio (float): Ratio of replacing original samples with | |||
| adversarial samples. Default: 0.5. | |||
| eps (float): PGD attack parameters, epsilon. Default: 0.3. | |||
| eps_iter (int): PGD attack parameters, inner loop epsilon. | |||
| Default:0.1. | |||
| nb_iter (int): PGD attack parameters, number of iteration. | |||
| Default: 5. | |||
| norm_level (str): Norm type. 'inf' or 'l2'. Default: 'inf'. | |||
| Examples: | |||
| >>> net = Net() | |||
| >>> adv_defense = ProjectedAdversarialDefense(net) | |||
| >>> adv_defense.defense(inputs, labels) | |||
| """ | |||
| def __init__(self, | |||
| network, | |||
| loss_fn=None, | |||
| optimizer=None, | |||
| bounds=(0.0, 1.0), | |||
| replace_ratio=0.5, | |||
| eps=0.3, | |||
| eps_iter=0.1, | |||
| nb_iter=5, | |||
| norm_level='inf'): | |||
| attack = ProjectedGradientDescent(network, | |||
| eps=eps, | |||
| eps_iter=eps_iter, | |||
| nb_iter=nb_iter, | |||
| bounds=bounds, | |||
| norm_level=norm_level, | |||
| loss_fn=loss_fn) | |||
| super(ProjectedAdversarialDefense, self).__init__( | |||
| network, [attack], loss_fn=loss_fn, optimizer=optimizer, | |||
| bounds=bounds, replace_ratio=replace_ratio) | |||
+ 18
- 0
mindarmour/detectors/__init__.py
View File
| @@ -0,0 +1,18 @@ | |||
| """ | |||
| This module includes detector methods on distinguishing adversarial examples | |||
| from benign examples. | |||
| """ | |||
| from .mag_net import ErrorBasedDetector | |||
| from .mag_net import DivergenceBasedDetector | |||
| from .ensemble_detector import EnsembleDetector | |||
| from .region_based_detector import RegionBasedDetector | |||
| from .spatial_smoothing import SpatialSmoothing | |||
| from . import black | |||
| from .black.similarity_detector import SimilarityDetector | |||
| __all__ = ['ErrorBasedDetector', | |||
| 'DivergenceBasedDetector', | |||
| 'RegionBasedDetector', | |||
| 'SpatialSmoothing', | |||
| 'EnsembleDetector', | |||
| 'SimilarityDetector'] | |||
+ 0
- 0
mindarmour/detectors/black/__init__.py
View File
+ 284
- 0
mindarmour/detectors/black/similarity_detector.py
View File
| @@ -0,0 +1,284 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Similarity Detector. | |||
| """ | |||
| import itertools | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore import Model | |||
| from mindarmour.detectors.detector import Detector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_model, check_numpy_param, \ | |||
| check_int_positive, check_value_positive, check_param_type, \ | |||
| check_param_in_range | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'SimilarityDetector' | |||
| def _pairwise_distances(x_input, y_input): | |||
| """ | |||
| Compute the Euclidean Distance matrix from a vector array x_input and | |||
| y_input. | |||
| Args: | |||
| x_input (numpy.ndarray): input data, [n_samples_x, n_features] | |||
| y_input (numpy.ndarray): input data, [n_samples_y, n_features] | |||
| Returns: | |||
| numpy.ndarray, distance matrix, [n_samples_a, n_samples_b] | |||
| """ | |||
| out = np.empty((x_input.shape[0], y_input.shape[0]), dtype='float') | |||
| iterator = itertools.product( | |||
| range(x_input.shape[0]), range(y_input.shape[0])) | |||
| for i, j in iterator: | |||
| out[i, j] = np.linalg.norm(x_input[i] - y_input[j]) | |||
| return out | |||
| class SimilarityDetector(Detector): | |||
| """ | |||
| The detector measures similarity among adjacent queries and rejects queries | |||
| which are remarkably similar to previous queries. | |||
| Reference: `Stateful Detection of Black-Box Adversarial Attacks by Steven | |||
| Chen, Nicholas Carlini, and David Wagner. at arxiv 2019 | |||
| <https://arxiv.org/abs/1907.05587>`_ | |||
| Args: | |||
| trans_model (Model): A MindSpore model to encode input data into lower | |||
| dimension vector. | |||
| max_k_neighbor (int): The maximum number of the nearest neighbors. | |||
| Default: 1000. | |||
| chunk_size (int): Buffer size. Default: 1000. | |||
| max_buffer_size (int): Maximum buffer size. Default: 10000. | |||
| tuning (bool): Calculate the average distance for the nearest k | |||
| neighbours, if tuning is true, k=K. If False k=1,...,K. | |||
| Default: False. | |||
| fpr (float): False positive ratio on legitimate query sequences. | |||
| Default: 0.001 | |||
| Examples: | |||
| >>> detector = SimilarityDetector(model) | |||
| >>> detector.fit(Tensor(ori), Tensor(labels)) | |||
| >>> adv_ids = detector.detect(Tensor(adv)) | |||
| """ | |||
| def __init__(self, trans_model, max_k_neighbor=1000, chunk_size=1000, | |||
| max_buffer_size=10000, tuning=False, fpr=0.001): | |||
| super(SimilarityDetector, self).__init__() | |||
| self._max_k_neighbor = check_int_positive('max_k_neighbor', | |||
| max_k_neighbor) | |||
| self._trans_model = check_model('trans_model', trans_model, Model) | |||
| self._tuning = check_param_type('tuning', tuning, bool) | |||
| self._chunk_size = check_int_positive('chunk_size', chunk_size) | |||
| self._max_buffer_size = check_int_positive('max_buffer_size', | |||
| max_buffer_size) | |||
| self._fpr = check_param_in_range('fpr', fpr, 0, 1) | |||
| self._num_of_neighbors = None | |||
| self._threshold = None | |||
| self._num_queries = 0 | |||
| # Stores recently processed queries | |||
| self._buffer = [] | |||
| # Tracks indexes of detected queries | |||
| self._detected_queries = [] | |||
| def fit(self, inputs, labels=None): | |||
| """ | |||
| Process input training data to calculate the threshold. | |||
| A proper threshold should make sure the false positive | |||
| rate is under a given value. | |||
| Args: | |||
| inputs (numpy.ndarray): Training data to calculate the threshold. | |||
| labels (numpy.ndarray): Labels of training data. | |||
| Returns: | |||
| - list[int], number of the nearest neighbors. | |||
| - list[float], calculated thresholds for different K. | |||
| Raises: | |||
| ValueError: The number of training data is less than | |||
| max_k_neighbor! | |||
| """ | |||
| data = check_numpy_param('inputs', inputs) | |||
| data_len = data.shape[0] | |||
| if data_len < self._max_k_neighbor: | |||
| raise ValueError('The number of training data must be larger than ' | |||
| 'max_k_neighbor!') | |||
| data = self._trans_model.predict(Tensor(data)).asnumpy() | |||
| data = data.reshape((data.shape[0], -1)) | |||
| distances = [] | |||
| for i in range(data.shape[0] // self._chunk_size): | |||
| distance_mat = _pairwise_distances( | |||
| x_input=data[i*self._chunk_size:(i + 1)*self._chunk_size, :], | |||
| y_input=data) | |||
| distance_mat = np.sort(distance_mat, axis=-1) | |||
| distances.append(distance_mat[:, :self._max_k_neighbor]) | |||
| # the rest | |||
| distance_mat = _pairwise_distances(x_input=data[(data.shape[0] // | |||
| self._chunk_size)* | |||
| self._chunk_size:, :], | |||
| y_input=data) | |||
| distance_mat = np.sort(distance_mat, axis=-1) | |||
| distances.append(distance_mat[:, :self._max_k_neighbor]) | |||
| distance_matrix = np.concatenate(distances, axis=0) | |||
| start = 1 if self._tuning else self._max_k_neighbor | |||
| thresholds = [] | |||
| num_nearest_neighbors = [] | |||
| for k in range(start, self._max_k_neighbor + 1): | |||
| avg_dist = distance_matrix[:, :k].mean(axis=-1) | |||
| index = int(len(avg_dist)*self._fpr) | |||
| threshold = np.sort(avg_dist, axis=None)[index] | |||
| num_nearest_neighbors.append(k) | |||
| thresholds.append(threshold) | |||
| if thresholds: | |||
| self._threshold = thresholds[-1] | |||
| self._num_of_neighbors = num_nearest_neighbors[-1] | |||
| return num_nearest_neighbors, thresholds | |||
| def detect(self, inputs): | |||
| """ | |||
| Process queries to detect black-box attack. | |||
| Args: | |||
| inputs (numpy.ndarray): Query sequence. | |||
| Raises: | |||
| ValueError: The parameters of threshold or num_of_neighbors is | |||
| not available. | |||
| """ | |||
| if self._threshold is None or self._num_of_neighbors is None: | |||
| msg = 'Explicit detection threshold and number of nearest ' \ | |||
| 'neighbors must be provided using set_threshold(), ' \ | |||
| 'or call fit() to calculate.' | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| queries = check_numpy_param('inputs', inputs) | |||
| queries = self._trans_model.predict(Tensor(queries)).asnumpy() | |||
| queries = queries.reshape((queries.shape[0], -1)) | |||
| for query in queries: | |||
| self._process_query(query) | |||
| def _process_query(self, query): | |||
| """ | |||
| Process each query to detect black-box attack. | |||
| Args: | |||
| query (numpy.ndarray): Query input. | |||
| """ | |||
| if len(self._buffer) < self._num_of_neighbors: | |||
| self._buffer.append(query) | |||
| self._num_queries += 1 | |||
| return | |||
| k = self._num_of_neighbors | |||
| if self._buffer: | |||
| queries = np.stack(self._buffer, axis=0) | |||
| dists = np.linalg.norm(queries - query, axis=-1) | |||
| k_nearest_dists = np.partition(dists, k - 1)[:k, None] | |||
| k_avg_dist = np.mean(k_nearest_dists) | |||
| self._buffer.append(query) | |||
| self._num_queries += 1 | |||
| if len(self._buffer) >= self._max_buffer_size: | |||
| self.clear_buffer() | |||
| # an attack is detected | |||
| if k_avg_dist < self._threshold: | |||
| self._detected_queries.append(self._num_queries) | |||
| self.clear_buffer() | |||
| def clear_buffer(self): | |||
| """ | |||
| Clear the buffer memory. | |||
| """ | |||
| while self._buffer: | |||
| self._buffer.pop() | |||
| def set_threshold(self, num_of_neighbors, threshold): | |||
| """ | |||
| Set the parameters num_of_neighbors and threshold. | |||
| Args: | |||
| num_of_neighbors (int): Number of the nearest neighbors. | |||
| threshold (float): Detection threshold. Default: None. | |||
| """ | |||
| self._num_of_neighbors = check_int_positive('num_of_neighbors', | |||
| num_of_neighbors) | |||
| self._threshold = check_value_positive('threshold', threshold) | |||
| def get_detection_interval(self): | |||
| """ | |||
| Get the interval between adjacent detections. | |||
| Returns: | |||
| list[int], number of queries between adjacent detections. | |||
| """ | |||
| detected_queries = self._detected_queries | |||
| interval = [] | |||
| for i in range(len(detected_queries) - 1): | |||
| interval.append(detected_queries[i + 1] - detected_queries[i]) | |||
| return interval | |||
| def get_detected_queries(self): | |||
| """ | |||
| Get the indexes of detected queries. | |||
| Returns: | |||
| list[int], sequence number of detected malicious queries. | |||
| """ | |||
| detected_queries = self._detected_queries | |||
| return detected_queries | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| Detect adversarial samples from input samples, like the predict_proba | |||
| function in common machine learning model. | |||
| Args: | |||
| inputs (Union[numpy.ndarray, list, tuple]): Data been used as | |||
| references to create adversarial examples. | |||
| Raises: | |||
| NotImplementedError: This function is not available | |||
| in class `SimilarityDetector`. | |||
| """ | |||
| msg = 'The function detect_diff() is not available in the class ' \ | |||
| '`SimilarityDetector`.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| def transform(self, inputs): | |||
| """ | |||
| Filter adversarial noises in input samples. | |||
| Raises: | |||
| NotImplementedError: This function is not available | |||
| in class `SimilarityDetector`. | |||
| """ | |||
| msg = 'The function transform() is not available in the class ' \ | |||
| '`SimilarityDetector`.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
+ 101
- 0
mindarmour/detectors/detector.py
View File
| @@ -0,0 +1,101 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Base Class of Detector. | |||
| """ | |||
| from abc import abstractmethod | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Detector' | |||
| class Detector: | |||
| """ | |||
| The abstract base class for all adversarial example detectors. | |||
| """ | |||
| def __init__(self): | |||
| pass | |||
| @abstractmethod | |||
| def fit(self, inputs, labels=None): | |||
| """ | |||
| Fit a threshold and refuse adversarial examples whose difference from | |||
| their denoised versions are larger than the threshold. The threshold is | |||
| determined by a certain false positive rate when applying to normal samples. | |||
| Args: | |||
| inputs (numpy.ndarray): The input samples to calculate the threshold. | |||
| labels (numpy.ndarray): Labels of training data. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function fit() is an abstract function in class ' \ | |||
| '`Detector` and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| @abstractmethod | |||
| def detect(self, inputs): | |||
| """ | |||
| Detect adversarial examples from input samples. | |||
| Args: | |||
| inputs (Union[numpy.ndarray, list, tuple]): The input samples to be | |||
| detected. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function detect() is an abstract function in class ' \ | |||
| '`Detector` and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| @abstractmethod | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| Calculate the difference between the input samples and de-noised samples. | |||
| Args: | |||
| inputs (Union[numpy.ndarray, list, tuple]): The input samples to be | |||
| detected. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function detect_diff() is an abstract function in class ' \ | |||
| '`Detector` and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| @abstractmethod | |||
| def transform(self, inputs): | |||
| """ | |||
| Filter adversarial noises in input samples. | |||
| Args: | |||
| inputs (Union[numpy.ndarray, list, tuple]): The input samples to be | |||
| transformed. | |||
| Raises: | |||
| NotImplementedError: It is an abstract method. | |||
| """ | |||
| msg = 'The function transform() is an abstract function in class ' \ | |||
| '`Detector` and should be implemented in child class.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
+ 126
- 0
mindarmour/detectors/ensemble_detector.py
View File
| @@ -0,0 +1,126 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Ensemble Detector. | |||
| """ | |||
| import numpy as np | |||
| from mindarmour.detectors.detector import Detector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_numpy_param, \ | |||
| check_param_multi_types | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'EnsembleDetector' | |||
| class EnsembleDetector(Detector): | |||
| """ | |||
| Ensemble detector. | |||
| Args: | |||
| detectors (Union[tuple, list]): List of detector methods. | |||
| policy (str): Decision policy, could be 'vote', 'all' or 'any'. | |||
| Default: 'vote' | |||
| """ | |||
| def __init__(self, detectors, policy="vote"): | |||
| super(EnsembleDetector, self).__init__() | |||
| self._detectors = check_param_multi_types('detectors', detectors, | |||
| [list, tuple]) | |||
| self._num_detectors = len(detectors) | |||
| self._policy = policy | |||
| def fit(self, inputs, labels=None): | |||
| """ | |||
| Fit detector like a machine learning model. This method is not available | |||
| in this class. | |||
| Args: | |||
| inputs (numpy.ndarray): Data to calculate the threshold. | |||
| labels (numpy.ndarray): Labels of data. | |||
| Raises: | |||
| NotImplementedError: This function is not available in ensemble. | |||
| """ | |||
| msg = 'The function fit() is not available in the class ' \ | |||
| '`EnsembleDetector`.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| def detect(self, inputs): | |||
| """ | |||
| Detect adversarial examples from input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| Returns: | |||
| list[int], whether a sample is adversarial. if res[i]=1, then the | |||
| input sample with index i is adversarial. | |||
| Raises: | |||
| ValueError: If policy is not supported. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| x_len = inputs.shape[0] | |||
| counts = np.zeros(x_len) | |||
| res = np.zeros(x_len, dtype=np.int) | |||
| for detector in list(self._detectors): | |||
| idx = detector.detect(inputs) | |||
| counts[idx] += 1 | |||
| if self._policy == "vote": | |||
| idx_adv = np.argwhere(counts > self._num_detectors / 2) | |||
| elif self._policy == "all": | |||
| idx_adv = np.argwhere(counts == self._num_detectors) | |||
| elif self._policy == "any": | |||
| idx_adv = np.argwhere(counts > 0) | |||
| else: | |||
| msg = 'Policy {} is not supported.'.format(self._policy) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| res[idx_adv] = 1 | |||
| return list(res) | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| This method is not available in this class. | |||
| Args: | |||
| inputs (Union[numpy.ndarray, list, tuple]): Data been used as | |||
| references to create adversarial examples. | |||
| Raises: | |||
| NotImplementedError: This function is not available in ensemble. | |||
| """ | |||
| msg = 'The function detect_diff() is not available in the class ' \ | |||
| '`EnsembleDetector`.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| def transform(self, inputs): | |||
| """ | |||
| Filter adversarial noises in input samples. | |||
| This method is not available in this class. | |||
| Raises: | |||
| NotImplementedError: This function is not available in ensemble. | |||
| """ | |||
| msg = 'The function transform() is not available in the class ' \ | |||
| '`EnsembleDetector`.' | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
+ 228
- 0
mindarmour/detectors/mag_net.py
View File
| @@ -0,0 +1,228 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Error-Based detector. | |||
| """ | |||
| import numpy as np | |||
| from scipy import stats | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import Model | |||
| from mindarmour.detectors.detector import Detector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_numpy_param, check_model, \ | |||
| check_param_in_range, check_param_multi_types, check_int_positive, \ | |||
| check_value_positive | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'MagNet' | |||
| class ErrorBasedDetector(Detector): | |||
| """ | |||
| The detector reconstructs input samples, measures reconstruction errors and | |||
| rejects samples with large reconstruction errors. | |||
| Reference: `MagNet: a Two-Pronged Defense against Adversarial Examples, | |||
| by Dongyu Meng and Hao Chen, at CCS 2017. | |||
| <https://arxiv.org/abs/1705.09064>`_ | |||
| Args: | |||
| auto_encoder (Model): An (trained) auto encoder which | |||
| represents the input by reduced encoding. | |||
| false_positive_rate (float): Detector's false positive rate. | |||
| Default: 0.01. | |||
| bounds (tuple): (clip_min, clip_max). Default: (0.0, 1.0). | |||
| """ | |||
| def __init__(self, auto_encoder, false_positive_rate=0.01, | |||
| bounds=(0.0, 1.0)): | |||
| super(ErrorBasedDetector, self).__init__() | |||
| self._auto_encoder = check_model('auto_encoder', auto_encoder, Model) | |||
| self._false_positive_rate = check_param_in_range('false_positive_rate', | |||
| false_positive_rate, | |||
| 0, 1) | |||
| self._threshold = 0.0 | |||
| self._bounds = check_param_multi_types('bounds', bounds, [list, tuple]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| def fit(self, inputs, labels=None): | |||
| """ | |||
| Find a threshold for a given dataset to distinguish adversarial examples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| labels (numpy.ndarray): Labels of input samples. Default: None. | |||
| Returns: | |||
| float, threshold to distinguish adversarial samples from benign ones. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| marks = self.detect_diff(inputs) | |||
| num = int(inputs.shape[0]*self._false_positive_rate) | |||
| marks = np.sort(marks) | |||
| if num <= len(marks): | |||
| self._threshold = marks[-num] | |||
| return self._threshold | |||
| def detect(self, inputs): | |||
| """ | |||
| Detect if input samples are adversarial or not. | |||
| Args: | |||
