Compare commits
merge into: hummingbird:master
hummingbird:master
hummingbird:r0.1
hummingbird:r0.2
hummingbird:r0.3
hummingbird:r0.5
hummingbird:r0.6
hummingbird:r0.7
hummingbird:r1.0
hummingbird:r1.1
hummingbird:r1.2
hummingbird:r1.3
hummingbird:r1.5
hummingbird:r1.6
hummingbird:r1.7
hummingbird:r1.8
hummingbird:r1.9
hummingbird:r2.0
hummingbird:serving
pull from: hummingbird:r0.1
hummingbird:master
hummingbird:r0.1
hummingbird:r0.2
hummingbird:r0.3
hummingbird:r0.5
hummingbird:r0.6
hummingbird:r0.7
hummingbird:r1.0
hummingbird:r1.1
hummingbird:r1.2
hummingbird:r1.3
hummingbird:r1.5
hummingbird:r1.6
hummingbird:r1.7
hummingbird:r1.8
hummingbird:r1.9
hummingbird:r2.0
hummingbird:serving
100 changed files with 711 additions and 7180 deletions
Split View
Diff Options
-
+2 -3.gitee/PULL_REQUEST_TEMPLATE.md
-
+0 -19.github/ISSUE_TEMPLATE/RFC.md
-
+0 -43.github/ISSUE_TEMPLATE/bug-report.md
-
+0 -19.github/ISSUE_TEMPLATE/task-tracking.md
-
+0 -24.github/PULL_REQUEST_TEMPLATE.md
-
+1 -2.gitignore
-
+0 -1.jenkins/check/config/filter_cppcheck.txt
-
+0 -1.jenkins/check/config/filter_cpplint.txt
-
+0 -48.jenkins/check/config/filter_pylint.txt
-
+0 -6.jenkins/check/config/whitelizard.txt
-
+0 -3.jenkins/test/config/dependent_packages.yaml
-
+0 -3.vscode/settings.json
-
+0 -8OWNERS
-
+28 -98README.md
-
+0 -141README_CN.md
-
+5 -373RELEASE.md
-
+0 -69RELEASE_CN.md
-
BINdocs/adversarial_robustness_cn.png
-
BINdocs/adversarial_robustness_en.png
-
+0 -618docs/api/api_python/mindarmour.adv_robustness.attacks.rst
-
+0 -96docs/api/api_python/mindarmour.adv_robustness.defenses.rst
-
+0 -348docs/api/api_python/mindarmour.adv_robustness.detectors.rst
-
+0 -174docs/api/api_python/mindarmour.adv_robustness.evaluations.rst
-
+0 -186docs/api/api_python/mindarmour.fuzz_testing.rst
-
+0 -143docs/api/api_python/mindarmour.natural_robustness.transform.image.rst
-
+0 -269docs/api/api_python/mindarmour.privacy.diff_privacy.rst
-
+0 -108docs/api/api_python/mindarmour.privacy.evaluation.rst
-
+0 -175docs/api/api_python/mindarmour.privacy.sup_privacy.rst
-
+0 -129docs/api/api_python/mindarmour.reliability.rst
-
+0 -344docs/api/api_python/mindarmour.rst
-
+0 -113docs/api/api_python/mindarmour.utils.rst
-
BINdocs/differential_privacy_architecture_cn.png
-
BINdocs/differential_privacy_architecture_en.png
-
BINdocs/fuzzer_architecture_cn.png
-
BINdocs/fuzzer_architecture_en.png
-
BINdocs/mindarmour_architecture.png
-
BINdocs/privacy_leakage_cn.png
-
BINdocs/privacy_leakage_en.png
-
+62 -0example/data_processing.py
-
+46 -0example/mnist_demo/README.md
-
+5 -4example/mnist_demo/lenet5_net.py
-
+19 -11example/mnist_demo/mnist_attack_cw.py
-
+20 -11example/mnist_demo/mnist_attack_deepfool.py
-
+27 -19example/mnist_demo/mnist_attack_fgsm.py
-
+24 -19example/mnist_demo/mnist_attack_genetic.py
-
+27 -19example/mnist_demo/mnist_attack_hsja.py
-
+22 -13example/mnist_demo/mnist_attack_jsma.py
-
+30 -21example/mnist_demo/mnist_attack_lbfgs.py
-
+24 -15example/mnist_demo/mnist_attack_nes.py
-
+29 -21example/mnist_demo/mnist_attack_pgd.py
-
+23 -14example/mnist_demo/mnist_attack_pointwise.py
-
+20 -15example/mnist_demo/mnist_attack_pso.py
-
+37 -21example/mnist_demo/mnist_attack_salt_and_pepper.py
-
+144 -0example/mnist_demo/mnist_defense_nad.py
-
+44 -46example/mnist_demo/mnist_evaluation.py
-
+26 -26example/mnist_demo/mnist_similarity_detector.py
-
+46 -23example/mnist_demo/mnist_train.py
-
+0 -45examples/README.md
-
+0 -16examples/__init__.py
-
+0 -32examples/ai_fuzzer/README.md
-
+0 -176examples/ai_fuzzer/fuzz_testing_and_model_enhense.py
-
+0 -89examples/ai_fuzzer/lenet5_mnist_coverage.py
-
+0 -131examples/ai_fuzzer/lenet5_mnist_fuzzing.py
-
+0 -188examples/common/dataset/data_processing.py
-
+0 -0examples/common/networks/__init__.py
-
+0 -0examples/common/networks/lenet5/__init__.py
-
+0 -98examples/common/networks/lenet5/lenet5_net_for_fuzzing.py
-
+0 -0examples/common/networks/resnet/__init__.py
-
+0 -401examples/common/networks/resnet/resnet.py
-
+0 -14examples/common/networks/vgg/__init__.py
-
+0 -45examples/common/networks/vgg/config.py
-
+0 -39examples/common/networks/vgg/crossentropy.py
-
+0 -23examples/common/networks/vgg/linear_warmup.py
-
+0 -0examples/common/networks/vgg/utils/__init__.py
-
+0 -36examples/common/networks/vgg/utils/util.py
-
+0 -219examples/common/networks/vgg/utils/var_init.py
-
+0 -142examples/common/networks/vgg/vgg.py
-
+0 -40examples/common/networks/vgg/warmup_cosine_annealing_lr.py
-
+0 -84examples/common/networks/vgg/warmup_step_lr.py
-
+0 -0examples/community/__init__.py
-
+0 -119examples/community/face_adversarial_attack/README.md
-
+0 -275examples/community/face_adversarial_attack/adversarial_attack.py
-
+0 -45examples/community/face_adversarial_attack/example_non_target_attack.py
-
+0 -46examples/community/face_adversarial_attack/example_target_attack.py
-
+0 -154examples/community/face_adversarial_attack/loss_design.py
-
BINexamples/community/face_adversarial_attack/photos/adv_input/adv.png
-
BINexamples/community/face_adversarial_attack/photos/input/input1.jpg
-
BINexamples/community/face_adversarial_attack/photos/target/target1.jpg
-
+0 -59examples/community/face_adversarial_attack/test.py
-
+0 -40examples/model_security/README.md
-
+0 -0examples/model_security/__init__.py
-
+0 -0examples/model_security/model_attacks/__init__.py
-
+0 -0examples/model_security/model_attacks/black_box/__init__.py
-
+0 -47examples/model_security/model_attacks/cv/faster_rcnn/README.md
-
+0 -150examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_genetic.py
-
+0 -135examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pgd.py
-
+0 -149examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pso.py
-
+0 -31examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/__init__.py
-
+0 -84examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/anchor_generator.py
-
+0 -166examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/bbox_assign_sample.py
+ 2
- 3
.gitee/PULL_REQUEST_TEMPLATE.md
View File
| @@ -11,7 +11,7 @@ If this is your first time, please read our contributor guidelines: https://gite | |||
| > /kind feature | |||
| **What does this PR do / why do we need it**: | |||
| **What this PR does / why we need it**: | |||
| **Which issue(s) this PR fixes**: | |||
| @@ -21,6 +21,5 @@ Usage: `Fixes #<issue number>`, or `Fixes (paste link of issue)`. | |||
| --> | |||
| Fixes # | |||
| **Special notes for your reviewers**: | |||
| **Special notes for your reviewer**: | |||
+ 0
- 19
.github/ISSUE_TEMPLATE/RFC.md
View File
| @@ -1,19 +0,0 @@ | |||
| --- | |||
| name: RFC | |||
| about: Use this template for the new feature or enhancement | |||
| labels: kind/feature or kind/enhancement | |||
| --- | |||
| ## Background | |||
| - Describe the status of the problem you wish to solve | |||
| - Attach the relevant issue if have | |||
| ## Introduction | |||
| - Describe the general solution, design and/or pseudo-code | |||
| ## Trail | |||
| | No. | Task Description | Related Issue(URL) | | |||
| | --- | ---------------- | ------------------ | | |||
| | 1 | | | | |||
| | 2 | | | | |||
+ 0
- 43
.github/ISSUE_TEMPLATE/bug-report.md
View File
| @@ -1,43 +0,0 @@ | |||
| --- | |||
| name: Bug Report | |||
| about: Use this template for reporting a bug | |||
| labels: kind/bug | |||
| --- | |||
| <!-- Thanks for sending an issue! Here are some tips for you: | |||
| If this is your first time, please read our contributor guidelines: https://github.com/mindspore-ai/mindspore/blob/master/CONTRIBUTING.md | |||
| --> | |||
| ## Environment | |||
| ### Hardware Environment(`Ascend`/`GPU`/`CPU`): | |||
| > Uncomment only one ` /device <>` line, hit enter to put that in a new line, and remove leading whitespaces from that line: | |||
| > | |||
| > `/device ascend`</br> | |||
| > `/device gpu`</br> | |||
| > `/device cpu`</br> | |||