| inputs (numpy.ndarray): Suspicious samples to be judged. | |||
| Returns: | |||
| list[int], whether a sample is adversarial. if res[i]=1, then the | |||
| input sample with index i is adversarial. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| dist = self.detect_diff(inputs) | |||
| res = [0]*len(dist) | |||
| for i, elem in enumerate(dist): | |||
| if elem > self._threshold: | |||
| res[i] = 1 | |||
| return res | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| Detect the distance between the original samples and reconstructed samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| Returns: | |||
| float, the distance between reconstructed and original samples. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| x_trans = self._auto_encoder.predict(Tensor(inputs)) | |||
| diff = np.abs(inputs - x_trans.asnumpy()) | |||
| dims = tuple(np.arange(len(inputs.shape))[1:]) | |||
| marks = np.mean(np.power(diff, 2), axis=dims) | |||
| return marks | |||
| def transform(self, inputs): | |||
| """ | |||
| Reconstruct input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| Returns: | |||
| numpy.ndarray, reconstructed images. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| x_trans = self._auto_encoder.predict(Tensor(inputs)) | |||
| if self._bounds is not None: | |||
| clip_min, clip_max = self._bounds | |||
| x_trans = np.clip(x_trans.asnumpy(), clip_min, clip_max) | |||
| return x_trans | |||
| def set_threshold(self, threshold): | |||
| """ | |||
| Set the parameters threshold. | |||
| Args: | |||
| threshold (float): Detection threshold. Default: None. | |||
| """ | |||
| self._threshold = check_value_positive('threshold', threshold) | |||
| class DivergenceBasedDetector(ErrorBasedDetector): | |||
| """ | |||
| This class implement a divergence-based detector. | |||
| Reference: `MagNet: a Two-Pronged Defense against Adversarial Examples, | |||
| by Dongyu Meng and Hao Chen, at CCS 2017. | |||
| <https://arxiv.org/abs/1705.09064>`_ | |||
| Args: | |||
| auto_encoder (Model): Encoder model. | |||
| model (Model): Targeted model. | |||
| option (str): Method used to calculate Divergence. Default: "jsd". | |||
| t (int): Temperature used to overcome numerical problem. Default: 1. | |||
| bounds (tuple): Upper and lower bounds of data. | |||
| In form of (clip_min, clip_max). Default: (0.0, 1.0). | |||
| """ | |||
| def __init__(self, auto_encoder, model, option="jsd", | |||
| t=1, bounds=(0.0, 1.0)): | |||
| super(DivergenceBasedDetector, self).__init__(auto_encoder, | |||
| bounds=bounds) | |||
| self._auto_encoder = auto_encoder | |||
| self._model = check_model('targeted model', model, Model) | |||
| self._threshold = 0.0 | |||
| self._option = option | |||
| self._t = check_int_positive('t', t) | |||
| self._bounds = check_param_multi_types('bounds', bounds, [tuple, list]) | |||
| for b in self._bounds: | |||
| _ = check_param_multi_types('bound', b, [int, float]) | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| Detect the distance between original samples and reconstructed samples. | |||
| The distance is calculated by JSD. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| Returns: | |||
| float, the distance. | |||
| Raises: | |||
| NotImplementedError: If the param `option` is not supported. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| x_len = inputs.shape[0] | |||
| x_transformed = self._auto_encoder.predict(Tensor(inputs)) | |||
| x_origin = self._model.predict(Tensor(inputs)) | |||
| x_trans = self._model.predict(x_transformed) | |||
| y_pred = softmax(x_origin.asnumpy() / self._t, axis=1) | |||
| y_trans_pred = softmax(x_trans.asnumpy() / self._t, axis=1) | |||
| if self._option == 'jsd': | |||
| marks = [_jsd(y_pred[i], y_trans_pred[i]) for i in range(x_len)] | |||
| else: | |||
| msg = '{} is not implemented.'.format(self._option) | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| return np.array(marks) | |||
| def _jsd(prob_dist_p, prob_dist_q): | |||
| """ | |||
| Compute the Jensen-Shannon Divergence between two probability distributions | |||
| with equal weights. | |||
| Args: | |||
| prob_dist_p (numpy.ndarray): Probability distribution p. | |||
| prob_dist_q (numpy.ndarray): Probability distribution q. | |||
| Returns: | |||
| float, the Jensen-Shannon Divergence. | |||
| """ | |||
| prob_dist_p = check_numpy_param('prob_dist_p', prob_dist_p) | |||
| prob_dist_q = check_numpy_param('prob_dist_q', prob_dist_q) | |||
| norm_dist_p = prob_dist_p / (np.linalg.norm(prob_dist_p, ord=1) + 1e-12) | |||
| norm_dist_q = prob_dist_q / (np.linalg.norm(prob_dist_q, ord=1) + 1e-12) | |||
| norm_mean = 0.5*(norm_dist_p + norm_dist_q) | |||
| return 0.5*(stats.entropy(norm_dist_p, norm_mean) | |||
| + stats.entropy(norm_dist_q, norm_mean)) | |||
+ 235
- 0
mindarmour/detectors/region_based_detector.py
View File
| @@ -0,0 +1,235 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Region-Based detector | |||
| """ | |||
| import time | |||
| import numpy as np | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindarmour.detectors.detector import Detector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_numpy_param, check_param_type, \ | |||
| check_pair_numpy_param, check_model, check_int_positive, \ | |||
| check_value_positive, check_value_non_negative, check_param_in_range, \ | |||
| check_equal_shape | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'RegionBasedDetector' | |||
| class RegionBasedDetector(Detector): | |||
| """ | |||
| This class implement a region-based detector. | |||
| Reference: `Mitigating evasion attacks to deep neural networks via | |||
| region-based classification <https://arxiv.org/abs/1709.05583>`_ | |||
| Args: | |||
| model (Model): Target model. | |||
| number_points (int): The number of samples generate from the | |||
| hyper cube of original sample. Default: 10. | |||
| initial_radius (float): Initial radius of hyper cube. Default: 0.0. | |||
| max_radius (float): Maximum radius of hyper cube. Default: 1.0. | |||
| search_step (float): Incremental during search of radius. Default: 0.01. | |||
| degrade_limit (float): Acceptable decrease of classification accuracy. | |||
| Default: 0.0. | |||
| sparse (bool): If True, input labels are sparse-encoded. If False, | |||
| input labels are one-hot-encoded. Default: False. | |||
| Examples: | |||
| >>> detector = RegionBasedDetector(model) | |||
| >>> detector.fit(Tensor(ori), Tensor(labels)) | |||
| >>> adv_ids = detector.detect(Tensor(adv)) | |||
| """ | |||
| def __init__(self, model, number_points=10, initial_radius=0.0, | |||
| max_radius=1.0, search_step=0.01, degrade_limit=0.0, | |||
| sparse=False): | |||
| super(RegionBasedDetector, self).__init__() | |||
| self._model = check_model('targeted model', model, Model) | |||
| self._number_points = check_int_positive('number_points', number_points) | |||
| self._initial_radius = check_value_non_negative('initial_radius', | |||
| initial_radius) | |||
| self._max_radius = check_value_positive('max_radius', max_radius) | |||
| self._search_step = check_value_positive('search_step', search_step) | |||
| self._degrade_limit = check_value_non_negative('degrade_limit', | |||
| degrade_limit) | |||
| self._sparse = check_param_type('sparse', sparse, bool) | |||
| self._radius = None | |||
| def set_radius(self, radius): | |||
| """Set radius.""" | |||
| self._radius = check_param_in_range('radius', radius, | |||
| self._initial_radius, | |||
| self._max_radius) | |||
| def fit(self, inputs, labels=None): | |||
| """ | |||
| Train detector to decide the best radius. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign samples. | |||
| labels (numpy.ndarray): Ground truth labels of the input samples. | |||
| Default:None. | |||
| Returns: | |||
| float, the best radius. | |||
| """ | |||
| inputs, labels = check_pair_numpy_param('inputs', inputs, | |||
| 'labels', labels) | |||
| LOGGER.debug(TAG, 'enter fit() function.') | |||
| time_start = time.time() | |||
| search_iters = (self._max_radius | |||
| - self._initial_radius) / self._search_step | |||
| search_iters = np.round(search_iters).astype(int) | |||
| radius = self._initial_radius | |||
| pred = self._model.predict(Tensor(inputs)) | |||
| raw_preds = np.argmax(pred.asnumpy(), axis=1) | |||
| if not self._sparse: | |||
| labels = np.argmax(labels, axis=1) | |||
| raw_preds, labels = check_equal_shape('raw_preds', raw_preds, 'labels', | |||
| labels) | |||
| raw_acc = np.sum(raw_preds == labels) / inputs.shape[0] | |||
| for _ in range(search_iters): | |||
| rc_preds = self._rc_forward(inputs, radius) | |||
| rc_preds, labels = check_equal_shape('rc_preds', rc_preds, 'labels', | |||
| labels) | |||
| def_acc = np.sum(rc_preds == labels) / inputs.shape[0] | |||
| if def_acc >= raw_acc - self._degrade_limit: | |||
| radius += self._search_step | |||
| continue | |||
| break | |||
| self._radius = radius - self._search_step | |||
| LOGGER.debug(TAG, 'best radius is: %s', self._radius) | |||
| LOGGER.debug(TAG, | |||
| 'time used to train detector of %d samples is: %s seconds', | |||
| inputs.shape[0], | |||
| time.time() - time_start) | |||
| return self._radius | |||
| def _generate_hyper_cube(self, inputs, radius): | |||
| """ | |||
| Generate random samples in the hyper cubes around input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| radius (float): The scope to generate hyper cubes around input samples. | |||
| Returns: | |||
| numpy.ndarray, randomly chosen samples in the hyper cubes. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter _generate_hyper_cube().') | |||
| res = [] | |||
| for _ in range(self._number_points): | |||
| res.append(np.clip((inputs + np.random.uniform( | |||
| -radius, radius, len(inputs))), 0.0, 1.0).astype(inputs.dtype)) | |||
| return np.asarray(res) | |||
| def _rc_forward(self, inputs, radius): | |||
| """ | |||
| Generate region-based predictions for input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| radius (float): The scope to generate hyper cubes around input samples. | |||
| Returns: | |||
| numpy.ndarray, classification result for input samples. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter _rc_forward().') | |||
| res = [] | |||
| for _, elem in enumerate(inputs): | |||
| hyper_cube_x = self._generate_hyper_cube(elem, radius) | |||
| hyper_cube_preds = [] | |||
| for ite_hyper_cube_x in hyper_cube_x: | |||
| model_inputs = Tensor(np.expand_dims(ite_hyper_cube_x, axis=0)) | |||
| ite_preds = self._model.predict(model_inputs).asnumpy()[0] | |||
| hyper_cube_preds.append(ite_preds) | |||
| pred_labels = np.argmax(hyper_cube_preds, axis=1) | |||
| bin_count = np.bincount(pred_labels) | |||
| # count the number of different class and choose the max one | |||
| # as final class | |||
| hyper_cube_tag = np.argmax(bin_count, axis=0) | |||
| res.append(hyper_cube_tag) | |||
| return np.asarray(res) | |||
| def detect(self, inputs): | |||
| """ | |||
| Tell whether input samples are adversarial or not. | |||
| Args: | |||
| inputs (numpy.ndarray): Suspicious samples to be judged. | |||
| Returns: | |||
| list[int], whether a sample is adversarial. if res[i]=1, then the | |||
| input sample with index i is adversarial. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter detect().') | |||
| self._radius = check_param_type('radius', self._radius, float) | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| time_start = time.time() | |||
| res = [1]*inputs.shape[0] | |||
| raw_preds = np.argmax(self._model.predict(Tensor(inputs)).asnumpy(), | |||
| axis=1) | |||
| rc_preds = self._rc_forward(inputs, self._radius) | |||
| for i in range(inputs.shape[0]): | |||
| if raw_preds[i] == rc_preds[i]: | |||
| res[i] = 0 | |||
| LOGGER.debug(TAG, | |||
| 'time used to detect %d samples is : %s seconds', | |||
| inputs.shape[0], | |||
| time.time() - time_start) | |||
| return res | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| Return raw prediction results and region-based prediction results. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| Returns: | |||
| numpy.ndarray, raw prediction results and region-based prediction results of input samples. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter detect_diff().') | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| raw_preds = self._model.predict(Tensor(inputs)) | |||
| rc_preds = self._rc_forward(inputs, self._radius) | |||
| return raw_preds.asnumpy(), rc_preds | |||
| def transform(self, inputs): | |||
| """ | |||
| Generate hyper cube for input samples. | |||
| Args: | |||
| inputs (numpy.ndarray): Input samples. | |||
| Returns: | |||
| numpy.ndarray, hyper cube corresponds to every sample. | |||
| """ | |||
| LOGGER.debug(TAG, 'enter transform().') | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| res = [] | |||
| for _, elem in enumerate(inputs): | |||
| res.append(self._generate_hyper_cube(elem, self._radius)) | |||
| return np.asarray(res) | |||
+ 171
- 0
mindarmour/detectors/spatial_smoothing.py
View File
| @@ -0,0 +1,171 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Spatial-Smoothing detector. | |||
| """ | |||
| import numpy as np | |||
| from scipy import ndimage | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindarmour.detectors.detector import Detector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_model, check_numpy_param, \ | |||
| check_pair_numpy_param, check_int_positive, check_param_type, \ | |||
| check_param_in_range, check_equal_shape, check_value_positive | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'SpatialSmoothing' | |||
| def _median_filter_np(inputs, size=2): | |||
| """median filter using numpy""" | |||
| return ndimage.filters.median_filter(inputs, size=size, mode='reflect') | |||
| class SpatialSmoothing(Detector): | |||
| """ | |||
| Detect method based on spatial smoothing. | |||
| Args: | |||
| model (Model): Target model. | |||
| ksize (int): Smooth window size. Default: 3. | |||
| is_local_smooth (bool): If True, trigger local smooth. If False, none | |||
| local smooth. Default: True. | |||
| metric (str): Distance method. Default: 'l1'. | |||
| false_positive_ratio (float): False positive rate over | |||
| benign samples. Default: 0.05. | |||
| Examples: | |||
| >>> detector = SpatialSmoothing(model) | |||
| >>> detector.fit(Tensor(ori), Tensor(labels)) | |||
| >>> adv_ids = detector.detect(Tensor(adv)) | |||
| """ | |||
| def __init__(self, model, ksize=3, is_local_smooth=True, | |||
| metric='l1', false_positive_ratio=0.05): | |||
| super(SpatialSmoothing, self).__init__() | |||
| self._ksize = check_int_positive('ksize', ksize) | |||
| self._is_local_smooth = check_param_type('is_local_smooth', | |||
| is_local_smooth, | |||
| bool) | |||
| self._model = check_model('model', model, Model) | |||
| self._metric = metric | |||
| self._fpr = check_param_in_range('false_positive_ratio', | |||
| false_positive_ratio, | |||
| 0, 1) | |||
| self._threshold = None | |||
| def fit(self, inputs, labels=None): | |||
| """ | |||
| Train detector to decide the threshold. The proper threshold make | |||
| sure the actual false positive rate over benign sample is less than | |||
| the given value. | |||
| Args: | |||
| inputs (numpy.ndarray): Benign samples. | |||
| labels (numpy.ndarray): Default None. | |||
| Returns: | |||
| float, threshold, distance larger than which is reported | |||
| as positive, i.e. adversarial. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| raw_pred = self._model.predict(Tensor(inputs)) | |||
| smoothing_pred = self._model.predict(Tensor(self.transform(inputs))) | |||
| dist = self._dist(raw_pred.asnumpy(), smoothing_pred.asnumpy()) | |||
| index = int(len(dist)*(1 - self._fpr)) | |||
| threshold = np.sort(dist, axis=None)[index] | |||
| self._threshold = threshold | |||
| return self._threshold | |||
| def detect(self, inputs): | |||
| """ | |||
| Detect if an input sample is an adversarial example. | |||
| Args: | |||
| inputs (numpy.ndarray): Suspicious samples to be judged. | |||
| Returns: | |||
| list[int], whether a sample is adversarial. if res[i]=1, then the | |||
| input sample with index i is adversarial. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| raw_pred = self._model.predict(Tensor(inputs)) | |||
| smoothing_pred = self._model.predict(Tensor(self.transform(inputs))) | |||
| dist = self._dist(raw_pred.asnumpy(), smoothing_pred.asnumpy()) | |||
| res = [0]*len(dist) | |||
| for i, elem in enumerate(dist): | |||
| if elem > self._threshold: | |||
| res[i] = 1 | |||
| return res | |||
| def detect_diff(self, inputs): | |||
| """ | |||
| Return the raw distance value (before apply the threshold) between | |||
| the input sample and its smoothed counterpart. | |||
| Args: | |||
| inputs (numpy.ndarray): Suspicious samples to be judged. | |||
| Returns: | |||
| float, distance. | |||
| """ | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| raw_pred = self._model.predict(Tensor(inputs)) | |||
| smoothing_pred = self._model.predict(Tensor(self.transform(inputs))) | |||
| dist = self._dist(raw_pred.asnumpy(), smoothing_pred.asnumpy()) | |||
| return dist | |||
| def transform(self, inputs): | |||
| inputs = check_numpy_param('inputs', inputs) | |||
| return _median_filter_np(inputs, self._ksize) | |||
| def set_threshold(self, threshold): | |||
| """ | |||
| Set the parameters threshold. | |||
| Args: | |||
| threshold (float): Detection threshold. Default: None. | |||
| """ | |||
| self._threshold = check_value_positive('threshold', threshold) | |||
| def _dist(self, before, after): | |||
| """ | |||
| Calculate the distance between the model outputs of a raw sample and | |||
| its smoothed counterpart. | |||
| Args: | |||
| before (numpy.ndarray): Model output of raw samples. | |||
| after (numpy.ndarray): Model output of smoothed counterparts. | |||
| Returns: | |||
| float, distance based on specified norm. | |||
| """ | |||
| before, after = check_pair_numpy_param('before', before, 'after', after) | |||
| before, after = check_equal_shape('before', before, 'after', after) | |||
| res = [] | |||
| diff = after - before | |||
| for _, elem in enumerate(diff): | |||
| if self._metric == 'l1': | |||
| res.append(np.linalg.norm(elem, ord=1)) | |||
| elif self._metric == 'l2': | |||
| res.append(np.linalg.norm(elem, ord=2)) | |||
| else: | |||
| res.append(np.linalg.norm(elem, ord=1)) | |||
| return res | |||
+ 14
- 0
mindarmour/evaluations/__init__.py
View File
| @@ -0,0 +1,14 @@ | |||
| """ | |||
| This module includes various metrics to evaluate the result of attacks or | |||
| defenses. | |||
| """ | |||
| from .attack_evaluation import AttackEvaluate | |||
| from .defense_evaluation import DefenseEvaluate | |||
| from .visual_metrics import RadarMetric | |||
| from . import black | |||
| from .black.defense_evaluation import BlackDefenseEvaluate | |||
| __all__ = ['AttackEvaluate', | |||
| 'BlackDefenseEvaluate', | |||
| 'DefenseEvaluate', | |||
| 'RadarMetric'] | |||
+ 275
- 0
mindarmour/evaluations/attack_evaluation.py
View File
| @@ -0,0 +1,275 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Attack evaluation. | |||
| """ | |||
| import numpy as np | |||
| from scipy.ndimage.filters import convolve | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, \ | |||
| check_param_type, check_numpy_param, check_equal_shape | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'AttackEvaluate' | |||
| def _compute_ssim(img_1, img_2, kernel_sigma=1.5, kernel_width=11): | |||
| """ | |||
| compute structural similarity. | |||
| Args: | |||
| img_1 (numpy.ndarray): The first image to be compared. | |||
| img_2 (numpy.ndarray): The second image to be compared. | |||
| kernel_sigma (float): Gassian kernel param. Default: 1.5. | |||
| kernel_width (int): Another Gassian kernel param. Default: 11. | |||
| Returns: | |||
| float, structural similarity. | |||
| """ | |||
| img_1, img_2 = check_equal_shape('images_1', img_1, 'images_2', img_2) | |||
| if len(img_1.shape) > 2: | |||