| ### Software Environment: | |||
| - **MindSpore version (source or binary)**: | |||
| - **Python version (e.g., Python 3.7.5)**: | |||
| - **OS platform and distribution (e.g., Linux Ubuntu 16.04)**: | |||
| - **GCC/Compiler version (if compiled from source)**: | |||
| ## Describe the current behavior | |||
| ## Describe the expected behavior | |||
| ## Steps to reproduce the issue | |||
| 1. | |||
| 2. | |||
| 3. | |||
| ## Related log / screenshot | |||
| ## Special notes for this issue | |||
+ 0
- 19
.github/ISSUE_TEMPLATE/task-tracking.md
View File
| @@ -1,19 +0,0 @@ | |||
| --- | |||
| name: Task | |||
| about: Use this template for task tracking | |||
| labels: kind/task | |||
| --- | |||
| ## Task Description | |||
| ## Task Goal | |||
| ## Sub Task | |||
| | No. | Task Description | Issue ID | | |||
| | --- | ---------------- | -------- | | |||
| | 1 | | | | |||
| | 2 | | | | |||
+ 0
- 24
.github/PULL_REQUEST_TEMPLATE.md
View File
| @@ -1,24 +0,0 @@ | |||
| <!-- Thanks for sending a pull request! Here are some tips for you: | |||
| If this is your first time, please read our contributor guidelines: https://github.com/mindspore-ai/mindspore/blob/master/CONTRIBUTING.md | |||
| --> | |||
| **What type of PR is this?** | |||
| > Uncomment only one ` /kind <>` line, hit enter to put that in a new line, and remove leading whitespaces from that line: | |||
| > | |||
| > `/kind bug`</br> | |||
| > `/kind task`</br> | |||
| > `/kind feature`</br> | |||
| **What does this PR do / why do we need it**: | |||
| **Which issue(s) this PR fixes**: | |||
| <!-- | |||
| *Automatically closes linked issue when PR is merged. | |||
| Usage: `Fixes #<issue number>`, or `Fixes (paste link of issue)`. | |||
| --> | |||
| Fixes # | |||
| **Special notes for your reviewers**: | |||
+ 1
- 2
.gitignore
View File
| @@ -13,7 +13,7 @@ build/ | |||
| dist/ | |||
| local_script/ | |||
| example/dataset/ | |||
| example/mnist_demo/MNIST/ | |||
| example/mnist_demo/MNIST_unzip/ | |||
| example/mnist_demo/trained_ckpt_file/ | |||
| example/mnist_demo/model/ | |||
| example/cifar_demo/model/ | |||
| @@ -26,4 +26,3 @@ mindarmour.egg-info/ | |||
| *pre_trained_model/ | |||
| *__pycache__/ | |||
| *kernel_meta | |||
| .DS_Store | |||
+ 0
- 1
.jenkins/check/config/filter_cppcheck.txt
View File
| @@ -1 +0,0 @@ | |||
| # MindArmour | |||
+ 0
- 1
.jenkins/check/config/filter_cpplint.txt
View File
| @@ -1 +0,0 @@ | |||
| # MindArmour | |||
+ 0
- 48
.jenkins/check/config/filter_pylint.txt
View File
| @@ -1,48 +0,0 @@ | |||
| # MindArmour | |||
| "mindarmour/mindarmour/privacy/diff_privacy" "protected-access" | |||
| "mindarmour/mindarmour/fuzz_testing/fuzzing.py" "missing-docstring" | |||
| "mindarmour/mindarmour/fuzz_testing/fuzzing.py" "protected-access" | |||
| "mindarmour/mindarmour/fuzz_testing/fuzzing.py" "consider-using-enumerate" | |||
| "mindarmour/setup.py" "missing-docstring" | |||
| "mindarmour/setup.py" "invalid-name" | |||
| "mindarmour/mindarmour/reliability/model_fault_injection/fault_injection.py" "protected-access" | |||
| "mindarmour/setup.py" "unused-argument" | |||
| # Tests | |||
| "mindarmour/tests/st" "missing-docstring" | |||
| "mindarmour/tests/ut" "missing-docstring" | |||
| "mindarmour/tests/st/resnet50/resnet_cifar10.py" "unused-argument" | |||
| "mindarmour/tests/ut/python/fuzzing/test_fuzzing.py" "invalid-name" | |||
| "mindarmour/tests/ut/python/attacks/test_lbfgs.py" "wrong-import-position" | |||
| "mindarmour/tests/ut/python/attacks/black/test_nes.py" "wrong-import-position" | |||
| "mindarmour/tests/ut/python/attacks/black/test_nes.py" "consider-using-enumerate" | |||
| "mindarmour/tests/ut/python/attacks/black/test_hsja.py" "wrong-import-position" | |||
| "mindarmour/tests/ut/python/attacks/black/test_hsja.py" "consider-using-enumerate" | |||
| "mindarmour/tests/ut/python/attacks/black/test_salt_and_pepper_attack.py" "unused-variable" | |||
| "mindarmour/tests/ut/python/attacks/black/test_pointwise_attack.py" "wrong-import-position" | |||
| "mindarmour/tests/ut/python/evaluations/test_radar_metric.py" "bad-continuation" | |||
| "mindarmour/tests/ut/python/diff_privacy/test_membership_inference.py" "wrong-import-position" | |||
| # Example | |||
| "mindarmour/examples/ai_fuzzer/lenet5_mnist_coverage.py" "missing-docstring" | |||
| "mindarmour/examples/ai_fuzzer/lenet5_mnist_fuzzing.py" "missing-docstring" | |||
| "mindarmour/examples/ai_fuzzer/fuzz_testing_and_model_enhense.py" "missing-docstring" | |||
| "mindarmour/examples/common/dataset/data_processing.py" "missing-docstring" | |||
| "mindarmour/examples/common/networks/lenet5/lenet5_net.py" "missing-docstring" | |||
| "mindarmour/examples/common/networks/lenet5/mnist_train.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/black_box/mnist_attack_genetic.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/black_box/mnist_attack_hsja.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/black_box/mnist_attack_nes.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/black_box/mnist_attack_pointwise.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/black_box/mnist_attack_pso.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/black_box/mnist_attack_salt_and_pepper.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_cw.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_deepfool.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_fgsm.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_jsma.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_lbfgs.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_mdi2fgsm.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_attacks/white_box/mnist_attack_pgd.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_defenses/mnist_defense_nad.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_defenses/mnist_evaluation.py" "missing-docstring" | |||
| "mindarmour/examples/model_security/model_defenses/mnist_similarity_detector.py" "missing-docstring" | |||
+ 0
- 6
.jenkins/check/config/whitelizard.txt
View File
| @@ -1,6 +0,0 @@ | |||
| # Scene1: | |||
| # function_name1, function_name2 | |||
| # Scene2: | |||
| # file_path:function_name1, function_name2 | |||
| # | |||
| mindarmour/examples/model_security/model_defenses/mnist_evaluation.py:test_defense_evaluation | |||
+ 0
- 3
.jenkins/test/config/dependent_packages.yaml
View File
| @@ -1,3 +0,0 @@ | |||
| mindspore: | |||
| 'mindspore/mindspore/version/202209/20220923/r1.9_20220923224458_c16390f59ab8dace3bb7e5a6ab4ae4d3bfe74bea/' | |||
+ 0
- 3
.vscode/settings.json
View File
| @@ -1,3 +0,0 @@ | |||
| { | |||
| "esbonio.sphinx.confDir": "" | |||
| } | |||
+ 0
- 8
OWNERS
View File
| @@ -1,8 +0,0 @@ | |||
| approvers: | |||
| - pkuliuliu | |||
| - ZhidanLiu | |||
| - jxlang910 | |||
| reviewers: | |||
| - 张澍坤 | |||
| - emmmmtang | |||
+ 28
- 98
README.md
View File
| @@ -1,123 +1,53 @@ | |||
| # MindArmour | |||
| <!-- TOC --> | |||
| - [MindArmour](#mindarmour) | |||
| - [What is MindArmour](#what-is-mindarmour) | |||
| - [Adversarial Robustness Module](#adversarial-robustness-module) | |||
| - [Fuzz Testing Module](#fuzz-testing-module) | |||
| - [Privacy Protection and Evaluation Module](#privacy-protection-and-evaluation-module) | |||
| - [Differential Privacy Training Module](#differential-privacy-training-module) | |||
| - [Privacy Leakage Evaluation Module](#privacy-leakage-evaluation-module) | |||
| - [Starting](#starting) | |||
| - [System Environment Information Confirmation](#system-environment-information-confirmation) | |||
| - [Installation](#installation) | |||
| - [Installation by Source Code](#installation-by-source-code) | |||
| - [Installation by pip](#installation-by-pip) | |||
| - [Installation Verification](#installation-verification) | |||
| - [Docs](#docs) | |||
| - [Community](#community) | |||
| - [Contributing](#contributing) | |||