| total_ssim = 0 | |||
| for i in range(img_1.shape[2]): | |||
| total_ssim += _compute_ssim(img_1[:, :, i], img_2[:, :, i]) | |||
| return total_ssim / 3 | |||
| # Create gaussian kernel | |||
| gaussian_kernel = np.zeros((kernel_width, kernel_width)) | |||
| for i in range(kernel_width): | |||
| for j in range(kernel_width): | |||
| gaussian_kernel[i, j] = (1 / (2*np.pi*(kernel_sigma**2)))*np.exp( | |||
| - (((i - 5)**2) + ((j - 5)**2)) / (2*(kernel_sigma**2))) | |||
| img_1 = img_1.astype(np.float32) | |||
| img_2 = img_2.astype(np.float32) | |||
| img_sq_1 = img_1**2 | |||
| img_sq_2 = img_2**2 | |||
| img_12 = img_1*img_2 | |||
| # Mean | |||
| img_mu_1 = convolve(img_1, gaussian_kernel) | |||
| img_mu_2 = convolve(img_2, gaussian_kernel) | |||
| # Mean square | |||
| img_mu_sq_1 = img_mu_1**2 | |||
| img_mu_sq_2 = img_mu_2**2 | |||
| img_mu_12 = img_mu_1*img_mu_2 | |||
| # Variances | |||
| img_sigma_sq_1 = convolve(img_sq_1, gaussian_kernel) | |||
| img_sigma_sq_2 = convolve(img_sq_2, gaussian_kernel) | |||
| # Covariance | |||
| img_sigma_12 = convolve(img_12, gaussian_kernel) | |||
| # Centered squares of variances | |||
| img_sigma_sq_1 = img_sigma_sq_1 - img_mu_sq_1 | |||
| img_sigma_sq_2 = img_sigma_sq_2 - img_mu_sq_2 | |||
| img_sigma_12 = img_sigma_12 - img_mu_12 | |||
| k_1 = 0.01 | |||
| k_2 = 0.03 | |||
| c_1 = (k_1*255)**2 | |||
| c_2 = (k_2*255)**2 | |||
| # Calculate ssim | |||
| num_ssim = (2*img_mu_12 + c_1)*(2*img_sigma_12 + c_2) | |||
| den_ssim = (img_mu_sq_1 + img_mu_sq_2 + c_1)*(img_sigma_sq_1 | |||
| + img_sigma_sq_2 + c_2) | |||
| res = np.average(num_ssim / den_ssim) | |||
| return res | |||
| class AttackEvaluate: | |||
| """ | |||
| Evaluation metrics of attack methods. | |||
| Args: | |||
| inputs (numpy.ndarray): Original samples. | |||
| labels (numpy.ndarray): Original samples' label by one-hot format. | |||
| adv_inputs (numpy.ndarray): Adversarial samples generated from original | |||
| samples. | |||
| adv_preds (numpy.ndarray): Probability of all output classes of | |||
| adversarial examples. | |||
| targeted (bool): If True, it is a targeted attack. If False, it is an | |||
| untargeted attack. Default: False. | |||
| target_label (numpy.ndarray): Targeted classes of adversarial examples, | |||
| which is one dimension whose size is adv_inputs.shape[0]. | |||
| Default: None. | |||
| Raises: | |||
| ValueError: If target_label is None when targeted is True. | |||
| Examples: | |||
| >>> x = np.random.normal(size=(3, 512, 512, 3)) | |||
| >>> adv_x = np.random.normal(size=(3, 512, 512, 3)) | |||
| >>> y = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| >>> [0.1, 0.7, 0.0, 0.2], | |||
| >>> [0.8, 0.1, 0.0, 0.1]]) | |||
| >>> adv_y = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| >>> [0.1, 0.0, 0.8, 0.1], | |||
| >>> [0.0, 0.9, 0.1, 0.0]]) | |||
| >>> attack_eval = AttackEvaluate(x, y, adv_x, adv_y) | |||
| >>> mr = attack_eval.mis_classification_rate() | |||
| """ | |||
| def __init__(self, inputs, labels, adv_inputs, adv_preds, | |||
| targeted=False, target_label=None): | |||
| self._inputs, self._labels = check_pair_numpy_param('inputs', | |||
| inputs, | |||
| 'labels', | |||
| labels) | |||
| self._adv_inputs, self._adv_preds = check_pair_numpy_param('adv_inputs', | |||
| adv_inputs, | |||
| 'adv_preds', | |||
| adv_preds) | |||
| targeted = check_param_type('targeted', targeted, bool) | |||
| self._targeted = targeted | |||
| if target_label is not None: | |||
| target_label = check_numpy_param('target_label', target_label) | |||
| self._target_label = target_label | |||
| self._true_label = np.argmax(self._labels, axis=1) | |||
| self._adv_label = np.argmax(self._adv_preds, axis=1) | |||
| idxes = np.arange(self._adv_preds.shape[0]) | |||
| if self._targeted: | |||
| if target_label is None: | |||
| msg = 'targeted attack need target_label, but got None.' | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| self._adv_preds, self._target_label = check_pair_numpy_param('adv_pred', | |||
| self._adv_preds, | |||
| 'target_label', | |||
| target_label) | |||
| self._success_idxes = idxes[self._adv_label == self._target_label] | |||
| else: | |||
| self._success_idxes = idxes[self._adv_label != self._true_label] | |||
| def mis_classification_rate(self): | |||
| """ | |||
| Calculate misclassification rate(MR). | |||
| Returns: | |||
| float, ranges between (0, 1). The higher, the more successful the attack is. | |||
| """ | |||
| return self._success_idxes.shape[0]*1.0 / self._inputs.shape[0] | |||
| def avg_conf_adv_class(self): | |||
| """ | |||
| Calculate average confidence of adversarial class (ACAC). | |||
| Returns: | |||
| float, ranges between (0, 1). The higher, the more successful the attack is. | |||
| """ | |||
| idxes = self._success_idxes | |||
| success_num = idxes.shape[0] | |||
| if success_num == 0: | |||
| return 0 | |||
| if self._targeted: | |||
| return np.mean(self._adv_preds[idxes, self._target_label[idxes]]) | |||
| return np.mean(self._adv_preds[idxes, self._adv_label[idxes]]) | |||
| def avg_conf_true_class(self): | |||
| """ | |||
| Calculate average confidence of true class (ACTC). | |||
| Returns: | |||
| float, ranges between (0, 1). The lower, the more successful the attack is. | |||
| """ | |||
| idxes = self._success_idxes | |||
| success_num = idxes.shape[0] | |||
| if success_num == 0: | |||
| return 0 | |||
| return np.mean(self._adv_preds[idxes, self._true_label[idxes]]) | |||
| def avg_lp_distance(self): | |||
| """ | |||
| Calculate average lp distance (lp-dist). | |||
| Returns: | |||
| - float, return average l0, l2, or linf distance of all success | |||
| adversarial examples, return value includes following cases. | |||
| - If return value :math:`>=` 0, average lp distance. The lower, | |||
| the more successful the attack is. | |||
| - If return value is -1, there is no success adversarial examples. | |||
| """ | |||
| idxes = self._success_idxes | |||
| success_num = idxes.shape[0] | |||
| if success_num == 0: | |||
| return -1, -1, -1 | |||
| l0_dist = 0 | |||
| l2_dist = 0 | |||
| linf_dist = 0 | |||
| avoid_zero_div = 1e-14 | |||
| for i in idxes: | |||
| diff = (self._adv_inputs[i] - self._inputs[i]).flatten() | |||
| data = self._inputs[i].flatten() | |||
| l0_dist += np.linalg.norm(diff, ord=0) \ | |||
| / (np.linalg.norm(data, ord=0) + avoid_zero_div) | |||
| l2_dist += np.linalg.norm(diff, ord=2) \ | |||
| / (np.linalg.norm(data, ord=2) + avoid_zero_div) | |||
| linf_dist += np.linalg.norm(diff, ord=np.inf) \ | |||
| / (np.linalg.norm(data, ord=np.inf) + avoid_zero_div) | |||
| return l0_dist / success_num, l2_dist / success_num, \ | |||
| linf_dist / success_num | |||
| def avg_ssim(self): | |||
| """ | |||
| Calculate average structural similarity (ASS). | |||
| Returns: | |||
| - float, average structural similarity. | |||
| - If return value ranges between (0, 1), the higher, the more | |||
| successful the attack is. | |||
| - If return value is -1: there is no success adversarial examples. | |||
| """ | |||
| success_num = self._success_idxes.shape[0] | |||
| if success_num == 0: | |||
| return -1 | |||
| total_ssim = 0.0 | |||
| for _, i in enumerate(self._success_idxes): | |||
| total_ssim += _compute_ssim(self._adv_inputs[i], self._inputs[i]) | |||
| return total_ssim / success_num | |||
| def nte(self): | |||
| """ | |||
| Calculate noise tolerance estimation (NTE). | |||
| References: `Towards Imperceptible and Robust Adversarial Example Attacks | |||
| against Neural Networks <https://arxiv.org/abs/1801.04693>`_ | |||
| Returns: | |||
| float, ranges between (0, 1). The higher, the more successful the | |||
| attack is. | |||
| """ | |||
| idxes = self._success_idxes | |||
| success_num = idxes.shape[0] | |||
| adv_y = self._adv_preds[idxes] | |||
| adv_y_2 = np.copy(adv_y) | |||
| adv_y_2[range(success_num), np.argmax(adv_y_2, axis=1)] = 0 | |||
| net = np.mean(np.abs(np.max(adv_y_2, axis=1) - np.max(adv_y, axis=1))) | |||
| return net | |||
+ 0
- 0
mindarmour/evaluations/black/__init__.py
View File
+ 204
- 0
mindarmour/evaluations/black/defense_evaluation.py
View File
| @@ -0,0 +1,204 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Evaluating Defense against Black-box Attacks. | |||
| """ | |||
| import numpy as np | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_pair_numpy_param, \ | |||
| check_equal_length, check_int_positive, check_numpy_param | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'BlackDefenseEvaluate' | |||
| class BlackDefenseEvaluate: | |||
| """ | |||
| Evaluation metrics of anti-black-box defense method. | |||
| Args: | |||
| raw_preds (numpy.ndarray): Predict results of some certain samples on | |||
| raw model. | |||
| def_preds (numpy.ndarray): Predict results of some certain samples on | |||
| defensed model. | |||
| raw_query_counts (numpy.ndarray): Number of queries to generate | |||
| adversarial examples on raw model, which is one dimensional whose | |||
| size is raw_preds.shape[0]. For benign samples, query count must be | |||
| set to 0. | |||
| def_query_counts (numpy.ndarray): Number of queries to generate | |||
| adversarial examples on defensed model, which is one dimensional | |||
| whose size is raw_preds.shape[0]. | |||
| For benign samples, query count must be set to 0. | |||
| raw_query_time (numpy.ndarray): The total time duration to generate | |||
| an adversarial example on raw model, which is one dimensional | |||
| whose size is raw_preds.shape[0]. | |||
| def_query_time (numpy.ndarray): The total time duration to generate an | |||
| adversarial example on defensed model, which is one dimensional | |||
| whose size is raw_preds.shape[0]. | |||
| def_detection_counts (numpy.ndarray): Total number of detected queries | |||
| during each adversarial example generation, which is one dimensional | |||
| whose size is raw_preds.shape[0]. For a benign sample, the | |||
| def_detection_counts is set to 1 if the query is identified as | |||
| suspicious, and 0 otherwise. | |||
| true_labels (numpy.ndarray): True labels in one-dim whose size is | |||
| raw_preds.shape[0]. | |||
| max_queries (int): Attack budget, the maximum number of queries. | |||
| Examples: | |||
| >>> raw_preds = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| >>> [0.1, 0.7, 0.0, 0.2], | |||
| >>> [0.8, 0.1, 0.0, 0.1]]) | |||
| >>> def_preds = np.array([[0.1, 0.1, 0.1, 0.7], | |||
| >>> [0.1, 0.6, 0.2, 0.1], | |||
| >>> [0.1, 0.2, 0.1, 0.6]]) | |||
| >>> raw_query_counts = np.array([0,20,10]) | |||
| >>> def_query_counts = np.array([0,50,60]) | |||
| >>> raw_query_time = np.array([0.1, 2, 1]) | |||
| >>> def_query_time = np.array([0.2, 6, 5]) | |||
| >>> def_detection_counts = np.array([1, 5, 10]) | |||
| >>> true_labels = np.array([3, 1, 0]) | |||
| >>> max_queries = 100 | |||
| >>> def_eval = BlackDefenseEvaluat(raw_preds, | |||
| >>> def_preds, | |||
| >>> raw_query_counts, | |||
| >>> def_query_counts, | |||
| >>> raw_query_time, | |||
| >>> def_query_time, | |||
| >>> def_detection_counts, | |||
| >>> true_labels, | |||
| >>> max_queries) | |||
| >>> def_eval.qcv() | |||
| """ | |||
| def __init__(self, raw_preds, def_preds, raw_query_counts, def_query_counts, | |||
| raw_query_time, def_query_time, def_detection_counts, | |||
| true_labels, max_queries): | |||
| self._raw_preds, self._def_preds = check_pair_numpy_param('raw_preds', | |||
| raw_preds, | |||
| 'def_preds', | |||
| def_preds) | |||
| self._num_samples = self._raw_preds.shape[0] | |||
| self._raw_query_counts, _ = check_equal_length('raw_query_counts', | |||
| raw_query_counts, | |||
| 'number of sample', | |||
| self._raw_preds) | |||
| self._def_query_counts, _ = check_equal_length('def_query_counts', | |||
| def_query_counts, | |||
| 'number of sample', | |||
| self._raw_preds) | |||
| self._raw_query_time, _ = check_equal_length('raw_query_time', | |||
| raw_query_time, | |||
| 'number of sample', | |||
| self._raw_preds) | |||
| self._def_query_time, _ = check_equal_length('def_query_time', | |||
| def_query_time, | |||
| 'number of sample', | |||
| self._raw_preds) | |||
| self._num_adv_samples = self._raw_query_counts[ | |||
| self._raw_query_counts > 0].shape[0] | |||
| self._num_adv_samples = check_int_positive( | |||
| 'the number of adversarial samples', | |||
| self._num_adv_samples) | |||
| self._num_ben_samples = self._num_samples - self._num_adv_samples | |||
| self._max_queries = check_int_positive('max_queries', max_queries) | |||
| self._def_detection_counts = check_numpy_param('def_detection_counts', | |||
| def_detection_counts) | |||
| self._true_labels = check_numpy_param('true_labels', true_labels) | |||
| def qcv(self): | |||
| """ | |||
| Calculate query count variance (QCV). | |||
| Returns: | |||
| float, the higher, the stronger the defense is. If num_adv_samples=0, | |||
| return -1. | |||
| """ | |||
| if self._num_adv_samples == 0: | |||
| return -1 | |||
| avg_def_query_count = \ | |||
| np.sum(self._def_query_counts) / self._num_adv_samples | |||
| avg_raw_query_count = \ | |||
| np.sum(self._raw_query_counts) / self._num_adv_samples | |||
| if (avg_def_query_count == self._max_queries) \ | |||
| and (avg_raw_query_count < self._max_queries): | |||
| query_variance = 1 | |||
| else: | |||
| query_variance = \ | |||
| min(avg_def_query_count - avg_raw_query_count, | |||
| self._max_queries) / self._max_queries | |||
| return query_variance | |||
| def asv(self): | |||
| """ | |||
| Calculate attack success rate variance (ASV). | |||
| Returns: | |||
| float, the lower, the stronger the defense is. If num_adv_samples=0, | |||
| return -1. | |||
| """ | |||
| adv_def_preds = self._def_preds[self._def_query_counts > 0] | |||
| adv_raw_preds = self._raw_preds[self._raw_query_counts > 0] | |||
| adv_true_labels = self._true_labels[self._raw_query_counts > 0] | |||
| def_succ_num = np.sum(np.argmax(adv_def_preds, axis=1) | |||
| != adv_true_labels) | |||
| raw_succ_num = np.sum(np.argmax(adv_raw_preds, axis=1) | |||
| != adv_true_labels) | |||
| if self._num_adv_samples == 0: | |||
| return -1 | |||
| return (raw_succ_num - def_succ_num) / self._num_adv_samples | |||
| def fpr(self): | |||
| """ | |||
| Calculate false positive rate (FPR) of the query-based detector. | |||
| Returns: | |||
| float, the lower, the higher usability the defense is. If | |||
| num_adv_samples=0, return -1. | |||
| """ | |||
| ben_detect_counts = \ | |||
| self._def_detection_counts[self._def_query_counts == 0] | |||
| num_fp = ben_detect_counts[ben_detect_counts > 0].shape[0] | |||
| if self._num_ben_samples == 0: | |||
| return -1 | |||
| return num_fp / self._num_ben_samples | |||
| def qrv(self): | |||
| """ | |||
| Calculate the benign query response time variance (QRV). | |||
| Returns: | |||
| float, the lower, the higher usability the defense is. If | |||
| num_adv_samples=0, return -1. | |||
| """ | |||
| if self._num_ben_samples == 0: | |||
| return -1 | |||
| raw_num_queries = self._num_ben_samples | |||
| def_num_queries = self._num_ben_samples | |||
| ben_raw_query_time = self._raw_query_time[self._raw_query_counts == 0] | |||
| ben_def_query_time = self._def_query_time[self._def_query_counts == 0] | |||
| avg_raw_query_time = np.sum(ben_raw_query_time) / raw_num_queries | |||
| avg_def_query_time = np.sum(ben_def_query_time) / def_num_queries | |||
| return (avg_def_query_time - | |||
| avg_raw_query_time) / (avg_raw_query_time + 1e-12) | |||
+ 152
- 0
mindarmour/evaluations/defense_evaluation.py
View File
| @@ -0,0 +1,152 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Defense Evaluation. | |||
| """ | |||
| import numpy as np | |||
| import scipy.stats as st | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_numpy_param | |||
| from mindarmour.utils._check_param import check_pair_numpy_param | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'DefenseEvaluate' | |||
| class DefenseEvaluate: | |||
| """ | |||
| Evaluation metrics of defense methods. | |||
| Args: | |||
| raw_preds (numpy.ndarray): Prediction results of some certain samples | |||
| on raw model. | |||
| def_preds (numpy.ndarray): Prediction results of some certain samples on | |||
| defensed model. | |||
| true_labels (numpy.ndarray): Ground-truth labels of samples, a | |||
| one-dimension array whose size is raw_preds.shape[0]. | |||
| Examples: | |||
| >>> raw_preds = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| >>> [0.1, 0.7, 0.0, 0.2], | |||
| >>> [0.8, 0.1, 0.0, 0.1]]) | |||
| >>> def_preds = np.array([[0.1, 0.1, 0.1, 0.7], | |||
| >>> [0.1, 0.6, 0.2, 0.1], | |||
| >>> [0.1, 0.2, 0.1, 0.6]]) | |||
| >>> true_labels = np.array([3, 1, 0]) | |||
| >>> def_eval = DefenseEvaluate(raw_preds, | |||
| >>> def_preds, | |||
| >>> true_labels) | |||
| >>> def_eval.cav() | |||
| """ | |||
| def __init__(self, raw_preds, def_preds, true_labels): | |||
| self._raw_preds, self._def_preds = check_pair_numpy_param('raw_preds', | |||
| raw_preds, | |||
| 'def_preds', | |||
| def_preds) | |||
| self._true_labels = check_numpy_param('true_labels', true_labels) | |||
| self._num_samples = len(true_labels) | |||
| def cav(self): | |||
| """ | |||
| Calculate classification accuracy variance (CAV). | |||
| Returns: | |||
| float, the higher, the more successful the defense is. | |||
| """ | |||
| def_succ_num = np.sum(np.argmax(self._def_preds, axis=1) | |||
| == self._true_labels) | |||
| raw_succ_num = np.sum(np.argmax(self._raw_preds, axis=1) | |||
| == self._true_labels) | |||
| return (def_succ_num - raw_succ_num) / self._num_samples | |||
| def crr(self): | |||
| """ | |||
| Calculate classification rectify ratio (CRR). | |||
| Returns: | |||
| float, the higher, the more successful the defense is. | |||
| """ | |||
| cond1 = np.argmax(self._def_preds, axis=1) == self._true_labels | |||
| cond2 = np.argmax(self._raw_preds, axis=1) != self._true_labels | |||
| rectify_num = np.sum(cond1*cond2) | |||
| return rectify_num*1.0 / self._num_samples | |||
| def csr(self): | |||
| """ | |||
| Calculate classification sacrifice ratio (CSR), the lower the better. | |||
| Returns: | |||
| float, the lower, the more successful the defense is. | |||
| """ | |||
| cond1 = np.argmax(self._def_preds, axis=1) != self._true_labels | |||
| cond2 = np.argmax(self._raw_preds, axis=1) == self._true_labels | |||
| sacrifice_num = np.sum(cond1*cond2) | |||
| return sacrifice_num*1.0 / self._num_samples | |||
| def ccv(self): | |||
| """ | |||
| Calculate classification confidence variance (CCV). | |||
| Returns: | |||
| - float, the lower, the more successful the defense is. | |||
| - If return value == -1, len(idxes) == 0. | |||
| """ | |||
| idxes = np.arange(self._num_samples) | |||
| cond1 = np.argmax(self._def_preds, axis=1) == self._true_labels | |||
| cond2 = np.argmax(self._raw_preds, axis=1) == self._true_labels | |||
| idxes = idxes[cond1*cond2] | |||
| def_max = np.max(self._def_preds, axis=1) | |||
| raw_max = np.max(self._raw_preds, axis=1) | |||
| if idxes.shape[0] == 0: | |||
| return -1 | |||
| conf_variance = np.mean(np.abs(def_max[idxes] - raw_max[idxes])) | |||
| return conf_variance | |||
| def cos(self): | |||
| """ | |||
| References: `Calculate classification output stability (COS) | |||
| <https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence>`_ | |||
| Returns: | |||
| float. | |||
| - If return value >= 0, is effective defense. The lower, the | |||
| more successful the defense. | |||
| - If return value == -1, idxes == 0. | |||
| """ | |||
| idxes = np.arange(self._num_samples) | |||
| cond1 = np.argmax(self._def_preds, axis=1) == self._true_labels | |||
| cond2 = np.argmax(self._raw_preds, axis=1) == self._true_labels | |||
| idxes = idxes[cond1*cond2] | |||
| if idxes.size == 0: | |||
| return -1 | |||
| def_preds = self._def_preds[idxes] | |||
| raw_preds = self._raw_preds[idxes] | |||
| js_total = 0.0 | |||
| mean_value = 0.5*(def_preds + raw_preds) | |||
| for i, value in enumerate(mean_value): | |||
| js_total += 0.5*st.entropy(def_preds[i], value) \ | |||
| + 0.5*st.entropy(raw_preds[i], value) | |||
| return js_total / len(idxes) | |||
+ 141
- 0
mindarmour/evaluations/visual_metrics.py
View File
| @@ -0,0 +1,141 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Radar map. | |||
| """ | |||
| from math import pi | |||
| import numpy as np | |||
| import matplotlib.pyplot as plt | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.utils._check_param import check_param_type, check_numpy_param, \ | |||
| check_param_multi_types, check_equal_length | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'RadarMetric' | |||
| class RadarMetric: | |||
| """ | |||
| Radar chart to show the robustness of a model by multiple metrics. | |||
| Args: | |||
| metrics_name (Union[tuple, list]): An array of names of metrics to show. | |||
| metrics_data (numpy.ndarray): The (normalized) values of each metrics of | |||
| multiple radar curves, like [[0.5, 0.8, ...], [0.2,0.6,...], ...]. | |||
| Each set of values corresponds to one radar curve. | |||
| labels (Union[tuple, list]): Legends of all radar curves. | |||
| title (str): Title of the chart. | |||
| scale (str): Scalar to adjust axis ticks, such as 'hide', 'norm', | |||
| 'sparse' or 'dense'. Default: 'hide'. | |||
| Raises: | |||
| ValueError: If scale not in ['hide', 'norm', 'sparse', 'dense']. | |||
| Examples: | |||
| >>> metrics_name = ['MR', 'ACAC', 'ASS', 'NTE', 'ACTC'] | |||
| >>> def_metrics = [0.9, 0.85, 0.6, 0.7, 0.8] | |||
| >>> raw_metrics = [0.5, 0.3, 0.55, 0.65, 0.7] | |||
| >>> metrics_data = [def_metrics, raw_metrics] | |||
| >>> metrics_labels = ['before', 'after'] | |||
| >>> rm = RadarMetric(metrics_name, | |||
| >>> metrics_data, | |||
| >>> metrics_labels, | |||
| >>> title='', | |||
| >>> scale='sparse') | |||
| >>> rm.show() | |||
| """ | |||
| def __init__(self, metrics_name, metrics_data, labels, title, scale='hide'): | |||
| self._metrics_name = check_param_multi_types('metrics_name', | |||
| metrics_name, | |||
| [tuple, list]) | |||
| self._metrics_data = check_numpy_param('metrics_data', metrics_data) | |||
| self._labels = check_param_multi_types('labels', labels, (tuple, list)) | |||
| _, _ = check_equal_length('metrics_name', metrics_name, | |||
| 'metrics_data', self._metrics_data[0]) | |||
| _, _ = check_equal_length('labels', labels, 'metrics_data', metrics_data) | |||
| self._title = check_param_type('title', title, str) | |||
| if scale in ['hide', 'norm', 'sparse', 'dense']: | |||
| self._scale = scale | |||
| else: | |||
| msg = "scale must be in ['hide', 'norm', 'sparse', 'dense'], but " \ | |||
| "got {}".format(scale) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| self._nb_var = len(metrics_name) | |||
| # divide the plot / number of variable | |||
| self._angles = [n / self._nb_var*2.0*pi for n in | |||
| range(self._nb_var)] | |||
| self._angles += self._angles[:1] | |||
| # add one more point | |||
| data = [self._metrics_data, self._metrics_data[:, [0]]] | |||
| self._metrics_data = np.concatenate(data, axis=1) | |||
| def show(self): | |||
| """ | |||
| Show the radar chart. | |||
| """ | |||
| # Initialise the spider plot | |||
| plt.clf() | |||
| axis_pic = plt.subplot(111, polar=True) | |||
| axis_pic.spines['polar'].set_visible(False) | |||
| axis_pic.set_yticklabels([]) | |||
| # If you want the first axis to be on top: | |||
| axis_pic.set_theta_offset(pi / 2) | |||
| axis_pic.set_theta_direction(-1) | |||
| # Draw one axe per variable + add labels labels yet | |||
| plt.xticks(self._angles[:-1], self._metrics_name) | |||
| # Draw y labels | |||
| axis_pic.set_rlabel_position(0) | |||
| if self._scale == 'hide': | |||
| plt.yticks([0.0], color="grey", size=7) | |||
| elif self._scale == 'norm': | |||
| plt.yticks([0.2, 0.4, 0.6, 0.8], | |||
| ["0.2", "0.4", "0.6", "0.8"], | |||
| color="grey", size=7) | |||
| elif self._scale == 'sparse': | |||
| plt.yticks([0.5], ["0.5"], color="grey", size=7) | |||
| elif self._scale == 'dense': | |||
| ticks = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] | |||
| labels = ["0.1", "0.2", "0.3", "0.4", "0.5", "0.6", | |||
| "0.7", "0.8", "0.9"] | |||
| plt.yticks(ticks, labels, color="grey", size=7) | |||
| else: | |||
| # default | |||
| plt.yticks([0.0], color="grey", size=7) | |||
| plt.ylim(0, 1) | |||
| # plot border | |||
| axis_pic.plot(self._angles, [1]*(self._nb_var + 1), color='grey', | |||
| linewidth=1, linestyle='solid') | |||
| for i in range(len(self._labels)): | |||
| axis_pic.plot(self._angles, self._metrics_data[i], linewidth=1, | |||
| linestyle='solid', label=self._labels[i]) | |||
| axis_pic.fill(self._angles, self._metrics_data[i], alpha=0.1) | |||
| # Add legend | |||
| plt.legend(loc='upper right', bbox_to_anchor=(0., 0.)) | |||
| plt.title(self._title, y=1.1, color='g') | |||
| plt.show() | |||
+ 7
- 0
mindarmour/utils/__init__.py
View File
| @@ -0,0 +1,7 @@ | |||
| """ | |||
| Util methods of MindArmour.""" | |||
| from .logger import LogUtil | |||
| from .util import GradWrap | |||
| from .util import GradWrapWithLoss | |||
| __all__ = ['LogUtil', 'GradWrapWithLoss', 'GradWrap'] | |||
+ 269
- 0
mindarmour/utils/_check_param.py
View File
| @@ -0,0 +1,269 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ check parameters for MindArmour. """ | |||
| import numpy as np | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'check parameters' | |||
| def _check_array_not_empty(arg_name, arg_value): | |||
| """Check parameter is empty or not.""" | |||
| if isinstance(arg_value, (tuple, list)): | |||
| if not arg_value: | |||
| msg = '{} must not be empty'.format(arg_name) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| if isinstance(arg_value, np.ndarray): | |||
| if arg_value.size <= 0: | |||
| msg = '{} must not be empty'.format(arg_name) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_param_type(arg_name, arg_value, valid_type): | |||
| """Check parameter type.""" | |||
| if not isinstance(arg_value, valid_type): | |||
| msg = '{} must be {}, but got {}'.format(arg_name, | |||
| valid_type, | |||
| type(arg_value).__name__) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_param_multi_types(arg_name, arg_value, valid_types): | |||
| """Check parameter type.""" | |||
| if not isinstance(arg_value, tuple(valid_types)): | |||
| msg = 'type of {} must be in {}, but got {}' \ | |||
| .format(arg_name, valid_types, type(arg_value).__name__) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_int_positive(arg_name, arg_value): | |||
| """Check positive integer.""" | |||
| arg_value = check_param_type(arg_name, arg_value, int) | |||
| if arg_value <= 0: | |||
| msg = '{} must be greater than 0, but got {}'.format(arg_name, | |||
| arg_value) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_value_non_negative(arg_name, arg_value): | |||
| """Check non negative value.""" | |||
| arg_value = check_param_multi_types(arg_name, arg_value, (int, float)) | |||
| if float(arg_value) < 0.0: | |||
| msg = '{} must not be less than 0, but got {}'.format(arg_name, | |||
| arg_value) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_value_positive(arg_name, arg_value): | |||
| """Check positive value.""" | |||
| arg_value = check_param_multi_types(arg_name, arg_value, (int, float)) | |||
| if float(arg_value) <= 0.0: | |||
| msg = '{} must be greater than zero, but got {}'.format(arg_name, | |||
| arg_value) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_param_in_range(arg_name, arg_value, lower, upper): | |||
| """ | |||
| Check range of parameter. | |||
| """ | |||
| if arg_value <= lower or arg_value >= upper: | |||
| msg = '{} must be between {} and {}, but got {}'.format(arg_name, | |||
| lower, | |||
| upper, | |||
| arg_value) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_model(model_name, model, model_type): | |||
| """ | |||
| Check the type of input `model` . | |||
| Args: | |||
| model_name (str): Name of model. | |||
| model (Object): Model object. | |||
| model_type (Class): Class of model. | |||
| Returns: | |||
| Object, if the type of `model` is `model_type`, return `model` itself. | |||
| Raises: | |||
| ValueError: If model is not an instance of `model_type` . | |||
| """ | |||
| if isinstance(model, model_type): | |||
| return model | |||
| msg = '{} should be an instance of {}, but got {}' \ | |||
| .format(model_name, | |||
| model_type, | |||
| type(model).__name__) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| def check_numpy_param(arg_name, arg_value): | |||
| """ | |||
| None-check and Numpy-check for `value` . | |||
| Args: | |||
| arg_name (str): Name of parameter. | |||
| arg_value (Union[list, tuple, numpy.ndarray]): Value for check. | |||
| Returns: | |||
| numpy.ndarray, if `value` is not empty, return `value` with type of | |||
| numpy.ndarray. | |||
| Raises: | |||
| ValueError: If value is empty. | |||
| ValueError: If value type is not in (list, tuple, numpy.ndarray). | |||
| """ | |||
| _ = _check_array_not_empty(arg_name, arg_value) | |||
| if isinstance(arg_value, (list, tuple)): | |||
| arg_value = np.asarray(arg_value) | |||
| elif isinstance(arg_value, np.ndarray): | |||
| arg_value = np.copy(arg_value) | |||
| else: | |||
| msg = 'type of {} must be in (list, tuple, numpy.ndarray)'.format( | |||
| arg_name) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return arg_value | |||
| def check_pair_numpy_param(inputs_name, inputs, labels_name, labels): | |||
| """ | |||
| Dimension-equivalence check for `inputs` and `labels`. | |||
| Args: | |||
| inputs_name (str): Name of inputs. | |||
| inputs (Union[list, tuple, numpy.ndarray]): Inputs. | |||
| labels_name (str): Name of labels. | |||
| labels (Union[list, tuple, numpy.ndarray]): Labels of `inputs`. | |||
| Returns: | |||
| - Union[list, tuple, numpy.ndarray], if `inputs` 's dimension equals to | |||
| `labels`, return inputs with type of numpy.ndarray. | |||
| - Union[list, tuple, numpy.ndarray], if `inputs` 's dimension equals to | |||
| `labels` , return labels with type of numpy.ndarray. | |||
| Raises: | |||
| ValueError: If inputs.shape[0] is not equal to labels.shape[0]. | |||
| """ | |||
| inputs = check_numpy_param(inputs_name, inputs) | |||
| labels = check_numpy_param(labels_name, labels) | |||
| if inputs.shape[0] != labels.shape[0]: | |||
| msg = '{} shape[0] must equal {} shape[0], bot got shape of ' \ | |||
| 'inputs {}, shape of labels {}'.format(inputs_name, labels_name, | |||
| inputs.shape, labels.shape) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return inputs, labels | |||
| def check_equal_length(para_name1, value1, para_name2, value2): | |||
| """check weather the two parameters have equal length.""" | |||
| if len(value1) != len(value2): | |||
| msg = 'The dimension of {0} must equal to the ' \ | |||
| '{1}, but got {0} is {2}, ' \ | |||
| '{1} is {3}'.format(para_name1, para_name2, len(value1), | |||
| len(value2)) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return value1, value2 | |||
| def check_equal_shape(para_name1, value1, para_name2, value2): | |||
| """check weather the two parameters have equal shape.""" | |||
| if value1.shape != value2.shape: | |||
| msg = 'The shape of {0} must equal to the ' \ | |||
| '{1}, but got {0} is {2}, ' \ | |||
| '{1} is {3}'.format(para_name1, para_name2, value1.shape[0], | |||
| value2.shape[0]) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return value1, value2 | |||
| def check_norm_level(norm_level): | |||
| """ | |||
| check norm_level of regularization. | |||
| """ | |||
| accept_norm = [1, 2, '1', '2', 'l1', 'l2', 'inf', 'linf', np.inf] | |||
| if norm_level not in accept_norm: | |||
| msg = 'norm_level must be in {}, but got {}'.format(accept_norm, | |||
| norm_level) | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| return norm_level | |||
| def normalize_value(value, norm_level): | |||
| """ | |||
| Normalize gradients for gradient attacks. | |||
| Args: | |||
| value (numpy.ndarray): Inputs. | |||
| norm_level (Union[int, str]): Normalized level. | |||
| Returns: | |||
| numpy.ndarray, normalized value. | |||
| Raises: | |||
| NotImplementedError: If norm_level is not in [1, 2 , np.inf, '1', '2', | |||
| 'inf] | |||
| """ | |||
| norm_level = check_norm_level(norm_level) | |||
| ori_shape = value.shape | |||
| value_reshape = value.reshape((value.shape[0], -1)) | |||
| avoid_zero_div = 1e-12 | |||
| if norm_level in (1, '1', 'l1'): | |||
| norm = np.linalg.norm(value_reshape, ord=1, axis=1, keepdims=True) + \ | |||
| avoid_zero_div | |||
| norm_value = value_reshape / norm | |||
| elif norm_level in (2, '2', 'l2'): | |||
| norm = np.linalg.norm(value_reshape, ord=2, axis=1, keepdims=True) + \ | |||
| avoid_zero_div | |||
| norm_value = value_reshape / norm | |||
| elif norm_level in (np.inf, 'inf'): | |||
| norm = np.max(abs(value_reshape), axis=1, keepdims=True) + \ | |||
| avoid_zero_div | |||
| norm_value = value_reshape / norm | |||
| else: | |||
| msg = 'Values of `norm_level` different from 1, 2 and ' \ | |||
| '`np.inf` are currently not supported, but got {}.' \ | |||
| .format(norm_level) | |||
| LOGGER.error(TAG, msg) | |||
| raise NotImplementedError(msg) | |||
| return norm_value.reshape(ori_shape) | |||
+ 154
- 0
mindarmour/utils/logger.py
View File
| @@ -0,0 +1,154 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ Util for log module. """ | |||
| import logging | |||
| _LOGGER = logging.getLogger('MA') | |||
| def _find_caller(): | |||
| """ | |||
| Bind findCaller() method, which is used to find the stack frame of the | |||
| caller so that we can note the source file name, line number and | |||
| function name. | |||
| """ | |||
| return _LOGGER.findCaller() | |||
| class LogUtil: | |||
| """ | |||
| Logging module. | |||
| Raises: | |||
| SyntaxError: If create this class. | |||
| """ | |||
| _instance = None | |||
| _logger = None | |||
| _extra_fmt = ' [%s] [%s] ' | |||
| def __init__(self): | |||
| raise SyntaxError('can not instance, please use get_instance.') | |||
| @staticmethod | |||
| def get_instance(): | |||
| """ | |||
| Get instance of class `LogUtil`. | |||
| Returns: | |||
| Object, instance of class `LogUtil`. | |||
| """ | |||
| if LogUtil._instance is None: | |||
| LogUtil._instance = object.__new__(LogUtil) | |||
| LogUtil._logger = _LOGGER | |||
| LogUtil._init_logger() | |||
| return LogUtil._instance | |||
| @staticmethod | |||
| def _init_logger(): | |||
| """ | |||
| Initialize logger. | |||
| """ | |||
| LogUtil._logger.setLevel(logging.WARNING) | |||
| log_fmt = '[%(levelname)s] %(name)s(%(process)d:%(thread)d,' \ | |||
| '%(processName)s):%(asctime)s%(message)s' | |||
| log_fmt = logging.Formatter(log_fmt) | |||
| # create console handler with a higher log level | |||
| console_handler = logging.StreamHandler() | |||
| console_handler.setFormatter(log_fmt) | |||
| # add the handlers to the logger | |||
| LogUtil._logger.handlers = [] | |||
| LogUtil._logger.addHandler(console_handler) | |||
| LogUtil._logger.propagate = False | |||
| def set_level(self, level): | |||
| """ | |||
| Set the logging level of this logger, level must be an integer or a | |||
| string. | |||
| Args: | |||
| level (Union[int, str]): Level of logger. | |||
| """ | |||
| self._logger.setLevel(level) | |||
| def add_handler(self, handler): | |||
| """ | |||
| Add other handler supported by logging module. | |||
| Args: | |||
| handler (logging.Handler): Other handler supported by logging module. | |||
| Raises: | |||
| ValueError: If handler is not an instance of logging.Handler. | |||
| """ | |||
| if isinstance(handler, logging.Handler): | |||
| self._logger.addHandler(handler) | |||
| else: | |||
| raise ValueError('handler must be an instance of logging.Handler,' | |||
| ' but got {}'.format(type(handler))) | |||
| def debug(self, tag, msg, *args): | |||
| """ | |||
| Log '[tag] msg % args' with severity 'DEBUG'. | |||
| Args: | |||
| tag (str): Logger tag. | |||
| msg (str): Logger message. | |||
| args (Any): Auxiliary value. | |||
| """ | |||
| caller_info = _find_caller() | |||
| file_info = ':'.join([caller_info[0], str(caller_info[1])]) | |||
| self._logger.debug(self._extra_fmt + msg, file_info, tag, *args) | |||
| def info(self, tag, msg, *args): | |||
| """ | |||
| Log '[tag] msg % args' with severity 'INFO'. | |||
| Args: | |||
| tag (str): Logger tag. | |||
| msg (str): Logger message. | |||
| args (Any): Auxiliary value. | |||
| """ | |||
| caller_info = _find_caller() | |||
| file_info = ':'.join([caller_info[0], str(caller_info[1])]) | |||
| self._logger.info(self._extra_fmt + msg, file_info, tag, *args) | |||
| def warn(self, tag, msg, *args): | |||
| """ | |||
| Log '[tag] msg % args' with severity 'WARNING'. | |||
| Args: | |||
| tag (str): Logger tag. | |||
| msg (str): Logger message. | |||
| args (Any): Auxiliary value. | |||
| """ | |||
| caller_info = _find_caller() | |||
| file_info = ':'.join([caller_info[0], str(caller_info[1])]) | |||
| self._logger.warning(self._extra_fmt + msg, file_info, tag, *args) | |||
| def error(self, tag, msg, *args): | |||
| """ | |||
| Log '[tag] msg % args' with severity 'ERROR'. | |||
| Args: | |||
| tag (str): Logger tag. | |||
| msg (str): Logger message. | |||
| args (Any): Auxiliary value. | |||
| """ | |||
| caller_info = _find_caller() | |||
| file_info = ':'.join([caller_info[0], str(caller_info[1])]) | |||
| self._logger.error(self._extra_fmt + msg, file_info, tag, *args) | |||
+ 147
- 0
mindarmour/utils/util.py
View File
| @@ -0,0 +1,147 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ Util for MindArmour. """ | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.composite import GradOperation | |||
| from mindarmour.utils.logger import LogUtil | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'util' | |||
| def jacobian_matrix(grad_wrap_net, inputs, num_classes): | |||
| """ | |||
| Calculate the Jacobian matrix for inputs. | |||
| Args: | |||
| grad_wrap_net (Cell): A network wrapped by GradWrap. | |||
| inputs (numpy.ndarray): Input samples. | |||
| num_classes (int): Number of labels of model output. | |||
| Returns: | |||
| numpy.ndarray, the Jacobian matrix of inputs. (labels, batch_size, ...) | |||
| Raises: | |||
| ValueError: If grad_wrap_net is not a instance of class `GradWrap`. | |||
| """ | |||
| if not isinstance(grad_wrap_net, GradWrap): | |||
| msg = 'grad_wrap_net be and instance of class `GradWrap`.' | |||
| LOGGER.error(TAG, msg) | |||
| raise ValueError(msg) | |||
| grad_wrap_net.set_train() | |||
| grads_matrix = [] | |||
| for idx in range(num_classes): | |||
| sens = np.zeros((inputs.shape[0], num_classes)).astype(np.float32) | |||
| sens[:, idx] = 1.0 | |||
| grads = grad_wrap_net(Tensor(inputs), Tensor(sens)) | |||
| grads_matrix.append(grads.asnumpy()) | |||
| return np.asarray(grads_matrix) | |||
| class WithLossCell(Cell): | |||
| """ | |||
| Wrap the network with loss function. | |||
| Args: | |||
| network (Cell): The target network to wrap. | |||
| loss_fn (Function): The loss function is used for computing loss. | |||
| Examples: | |||
| >>> data = Tensor(np.ones([1, 1, 32, 32]).astype(np.float32)*0.01) | |||
| >>> label = Tensor(np.ones([1, 10]).astype(np.float32)) | |||
| >>> net = NET() | |||
| >>> loss_fn = nn.SoftmaxCrossEntropyWithLogits() | |||
| >>> loss_net = WithLossCell(net, loss_fn) | |||
| >>> loss_out = loss_net(data, label) | |||
| """ | |||
| def __init__(self, network, loss_fn): | |||
| super(WithLossCell, self).__init__() | |||
| self._network = network | |||
| self._loss_fn = loss_fn | |||
| def construct(self, data, label): | |||
| """ | |||
| Compute loss based on the wrapped loss cell. | |||
| Args: | |||
| data (Tensor): Tensor data to train. | |||
| label (Tensor): Tensor label data. | |||
| Returns: | |||
| Tensor, compute result. | |||
| """ | |||
| out = self._network(data) | |||
| return self._loss_fn(out, label) | |||