| - [Release Notes](#release-notes) | |||
| - [License](#license) | |||
| <!-- /TOC --> | |||
| [查看中文](./README_CN.md) | |||
| - [What is MindArmour](#what-is-mindarmour) | |||
| - [Setting up](#setting-up-mindarmour) | |||
| - [Docs](#docs) | |||
| - [Community](#community) | |||
| - [Contributing](#contributing) | |||
| - [Release Notes](#release-notes) | |||
| - [License](#license) | |||
| ## What is MindArmour | |||
| MindArmour focus on security and privacy of artificial intelligence. MindArmour can be used as a tool box for MindSpore users to enhance model security and trustworthiness and protect privacy data. MindArmour contains three module: Adversarial Robustness Module, Fuzz Testing Module, Privacy Protection and Evaluation Module. | |||
| A tool box for MindSpore users to enhance model security and trustworthiness. | |||
| ### Adversarial Robustness Module | |||
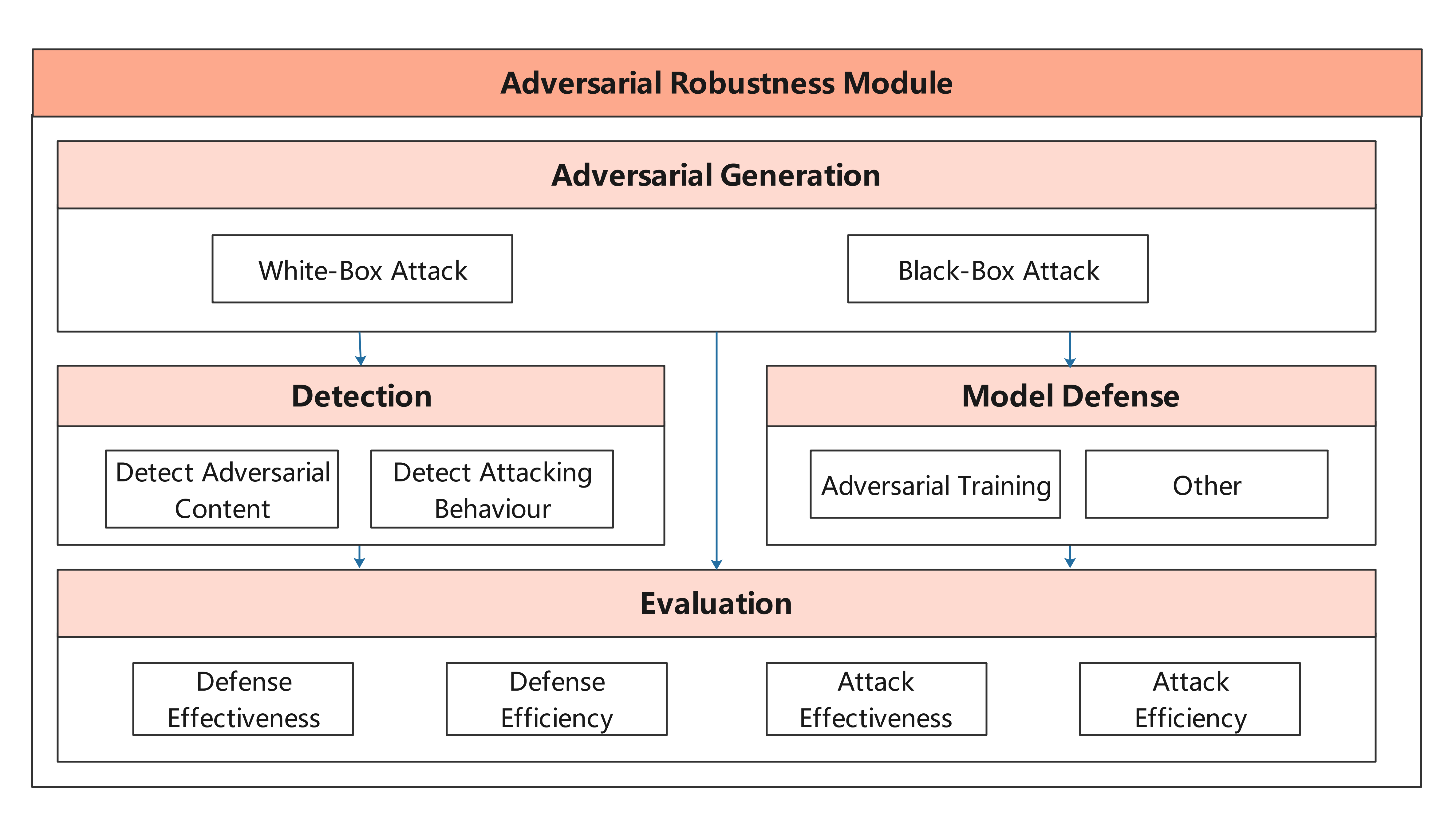
| MindArmour is designed for adversarial examples, including four submodule: adversarial examples generation, adversarial example detection, model defense and evaluation. The architecture is shown as follow: | |||
| Adversarial robustness module is designed for evaluating the robustness of the model against adversarial examples, and provides model enhancement methods to enhance the model's ability to resist the adversarial attack and improve the model's robustness. | |||
| This module includes four submodule: Adversarial Examples Generation, Adversarial Examples Detection, Model Defense and Evaluation. | |||
|  | |||
| The architecture is shown as follow: | |||
| ## Setting up MindArmour | |||
|  | |||
| ### Dependencies | |||
| ### Fuzz Testing Module | |||
| Fuzz Testing module is a security test for AI models. We introduce neuron coverage gain as a guide to fuzz testing according to the characteristics of neural networks. | |||
| Fuzz testing is guided to generate samples in the direction of increasing neuron coverage rate, so that the input can activate more neurons and neuron values have a wider distribution range to fully test neural networks and explore different types of model output results and wrong behaviors. | |||
| The architecture is shown as follow: | |||
|  | |||
| ### Privacy Protection and Evaluation Module | |||
| Privacy Protection and Evaluation Module includes two modules: Differential Privacy Training Module and Privacy Leakage Evaluation Module. | |||
| #### Differential Privacy Training Module | |||
| Differential Privacy Training Module implements the differential privacy optimizer. Currently, `SGD`, `Momentum` and `Adam` are supported. They are differential privacy optimizers based on the Gaussian mechanism. | |||
| This mechanism supports both non-adaptive and adaptive policy. Rényi differential privacy (RDP) and Zero-Concentrated differential privacy(ZCDP) are provided to monitor differential privacy budgets. | |||
| The architecture is shown as follow: | |||
|  | |||
| #### Privacy Leakage Evaluation Module | |||
| Privacy Leakage Evaluation Module is used to assess the risk of a model revealing user privacy. The privacy data security of the deep learning model is evaluated by using membership inference method to infer whether the sample belongs to training dataset. | |||
| The architecture is shown as follow: | |||
|  | |||
| ## Starting | |||
| ### System Environment Information Confirmation | |||
| - The hardware platform should be Ascend, GPU or CPU. | |||
| - See our [MindSpore Installation Guide](https://www.mindspore.cn/install) to install MindSpore. | |||
| The versions of MindArmour and MindSpore must be consistent. | |||
| - All other dependencies are included in [setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py). | |||
| This library uses MindSpore to accelerate graph computations performed by many machine learning models. Therefore, installing MindSpore is a pre-requisite. All other dependencies are included in `setup.py`. | |||
| ### Installation | |||
| ### Version dependency | |||
| Due the dependency between MindArmour and MindSpore, please follow the table below and install the corresponding MindSpore verision from [MindSpore download page](https://www.mindspore.cn/versions/en). | |||
| | MindArmour Version | Branch | MindSpore Version | | |||
| | ------------------ | --------------------------------------------------------- | ----------------- | | |||
| | 2.0.0 | [r2.0](https://gitee.com/mindspore/mindarmour/tree/r2.0/) | >=1.7.0 | | |||
| | 1.9.0 | [r1.9](https://gitee.com/mindspore/mindarmour/tree/r1.9/) | >=1.7.0 | | |||
| | 1.8.0 | [r1.8](https://gitee.com/mindspore/mindarmour/tree/r1.8/) | >=1.7.0 | | |||
| | 1.7.0 | [r1.7](https://gitee.com/mindspore/mindarmour/tree/r1.7/) | r1.7 | | |||
| #### Installation by Source Code | |||
| #### Installation for development | |||
| 1. Download source code from Gitee. | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| 2. Compile and install in MindArmour directory. | |||
| ```bash | |||
| cd mindarmour | |||
| python setup.py install | |||
| ``` | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| #### Installation by pip | |||
| 2. Compile and install in MindArmour directory. | |||
| ```bash | |||
| pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindArmour/{arch}/mindarmour-{version}-cp37-cp37m-linux_{arch}.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple | |||
| $ cd mindarmour | |||
| $ python setup.py install | |||
| ``` | |||
| > - When the network is connected, dependency items are automatically downloaded during .whl package installation. (For details about other dependency items, see [setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py)). In other cases, you need to manually install dependency items. | |||
| > - `{version}` denotes the version of MindArmour. For example, when you are downloading MindArmour 1.0.1, `{version}` should be 1.0.1. | |||
| > - `{arch}` denotes the system architecture. For example, the Linux system you are using is x86 architecture 64-bit, `{arch}` should be `x86_64`. If the system is ARM architecture 64-bit, then it should be `aarch64`. | |||
| #### `Pip` installation | |||
| ### Installation Verification | |||
| 1. Download whl package from [MindSpore website](https://www.mindspore.cn/versions/en), then run the following command: | |||
| ``` | |||
| pip install mindarmour-{version}-cp37-cp37m-linux_{arch}.whl | |||
| ``` | |||
| Successfully installed, if there is no error message such as `No module named 'mindarmour'` when execute the following command: | |||
| 2. Successfully installed, if there is no error message such as `No module named 'mindarmour'` when execute the following command: | |||
| ```bash | |||
| python -c 'import mindarmour' | |||
| @@ -129,7 +59,7 @@ Guidance on installation, tutorials, API, see our [User Documentation](https://g | |||
| ## Community | |||
| [MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ) - Ask questions and find answers. | |||
| - [MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ) - Ask questions and find answers. | |||
| ## Contributing | |||
+ 0
- 141
README_CN.md
View File
| @@ -1,141 +0,0 @@ | |||
| # MindArmour | |||
| <!-- TOC --> | |||
| - [MindArmour](#mindarmour) | |||
| - [简介](#简介) | |||
| - [对抗样本鲁棒性模块](#对抗样本鲁棒性模块) | |||
| - [Fuzz Testing模块](#fuzz-testing模块) | |||
| - [隐私保护模块](#隐私保护模块) | |||
| - [差分隐私训练模块](#差分隐私训练模块) | |||
| - [隐私泄露评估模块](#隐私泄露评估模块) | |||
| - [开始](#开始) | |||
| - [确认系统环境信息](#确认系统环境信息) | |||
| - [安装](#安装) | |||
| - [源码安装](#源码安装) | |||
| - [pip安装](#pip安装) | |||
| - [验证是否成功安装](#验证是否成功安装) | |||
| - [文档](#文档) | |||
| - [社区](#社区) | |||
| - [贡献](#贡献) | |||
| - [版本](#版本) | |||
| - [版权](#版权) | |||
| <!-- /TOC --> | |||
| [View English](./README.md) | |||
| ## 简介 | |||
| MindArmour关注AI的安全和隐私问题。致力于增强模型的安全可信、保护用户的数据隐私。主要包含3个模块:对抗样本鲁棒性模块、Fuzz Testing模块、隐私保护与评估模块。 | |||