| class GradWrapWithLoss(Cell): | |||
| """ | |||
| Construct a network to compute the gradient of loss function in input space | |||
| and weighted by `weight`. | |||
| """ | |||
| def __init__(self, network): | |||
| super(GradWrapWithLoss, self).__init__() | |||
| self._grad_all = GradOperation(name="get_all", | |||
| get_all=True, | |||
| sens_param=True) | |||
| self._network = network | |||
| def construct(self, inputs, labels, weight): | |||
| """ | |||
| Compute gradient of `inputs` with labels and weight. | |||
| Args: | |||
| inputs (Tensor): Inputs of network. | |||
| labels (Tensor): Labels of inputs. | |||
| weight (Tensor): Weight of each gradient, `weight` has the same | |||
| shape with labels. | |||
| Returns: | |||
| Tensor, gradient matrix. | |||
| """ | |||
| gout = self._grad_all(self._network)(inputs, labels, weight) | |||
| return gout[0] | |||
| class GradWrap(Cell): | |||
| """ | |||
| Construct a network to compute the gradient of network outputs in input | |||
| space and weighted by `weight`, expressed as a jacobian matrix. | |||
| """ | |||
| def __init__(self, network): | |||
| super(GradWrap, self).__init__() | |||
| self.grad = GradOperation(name="grad", get_all=False, | |||
| sens_param=True) | |||
| self.network = network | |||
| def construct(self, inputs, weight): | |||
| """ | |||
| Compute jacobian matrix. | |||
| Args: | |||
| inputs (Tensor): Inputs of network. | |||
| weight (Tensor): Weight of each gradient, `weight` has the same | |||
| shape with labels. | |||
| Returns: | |||
| Tensor, Jacobian matrix. | |||
| """ | |||
| gout = self.grad(self.network)(inputs, weight) | |||
| return gout | |||
+ 38
- 0
package.sh
View File
| @@ -0,0 +1,38 @@ | |||
| #!/bin/bash | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| set -e | |||
| BASEPATH=$(cd "$(dirname $0)"; pwd) | |||
| OUTPUT_PATH="${BASEPATH}/output" | |||
| PYTHON=$(which python3) | |||
| mk_new_dir() { | |||
| local create_dir="$1" # the target to make | |||
| if [[ -d "${create_dir}" ]];then | |||
| rm -rf "${create_dir}" | |||
| fi | |||
| mkdir -pv "${create_dir}" | |||
| } | |||
| mk_new_dir "${OUTPUT_PATH}" | |||
| ${PYTHON} ${BASEPATH}/setup.py bdist_wheel | |||
| mv ${BASEPATH}/dist/*whl ${OUTPUT_PATH} | |||
| echo "------Successfully created mindarmour package------" | |||
+ 7
- 0
requirements.txt
View File
| @@ -0,0 +1,7 @@ | |||
| numpy >= 1.17.0 | |||
| scipy >= 1.3.3 | |||
| matplotlib >= 3.1.3 | |||
| pytest >= 4.3.1 | |||
| wheel >= 0.32.0 | |||
| setuptools >= 40.8.0 | |||
| mindspore | |||
+ 102
- 0
setup.py
View File
| @@ -0,0 +1,102 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import os | |||
| import stat | |||
| from setuptools import find_packages | |||
| from setuptools import setup | |||
| from setuptools.command.egg_info import egg_info | |||
| from setuptools.command.build_py import build_py | |||
| version = '0.1.0' | |||
| cur_dir = os.path.dirname(os.path.realpath(__file__)) | |||
| pkg_dir = os.path.join(cur_dir, 'build') | |||
| try: | |||
| from wheel.bdist_wheel import bdist_wheel as _bdist_wheel | |||
| class bdist_wheel(_bdist_wheel): | |||
| def finalize_options(self): | |||
| _bdist_wheel.finalize_options(self) | |||
| self.root_is_pure = False | |||
| except ImportError: | |||
| bdist_wheel = None | |||
| def write_version(file): | |||
| file.write("__version__ = '{}'\n".format(version)) | |||
| def build_depends(): | |||
| """generate python file""" | |||
| version_file = os.path.join(cur_dir, 'mindarmour/', 'version.py') | |||
| with open(version_file, 'w') as f: | |||
| write_version(f) | |||
| build_depends() | |||
| def update_permissions(path): | |||
| """ | |||
| Update permissions. | |||
| Args: | |||
| path (str): Target directory path. | |||
| """ | |||
| for dirpath, dirnames, filenames in os.walk(path): | |||
| for dirname in dirnames: | |||
| dir_fullpath = os.path.join(dirpath, dirname) | |||
| os.chmod(dir_fullpath, stat.S_IREAD | stat.S_IWRITE | stat.S_IEXEC | stat.S_IRGRP | stat.S_IXGRP) | |||
| for filename in filenames: | |||
| file_fullpath = os.path.join(dirpath, filename) | |||
| os.chmod(file_fullpath, stat.S_IREAD) | |||
| class EggInfo(egg_info): | |||
| """Egg info.""" | |||
| def run(self): | |||
| super().run() | |||
| egg_info_dir = os.path.join(cur_dir, 'mindarmour.egg-info') | |||
| update_permissions(egg_info_dir) | |||
| class BuildPy(build_py): | |||
| """BuildPy.""" | |||
| def run(self): | |||
| super().run() | |||
| mindarmour_dir = os.path.join(pkg_dir, 'lib', 'mindarmour') | |||
| update_permissions(mindarmour_dir) | |||
| setup( | |||
| name='mindarmour', | |||
| version='0.1.0', | |||
| description="A smart AI security and trustworthy tool box.", | |||
| packages=find_packages(), | |||
| include_package_data=True, | |||
| zip_safe=False, | |||
| cmdclass={ | |||
| 'egg_info': EggInfo, | |||
| 'build_py': BuildPy, | |||
| 'bdist_wheel': bdist_wheel | |||
| }, | |||
| install_requires=[ | |||
| 'scipy >= 1.3.3', | |||
| 'numpy >= 1.17.0', | |||
| 'matplotlib >= 3.1.3', | |||
| 'mindspore' | |||
| ], | |||
| ) | |||
| print(find_packages()) | |||
+ 311
- 0
tests/st/resnet50/resnet_cifar10.py
View File
| @@ -0,0 +1,311 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import numpy as np | |||
| import math | |||
| from mindspore import nn | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| from mindspore import context | |||
| def variance_scaling_raw(shape): | |||
| value = np.random.normal(size=shape).astype(np.float32) | |||
| return Tensor(value) | |||
| def weight_variable(shape): | |||
| value = np.random.normal(size=shape).astype(np.float32) | |||
| return Tensor(value) | |||
| def sweight_variable(shape): | |||
| value = np.random.uniform(size=shape).astype(np.float32) | |||
| return Tensor(value) | |||
| def weight_variable_0(shape): | |||
| zeros = np.zeros(shape).astype(np.float32) | |||
| return Tensor(zeros) | |||
| def weight_variable_1(shape): | |||
| ones = np.ones(shape).astype(np.float32) | |||
| return Tensor(ones) | |||
| def conv3x3(in_channels, out_channels, stride=1, padding=0): | |||
| """3x3 convolution """ | |||
| weight_shape = (out_channels, in_channels, 3, 3) | |||
| weight = variance_scaling_raw(weight_shape) | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=3, stride=stride, padding=padding, weight_init=weight, has_bias=False, pad_mode="same") | |||
| def conv1x1(in_channels, out_channels, stride=1, padding=0): | |||
| """1x1 convolution""" | |||
| weight_shape = (out_channels, in_channels, 1, 1) | |||
| weight = variance_scaling_raw(weight_shape) | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=1, stride=stride, padding=padding, weight_init=weight, has_bias=False, pad_mode="same") | |||
| def conv7x7(in_channels, out_channels, stride=1, padding=0): | |||
| """1x1 convolution""" | |||
| weight_shape = (out_channels, in_channels, 7, 7) | |||
| weight = variance_scaling_raw(weight_shape) | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=7, stride=stride, padding=padding, weight_init=weight, has_bias=False, pad_mode="same") | |||
| def bn_with_initialize(out_channels): | |||
| shape = (out_channels) | |||
| mean = weight_variable_0(shape) | |||
| var = weight_variable_1(shape) | |||
| beta = weight_variable_0(shape) | |||
| gamma = sweight_variable(shape) | |||
| bn = nn.BatchNorm2d(out_channels, momentum=0.99, eps=0.00001, gamma_init=gamma, | |||
| beta_init=beta, moving_mean_init=mean, moving_var_init=var) | |||
| return bn | |||
| def bn_with_initialize_last(out_channels): | |||
| shape = (out_channels) | |||
| mean = weight_variable_0(shape) | |||
| var = weight_variable_1(shape) | |||
| beta = weight_variable_0(shape) | |||
| gamma = sweight_variable(shape) | |||
| bn = nn.BatchNorm2d(out_channels, momentum=0.99, eps=0.00001, gamma_init=gamma, | |||
| beta_init=beta, moving_mean_init=mean, moving_var_init=var) | |||
| return bn | |||
| def fc_with_initialize(input_channels, out_channels): | |||
| weight_shape = (out_channels, input_channels) | |||
| weight = np.random.normal(size=weight_shape).astype(np.float32) | |||
| weight = Tensor(weight) | |||
| bias_shape = (out_channels) | |||
| bias_value = np.random.uniform(size=bias_shape).astype(np.float32) | |||
| bias = Tensor(bias_value) | |||
| return nn.Dense(input_channels, out_channels, weight, bias) | |||
| class ResidualBlock(nn.Cell): | |||
| expansion = 4 | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| stride=1, | |||
| down_sample=False): | |||
| super(ResidualBlock, self).__init__() | |||
| out_chls = out_channels // self.expansion | |||
| self.conv1 = conv1x1(in_channels, out_chls, stride=stride, padding=0) | |||
| self.bn1 = bn_with_initialize(out_chls) | |||
| self.conv2 = conv3x3(out_chls, out_chls, stride=1, padding=0) | |||
| self.bn2 = bn_with_initialize(out_chls) | |||
| self.conv3 = conv1x1(out_chls, out_channels, stride=1, padding=0) | |||
| self.bn3 = bn_with_initialize_last(out_channels) | |||
| self.relu = P.ReLU() | |||
| self.add = P.TensorAdd() | |||
| def construct(self, x): | |||
| identity = x | |||
| out = self.conv1(x) | |||
| out = self.bn1(out) | |||
| out = self.relu(out) | |||
| out = self.conv2(out) | |||
| out = self.bn2(out) | |||
| out = self.relu(out) | |||
| out = self.conv3(out) | |||
| out = self.bn3(out) | |||
| out = self.add(out, identity) | |||
| out = self.relu(out) | |||
| return out | |||
| class ResidualBlockWithDown(nn.Cell): | |||
| expansion = 4 | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| stride=1, | |||
| down_sample=False): | |||
| super(ResidualBlockWithDown, self).__init__() | |||
| out_chls = out_channels // self.expansion | |||
| self.conv1 = conv1x1(in_channels, out_chls, stride=stride, padding=0) | |||
| self.bn1 = bn_with_initialize(out_chls) | |||
| self.conv2 = conv3x3(out_chls, out_chls, stride=1, padding=0) | |||
| self.bn2 = bn_with_initialize(out_chls) | |||
| self.conv3 = conv1x1(out_chls, out_channels, stride=1, padding=0) | |||
| self.bn3 = bn_with_initialize_last(out_channels) | |||
| self.relu = P.ReLU() | |||
| self.downSample = down_sample | |||
| self.conv_down_sample = conv1x1(in_channels, out_channels, stride=stride, padding=0) | |||
| self.bn_down_sample = bn_with_initialize(out_channels) | |||
| self.add = P.TensorAdd() | |||
| def construct(self, x): | |||
| identity = x | |||
| out = self.conv1(x) | |||
| out = self.bn1(out) | |||
| out = self.relu(out) | |||
| out = self.conv2(out) | |||
| out = self.bn2(out) | |||
| out = self.relu(out) | |||
| out = self.conv3(out) | |||
| out = self.bn3(out) | |||
| identity = self.conv_down_sample(identity) | |||
| identity = self.bn_down_sample(identity) | |||
| out = self.add(out, identity) | |||
| out = self.relu(out) | |||
| return out | |||
| class MakeLayer0(nn.Cell): | |||
| def __init__(self, block, layer_num, in_channels, out_channels, stride): | |||
| super(MakeLayer0, self).__init__() | |||
| self.a = ResidualBlockWithDown(in_channels, out_channels, stride=1, down_sample=True) | |||
| self.b = block(out_channels, out_channels, stride=stride) | |||
| self.c = block(out_channels, out_channels, stride=1) | |||
| def construct(self, x): | |||
| x = self.a(x) | |||
| x = self.b(x) | |||
| x = self.c(x) | |||
| return x | |||
| class MakeLayer1(nn.Cell): | |||
| def __init__(self, block, layer_num, in_channels, out_channels, stride): | |||
| super(MakeLayer1, self).__init__() | |||
| self.a = ResidualBlockWithDown(in_channels, out_channels, stride=stride, down_sample=True) | |||
| self.b = block(out_channels, out_channels, stride=1) | |||
| self.c = block(out_channels, out_channels, stride=1) | |||
| self.d = block(out_channels, out_channels, stride=1) | |||
| def construct(self, x): | |||
| x = self.a(x) | |||
| x = self.b(x) | |||
| x = self.c(x) | |||
| x = self.d(x) | |||
| return x | |||
| class MakeLayer2(nn.Cell): | |||
| def __init__(self, block, layer_num, in_channels, out_channels, stride): | |||
| super(MakeLayer2, self).__init__() | |||
| self.a = ResidualBlockWithDown(in_channels, out_channels, stride=stride, down_sample=True) | |||
| self.b = block(out_channels, out_channels, stride=1) | |||
| self.c = block(out_channels, out_channels, stride=1) | |||
| self.d = block(out_channels, out_channels, stride=1) | |||
| self.e = block(out_channels, out_channels, stride=1) | |||
| self.f = block(out_channels, out_channels, stride=1) | |||
| def construct(self, x): | |||
| x = self.a(x) | |||
| x = self.b(x) | |||
| x = self.c(x) | |||
| x = self.d(x) | |||
| x = self.e(x) | |||
| x = self.f(x) | |||
| return x | |||
| class MakeLayer3(nn.Cell): | |||
| def __init__(self, block, layer_num, in_channels, out_channels, stride): | |||
| super(MakeLayer3, self).__init__() | |||
| self.a = ResidualBlockWithDown(in_channels, out_channels, stride=stride, down_sample=True) | |||
| self.b = block(out_channels, out_channels, stride=1) | |||
| self.c = block(out_channels, out_channels, stride=1) | |||
| def construct(self, x): | |||
| x = self.a(x) | |||
| x = self.b(x) | |||
| x = self.c(x) | |||
| return x | |||
| class ResNet(nn.Cell): | |||
| def __init__(self, block, layer_num, num_classes=100): | |||
| super(ResNet, self).__init__() | |||
| self.num_classes = num_classes | |||
| self.conv1 = conv7x7(3, 64, stride=2, padding=0) | |||
| self.bn1 = bn_with_initialize(64) | |||
| self.relu = P.ReLU() | |||
| self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same") | |||
| self.layer1 = MakeLayer0(block, layer_num[0], in_channels=64, out_channels=256, stride=1) | |||
| self.layer2 = MakeLayer1(block, layer_num[1], in_channels=256, out_channels=512, stride=2) | |||
| self.layer3 = MakeLayer2(block, layer_num[2], in_channels=512, out_channels=1024, stride=2) | |||
| self.layer4 = MakeLayer3(block, layer_num[3], in_channels=1024, out_channels=2048, stride=2) | |||
| self.pool = P.ReduceMean(keep_dims=True) | |||
| self.squeeze = P.Squeeze(axis=(2, 3)) | |||
| self.fc = fc_with_initialize(512*block.expansion, num_classes) | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| x = self.bn1(x) | |||
| x = self.relu(x) | |||
| x = self.maxpool(x) | |||
| x = self.layer1(x) | |||
| x = self.layer2(x) | |||
| x = self.layer3(x) | |||
| x = self.layer4(x) | |||
| x = self.pool(x, (2, 3)) | |||
| x = self.squeeze(x) | |||
| x = self.fc(x) | |||
| return x | |||
| def resnet50_cifar10(num_classes): | |||
| return ResNet(ResidualBlock, [3, 4, 6, 3], num_classes) | |||
+ 76
- 0
tests/st/resnet50/test_cifar10_attack_fgsm.py
View File
| @@ -0,0 +1,76 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Fuction: | |||
| Test fgsm attack about resnet50 network | |||
| Usage: | |||
| py.test test_cifar10_attack_fgsm.py | |||
| """ | |||
| import os | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.nn import Cell | |||
| from mindspore.common import dtype as mstype | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import functional as F | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from resnet_cifar10 import resnet50_cifar10 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| class CrossEntropyLoss(Cell): | |||
| def __init__(self): | |||
| super(CrossEntropyLoss, self).__init__() | |||
| self.cross_entropy = P.SoftmaxCrossEntropyWithLogits() | |||
| self.mean = P.ReduceMean() | |||
| self.one_hot = P.OneHot() | |||
| self.on_value = Tensor(1.0, mstype.float32) | |||
| self.off_value = Tensor(0.0, mstype.float32) | |||
| def construct(self, logits, label): | |||
| label = self.one_hot(label, F.shape(logits)[1], self.on_value, self.off_value) | |||
| loss = self.cross_entropy(logits, label)[0] | |||
| loss = self.mean(loss, (-1,)) | |||
| return loss | |||
| @pytest.mark.level0 | |||
| @pytest.mark.env_single | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.platform_x86_ascend_inference | |||
| def test_fast_gradient_sign_method(): | |||
| """ | |||
| FGSM-Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| # get network | |||
| net = resnet50_cifar10(10) | |||
| # create test data | |||
| test_images = np.random.rand(64, 3, 224, 224).astype(np.float32) | |||
| test_labels = np.random.randint(10, size=64).astype(np.int32) | |||
| # attacking | |||
| loss_fn = CrossEntropyLoss() | |||
| attack = FastGradientSignMethod(net, eps=0.1, loss_fn=loss_fn) | |||
| adv_data = attack.batch_generate(test_images, test_labels, batch_size=32) | |||
| assert np.any(adv_data != test_images) | |||
+ 144
- 0
tests/ut/python/attacks/black/test_genetic_attack.py
View File
| @@ -0,0 +1,144 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Genetic-Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as M | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindarmour.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for user | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| class SimpleNet(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = SimpleNet() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(SimpleNet, self).__init__() | |||
| self._softmax = M.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._softmax(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_genetic_attack(): | |||
| """ | |||
| Genetic_Attack test | |||
| """ | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = GeneticAttack(model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| _, adv_data, _ = attack.generate(inputs, labels) | |||
| assert np.any(inputs != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_supplement(): | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = GeneticAttack(model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| adaptive=True, | |||
| sparse=False) | |||
| # raise error | |||
| _, adv_data, _ = attack.generate(inputs, labels) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| """test that exception is raised for invalid labels""" | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| # labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = GeneticAttack(model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| adaptive=True, | |||
| sparse=False) | |||
| # raise error | |||
| with pytest.raises(ValueError) as e: | |||
| assert attack.generate(inputs, labels) | |||
+ 166
- 0
tests/ut/python/attacks/black/test_hsja.py
View File
| @@ -0,0 +1,166 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import os | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.hop_skip_jump_attack import HopSkipJumpAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), | |||
| "../../../../../")) | |||
| from example.mnist_demo.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'HopSkipJumpAttack' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| if len(inputs.shape) == 3: | |||
| inputs = inputs[np.newaxis, :] | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| def random_target_labels(true_labels): | |||
| target_labels = [] | |||
| for label in true_labels: | |||
| while True: | |||
| target_label = np.random.randint(0, 10) | |||
| if target_label != label: | |||
| target_labels.append(target_label) | |||
| break | |||
| return target_labels | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| # public variable | |||
| def get_model(): | |||
| # upload trained network | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| ckpt_name = os.path.join(current_dir, | |||
| '../../test_data/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt') | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| model = ModelToBeAttacked(net) | |||
| return model | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_hsja_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| # get test data | |||
| test_images_set = np.load(os.path.join(current_dir, | |||
| '../../test_data/test_images.npy')) | |||
| test_labels_set = np.load(os.path.join(current_dir, | |||
| '../../test_data/test_labels.npy')) | |||
| # prediction accuracy before attack | |||
| model = get_model() | |||
| batch_num = 1 # the number of batches of attacking samples | |||
| predict_labels = [] | |||