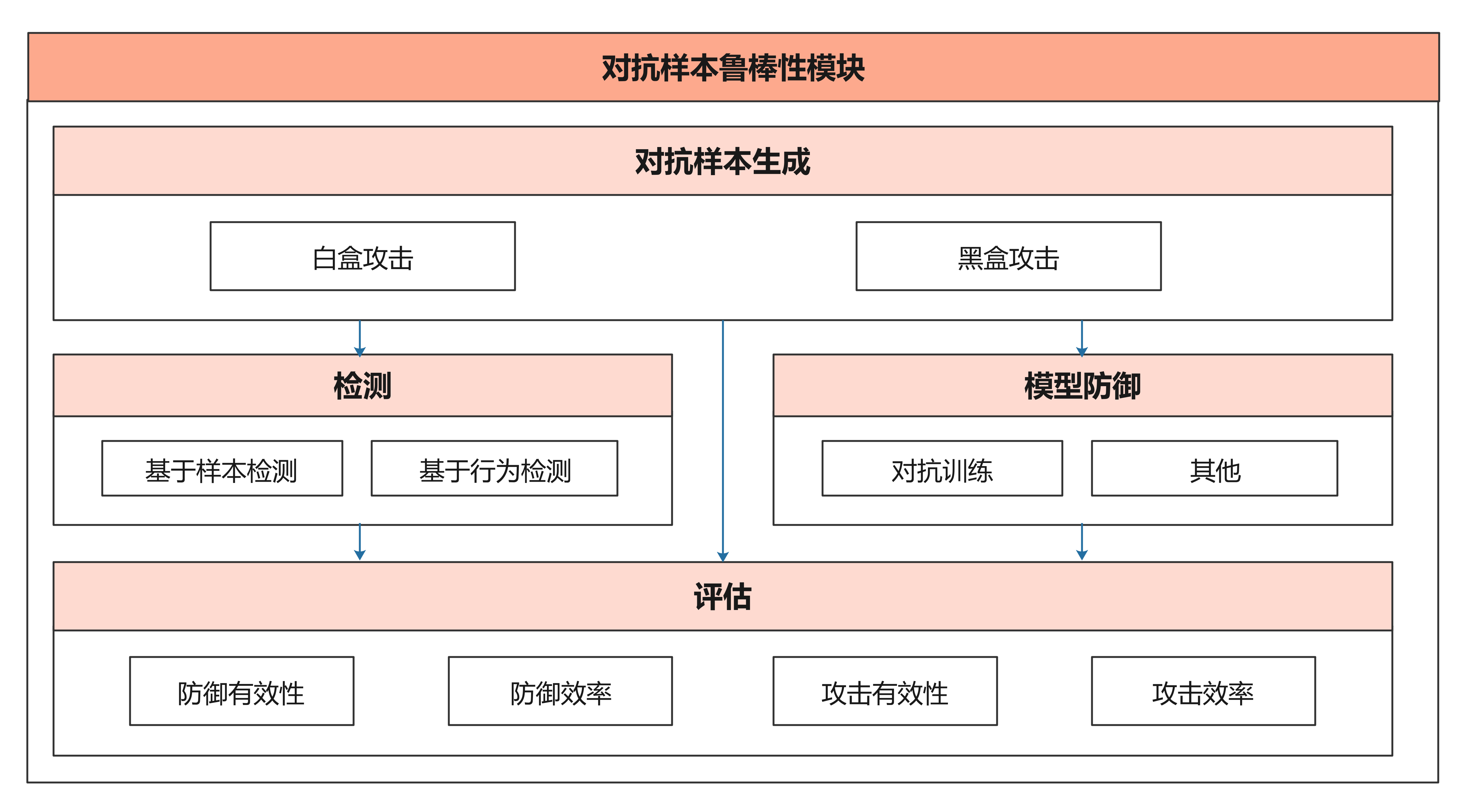
| ### 对抗样本鲁棒性模块 | |||
| 对抗样本鲁棒性模块用于评估模型对于对抗样本的鲁棒性,并提供模型增强方法用于增强模型抗对抗样本攻击的能力,提升模型鲁棒性。对抗样本鲁棒性模块包含了4个子模块:对抗样本的生成、对抗样本的检测、模型防御、攻防评估。 | |||
| 对抗样本鲁棒性模块的架构图如下: | |||
|  | |||
| ### Fuzz Testing模块 | |||
| Fuzz Testing模块是针对AI模型的安全测试,根据神经网络的特点,引入神经元覆盖率,作为Fuzz测试的指导,引导Fuzzer朝着神经元覆盖率增加的方向生成样本,让输入能够激活更多的神经元,神经元值的分布范围更广,以充分测试神经网络,探索不同类型的模型输出结果和错误行为。 | |||
| Fuzz Testing模块的架构图如下: | |||
|  | |||
| ### 隐私保护模块 | |||
| 隐私保护模块包含差分隐私训练与隐私泄露评估。 | |||
| #### 差分隐私训练模块 | |||
| 差分隐私训练包括动态或者非动态的差分隐私`SGD`、`Momentum`、`Adam`优化器,噪声机制支持高斯分布噪声、拉普拉斯分布噪声,差分隐私预算监测包含ZCDP、RDP。 | |||
| 差分隐私的架构图如下: | |||
|  | |||
| #### 隐私泄露评估模块 | |||
| 隐私泄露评估模块用于评估模型泄露用户隐私的风险。利用成员推理方法来推测样本是否属于用户训练数据集,从而评估深度学习模型的隐私数据安全。 | |||
| 隐私泄露评估模块框架图如下: | |||
|  | |||
| ## 开始 | |||
| ### 确认系统环境信息 | |||
| - 硬件平台为Ascend、GPU或CPU。 | |||
| - 参考[MindSpore安装指南](https://www.mindspore.cn/install),完成MindSpore的安装。 | |||
| MindArmour与MindSpore的版本需保持一致。 | |||
| - 其余依赖请参见[setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py)。 | |||
| ### 安装 | |||
| #### MindSpore版本依赖关系 | |||
| 由于MindArmour与MindSpore有依赖关系,请按照下表所示的对应关系,在[MindSpore下载页面](https://www.mindspore.cn/versions)下载并安装对应的whl包。 | |||
| | MindArmour | 分支 | MindSpore | | |||
| | ---------- | --------------------------------------------------------- | --------- | | |||
| | 2.0.0 | [r2.0](https://gitee.com/mindspore/mindarmour/tree/r2.0/) | >=1.7.0 | | |||
| | 1.9.0 | [r1.9](https://gitee.com/mindspore/mindarmour/tree/r1.9/) | >=1.7.0 | | |||
| | 1.8.0 | [r1.8](https://gitee.com/mindspore/mindarmour/tree/r1.8/) | >=1.7.0 | | |||
| | 1.7.0 | [r1.7](https://gitee.com/mindspore/mindarmour/tree/r1.7/) | r1.7 | | |||
| #### 源码安装 | |||
| 1. 从Gitee下载源码。 | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| 2. 在源码根目录下,执行如下命令编译并安装MindArmour。 | |||
| ```bash | |||
| cd mindarmour | |||
| python setup.py install | |||
| ``` | |||
| #### pip安装 | |||
| ```bash | |||
| pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindArmour/{arch}/mindarmour-{version}-cp37-cp37m-linux_{arch}.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple | |||
| ``` | |||
| > - 在联网状态下,安装whl包时会自动下载MindArmour安装包的依赖项(依赖项详情参见[setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py)),其余情况需自行安装。 | |||
| > - `{version}`表示MindArmour版本号,例如下载1.0.1版本MindArmour时,`{version}`应写为1.0.1。 | |||
| > - `{arch}`表示系统架构,例如使用的Linux系统是x86架构64位时,`{arch}`应写为`x86_64`。如果系统是ARM架构64位,则写为`aarch64`。 | |||
| ### 验证是否成功安装 | |||
| 执行如下命令,如果没有报错`No module named 'mindarmour'`,则说明安装成功。 | |||
| ```bash | |||
| python -c 'import mindarmour' | |||
| ``` | |||
| ## 文档 | |||
| 安装指导、使用教程、API,请参考[用户文档](https://gitee.com/mindspore/docs)。 | |||
| ## 社区 | |||
| 社区问答:[MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ)。 | |||
| ## 贡献 | |||
| 欢迎参与社区贡献,详情参考[Contributor Wiki](https://gitee.com/mindspore/mindspore/blob/master/CONTRIBUTING.md)。 | |||
| ## 版本 | |||
| 版本信息参考:[RELEASE](RELEASE.md)。 | |||
| ## 版权 | |||
| [Apache License 2.0](LICENSE) | |||
+ 5
- 373
RELEASE.md
View File
| @@ -1,379 +1,11 @@ | |||
| # MindArmour Release Notes | |||
| ## MindArmour 2.0.0 Release Notes | |||
| ### API Change | |||
| * Add version check with MindSpore. | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Zhidan, Zhang Shukun, Liu Liu, Tang Cong. | |||
| Contributions of any kind are welcome! | |||
| ## MindArmour 1.9.0 Release Notes | |||
| ### API Change | |||
| * Add Chinese version api of natural robustness feature. | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Zhidan, Zhang Shukun, Jin Xiulang, Liu Liu, Tang Cong, Yangyuan. | |||
| Contributions of any kind are welcome! | |||
| ## MindArmour 1.8.0 Release Notes | |||
| ### API Change | |||
| * Add Chinese version of all existed api. | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Zhang Shukun, Liu Zhidan, Jin Xiulang, Liu Liu, Tang Cong, Yangyuan. | |||
| Contributions of any kind are welcome! | |||
| ## MindArmour 1.7.0 Release Notes | |||
| ### Major Features and Improvements | |||
| #### Robustness | |||
| * [STABLE] Real-World Robustness Evaluation Methods | |||
| ### API Change | |||
| * Change value of parameter `mutate_config` in `mindarmour.fuzz_testing.Fuzzer.fuzzing` interface. ([!333](https://gitee.com/mindspore/mindarmour/pulls/333)) | |||
| ### Bug fixes | |||
| * Update version of third-party dependence pillow from more than or equal to 6.2.0 to more than or equal to 7.2.0. ([!329](https://gitee.com/mindspore/mindarmour/pulls/329)) | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Zhidan, Zhang Shukun, Jin Xiulang, Liu Liu. | |||
| Contributions of any kind are welcome! | |||
| # MindArmour 1.6.0 | |||
| ## MindArmour 1.6.0 Release Notes | |||
| ### Major Features and Improvements | |||
| #### Reliability | |||
| * [BETA] Data Drift Detection for Image Data | |||
| * [BETA] Model Fault Injection | |||
| ### Bug fixes | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Wu Xiaoyu,Feng Zhenye, Liu Zhidan, Jin Xiulang, Liu Luobin, Liu Liu, Zhang Shukun | |||
| # MindArmour 1.5.0 | |||
| ## MindArmour 1.5.0 Release Notes | |||
| ### Major Features and Improvements | |||
| #### Reliability | |||
| * [BETA] Reconstruct AI Fuzz and Neuron Coverage Metrics | |||
| ### Bug fixes | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Wu Xiaoyu,Liu Zhidan, Jin Xiulang, Liu Luobin, Liu Liu | |||
| # MindArmour 1.3.0-rc1 | |||
| ## MindArmour 1.3.0 Release Notes | |||
| ### Major Features and Improvements | |||
| #### Privacy | |||
| * [STABLE] Data Drift Detection for Time Series Data | |||
| ### Bug fixes | |||
| * [BUGFIX] Optimization of API description. | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| Wu Xiaoyu,Liu Zhidan, Jin Xiulang, Liu Luobin, Liu Liu | |||
| # MindArmour 1.2.0 | |||
| ## MindArmour 1.2.0 Release Notes | |||
| ### Major Features and Improvements | |||
| #### Privacy | |||
| * [STABLE] Tailored-based privacy protection technology (Pynative) | |||
| * [STABLE] Model Inversion. Reverse analysis technology of privacy information | |||
| ### API Change | |||
| #### Backwards Incompatible Change | |||
| ##### C++ API | |||
| [Modify] ... | |||
| [Add] ... | |||
| [Delete] ... | |||
| ##### Java API | |||
| [Add] ... | |||
| #### Deprecations | |||
| ##### C++ API | |||
| ##### Java API | |||
| ### Bug fixes | |||
| [BUGFIX] ... | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| han.yin | |||
| # MindArmour 1.1.0 Release Notes | |||
| ## MindArmour | |||
| ### Major Features and Improvements | |||
| * [STABLE] Attack capability of the Object Detection models. | |||
| * Some white-box adversarial attacks, such as [iterative] gradient method and DeepFool now can be applied to Object Detection models. | |||
| * Some black-box adversarial attacks, such as PSO and Genetic Attack now can be applied to Object Detection models. | |||
| ### Backwards Incompatible Change | |||
| #### Python API | |||
| #### C++ API | |||
| ### Deprecations | |||
| #### Python API | |||
| #### C++ API | |||
| ### New Features | |||
| #### Python API | |||
| #### C++ API | |||
| ### Improvements | |||
| #### Python API | |||
| #### C++ API | |||
| ### Bug fixes | |||
| #### Python API | |||
| #### C++ API | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Xiulang Jin, Zhidan Liu, Luobin Liu and Liu Liu. | |||
| Contributions of any kind are welcome! | |||
| # Release 1.0.0 | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Privacy leakage evaluation. | |||
| * Parameter verification enhancement. | |||
| * Support parallel computing. | |||
| ### Model robustness evaluation | |||
| * Fuzzing based Adversarial Robustness testing. | |||
| * Parameter verification enhancement. | |||
| ### Other | |||
| * Api & Directory Structure | |||
| * Adjusted the directory structure based on different features. | |||
| * Optimize the structure of examples. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Xiulang Jin, Zhidan Liu and Luobin Liu. | |||
| Contributions of any kind are welcome! | |||
| # Release 0.7.0-beta | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Privacy leakage evaluation. | |||
| * Using Membership inference to evaluate the effectiveness of privacy-preserving techniques for AI. | |||
| ### Model robustness evaluation | |||
| * Fuzzing based Adversarial Robustness testing. | |||
| * Coverage-guided test set generation. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Xiulang Jin, Zhidan Liu, Luobin Liu and Huanhuan Zheng. | |||
| Contributions of any kind are welcome! | |||
| # Release 0.6.0-beta | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Optimizers with differential privacy | |||
| * Differential privacy model training now supports some new policies. | |||
| * Adaptive Norm policy is supported. | |||
| * Adaptive Noise policy with exponential decrease is supported. | |||
| * Differential Privacy Training Monitor | |||
| * A new monitor is supported using zCDP as its asymptotic budget estimator. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, XiuLang jin, Zhidan liu. | |||
| Contributions of any kind are welcome. | |||
| # Release 0.5.0-beta | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Optimizers with differential privacy | |||
| * Differential privacy model training now supports both Pynative mode and graph mode. | |||
| * Graph mode is recommended for its performance. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, Xiulang Jin, Zhidan Liu. | |||
| Contributions of any kind are welcome! | |||
| # Release 0.3.0-alpha | |||
| ## Major Features and Improvements | |||
| ### Differential Privacy Model Training | |||
| Differential Privacy is coming! By using Differential-Privacy-Optimizers, one can still train a model as usual, while the trained model preserved the privacy of training dataset, satisfying the definition of | |||
| differential privacy with proper budget. | |||
| * Optimizers with Differential Privacy([PR23](https://gitee.com/mindspore/mindarmour/pulls/23), [PR24](https://gitee.com/mindspore/mindarmour/pulls/24)) | |||
| * Some common optimizers now have a differential privacy version (SGD/Adam). We are adding more. | |||
| * Automatically and adaptively add Gaussian Noise during training to achieve Differential Privacy. | |||
| * Automatically stop training when Differential Privacy Budget exceeds. | |||
| * Differential Privacy Monitor([PR22](https://gitee.com/mindspore/mindarmour/pulls/22)) | |||
| * Calculate overall budget consumed during training, indicating the ultimate protect effect. | |||
| ## Bug fixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, Zhidan Liu, Xiulang Jin | |||
| Contributions of any kind are welcome! | |||
| # Release 0.2.0-alpha | |||
| ## Major Features and Improvements | |||
| * Add a white-box attack method: M-DI2-FGSM([PR14](https://gitee.com/mindspore/mindarmour/pulls/14)). | |||
| * Add three neuron coverage metrics: KMNCov, NBCov, SNACov([PR12](https://gitee.com/mindspore/mindarmour/pulls/12)). | |||
| * Add a coverage-guided fuzzing test framework for deep neural networks([PR13](https://gitee.com/mindspore/mindarmour/pulls/13)). | |||
| * Update the MNIST Lenet5 examples. | |||
| * Remove some duplicate code. | |||
| ## Bug fixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, Zhidan Liu, Xiulang Jin | |||
| Contributions of any kind are welcome! | |||
| # Release 0.1.0-alpha | |||
| Initial release of MindArmour. | |||
| ## Major Features | |||
| * Support adversarial attack and defense on the platform of MindSpore. | |||
| * Include 13 white-box and 7 black-box attack methods. | |||
| * Provide 5 detection algorithms to detect attacking in multiple way. | |||
| * Provide adversarial training to enhance model security. | |||
| * Provide 6 evaluation metrics for attack methods and 9 evaluation metrics for defense methods. | |||
| - Support adversarial attack and defense on the platform of MindSpore. | |||
| - Include 13 white-box and 7 black-box attack methods. | |||
| - Provide 5 detection algorithms to detect attacking in multiple way. | |||
| - Provide adversarial training to enhance model security. | |||
| - Provide 6 evaluation metrics for attack methods and 9 evaluation metrics for defense methods. | |||
+ 0
- 69
RELEASE_CN.md
View File
| @@ -1,69 +0,0 @@ | |||
| # MindArmour Release Notes | |||
| [View English](./RELEASE.md) | |||
| ## MindArmour 2.0.0 Release Notes | |||
| ### API Change | |||
| * 增加与MindSpore的版本校验关系。 | |||
| ### 贡献 | |||
| 感谢以下人员做出的贡献: | |||
| Liu Zhidan, Zhang Shukun, Liu Liu, Tang Cong. | |||
| 欢迎以任何形式对项目提供贡献! | |||
| ## MindArmour 1.9.0 Release Notes | |||
| ### API Change | |||
| * 增加自然鲁棒性特性的api中文版本 | |||
| ### 贡献 | |||
| 感谢以下人员做出的贡献: | |||
| Liu Zhidan, Zhang Shukun, Jin Xiulang, Liu Liu, Tang Cong, Yangyuan. | |||
| 欢迎以任何形式对项目提供贡献! | |||
| ## MindArmour 1.8.0 Release Notes | |||
| ### API Change | |||
| * 增加所有特性的api中文版本 | |||
| ### 贡献 | |||
| 感谢以下人员做出的贡献: | |||
| Zhang Shukun, Liu Zhidan, Jin Xiulang, Liu Liu, Tang Cong, Yangyuan. | |||
| 欢迎以任何形式对项目提供贡献! | |||
| ## MindArmour 1.7.0 Release Notes | |||
| ### 主要特性和增强 | |||
| #### 鲁棒性 | |||
| * [STABLE] 自然扰动评估方法 | |||
| ### API Change | |||
| * 接口`mindarmour.fuzz_testing.Fuzzer.fuzzing`的参数`mutate_config`的取值范围变化。 ([!333](https://gitee.com/mindspore/mindarmour/pulls/333)) | |||
| ### Bug修复 | |||
| * 更新第三方依赖pillow的版本从大于等于6.2.0更新为大于等于7.2.0. ([!329](https://gitee.com/mindspore/mindarmour/pulls/329)) | |||
| ### 贡献 | |||
| 感谢以下人员做出的贡献: | |||
| Liu Zhidan, Zhang Shukun, Jin Xiulang, Liu Liu. | |||
| 欢迎以任何形式对项目提供贡献! | |||
BIN
docs/adversarial_robustness_cn.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 4705 | Height: 2601 | Size: 238 kB |
BIN
docs/adversarial_robustness_en.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 4737 | Height: 2705 | Size: 297 kB |
+ 0
- 618
docs/api/api_python/mindarmour.adv_robustness.attacks.rst
View File
| @@ -1,618 +0,0 @@ | |||
| mindarmour.adv_robustness.attacks | |||
| ================================= | |||
| 本模块包括经典的黑盒和白盒攻击算法,以制作对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.FastGradientMethod(network, eps=0.07, alpha=None, bounds=(0.0, 1.0), norm_level=2, is_targeted=False, loss_fn=None) | |||
| 基于梯度计算的单步攻击,扰动的范数包括 'L1'、'L2'和'Linf'。 | |||
| 参考文献:`I. J. Goodfellow, J. Shlens, and C. Szegedy, "Explaining and harnessing adversarial examples," in ICLR, 2015. <https://arxiv.org/abs/1412.6572>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.07。 | |||
| - **alpha** (Union[float, None]) - 单步随机扰动与数据范围的比例。默认值:None。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值, 数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **norm_level** (Union[int, str, numpy.inf]) - 范数类型。 | |||
| 可取值:numpy.inf、1、2、'1'、'2'、'l1'、'l2'、'np.inf'、'inf'、'linf'。默认值:2。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **loss_fn** (Union[loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.RandomFastGradientMethod(network, eps=0.07, alpha=0.035, bounds=(0.0, 1.0), norm_level=2, is_targeted=False, loss_fn=None) | |||
| 使用随机扰动的快速梯度法(Fast Gradient Method)。 | |||
| 基于梯度计算的单步攻击,其对抗性噪声是根据输入的梯度生成的,然后加入随机扰动,从而生成对抗样本。 | |||
| 参考文献:`Florian Tramer, Alexey Kurakin, Nicolas Papernot, "Ensemble adversarial training: Attacks and defenses" in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.07。 | |||
| - **alpha** (float) - 单步随机扰动与数据范围的比例。默认值:0.035。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **norm_level** (Union[int, str, numpy.inf]) - 范数类型。 | |||
| 可取值:numpy.inf、1、2、'1'、'2'、'l1'、'l2'、'np.inf'、'inf'、'linf'。默认值:2。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **loss_fn** (Union[loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| 异常: | |||
| - **ValueError** - `eps` 小于 `alpha` 。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.FastGradientSignMethod(network, eps=0.07, alpha=None, bounds=(0.0, 1.0), is_targeted=False, loss_fn=None) | |||