| i = 0 | |||
| for img in test_images_set: | |||
| i += 1 | |||
| pred_labels = np.argmax(model.predict(img), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = test_labels_set[:batch_num] | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", | |||
| accuracy) | |||
| test_images = test_images_set[:batch_num] | |||
| # attacking | |||
| norm = 'l2' | |||
| search = 'grid_search' | |||
| target = False | |||
| attack = HopSkipJumpAttack(model, constraint=norm, stepsize_search=search) | |||
| if target: | |||
| target_labels = random_target_labels(true_labels) | |||
| target_images = create_target_images(test_images_set, test_labels_set, | |||
| target_labels) | |||
| LOGGER.info(TAG, 'len target labels : %s', len(target_labels)) | |||
| LOGGER.info(TAG, 'len target_images : %s', len(target_images)) | |||
| LOGGER.info(TAG, 'len test_images : %s', len(test_images)) | |||
| attack.set_target_images(target_images) | |||
| success_list, adv_data, _ = attack.generate(test_images, target_labels) | |||
| else: | |||
| success_list, adv_data, query_list = attack.generate(test_images, None) | |||
| assert (adv_data != test_images).any() | |||
| adv_datas = [] | |||
| gts = [] | |||
| for success, adv, gt in zip(success_list, adv_data, true_labels): | |||
| if success: | |||
| adv_datas.append(adv) | |||
| gts.append(gt) | |||
| if len(gts) > 0: | |||
| adv_datas = np.concatenate(np.asarray(adv_datas), axis=0) | |||
| gts = np.asarray(gts) | |||
| pred_logits_adv = model.predict(adv_datas) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, gts)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| accuracy_adv) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| model = get_model() | |||
| norm = 'l2' | |||
| with pytest.raises(ValueError) as e: | |||
| assert HopSkipJumpAttack(model, constraint=norm, stepsize_search='bad-search') | |||
+ 217
- 0
tests/ut/python/attacks/black/test_nes.py
View File
| @@ -0,0 +1,217 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import os | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.natural_evolutionary_strategy import NES | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), | |||
| "../../../../../")) | |||
| from example.mnist_demo.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'HopSkipJumpAttack' | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| if len(inputs.shape) == 3: | |||
| inputs = inputs[np.newaxis, :] | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| def random_target_labels(true_labels): | |||
| target_labels = [] | |||
| for label in true_labels: | |||
| while True: | |||
| target_label = np.random.randint(0, 10) | |||
| if target_label != label: | |||
| target_labels.append(target_label) | |||
| break | |||
| return target_labels | |||
| def _pseudorandom_target(index, total_indices, true_class): | |||
| """ pseudo random_target """ | |||
| rng = np.random.RandomState(index) | |||
| target = true_class | |||
| while target == true_class: | |||
| target = rng.randint(0, total_indices) | |||
| return target | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| def get_model(current_dir): | |||
| ckpt_name = os.path.join(current_dir, | |||
| '../../test_data/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt') | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| model = ModelToBeAttacked(net) | |||
| return model | |||
| def get_dataset(current_dir): | |||
| # upload trained network | |||
| # get test data | |||
| test_images = np.load(os.path.join(current_dir, | |||
| '../../test_data/test_images.npy')) | |||
| test_labels = np.load(os.path.join(current_dir, | |||
| '../../test_data/test_labels.npy')) | |||
| return test_images, test_labels | |||
| def nes_mnist_attack(scene, top_k): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| test_images, test_labels = get_dataset(current_dir) | |||
| model = get_model(current_dir) | |||
| # prediction accuracy before attack | |||
| batch_num = 5 # the number of batches of attacking samples | |||
| predict_labels = [] | |||
| i = 0 | |||
| for img in test_images: | |||
| i += 1 | |||
| pred_labels = np.argmax(model.predict(img), axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = test_labels | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels[:batch_num])) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", | |||
| accuracy) | |||
| test_images = test_images | |||
| # attacking | |||
| if scene == 'Query_Limit': | |||
| top_k = -1 | |||
| elif scene == 'Partial_Info': | |||
| top_k = top_k | |||
| elif scene == 'Label_Only': | |||
| top_k = top_k | |||
| success = 0 | |||
| queries_num = 0 | |||
| nes_instance = NES(model, scene, top_k=top_k) | |||
| test_length = 1 | |||
| advs = [] | |||
| for img_index in range(test_length): | |||
| # INITIAL IMAGE AND CLASS SELECTION | |||
| initial_img = test_images[img_index] | |||
| orig_class = true_labels[img_index] | |||
| initial_img = [initial_img] | |||
| target_class = random_target_labels([orig_class]) | |||
| target_image = create_target_images(test_images, true_labels, | |||
| target_class) | |||
| nes_instance.set_target_images(target_image) | |||
| tag, adv, queries = nes_instance.generate(initial_img, target_class) | |||
| if tag[0]: | |||
| success += 1 | |||
| queries_num += queries[0] | |||
| advs.append(adv) | |||
| advs = np.reshape(advs, (len(advs), 1, 32, 32)) | |||
| assert (advs != test_images[:batch_num]).any() | |||
| adv_pred = np.argmax(model.predict(advs), axis=1) | |||
| adv_accuracy = np.mean(np.equal(adv_pred, true_labels[:test_length])) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nes_query_limit(): | |||
| # scene is in ['Query_Limit', 'Partial_Info', 'Label_Only'] | |||
| scene = 'Query_Limit' | |||
| nes_mnist_attack(scene, top_k=-1) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nes_partial_info(): | |||
| # scene is in ['Query_Limit', 'Partial_Info', 'Label_Only'] | |||
| scene = 'Partial_Info' | |||
| nes_mnist_attack(scene, top_k=5) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nes_label_only(): | |||
| # scene is in ['Query_Limit', 'Partial_Info', 'Label_Only'] | |||
| scene = 'Label_Only' | |||
| nes_mnist_attack(scene, top_k=5) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| """test that exception is raised for invalid labels""" | |||
| with pytest.raises(ValueError): | |||
| assert nes_mnist_attack('Label_Only', -1) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_none(): | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| model = get_model(current_dir) | |||
| test_images, test_labels = get_dataset(current_dir) | |||
| nes = NES(model, 'Partial_Info') | |||
| with pytest.raises(ValueError): | |||
| assert nes.generate(test_images, test_labels) | |||
+ 90
- 0
tests/ut/python/attacks/black/test_pointwise_attack.py
View File
| @@ -0,0 +1,90 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| PointWise Attack test | |||
| """ | |||
| import sys | |||
| import os | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.black.pointwise_attack import PointWiseAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), | |||
| "../../../../../")) | |||
| from example.mnist_demo.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Pointwise_Test' | |||
| LOGGER.set_level('INFO') | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pointwise_attack_method(): | |||
| """ | |||
| Pointwise attack method unit test. | |||
| """ | |||
| np.random.seed(123) | |||
| # upload trained network | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| ckpt_name = os.path.join(current_dir, | |||
| '../../test_data/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt') | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get one mnist image | |||
| input_np = np.load(os.path.join(current_dir, | |||
| '../../test_data/test_images.npy'))[:3] | |||
| labels = np.load(os.path.join(current_dir, | |||
| '../../test_data/test_labels.npy'))[:3] | |||
| model = ModelToBeAttacked(net) | |||
| pre_label = np.argmax(model.predict(input_np), axis=1) | |||
| LOGGER.info(TAG, 'original sample predict labels are :{}'.format(pre_label)) | |||
| LOGGER.info(TAG, 'true labels are: {}'.format(labels)) | |||
| attack = PointWiseAttack(model, sparse=True, is_targeted=False) | |||
| is_adv, adv_data, query_times = attack.generate(input_np, pre_label) | |||
| LOGGER.info(TAG, 'adv sample predict labels are: {}' | |||
| .format(np.argmax(model.predict(adv_data), axis=1))) | |||
| assert np.any(adv_data[is_adv][0] != input_np[is_adv][0]), 'Pointwise attack method: ' \ | |||
| 'generate value must not be equal' \ | |||
| ' to original value.' | |||
+ 166
- 0
tests/ut/python/attacks/black/test_pso_attack.py
View File
| @@ -0,0 +1,166 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| PSO-Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| import mindspore.nn as nn | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| # for user | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| class SimpleNet(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = SimpleNet() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(SimpleNet, self).__init__() | |||
| self._relu = nn.ReLU() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._relu(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack(): | |||
| """ | |||
| PSO_Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = PSOAttack(model, bounds=(0.0, 1.0), pm=0.5, sparse=False) | |||
| _, adv_data, _ = attack.generate(inputs, labels) | |||
| assert np.any(inputs != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack_targeted(): | |||
| """ | |||
| PSO_Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = PSOAttack(model, bounds=(0.0, 1.0), pm=0.5, targeted=True, | |||
| sparse=False) | |||
| _, adv_data, _ = attack.generate(inputs, labels) | |||
| assert np.any(inputs != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_x86_gpu_inference | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack_gpu(): | |||
| """ | |||
| PSO_Attack test | |||
| """ | |||
| context.set_context(device_target="GPU") | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = PSOAttack(model, bounds=(0.0, 1.0), pm=0.5, sparse=False) | |||
| _, adv_data, _ = attack.generate(inputs, labels) | |||
| assert np.any(inputs != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_x86_cpu | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack_cpu(): | |||
| """ | |||
| PSO_Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| batch_size = 6 | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = PSOAttack(model, bounds=(0.0, 1.0), pm=0.5, sparse=False) | |||
| _, adv_data, _ = attack.generate(inputs, labels) | |||
| assert np.any(inputs != adv_data) | |||
+ 123
- 0
tests/ut/python/attacks/black/test_salt_and_pepper_attack.py
View File
| @@ -0,0 +1,123 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| SaltAndPepper Attack Test | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as M | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindarmour.attacks.black.salt_and_pepper_attack import \ | |||
| SaltAndPepperNoiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| # for user | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| # for user | |||
| class SimpleNet(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = SimpleNet() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(SimpleNet, self).__init__() | |||
| self._softmax = M.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._softmax(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_salt_and_pepper_attack_method(): | |||
| """ | |||
| Salt and pepper attack method unit test. | |||
| """ | |||
| batch_size = 6 | |||
| np.random.seed(123) | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = SaltAndPepperNoiseAttack(model, sparse=False) | |||
| is_adv, adv_data, query_times = attack.generate(inputs, labels) | |||
| assert np.any(adv_data[0] != inputs[0]), 'Salt and pepper attack method: ' \ | |||
| 'generate value must not be equal' \ | |||
| ' to original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_salt_and_pepper_attack_in_batch(): | |||
| """ | |||
| Salt and pepper attack method unit test in batch. | |||
| """ | |||
| batch_size = 32 | |||
| np.random.seed(123) | |||
| net = SimpleNet() | |||
| inputs = np.random.rand(batch_size*2, 10) | |||
| model = ModelToBeAttacked(net) | |||
| labels = np.random.randint(low=0, high=10, size=batch_size*2) | |||
| labels = np.eye(10)[labels] | |||
| labels = labels.astype(np.float32) | |||
| attack = SaltAndPepperNoiseAttack(model, sparse=False) | |||
| adv_data = attack.batch_generate(inputs, labels, batch_size=32) | |||
| assert np.any(adv_data[0] != inputs[0]), 'Salt and pepper attack method: ' \ | |||
| 'generate value must not be equal' \ | |||
| ' to original value.' | |||
+ 74
- 0
tests/ut/python/attacks/test_batch_generate_attack.py
View File
| @@ -0,0 +1,74 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Batch-generate-attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as P | |||
| from mindspore.nn import Cell | |||
| import mindspore.context as context | |||
| from mindarmour.attacks.gradient_method import FastGradientMethod | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for user | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = Net() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(Net, self).__init__() | |||
| self._softmax = P.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._softmax(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_batch_generate_attack(): | |||
| """ | |||
| Attack with batch-generate. | |||
| """ | |||
| input_np = np.random.random((128, 10)).astype(np.float32) | |||
| label = np.random.randint(0, 10, 128).astype(np.int32) | |||
| label = np.eye(10)[label].astype(np.float32) | |||
| attack = FastGradientMethod(Net()) | |||
| ms_adv_x = attack.batch_generate(input_np, label, batch_size=32) | |||
| assert np.any(ms_adv_x != input_np), 'Fast gradient method: generate value' \ | |||
| ' must not be equal to original value.' | |||
+ 90
- 0
tests/ut/python/attacks/test_cw.py
View File
| @@ -0,0 +1,90 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| CW-Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as M | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindarmour.attacks.carlini_wagner import CarliniWagnerL2Attack | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for user | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = Net() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(Net, self).__init__() | |||
| self._softmax = M.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._softmax(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_cw_attack(): | |||
| """ | |||
| CW-Attack test | |||
| """ | |||
| net = Net() | |||
| input_np = np.array([[0.1, 0.2, 0.7, 0.5, 0.4]]).astype(np.float32) | |||
| label_np = np.array([3]).astype(np.int64) | |||
| num_classes = input_np.shape[1] | |||
| attack = CarliniWagnerL2Attack(net, num_classes, targeted=False) | |||
| adv_data = attack.generate(input_np, label_np) | |||
| assert np.any(input_np != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_cw_attack_targeted(): | |||
| """ | |||
| CW-Attack test | |||
| """ | |||
| net = Net() | |||
| input_np = np.array([[0.1, 0.2, 0.7, 0.5, 0.4]]).astype(np.float32) | |||
| target_np = np.array([1]).astype(np.int64) | |||
| num_classes = input_np.shape[1] | |||
| attack = CarliniWagnerL2Attack(net, num_classes, targeted=True) | |||
| adv_data = attack.generate(input_np, target_np) | |||
| assert np.any(input_np != adv_data) | |||
+ 119
- 0
tests/ut/python/attacks/test_deep_fool.py
View File
| @@ -0,0 +1,119 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| DeepFool-Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as M | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindarmour.attacks.deep_fool import DeepFool | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for user | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = Net() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(Net, self).__init__() | |||
| self._softmax = M.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._softmax(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_deepfool_attack(): | |||
| """ | |||
| Deepfool-Attack test | |||
| """ | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| _, classes = input_shape | |||
| input_np = np.array([[0.1, 0.2, 0.7, 0.5, 0.4]]).astype(np.float32) | |||
| input_me = Tensor(input_np) | |||
| true_labels = np.argmax(net(input_me).asnumpy(), axis=1) | |||
| attack = DeepFool(net, classes, max_iters=10, norm_level=2, | |||
| bounds=(0.0, 1.0)) | |||
| adv_data = attack.generate(input_np, true_labels) | |||
| # expected adv value | |||
| expect_value = np.asarray([[0.10300991, 0.20332647, 0.59308802, 0.59651263, | |||
| 0.40406296]]) | |||
| assert np.allclose(adv_data, expect_value), 'mindspore deepfool_method' \ | |||
| ' implementation error, ms_adv_x != expect_value' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_deepfool_attack_inf(): | |||
| """ | |||
| Deepfool-Attack test | |||
| """ | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| _, classes = input_shape | |||
| input_np = np.array([[0.1, 0.2, 0.7, 0.5, 0.4]]).astype(np.float32) | |||
| input_me = Tensor(input_np) | |||
| true_labels = np.argmax(net(input_me).asnumpy(), axis=1) | |||
| attack = DeepFool(net, classes, max_iters=10, norm_level=np.inf, | |||
| bounds=(0.0, 1.0)) | |||
| adv_data = attack.generate(input_np, true_labels) | |||
| assert np.any(input_np != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| _, classes = input_shape | |||
| input_np = np.array([[0.1, 0.2, 0.7, 0.5, 0.4]]).astype(np.float32) | |||
| input_me = Tensor(input_np) | |||
| true_labels = np.argmax(net(input_me).asnumpy(), axis=1) | |||
| with pytest.raises(NotImplementedError): | |||
| # norm_level=0 is not available | |||
| attack = DeepFool(net, classes, max_iters=10, norm_level=1, | |||
| bounds=(0.0, 1.0)) | |||
| assert attack.generate(input_np, true_labels) | |||
+ 242
- 0
tests/ut/python/attacks/test_gradient_method.py
View File
| @@ -0,0 +1,242 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Gradient-Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.nn as nn | |||
| from mindspore.nn import Cell | |||
| import mindspore.context as context | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.attacks.gradient_method import FastGradientMethod | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from mindarmour.attacks.gradient_method import LeastLikelyClassMethod | |||
| from mindarmour.attacks.gradient_method import RandomFastGradientMethod | |||
| from mindarmour.attacks.gradient_method import RandomFastGradientSignMethod | |||
| from mindarmour.attacks.gradient_method import RandomLeastLikelyClassMethod | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for user | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = Net() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(Net, self).__init__() | |||
| self._relu = nn.ReLU() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._relu(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_method(): | |||
| """ | |||
| Fast gradient method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| attack = FastGradientMethod(Net()) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Fast gradient method: generate value' \ | |||
| ' must not be equal to original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_x86_gpu_inference | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_method_gpu(): | |||
| """ | |||
| Fast gradient method unit test. | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| attack = FastGradientMethod(Net()) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Fast gradient method: generate value' \ | |||
| ' must not be equal to original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_x86_cpu | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_method_cpu(): | |||