| 快速梯度下降法(Fast Gradient Sign Method)攻击计算输入数据的梯度,然后使用梯度的符号创建对抗性噪声。 | |||
| 参考文献:`Ian J. Goodfellow, J. Shlens, and C. Szegedy, "Explaining and harnessing adversarial examples," in ICLR, 2015 <https://arxiv.org/abs/1412.6572>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.07。 | |||
| - **alpha** (Union[float, None]) - 单步随机扰动与数据范围的比例。默认值:None。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.RandomFastGradientSignMethod(network, eps=0.07, alpha=0.035, bounds=(0.0, 1.0), is_targeted=False, loss_fn=None) | |||
| 快速梯度下降法(Fast Gradient Sign Method)使用随机扰动。 | |||
| 随机快速梯度符号法(Random Fast Gradient Sign Method)攻击计算输入数据的梯度,然后使用带有随机扰动的梯度符号来创建对抗性噪声。 | |||
| 参考文献:`F. Tramer, et al., "Ensemble adversarial training: Attacks and defenses," in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.07。 | |||
| - **alpha** (float) - 单步随机扰动与数据范围的比例。默认值:0.005。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| 异常: | |||
| - **ValueError** - `eps` 小于 `alpha` 。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.LeastLikelyClassMethod(network, eps=0.07, alpha=None, bounds=(0.0, 1.0), loss_fn=None) | |||
| 单步最不可能类方法(Single Step Least-Likely Class Method)是FGSM的变体,它以最不可能类为目标,以生成对抗样本。 | |||
| 参考文献:`F. Tramer, et al., "Ensemble adversarial training: Attacks and defenses," in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.07。 | |||
| - **alpha** (Union[float, None]) - 单步随机扰动与数据范围的比例。默认值:None。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.RandomLeastLikelyClassMethod(network, eps=0.07, alpha=0.035, bounds=(0.0, 1.0), loss_fn=None) | |||
| 随机最不可能类攻击方法:以置信度最小类别对应的梯度加一个随机扰动为攻击方向。 | |||
| 具有随机扰动的单步最不可能类方法(Single Step Least-Likely Class Method)是随机FGSM的变体,它以最不可能类为目标,以生成对抗样本。 | |||
| 参考文献:`F. Tramer, et al., "Ensemble adversarial training: Attacks and defenses," in ICLR, 2018 <https://arxiv.org/abs/1705.07204>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.07。 | |||
| - **alpha** (float) - 单步随机扰动与数据范围的比例。默认值:0.005。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| 异常: | |||
| - **ValueError** - `eps` 小于 `alpha` 。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.IterativeGradientMethod(network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), nb_iter=5, loss_fn=None) | |||
| 所有基于迭代梯度的攻击的抽象基类。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的对抗性扰动占数据范围的比例。默认值:0.3。 | |||
| - **eps_iter** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.1。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **nb_iter** (int) - 迭代次数。默认值:5。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入样本和原始/目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 良性输入样本,用于创建对抗样本。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 原始/目标标签。若每个输入有多个标签,将它包装在元组中。 | |||
| 异常: | |||
| - **NotImplementedError** - 此函数在迭代梯度方法中不可用。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.BasicIterativeMethod(network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), is_targeted=False, nb_iter=5, loss_fn=None) | |||
| 基本迭代法(Basic Iterative Method)攻击,一种生成对抗示例的迭代FGSM方法。 | |||
| 参考文献:`A. Kurakin, I. Goodfellow, and S. Bengio, "Adversarial examples in the physical world," in ICLR, 2017 <https://arxiv.org/abs/1607.02533>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的对抗性扰动占数据范围的比例。默认值:0.3。 | |||
| - **eps_iter** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.1。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **nb_iter** (int) - 迭代次数。默认值:5。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 使用迭代FGSM方法生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 良性输入样本,用于创建对抗样本。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 原始/目标标签。若每个输入有多个标签,将它包装在元组中。 | |||
| 返回: | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.MomentumIterativeMethod(network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), is_targeted=False, nb_iter=5, decay_factor=1.0, norm_level='inf', loss_fn=None) | |||
| 动量迭代法(Momentum Iterative Method)攻击,通过在迭代中积累损失函数的梯度方向上的速度矢量,加速梯度下降算法,如FGSM、FGM和LLCM,从而生成对抗样本。 | |||
| 参考文献:`Y. Dong, et al., "Boosting adversarial attacks with momentum," arXiv:1710.06081, 2017 <https://arxiv.org/abs/1710.06081>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的对抗性扰动占数据范围的比例。默认值:0.3。 | |||
| - **eps_iter** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.1。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。 | |||
| 以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **nb_iter** (int) - 迭代次数。默认值:5。 | |||
| - **decay_factor** (float) - 迭代中的衰变因子。默认值:1.0。 | |||
| - **norm_level** (Union[int, str, numpy.inf]) - 范数类型。 | |||
| 可取值:numpy.inf、1、2、'1'、'2'、'l1'、'l2'、'np.inf'、'inf'、'linf'。默认值:numpy.inf。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和原始/目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 良性输入样本,用于创建对抗样本。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 原始/目标标签。若每个输入有多个标签,将它包装在元组中。 | |||
| 返回: | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.ProjectedGradientDescent(network, eps=0.3, eps_iter=0.1, bounds=(0.0, 1.0), is_targeted=False, nb_iter=5, norm_level='inf', loss_fn=None) | |||
| 投影梯度下降(Projected Gradient Descent)攻击是基本迭代法的变体,在这种方法中,每次迭代之后,扰动被投影在指定半径的p范数球上(除了剪切对抗样本的值,使其位于允许的数据范围内)。这是Madry等人提出的用于对抗性训练的攻击。 | |||
| 参考文献:`A. Madry, et al., "Towards deep learning models resistant to adversarial attacks," in ICLR, 2018 <https://arxiv.org/abs/1706.06083>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的对抗性扰动占数据范围的比例。默认值:0.3。 | |||
| - **eps_iter** (float) - 攻击产生的单步对抗扰动占数据范围的比例。默认值:0.1。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **nb_iter** (int) - 迭代次数。默认值:5。 | |||
| - **norm_level** (Union[int, str, numpy.inf]) - 范数类型。 | |||
| 可取值:numpy.inf、1、2、'1'、'2'、'l1'、'l2'、'np.inf'、'inf'、'linf'。默认值:'numpy.inf'。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 基于BIM方法迭代生成对抗样本。通过带有参数norm_level的投影方法归一化扰动。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 良性输入样本,用于创建对抗样本。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 原始/目标标签。若每个输入有多个标签,将它包装在元组中。 | |||
| 返回: | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.DiverseInputIterativeMethod(network, eps=0.3, bounds=(0.0, 1.0), is_targeted=False, prob=0.5, loss_fn=None) | |||
| 多样性输入迭代法(Diverse Input Iterative Method)攻击遵循基本迭代法,并在每次迭代时对输入数据应用随机转换。对输入数据的这种转换可以提高对抗样本的可转移性。 | |||
| 参考文献:`Xie, Cihang and Zhang, et al., "Improving Transferability of Adversarial Examples With Input Diversity," in CVPR, 2019 <https://arxiv.org/abs/1803.06978>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的对抗性扰动占数据范围的比例。默认值:0.3。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **prob** (float) - 对输入样本的转换概率。默认值:0.5。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.MomentumDiverseInputIterativeMethod(network, eps=0.3, bounds=(0.0, 1.0), is_targeted=False, norm_level='l1', prob=0.5, loss_fn=None) | |||
| 动量多样性输入迭代法(Momentum Diverse Input Iterative Method)攻击是一种动量迭代法,在每次迭代时对输入数据应用随机变换。对输入数据的这种转换可以提高对抗样本的可转移性。 | |||
| 参考文献:`Xie, Cihang and Zhang, et al., "Improving Transferability of Adversarial Examples With Input Diversity," in CVPR, 2019 <https://arxiv.org/abs/1803.06978>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **eps** (float) - 攻击产生的对抗性扰动占数据范围的比例。默认值:0.3。 | |||
| - **bounds** (tuple) - 数据的上下界,表示数据范围。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **norm_level** (Union[int, str, numpy.inf]) - 范数类型。 | |||
| 可取值:numpy.inf、1、2、'1'、'2'、'l1'、'l2'、'np.inf'、'inf'、'linf'。默认值:'l1'。 | |||
| - **prob** (float) - 对输入样本的转换概率。默认值:0.5。 | |||
| - **loss_fn** (Union[Loss, None]) - 用于优化的损失函数。如果为None,则输入网络已配备损失函数。默认值:None。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.DeepFool(network, num_classes, model_type='classification', reserve_ratio=0.3, max_iters=50, overshoot=0.02, norm_level=2, bounds=None, sparse=True) | |||
| DeepFool是一种无目标的迭代攻击,通过将良性样本移动到最近的分类边界并跨越边界来实现。 | |||
| 参考文献:`DeepFool: a simple and accurate method to fool deep neural networks <https://arxiv.org/abs/1511.04599>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **num_classes** (int) - 模型输出的标签数,应大于零。 | |||