| """ | |||
| Fast gradient method unit test. | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=True) | |||
| attack = FastGradientMethod(Net(), loss_fn=loss) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Fast gradient method: generate value' \ | |||
| ' must not be equal to original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_random_fast_gradient_method(): | |||
| """ | |||
| Random fast gradient method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| attack = RandomFastGradientMethod(Net()) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Random fast gradient method: ' \ | |||
| 'generate value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_sign_method(): | |||
| """ | |||
| Fast gradient sign method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| attack = FastGradientSignMethod(Net()) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Fast gradient sign method: generate' \ | |||
| ' value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_random_fast_gradient_sign_method(): | |||
| """ | |||
| Random fast gradient sign method unit test. | |||
| """ | |||
| input_np = np.random.random((1, 28)).astype(np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(28)[label].astype(np.float32) | |||
| attack = RandomFastGradientSignMethod(Net()) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Random fast gradient sign method: ' \ | |||
| 'generate value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_least_likely_class_method(): | |||
| """ | |||
| Least likely class method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| attack = LeastLikelyClassMethod(Net()) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Least likely class method: generate' \ | |||
| ' value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_random_least_likely_class_method(): | |||
| """ | |||
| Random least likely class method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| attack = RandomLeastLikelyClassMethod(Net(), eps=0.1, alpha=0.01) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Random least likely class method: ' \ | |||
| 'generate value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_assert_error(): | |||
| """ | |||
| Random least likely class method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| with pytest.raises(ValueError) as e: | |||
| assert RandomLeastLikelyClassMethod(Net(), eps=0.05, alpha=0.21) | |||
| assert str(e.value) == 'eps must be larger than alpha!' | |||
+ 136
- 0
tests/ut/python/attacks/test_iterative_gradient_method.py
View File
| @@ -0,0 +1,136 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Iterative-gradient Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore.ops import operations as P | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindarmour.attacks import BasicIterativeMethod | |||
| from mindarmour.attacks import MomentumIterativeMethod | |||
| from mindarmour.attacks import ProjectedGradientDescent | |||
| from mindarmour.attacks import IterativeGradientMethod | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for user | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = Net() | |||
| """ | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| self._softmax = P.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._softmax(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_basic_iterative_method(): | |||
| """ | |||
| Basic iterative method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| for i in range(5): | |||
| net = Net() | |||
| attack = BasicIterativeMethod(net, nb_iter=i + 1) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any( | |||
| ms_adv_x != input_np), 'Basic iterative method: generate value' \ | |||
| ' must not be equal to original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_momentum_iterative_method(): | |||
| """ | |||
| Momentum iterative method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| for i in range(5): | |||
| attack = MomentumIterativeMethod(Net(), nb_iter=i + 1) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any(ms_adv_x != input_np), 'Basic iterative method: generate' \ | |||
| ' value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_projected_gradient_descent_method(): | |||
| """ | |||
| Projected gradient descent method unit test. | |||
| """ | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| for i in range(5): | |||
| attack = ProjectedGradientDescent(Net(), nb_iter=i + 1) | |||
| ms_adv_x = attack.generate(input_np, label) | |||
| assert np.any( | |||
| ms_adv_x != input_np), 'Projected gradient descent method: ' \ | |||
| 'generate value must not be equal to' \ | |||
| ' original value.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_error(): | |||
| with pytest.raises(ValueError): | |||
| # check_param_multi_types | |||
| assert IterativeGradientMethod(Net(), bounds=None) | |||
| attack = IterativeGradientMethod(Net(), bounds=(0.0, 1.0)) | |||
| with pytest.raises(NotImplementedError): | |||
| input_np = np.asarray([[0.1, 0.2, 0.7]], np.float32) | |||
| label = np.asarray([2], np.int32) | |||
| label = np.eye(3)[label].astype(np.float32) | |||
| assert attack.generate(input_np, label) | |||
+ 161
- 0
tests/ut/python/attacks/test_jsma.py
View File
| @@ -0,0 +1,161 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| JSMA-Attack test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.nn as nn | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindarmour.attacks.jsma import JSMAAttack | |||
| # for user | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| Examples: | |||
| >>> net = Net() | |||
| """ | |||
| def __init__(self): | |||
| """ | |||
| Introduce the layers used for network construction. | |||
| """ | |||
| super(Net, self).__init__() | |||
| self._relu = nn.ReLU() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| out = self._relu(inputs) | |||
| return out | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| batch_size, classes = input_shape | |||
| np.random.seed(5) | |||
| input_np = np.random.random(input_shape).astype(np.float32) | |||
| label_np = np.random.randint(classes, size=batch_size) | |||
| ori_label = np.argmax(net(Tensor(input_np)).asnumpy(), axis=1) | |||
| for i in range(batch_size): | |||
| if label_np[i] == ori_label[i]: | |||
| if label_np[i] < classes - 1: | |||
| label_np[i] += 1 | |||
| else: | |||
| label_np[i] -= 1 | |||
| attack = JSMAAttack(net, classes, max_iteration=5) | |||
| adv_data = attack.generate(input_np, label_np) | |||
| assert np.any(input_np != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack_2(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| batch_size, classes = input_shape | |||
| np.random.seed(5) | |||
| input_np = np.random.random(input_shape).astype(np.float32) | |||
| label_np = np.random.randint(classes, size=batch_size) | |||
| ori_label = np.argmax(net(Tensor(input_np)).asnumpy(), axis=1) | |||
| for i in range(batch_size): | |||
| if label_np[i] == ori_label[i]: | |||
| if label_np[i] < classes - 1: | |||
| label_np[i] += 1 | |||
| else: | |||
| label_np[i] -= 1 | |||
| attack = JSMAAttack(net, classes, max_iteration=5, increase=False) | |||
| adv_data = attack.generate(input_np, label_np) | |||
| assert np.any(input_np != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_x86_gpu_inference | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack_gpu(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| context.set_context(device_target="GPU") | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| batch_size, classes = input_shape | |||
| np.random.seed(5) | |||
| input_np = np.random.random(input_shape).astype(np.float32) | |||
| label_np = np.random.randint(classes, size=batch_size) | |||
| ori_label = np.argmax(net(Tensor(input_np)).asnumpy(), axis=1) | |||
| for i in range(batch_size): | |||
| if label_np[i] == ori_label[i]: | |||
| if label_np[i] < classes - 1: | |||
| label_np[i] += 1 | |||
| else: | |||
| label_np[i] -= 1 | |||
| attack = JSMAAttack(net, classes, max_iteration=5) | |||
| adv_data = attack.generate(input_np, label_np) | |||
| assert np.any(input_np != adv_data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_x86_cpu | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack_cpu(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| net = Net() | |||
| input_shape = (1, 5) | |||
| batch_size, classes = input_shape | |||
| np.random.seed(5) | |||
| input_np = np.random.random(input_shape).astype(np.float32) | |||
| label_np = np.random.randint(classes, size=batch_size) | |||
| ori_label = np.argmax(net(Tensor(input_np)).asnumpy(), axis=1) | |||
| for i in range(batch_size): | |||
| if label_np[i] == ori_label[i]: | |||
| if label_np[i] < classes - 1: | |||
| label_np[i] += 1 | |||
| else: | |||
| label_np[i] -= 1 | |||
| attack = JSMAAttack(net, classes, max_iteration=5) | |||
| adv_data = attack.generate(input_np, label_np) | |||
| assert np.any(input_np != adv_data) | |||
+ 72
- 0
tests/ut/python/attacks/test_lbfgs.py
View File
| @@ -0,0 +1,72 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| LBFGS-Attack test. | |||
| """ | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| import os | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks.lbfgs import LBFGS | |||
| from mindarmour.utils.logger import LogUtil | |||
| sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), | |||
| "../../../../")) | |||
| from example.mnist_demo.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'LBFGS_Test' | |||
| LOGGER.set_level('DEBUG') | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_lbfgs_attack(): | |||
| """ | |||
| LBFGS-Attack test | |||
| """ | |||
| np.random.seed(123) | |||
| # upload trained network | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| ckpt_name = os.path.join(current_dir, | |||
| '../test_data/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt') | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get one mnist image | |||
| input_np = np.load(os.path.join(current_dir, | |||
| '../test_data/test_images.npy'))[:1] | |||
| label_np = np.load(os.path.join(current_dir, | |||
| '../test_data/test_labels.npy'))[:1] | |||
| LOGGER.debug(TAG, 'true label is :{}'.format(label_np[0])) | |||
| classes = 10 | |||
| target_np = np.random.randint(0, classes, 1) | |||
| while target_np == label_np[0]: | |||
| target_np = np.random.randint(0, classes) | |||
| target_np = np.eye(10)[target_np].astype(np.float32) | |||
| attack = LBFGS(net, is_targeted=True) | |||
| LOGGER.debug(TAG, 'target_np is :{}'.format(target_np[0])) | |||
| adv_data = attack.generate(input_np, target_np) | |||
+ 107
- 0
tests/ut/python/defenses/mock_net.py
View File
| @@ -0,0 +1,107 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| mocked model for UT of defense algorithms. | |||
| """ | |||
| import numpy as np | |||
| from mindspore import nn | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.nn import WithLossCell, TrainOneStepCell | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindspore.ops import operations as P | |||
| from mindspore import context | |||
| from mindspore.common.initializer import TruncatedNormal | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| def conv(in_channels, out_channels, kernel_size, stride=1, padding=0): | |||
| weight = weight_variable() | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=kernel_size, stride=stride, padding=padding, | |||
| weight_init=weight, has_bias=False, pad_mode="valid") | |||
| def fc_with_initialize(input_channels, out_channels): | |||
| weight = weight_variable() | |||
| bias = weight_variable() | |||
| return nn.Dense(input_channels, out_channels, weight, bias) | |||
| def weight_variable(): | |||
| return TruncatedNormal(0.02) | |||
| class Net(nn.Cell): | |||
| """ | |||
| Lenet network | |||
| """ | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| self.conv1 = conv(1, 6, 5) | |||
| self.conv2 = conv(6, 16, 5) | |||
| self.fc1 = fc_with_initialize(16*5*5, 120) | |||
| self.fc2 = fc_with_initialize(120, 84) | |||
| self.fc3 = fc_with_initialize(84, 10) | |||
| self.relu = nn.ReLU() | |||
| self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) | |||
| self.reshape = P.Reshape() | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.conv2(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.reshape(x, (-1, 16*5*5)) | |||
| x = self.fc1(x) | |||
| x = self.relu(x) | |||
| x = self.fc2(x) | |||
| x = self.relu(x) | |||
| x = self.fc3(x) | |||
| return x | |||
| if __name__ == '__main__': | |||
| num_classes = 10 | |||
| batch_size = 32 | |||
| sparse = False | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target='Ascend') | |||
| # create test data | |||
| inputs_np = np.random.rand(batch_size, 1, 32, 32).astype(np.float32) | |||
| labels_np = np.random.randint(num_classes, size=batch_size).astype(np.int32) | |||
| if not sparse: | |||
| labels_np = np.eye(num_classes)[labels_np].astype(np.float32) | |||
| net = Net() | |||
| # test fgsm | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| attack.generate(inputs_np, labels_np) | |||
| # test train ops | |||
| loss_fn = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=sparse) | |||
| optimizer = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), | |||
| 0.01, 0.9) | |||
| loss_net = WithLossCell(net, loss_fn) | |||
| train_net = TrainOneStepCell(loss_net, optimizer) | |||
| train_net.set_train() | |||
| train_net(Tensor(inputs_np), Tensor(labels_np)) | |||
+ 66
- 0
tests/ut/python/defenses/test_ad.py
View File
| @@ -0,0 +1,66 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Adversarial defense test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import logging | |||
| from mindspore import nn | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindarmour.defenses.adversarial_defense import AdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mock_net import Net | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Ad_Test' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_ad(): | |||
| """UT for adversarial defense.""" | |||
| num_classes = 10 | |||
| batch_size = 16 | |||
| sparse = False | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target='Ascend') | |||
| # create test data | |||
| inputs = np.random.rand(batch_size, 1, 32, 32).astype(np.float32) | |||
| labels = np.random.randint(num_classes, size=batch_size).astype(np.int32) | |||
| if not sparse: | |||
| labels = np.eye(num_classes)[labels].astype(np.float32) | |||
| net = Net() | |||
| loss_fn = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=sparse) | |||
| optimizer = Momentum(learning_rate=Tensor(np.array([0.001], np.float32)), | |||
| momentum=Tensor(np.array([0.9], np.float32)), | |||
| params=net.trainable_params()) | |||
| ad_defense = AdversarialDefense(net, loss_fn=loss_fn, optimizer=optimizer) | |||
| LOGGER.set_level(logging.DEBUG) | |||
| LOGGER.debug(TAG, '--start adversarial defense--') | |||
| loss = ad_defense.defense(inputs, labels) | |||
| LOGGER.debug(TAG, '--end adversarial defense--') | |||
| assert np.any(loss >= 0.0) | |||
+ 70
- 0
tests/ut/python/defenses/test_ead.py
View File
| @@ -0,0 +1,70 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| ensemble adversarial defense test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import logging | |||
| from mindspore import nn | |||
| from mindspore import context | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from mindarmour.attacks.iterative_gradient_method import \ | |||
| ProjectedGradientDescent | |||
| from mindarmour.defenses.adversarial_defense import EnsembleAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mock_net import Net | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Ead_Test' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_ead(): | |||
| """UT for ensemble adversarial defense.""" | |||
| num_classes = 10 | |||
| batch_size = 16 | |||
| sparse = False | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target='Ascend') | |||
| # create test data | |||
| inputs = np.random.rand(batch_size, 1, 32, 32).astype(np.float32) | |||
| labels = np.random.randint(num_classes, size=batch_size).astype(np.int32) | |||
| if not sparse: | |||
| labels = np.eye(num_classes)[labels].astype(np.float32) | |||
| net = Net() | |||
| loss_fn = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=sparse) | |||
| optimizer = Momentum(net.trainable_params(), 0.001, 0.9) | |||
| net = Net() | |||
| fgsm = FastGradientSignMethod(net) | |||
| pgd = ProjectedGradientDescent(net) | |||
| ead = EnsembleAdversarialDefense(net, [fgsm, pgd], loss_fn=loss_fn, | |||
| optimizer=optimizer) | |||
| LOGGER.set_level(logging.DEBUG) | |||
| LOGGER.debug(TAG, '---start ensemble adversarial defense--') | |||
| loss = ead.defense(inputs, labels) | |||
| LOGGER.debug(TAG, '---end ensemble adversarial defense--') | |||
| assert np.any(loss >= 0.0) | |||
+ 65
- 0
tests/ut/python/defenses/test_nad.py
View File
| @@ -0,0 +1,65 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Natural adversarial defense test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import logging | |||
| from mindspore import nn | |||
| from mindspore import context | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindarmour.defenses.natural_adversarial_defense import \ | |||
| NaturalAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mock_net import Net | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Nad_Test' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nad(): | |||
| """UT for natural adversarial defense.""" | |||
| num_classes = 10 | |||
| batch_size = 16 | |||
| sparse = False | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target='Ascend') | |||
| # create test data | |||
| inputs = np.random.rand(batch_size, 1, 32, 32).astype(np.float32) | |||
| labels = np.random.randint(num_classes, size=batch_size).astype(np.int32) | |||
| if not sparse: | |||
| labels = np.eye(num_classes)[labels].astype(np.float32) | |||
| net = Net() | |||
| loss_fn = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=sparse) | |||
| optimizer = Momentum(net.trainable_params(), 0.001, 0.9) | |||
| # defense | |||
| nad = NaturalAdversarialDefense(net, loss_fn=loss_fn, optimizer=optimizer) | |||
| LOGGER.set_level(logging.DEBUG) | |||
| LOGGER.debug(TAG, '---start natural adversarial defense--') | |||
| loss = nad.defense(inputs, labels) | |||
| LOGGER.debug(TAG, '---end natural adversarial defense--') | |||
| assert np.any(loss >= 0.0) | |||
+ 66
- 0
tests/ut/python/defenses/test_pad.py
View File
| @@ -0,0 +1,66 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Projected adversarial defense test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import logging | |||
| from mindspore import nn | |||
| from mindspore import context | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindarmour.defenses.projected_adversarial_defense import \ | |||
| ProjectedAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mock_net import Net | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Pad_Test' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pad(): | |||
| """UT for projected adversarial defense.""" | |||
| num_classes = 10 | |||
| batch_size = 16 | |||
| sparse = False | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target='Ascend') | |||
| # create test data | |||
| inputs = np.random.rand(batch_size, 1, 32, 32).astype(np.float32) | |||
| labels = np.random.randint(num_classes, size=batch_size).astype(np.int32) | |||
| if not sparse: | |||
| labels = np.eye(num_classes)[labels].astype(np.float32) | |||
| # construct network | |||
| net = Net() | |||
| loss_fn = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=sparse) | |||
| optimizer = Momentum(net.trainable_params(), 0.001, 0.9) | |||
| # defense | |||
| pad = ProjectedAdversarialDefense(net, loss_fn=loss_fn, optimizer=optimizer) | |||
| LOGGER.set_level(logging.DEBUG) | |||
| LOGGER.debug(TAG, '---start projected adversarial defense--') | |||