| - **model_type** (str) - 目标模型的类型。现在支持'classification'和'detection'。默认值:'classification'。 | |||
| - **reserve_ratio** (Union[int, float]) - 攻击后可检测到的对象百分比,仅当model_type='detection'时有效。保留比率应在(0, 1)的范围内。默认值:0.3。 | |||
| - **max_iters** (int) - 最大迭代次数,应大于零。默认值:50。 | |||
| - **overshoot** (float) - 过冲参数。默认值:0.02。 | |||
| - **norm_level** (Union[int, str, numpy.inf]) - 矢量范数类型。可取值:numpy.inf或2。默认值:2。 | |||
| - **bounds** (Union[tuple, list]) - 数据范围的上下界。以(数据最小值,数据最大值)的形式出现。默认值:None。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入样本和原始标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 输入样本。 | |||
| - 如果 `model_type` ='classification',则输入的格式应为numpy.ndarray。输入的格式可以是(input1, input2, ...)。 | |||
| - 如果 `model_type` ='detection',则只能是一个数组。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 目标标签或ground-truth标签。 | |||
| - 如果 `model_type` ='classification',标签的格式应为numpy.ndarray。 | |||
| - 如果 `model_type` ='detection',标签的格式应为(gt_boxes, gt_labels)。 | |||
| 返回: | |||
| - **numpy.ndarray** - 对抗样本。 | |||
| 异常: | |||
| - **NotImplementedError** - `norm_level` 不在[2, numpy.inf, '2', 'inf']中。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.CarliniWagnerL2Attack(network, num_classes, box_min=0.0, box_max=1.0, bin_search_steps=5, max_iterations=1000, confidence=0, learning_rate=5e-3, initial_const=1e-2, abort_early_check_ratio=5e-2, targeted=False, fast=True, abort_early=True, sparse=True) | |||
| 使用L2范数的Carlini & Wagner攻击通过分别利用两个损失生成对抗样本:“对抗损失”可使生成的示例实际上是对抗性的,“距离损失”可以控制对抗样本的质量。 | |||
| 参考文献:`Nicholas Carlini, David Wagner: "Towards Evaluating the Robustness of Neural Networks" <https://arxiv.org/abs/1608.04644>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **num_classes** (int) - 模型输出的标签数,应大于零。 | |||
| - **box_min** (float) - 目标模型输入的下界。默认值:0。 | |||
| - **box_max** (float) - 目标模型输入的上界。默认值:1.0。 | |||
| - **bin_search_steps** (int) - 用于查找距离和置信度之间的最优trade-off常数的二分查找步数。默认值:5。 | |||
| - **max_iterations** (int) - 最大迭代次数,应大于零。默认值:1000。 | |||
| - **confidence** (float) - 对抗样本输出的置信度。默认值:0。 | |||
| - **learning_rate** (float) - 攻击算法的学习率。默认值:5e-3。 | |||
| - **initial_const** (float) - 用于平衡扰动范数和置信度差异的初始trade-off常数。默认值:1e-2。 | |||
| - **abort_early_check_ratio** (float) - 检查所有迭代中所有比率的损失进度。默认值:5e-2。 | |||
| - **targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **fast** (bool) - 如果为True,则返回第一个找到的对抗样本。如果为False,则返回扰动较小的对抗样本。默认值:True。 | |||
| - **abort_early** (bool) - 是否提前终止。 | |||
| - 如果为True,则当损失在一段时间内没有减少,Adam将被中止。 | |||
| - 如果为False,Adam将继续工作,直到到达最大迭代。默认值:True。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的真值标签或目标标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.JSMAAttack(network, num_classes, box_min=0.0, box_max=1.0, theta=1.0, max_iteration=1000, max_count=3, increase=True, sparse=True) | |||
| 基于Jacobian的显著图攻击(Jacobian-based Saliency Map Attack)是一种基于输入特征显著图的有目标的迭代攻击。它使用每个类标签相对于输入的每个组件的损失梯度。然后,使用显著图来选择产生最大误差的维度。 | |||
| 参考文献:`The limitations of deep learning in adversarial settings <https://arxiv.org/abs/1511.07528>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 目标模型。 | |||
| - **num_classes** (int) - 模型输出的标签数,应大于零。 | |||
| - **box_min** (float) - 目标模型输入的下界。默认值:0。 | |||
| - **box_max** (float) - 目标模型输入的上界。默认值:1.0。 | |||
| - **theta** (float) - 一个像素的变化率(相对于输入数据范围)。默认值:1.0。 | |||
| - **max_iteration** (int) - 迭代的最大轮次。默认值:1000。 | |||
| - **max_count** (int) - 每个像素的最大更改次数。默认值:3。 | |||
| - **increase** (bool) - 如果为True,则增加扰动。如果为False,则减少扰动。默认值:True。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 批量生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| - **labels** (numpy.ndarray) - 目标标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.LBFGS(network, eps=1e-5, bounds=(0.0, 1.0), is_targeted=True, nb_iter=150, search_iters=30, loss_fn=None, sparse=False) | |||
| L-BFGS-B攻击使用有限内存BFGS优化算法来最小化输入与对抗样本之间的距离。 | |||
| 参考文献:`Pedro Tabacof, Eduardo Valle. "Exploring the Space of Adversarial Images" <https://arxiv.org/abs/1510.05328>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 被攻击模型的网络。 | |||
| - **eps** (float) - 攻击步长。默认值:1e-5。 | |||
| - **bounds** (tuple) - 数据的上下界。默认值:(0.0, 1.0) | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:True。 | |||
| - **nb_iter** (int) - lbfgs优化器的迭代次数,应大于零。默认值:150。 | |||
| - **search_iters** (int) - 步长的变更数,应大于零。默认值:30。 | |||
| - **loss_fn** (Functions) - 替代模型的损失函数。默认值:None。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:False。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 良性输入样本,用于创建对抗样本。 | |||
| - **labels** (numpy.ndarray) - 原始/目标标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.GeneticAttack(model, model_type='classification', targeted=True, reserve_ratio=0.3, sparse=True, pop_size=6, mutation_rate=0.005, per_bounds=0.15, max_steps=1000, step_size=0.20, temp=0.3, bounds=(0, 1.0), adaptive=False, c=0.1) | |||
| 遗传攻击(Genetic Attack)为基于遗传算法的黑盒攻击,属于差分进化算法。 | |||
| 此攻击是由Moustafa Alzantot等人(2018)提出的。 | |||
| 参考文献: `Moustafa Alzantot, Yash Sharma, Supriyo Chakraborty, "GeneticAttack: Practical Black-box Attacks with Gradient-FreeOptimization" <https://arxiv.org/abs/1805.11090>`_。 | |||
| 参数: | |||
| - **model** (BlackModel) - 目标模型。 | |||
| - **model_type** (str) - 目标模型的类型。现在支持'classification'和'detection'。默认值:'classification'。 | |||
| - **targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。 `model_type` ='detection'仅支持无目标攻击,默认值:True。 | |||
| - **reserve_ratio** (Union[int, float]) - 攻击后可检测到的对象百分比,仅当 `model_type` ='detection'时有效。保留比率应在(0, 1)的范围内。默认值:0.3。 | |||
| - **pop_size** (int) - 粒子的数量,应大于零。默认值:6。 | |||
| - **mutation_rate** (Union[int, float]) - 突变的概率,应在(0,1)的范围内。默认值:0.005。 | |||
| - **per_bounds** (Union[int, float]) - 扰动允许的最大无穷范数距离。 | |||
| - **max_steps** (int) - 每个对抗样本的最大迭代轮次。默认值:1000。 | |||
| - **step_size** (Union[int, float]) - 攻击步长。默认值:0.2。 | |||
| - **temp** (Union[int, float]) - 用于选择的采样温度。默认值:0.3。温度越大,个体选择概率之间的差异就越大。 | |||
| - **bounds** (Union[tuple, list, None]) - 数据的上下界。以(数据最小值,数据最大值)的形式出现。默认值:(0, 1.0)。 | |||
| - **adaptive** (bool) - 为True,则打开突变参数的动态缩放。如果为false,则打开静态突变参数。默认值:False。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| - **c** (Union[int, float]) - 扰动损失的权重。默认值:0.1。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和目标标签(或ground_truth标签)生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 输入样本。 | |||
| - 如果 `model_type` ='classification',则输入的格式应为numpy.ndarray。输入的格式可以是(input1, input2, ...)。 | |||
| - 如果 `model_type` ='detection',则只能是一个数组。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 目标标签或ground-truth标签。 | |||
| - 如果 `model_type` ='classification',标签的格式应为numpy.ndarray。 | |||
| - 如果 `model_type` ='detection',标签的格式应为(gt_boxes, gt_labels)。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个攻击结果的布尔值。 | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| - **numpy.ndarray** - 每个样本的查询次数。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.HopSkipJumpAttack(model, init_num_evals=100, max_num_evals=1000, stepsize_search='geometric_progression', num_iterations=20, gamma=1.0, constraint='l2', batch_size=32, clip_min=0.0, clip_max=1.0, sparse=True) | |||
| Chen、Jordan和Wainwright提出的HopSkipJumpAttack是一种基于决策的攻击。此攻击需要访问目标模型的输出标签。 | |||
| 参考文献:`Chen J, Michael I. Jordan, Martin J. Wainwright. HopSkipJumpAttack: A Query-Efficient Decision-Based Attack. 2019. arXiv:1904.02144 <https://arxiv.org/abs/1904.02144>`_。 | |||
| 参数: | |||
| - **model** (BlackModel) - 目标模型。 | |||
| - **init_num_evals** (int) - 梯度估计的初始评估数。默认值:100。 | |||
| - **max_num_evals** (int) - 梯度估计的最大评估数。默认值:1000。 | |||
| - **stepsize_search** (str) - 表示要如何搜索步长; | |||
| - 可取值为'geometric_progression'或'grid_search'。默认值:'geometric_progression'。 | |||
| - **num_iterations** (int) - 迭代次数。默认值:20。 | |||
| - **gamma** (float) - 用于设置二进制搜索阈值theta。默认值:1.0。 | |||
| 对于l2攻击,二进制搜索阈值 `theta` 为 :math:`gamma / d^{3/2}` 。对于linf攻击是 :math:`gamma/d^2` 。默认值:1.0。 | |||