| loss = pad.defense(inputs, labels) | |||
| LOGGER.debug(TAG, '---end projected adversarial defense--') | |||
| assert np.any(loss >= 0.0) | |||
+ 101
- 0
tests/ut/python/detectors/black/test_similarity_detector.py
View File
| @@ -0,0 +1,101 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Similarity-detector test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore.nn import Cell | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| class EncoderNet(Cell): | |||
| """ | |||
| Similarity encoder for input data | |||
| """ | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| construct the neural network | |||
| Args: | |||
| inputs (Tensor): input data to neural network. | |||
| Returns: | |||
| Tensor, output of neural network. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| def get_encode_dim(self): | |||
| """ | |||
| Get the dimension of encoded inputs | |||
| Returns: | |||
| int, dimension of encoded inputs. | |||
| """ | |||
| return self._encode_dim | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_similarity_detector(): | |||
| """ | |||
| Similarity detector unit test | |||
| """ | |||
| # Prepare dataset | |||
| np.random.seed(5) | |||
| x_train = np.random.rand(1000, 32, 32, 3).astype(np.float32) | |||
| perm = np.random.permutation(x_train.shape[0]) | |||
| # Generate query sequences | |||
| benign_queries = x_train[perm[:1000], :, :, :] | |||
| suspicious_queries = x_train[perm[-1], :, :, :] + np.random.normal( | |||
| 0, 0.05, (1000,) + x_train.shape[1:]) | |||
| suspicious_queries = suspicious_queries.astype(np.float32) | |||
| # explicit threshold not provided, calculate threshold for K | |||
| encoder = Model(EncoderNet(encode_dim=256)) | |||
| detector = SimilarityDetector(max_k_neighbor=50, trans_model=encoder) | |||
| num_nearest_neighbors, thresholds = detector.fit(inputs=x_train) | |||
| detector.set_threshold(num_nearest_neighbors[-1], thresholds[-1]) | |||
| detector.detect(benign_queries) | |||
| detections = detector.get_detection_interval() | |||
| # compare | |||
| expected_value = 0 | |||
| assert len(detections) == expected_value | |||
| detector.clear_buffer() | |||
| detector.detect(suspicious_queries) | |||
| # compare | |||
| expected_value = [1051, 1102, 1153, 1204, 1255, | |||
| 1306, 1357, 1408, 1459, 1510, | |||
| 1561, 1612, 1663, 1714, 1765, | |||
| 1816, 1867, 1918, 1969] | |||
| assert np.all(detector.get_detected_queries() == expected_value) | |||
+ 112
- 0
tests/ut/python/detectors/test_ensemble_detector.py
View File
| @@ -0,0 +1,112 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| EnsembleDetector Test | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.train.model import Model | |||
| from mindspore import context | |||
| from mindarmour.detectors.mag_net import ErrorBasedDetector | |||
| from mindarmour.detectors.region_based_detector import RegionBasedDetector | |||
| from mindarmour.detectors.ensemble_detector import EnsembleDetector | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| """ | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| class AutoNet(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| """ | |||
| def __init__(self): | |||
| super(AutoNet, self).__init__() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_ensemble_detector(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4).astype(np.float32) | |||
| model = Model(Net()) | |||
| auto_encoder = Model(AutoNet()) | |||
| random_label = np.random.randint(10, size=4) | |||
| labels = np.eye(10)[random_label] | |||
| magnet_detector = ErrorBasedDetector(auto_encoder) | |||
| region_detector = RegionBasedDetector(model) | |||
| # use this to enable radius in region_detector | |||
| region_detector.fit(adv, labels) | |||
| detectors = [magnet_detector, region_detector] | |||
| detector = EnsembleDetector(detectors) | |||
| detected_res = detector.detect(adv) | |||
| expected_value = np.array([0, 1, 0, 0]) | |||
| assert np.all(detected_res == expected_value) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_error(): | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4).astype(np.float32) | |||
| model = Model(Net()) | |||
| auto_encoder = Model(AutoNet()) | |||
| random_label = np.random.randint(10, size=4) | |||
| labels = np.eye(10)[random_label] | |||
| magnet_detector = ErrorBasedDetector(auto_encoder) | |||
| region_detector = RegionBasedDetector(model) | |||
| # use this to enable radius in region_detector | |||
| detectors = [magnet_detector, region_detector] | |||
| detector = EnsembleDetector(detectors) | |||
| with pytest.raises(NotImplementedError): | |||
| assert detector.fit(adv, labels) | |||
+ 164
- 0
tests/ut/python/detectors/test_mag_net.py
View File
| @@ -0,0 +1,164 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Mag-net detector test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as P | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindarmour.detectors.mag_net import ErrorBasedDetector | |||
| from mindarmour.detectors.mag_net import DivergenceBasedDetector | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| """ | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| class PredNet(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| """ | |||
| def __init__(self): | |||
| super(PredNet, self).__init__() | |||
| self.shape = P.Shape() | |||
| self.reshape = P.Reshape() | |||
| self._softmax = P.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| data = self.reshape(inputs, (self.shape(inputs)[0], -1)) | |||
| return self._softmax(data) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_mag_net(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| np.random.seed(5) | |||
| ori = np.random.rand(4, 4, 4).astype(np.float32) | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4, 4).astype(np.float32) | |||
| model = Model(Net()) | |||
| detector = ErrorBasedDetector(model) | |||
| detector.fit(ori) | |||
| detected_res = detector.detect(adv) | |||
| expected_value = np.array([1, 1, 1, 1]) | |||
| assert np.all(detected_res == expected_value) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_mag_net_transform(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4, 4).astype(np.float32) | |||
| model = Model(Net()) | |||
| detector = ErrorBasedDetector(model) | |||
| adv_trans = detector.transform(adv) | |||
| assert np.any(adv_trans != adv) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_mag_net_divergence(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| np.random.seed(5) | |||
| ori = np.random.rand(4, 4, 4).astype(np.float32) | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4, 4).astype(np.float32) | |||
| encoder = Model(Net()) | |||
| model = Model(PredNet()) | |||
| detector = DivergenceBasedDetector(encoder, model) | |||
| threshold = detector.fit(ori) | |||
| detector.set_threshold(threshold) | |||
| detected_res = detector.detect(adv) | |||
| expected_value = np.array([1, 0, 1, 1]) | |||
| assert np.all(detected_res == expected_value) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_mag_net_divergence_transform(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4, 4).astype(np.float32) | |||
| encoder = Model(Net()) | |||
| model = Model(PredNet()) | |||
| detector = DivergenceBasedDetector(encoder, model) | |||
| adv_trans = detector.transform(adv) | |||
| assert np.any(adv_trans != adv) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4, 4).astype(np.float32) | |||
| encoder = Model(Net()) | |||
| model = Model(PredNet()) | |||
| detector = DivergenceBasedDetector(encoder, model, option='bad_op') | |||
| with pytest.raises(NotImplementedError): | |||
| assert detector.detect_diff(adv) | |||
+ 115
- 0
tests/ut/python/detectors/test_region_based_detector.py
View File
| @@ -0,0 +1,115 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Region-based detector test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore.nn import Cell | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindarmour.detectors.region_based_detector import \ | |||
| RegionBasedDetector | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| """ | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| return self.add(inputs, inputs) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_region_based_classification(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| np.random.seed(5) | |||
| ori = np.random.rand(4, 4).astype(np.float32) | |||
| labels = np.array([[1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], | |||
| [0, 1, 0, 0]]).astype(np.int32) | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4).astype(np.float32) | |||
| model = Model(Net()) | |||
| detector = RegionBasedDetector(model) | |||
| radius = detector.fit(ori, labels) | |||
| detector.set_radius(radius) | |||
| detected_res = detector.detect(adv) | |||
| expected_value = np.array([0, 0, 1, 0]) | |||
| assert np.all(detected_res == expected_value) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| np.random.seed(5) | |||
| ori = np.random.rand(4, 4).astype(np.float32) | |||
| labels = np.array([[1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], | |||
| [0, 1, 0, 0]]).astype(np.int32) | |||
| np.random.seed(6) | |||
| adv = np.random.rand(4, 4).astype(np.float32) | |||
| model = Model(Net()) | |||
| # model should be mindspore model | |||
| with pytest.raises(ValueError): | |||
| assert RegionBasedDetector(Net()) | |||
| with pytest.raises(ValueError): | |||
| assert RegionBasedDetector(model, number_points=-1) | |||
| with pytest.raises(ValueError): | |||
| assert RegionBasedDetector(model, initial_radius=-1) | |||
| with pytest.raises(ValueError): | |||
| assert RegionBasedDetector(model, max_radius=-2.2) | |||
| with pytest.raises(ValueError): | |||
| assert RegionBasedDetector(model, search_step=0) | |||
| with pytest.raises(ValueError): | |||
| assert RegionBasedDetector(model, sparse='False') | |||
| detector = RegionBasedDetector(model) | |||
| with pytest.raises(ValueError): | |||
| # radius must not empty | |||
| assert detector.detect(adv) | |||
| radius = detector.fit(ori, labels) | |||
| detector.set_radius(radius) | |||
| with pytest.raises(ValueError): | |||
| # adv type should be in (list, tuple, numpy.ndarray) | |||
| assert detector.detect(adv.tostring()) | |||
+ 116
- 0
tests/ut/python/detectors/test_spatial_smoothing.py
View File
| @@ -0,0 +1,116 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Spatial-smoothing detector test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| import mindspore.ops.operations as M | |||
| from mindspore import Model | |||
| from mindspore.nn import Cell | |||
| from mindspore import context | |||
| from mindarmour.detectors.spatial_smoothing import SpatialSmoothing | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| # for use | |||
| class Net(Cell): | |||
| """ | |||
| Construct the network of target model. | |||
| """ | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| self._softmax = M.Softmax() | |||
| def construct(self, inputs): | |||
| """ | |||
| Construct network. | |||
| Args: | |||
| inputs (Tensor): Input data. | |||
| """ | |||
| return self._softmax(inputs) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_spatial_smoothing(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| input_shape = (50, 3) | |||
| np.random.seed(1) | |||
| input_np = np.random.randn(*input_shape).astype(np.float32) | |||
| np.random.seed(2) | |||
| adv_np = np.random.randn(*input_shape).astype(np.float32) | |||
| # mock user model | |||
| model = Model(Net()) | |||
| detector = SpatialSmoothing(model) | |||
| # Training | |||
| threshold = detector.fit(input_np) | |||
| detector.set_threshold(threshold.item()) | |||
| detected_res = np.array(detector.detect(adv_np)) | |||
| idx = np.where(detected_res > 0) | |||
| expected_value = np.array([10, 39, 48]) | |||
| assert np.all(idx == expected_value) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_spatial_smoothing_diff(): | |||
| """ | |||
| Compute mindspore result. | |||
| """ | |||
| input_shape = (50, 3) | |||
| np.random.seed(1) | |||
| input_np = np.random.randn(*input_shape).astype(np.float32) | |||
| np.random.seed(2) | |||
| adv_np = np.random.randn(*input_shape).astype(np.float32) | |||
| # mock user model | |||
| model = Model(Net()) | |||
| detector = SpatialSmoothing(model) | |||
| # Training | |||
| detector.fit(input_np) | |||
| diffs = detector.detect_diff(adv_np) | |||
| expected_value = np.array([0.20959496, 0.69537306, 0.13034256, 0.7421039, | |||
| 0.41419053, 0.56346416, 0.4277994, 0.3240941, | |||
| 0.048190027, 0.6806958, 1.1405756, 0.587804, | |||
| 0.40533313, 0.2875523, 0.36801508, 0.61993587, | |||
| 0.49286827, 0.13222921, 0.68012404, 0.4164942, | |||
| 0.25758877, 0.6008735, 0.60623455, 0.34981924, | |||
| 0.3945489, 0.879787, 0.3934811, 0.23387678, | |||
| 0.63480926, 0.56435543, 0.16067612, 0.57489645, | |||
| 0.21772699, 0.55924356, 0.5186635, 0.7094835, | |||
| 0.0613693, 0.13305652, 0.11505881, 1.2404268, | |||
| 0.50948, 0.15797901, 0.44473758, 0.2495422, | |||
| 0.38254014, 0.543059, 0.06452079, 0.36902517, | |||
| 1.1845329, 0.3870097]) | |||
| assert np.allclose(diffs, expected_value, 0.0001, 0.0001) | |||
+ 73
- 0
tests/ut/python/evaluations/black/test_black_defense_eval.py
View File
| @@ -0,0 +1,73 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Black-box defense evaluation test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindarmour.evaluations.black.defense_evaluation import BlackDefenseEvaluate | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_def_eval(): | |||
| """ | |||
| Tests for black-box defense evaluation | |||
| """ | |||
| # prepare data | |||
| raw_preds = np.array([[0.1, 0.1, 0.2, 0.6], [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1], [0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.7, 0.0, 0.2], [0.8, 0.1, 0.0, 0.1], | |||
| [0.1, 0.1, 0.2, 0.6], [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1], [0.1, 0.1, 0.2, 0.6]]) | |||
| def_preds = np.array([[0.1, 0.1, 0.2, 0.6], [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1], [0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.7, 0.0, 0.2], [0.8, 0.1, 0.0, 0.1], | |||
| [0.1, 0.1, 0.2, 0.6], [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1], [0.1, 0.1, 0.2, 0.6]]) | |||
| raw_query_counts = np.array([0, 0, 0, 0, 0, 10, 10, 20, 20, 30]) | |||
| def_query_counts = np.array([0, 0, 0, 0, 0, 30, 30, 40, 40, 50]) | |||
| raw_query_time = np.array([0.1, 0.1, 0.1, 0.1, 0.1, 2, 2, 4, 4, 6]) | |||
| def_query_time = np.array([0.3, 0.3, 0.3, 0.3, 0.3, 4, 4, 8, 8, 12]) | |||
| def_detection_counts = np.array([1, 0, 0, 0, 1, 5, 5, 5, 10, 20]) | |||
| true_labels = np.array([3, 1, 0, 3, 1, 0, 3, 1, 0, 3]) | |||
| # create obj | |||
| def_eval = BlackDefenseEvaluate(raw_preds, | |||
| def_preds, | |||
| raw_query_counts, | |||
| def_query_counts, | |||
| raw_query_time, | |||
| def_query_time, | |||
| def_detection_counts, | |||
| true_labels, | |||
| max_queries=100) | |||
| # run eval | |||
| qcv = def_eval.qcv() | |||
| asv = def_eval.asv() | |||
| fpr = def_eval.fpr() | |||
| qrv = def_eval.qrv() | |||
| res = [qcv, asv, fpr, qrv] | |||
| # compare | |||
| expected_value = [0.2, 0.0, 0.4, 2.0] | |||
| assert np.allclose(res, expected_value, 0.0001, 0.0001) | |||
+ 95
- 0
tests/ut/python/evaluations/test_attack_eval.py
View File
| @@ -0,0 +1,95 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Attack evaluation test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_attack_eval(): | |||
| # prepare test data | |||
| np.random.seed(1024) | |||
| inputs = np.random.normal(size=(3, 512, 512, 3)) | |||
| labels = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1]]) | |||
| adv_x = inputs + np.ones((3, 512, 512, 3))*0.001 | |||
| adv_y = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.0, 0.8, 0.1], | |||
| [0.0, 0.9, 0.1, 0.0]]) | |||
| # create obj | |||
| attack_eval = AttackEvaluate(inputs, labels, adv_x, adv_y) | |||
| # run eval | |||
| mr = attack_eval.mis_classification_rate() | |||
| acac = attack_eval.avg_conf_adv_class() | |||
| l_0, l_2, l_inf = attack_eval.avg_lp_distance() | |||
| ass = attack_eval.avg_ssim() | |||
| nte = attack_eval.nte() | |||
| res = [mr, acac, l_0, l_2, l_inf, ass, nte] | |||
| # compare | |||
| expected_value = [0.6666, 0.8500, 1.0, 0.0009, 0.0001, 0.9999, 0.75] | |||
| assert np.allclose(res, expected_value, 0.0001, 0.0001) | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| # prepare test data | |||
| np.random.seed(1024) | |||
| inputs = np.random.normal(size=(3, 512, 512, 3)) | |||
| labels = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1]]) | |||
| adv_x = inputs + np.ones((3, 512, 512, 3))*0.001 | |||
| adv_y = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.0, 0.8, 0.1], | |||
| [0.0, 0.9, 0.1, 0.0]]) | |||
| # create obj | |||
| with pytest.raises(ValueError) as e: | |||
| assert AttackEvaluate(inputs, labels, adv_x, adv_y, targeted=True) | |||
| assert str(e.value) == 'targeted attack need target_label, but got None.' | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| # prepare test data | |||
| np.random.seed(1024) | |||
| inputs = np.array([]) | |||
| labels = np.array([]) | |||
| adv_x = inputs | |||
| adv_y = np.array([]) | |||
| # create obj | |||
| with pytest.raises(ValueError) as e: | |||
| assert AttackEvaluate(inputs, labels, adv_x, adv_y) | |||
| assert str(e.value) == 'inputs must not be empty' | |||
+ 51
- 0
tests/ut/python/evaluations/test_defense_eval.py
View File
| @@ -0,0 +1,51 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Defense evaluation test. | |||
| """ | |||
| import numpy as np | |||
| import pytest | |||
| from mindarmour.evaluations.defense_evaluation import DefenseEvaluate | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_def_eval(): | |||
| # prepare data | |||
| raw_preds = np.array([[0.1, 0.1, 0.2, 0.6], | |||
| [0.1, 0.7, 0.0, 0.2], | |||
| [0.8, 0.1, 0.0, 0.1]]) | |||
| def_preds = np.array([[0.1, 0.1, 0.1, 0.7], | |||
| [0.1, 0.6, 0.2, 0.1], | |||
| [0.1, 0.2, 0.1, 0.6]]) | |||
| true_labels = np.array([3, 1, 0]) | |||
| # create obj | |||
| def_eval = DefenseEvaluate(raw_preds, def_preds, true_labels) | |||
| # run eval | |||
| cav = def_eval.cav() | |||
| crr = def_eval.crr() | |||
| csr = def_eval.csr() | |||
| ccv = def_eval.ccv() | |||
| cos = def_eval.cos() | |||
| res = [cav, crr, csr, ccv, cos] | |||
| # compare | |||
| expected_value = [-0.3333, 0.0, 0.3333, 0.0999, 0.0450] | |||
| assert np.allclose(res, expected_value, 0.0001, 0.0001) | |||
+ 57
- 0
tests/ut/python/evaluations/test_radar_metric.py
View File
| @@ -0,0 +1,57 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| Radar map test. | |||
| """ | |||
| import pytest | |||
| from mindarmour.evaluations.visual_metrics import RadarMetric | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_radar_metric(): | |||
| # prepare data | |||
| metrics_name = ['MR', 'ACAC', 'ASS', 'NTE', 'RGB'] | |||
| def_metrics = [0.9, 0.85, 0.6, 0.7, 0.8] | |||
| raw_metrics = [0.5, 0.3, 0.55, 0.65, 0.7] | |||
| metrics_data = [def_metrics, raw_metrics] | |||
| metrics_labels = ['before', 'after'] | |||
| # create obj | |||
| rm = RadarMetric(metrics_name, metrics_data, metrics_labels, title='', | |||
| scale='sparse') | |||
| @pytest.mark.level0 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_value_error(): | |||
| # prepare data | |||
| metrics_name = ['MR', 'ACAC', 'ASS', 'NTE', 'RGB'] | |||
| def_metrics = [0.9, 0.85, 0.6, 0.7, 0.8] | |||
| raw_metrics = [0.5, 0.3, 0.55, 0.65, 0.7] | |||
| metrics_data = [def_metrics, raw_metrics] | |||
| metrics_labels = ['before', 'after'] | |||
| with pytest.raises(ValueError): | |||
| assert RadarMetric(metrics_name, metrics_data, metrics_labels, | |||
| title='', scale='bad_s') | |||
| with pytest.raises(ValueError): | |||
| assert RadarMetric(['MR', 'ACAC', 'ASS'], metrics_data, metrics_labels, | |||
| title='', scale='bad_s') | |||