| - **constraint** (str) - 要优化距离的范数。可取值为'l2'或'linf'。默认值:'l2'。 | |||
| - **batch_size** (int) - 批次大小。默认值:32。 | |||
| - **clip_min** (float, optional) - 最小图像组件值。默认值:0。 | |||
| - **clip_max** (float, optional) - 最大图像组件值。默认值:1。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| 异常: | |||
| - **ValueError** - `stepsize_search` 不在['geometric_progression','grid_search']中。 | |||
| - **ValueError** - `constraint` 不在['l2', 'linf']中 | |||
| .. py:method:: generate(inputs, labels) | |||
| 在for循环中生成对抗图像。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 原始图像。 | |||
| - **labels** (numpy.ndarray) - 目标标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个攻击结果的布尔值。 | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| - **numpy.ndarray** - 每个样本的查询次数。 | |||
| .. py:method:: set_target_images(target_images) | |||
| 设置目标图像进行目标攻击。 | |||
| 参数: | |||
| - **target_images** (numpy.ndarray) - 目标图像。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.NES(model, scene, max_queries=10000, top_k=-1, num_class=10, batch_size=128, epsilon=0.3, samples_per_draw=128, momentum=0.9, learning_rate=1e-3, max_lr=5e-2, min_lr=5e-4, sigma=1e-3, plateau_length=20, plateau_drop=2.0, adv_thresh=0.25, zero_iters=10, starting_eps=1.0, starting_delta_eps=0.5, label_only_sigma=1e-3, conservative=2, sparse=True) | |||
| 该类是自然进化策略(Natural Evolutionary Strategies,NES)攻击法的实现。NES使用自然进化策略来估计梯度,以提高查询效率。NES包括三个设置:Query-Limited设置、Partial-Information置和Label-Only设置。 | |||
| - 在'query-limit'设置中,攻击对目标模型的查询数量有限,但可以访问所有类的概率。 | |||
| - 在'partial-info'设置中,攻击仅有权访问top-k类的概率。 | |||
| - 在'label-only'设置中,攻击只能访问按其预测概率排序的k个推断标签列表。 | |||
| 在Partial-Information设置和Label-Only设置中,NES会进行目标攻击,因此用户需要使用set_target_images方法来设置目标类的目标图像。 | |||
| 参考文献:`Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. In ICML, July 2018 <https://arxiv.org/abs/1804.08598>`_。 | |||
| 参数: | |||
| - **model** (BlackModel) - 要攻击的目标模型。 | |||
| - **scene** (str) - 确定算法的场景,可选值为:'Label_Only'、'Partial_Info'、'Query_Limit'。 | |||
| - **max_queries** (int) - 生成对抗样本的最大查询编号。默认值:10000。 | |||
| - **top_k** (int) - 用于'Partial-Info'或'Label-Only'设置,表示攻击者可用的(Top-k)信息数量。对于Query-Limited设置,此输入应设置为-1。默认值:-1。 | |||
| - **num_class** (int) - 数据集中的类数。默认值:10。 | |||
| - **batch_size** (int) - 批次大小。默认值:128。 | |||
| - **epsilon** (float) - 攻击中允许的最大扰动。默认值:0.3。 | |||
| - **samples_per_draw** (int) - 对偶采样中绘制的样本数。默认值:128。 | |||
| - **momentum** (float) - 动量。默认值:0.9。 | |||
| - **learning_rate** (float) - 学习率。默认值:1e-3。 | |||
| - **max_lr** (float) - 最大学习率。默认值:5e-2。 | |||
| - **min_lr** (float) - 最小学习率。默认值:5e-4。 | |||
| - **sigma** (float) - 随机噪声的步长。默认值:1e-3。 | |||
| - **plateau_length** (int) - 退火算法中使用的平台长度。默认值:20。 | |||
| - **plateau_drop** (float) - 退火算法中使用的平台Drop。默认值:2.0。 | |||
| - **adv_thresh** (float) - 对抗阈值。默认值:0.25。 | |||
| - **zero_iters** (int) - 用于代理分数的点数。默认值:10。 | |||
| - **starting_eps** (float) - Label-Only设置中使用的启动epsilon。默认值:1.0。 | |||
| - **starting_delta_eps** (float) - Label-Only设置中使用的delta epsilon。默认值:0.5。 | |||
| - **label_only_sigma** (float) - Label-Only设置中使用的Sigma。默认值:1e-3。 | |||
| - **conservative** (int) - 用于epsilon衰变的守恒,如果没有收敛,它将增加。默认值:2。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 良性输入样本。 | |||
| - **labels** (numpy.ndarray) - 目标标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个攻击结果的布尔值。 | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| - **numpy.ndarray** - 每个样本的查询次数。 | |||
| 异常: | |||
| - **ValueError** - 在'Label-Only'或'Partial-Info'设置中 `top_k` 小于0。 | |||
| - **ValueError** - 在'Label-Only'或'Partial-Info'设置中target_imgs为None。 | |||
| - **ValueError** - `scene` 不在['Label_Only', 'Partial_Info', 'Query_Limit']中 | |||
| .. py:method:: set_target_images(target_images) | |||
| 在'Partial-Info'或'Label-Only'设置中设置目标攻击的目标样本。 | |||
| 参数: | |||
| - **target_images** (numpy.ndarray) - 目标攻击的目标样本。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.PointWiseAttack(model, max_iter=1000, search_iter=10, is_targeted=False, init_attack=None, sparse=True) | |||
| 点式攻击(Pointwise Attack)确保使用最小数量的更改像素为每个原始样本生成对抗样本。那些更改的像素将使用二进制搜索,以确保对抗样本和原始样本之间的距离尽可能接近。 | |||
| 参考文献:`L. Schott, J. Rauber, M. Bethge, W. Brendel: "Towards the first adversarially robust neural network model on MNIST", ICLR (2019) <https://arxiv.org/abs/1805.09190>`_。 | |||
| 参数: | |||
| - **model** (BlackModel) - 目标模型。 | |||
| - **max_iter** (int) - 生成对抗图像的最大迭代轮数。默认值:1000。 | |||
| - **search_iter** (int) - 二进制搜索的最大轮数。默认值:10。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **init_attack** (Union[Attack, None]) - 用于查找起点的攻击。默认值:None。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入样本和目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 良性输入样本,用于创建对抗样本。 | |||
| - **labels** (numpy.ndarray) - 对于有目标的攻击,标签是对抗性的目标标签。对于无目标攻击,标签是ground-truth标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个攻击结果的布尔值。 | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| - **numpy.ndarray** - 每个样本的查询次数。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.PSOAttack(model, model_type='classification', targeted=False, reserve_ratio=0.3, sparse=True, step_size=0.5, per_bounds=0.6, c1=2.0, c2=2.0, c=2.0, pop_size=6, t_max=1000, pm=0.5, bounds=None) | |||
| PSO攻击表示基于粒子群优化(Particle Swarm Optimization)算法的黑盒攻击,属于进化算法。 | |||
| 此攻击由Rayan Mosli等人(2019)提出。 | |||
| 参考文献:`Rayan Mosli, Matthew Wright, Bo Yuan, Yin Pan, "They Might NOT Be Giants: Crafting Black-Box Adversarial Examples with Fewer Queries Using Particle Swarm Optimization", arxiv: 1909.07490, 2019. <https://arxiv.org/abs/1909.07490>`_。 | |||
| 参数: | |||
| - **model** (BlackModel) - 目标模型。 | |||
| - **step_size** (Union[int, float]) - 攻击步长。默认值:0.5。 | |||
| - **per_bounds** (Union[int, float]) - 扰动的相对变化范围。默认值:0.6。 | |||
| - **c1** (Union[int, float]) - 权重系数。默认值:2。 | |||
| - **c2** (Union[int, float]) - 权重系数。默认值:2。 | |||
| - **c** (Union[int, float]) - 扰动损失的权重。默认值:2。 | |||
| - **pop_size** (int) - 粒子的数量,应大于零。默认值:6。 | |||
| - **t_max** (int) - 每个对抗样本的最大迭代轮数,应大于零。默认值:1000。 | |||
| - **pm** (Union[int, float]) - 突变的概率,应在(0,1)的范围内。默认值:0.5。 | |||
| - **bounds** (Union[list, tuple, None]) - 数据的上下界。以(数据最小值,数据最大值)的形式出现。默认值:None。 | |||
| - **targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。 `model_type` ='detection'仅支持无目标攻击,默认值:False。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| - **model_type** (str) - 目标模型的类型。现在支持'classification'和'detection'。默认值:'classification'。 | |||
| - **reserve_ratio** (Union[int, float]) - 攻击后可检测到的对象百分比,用于 `model_type` ='detection'模式。保留比率应在(0, 1)的范围内。默认值:0.3。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和目标标签(或ground_truth标签)生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 输入样本。 | |||
| - 如果 `model_type` ='classification',则输入的格式应为numpy.ndarray。输入的格式可以是(input1, input2, ...)。 | |||
| - 如果 `model_type` ='detection',则只能是一个数组。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 目标标签或ground-truth标签。 | |||
| - 如果 `model_type` ='classification',标签的格式应为numpy.ndarray。 | |||
| - 如果 `model_type` ='detection',标签的格式应为(gt_boxes, gt_labels)。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个攻击结果的布尔值。 | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| - **numpy.ndarray** - 每个样本的查询次数。 | |||
| .. py:class:: mindarmour.adv_robustness.attacks.SaltAndPepperNoiseAttack(model, bounds=(0.0, 1.0), max_iter=100, is_targeted=False, sparse=True) | |||
| 增加椒盐噪声的量以生成对抗样本。 | |||
| 参数: | |||
| - **model** (BlackModel) - 目标模型。 | |||
| - **bounds** (tuple) - 数据的上下界。以(数据最小值,数据最大值)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **max_iter** (int) - 生成对抗样本的最大迭代。默认值:100。 | |||
| - **is_targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为one-hot编码。默认值:True。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据输入数据和目标标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 原始的、未受扰动的输入。 | |||
| - **labels** (numpy.ndarray) - 目标标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个攻击结果的布尔值。 | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| - **numpy.ndarray** - 每个样本的查询次数。 | |||
+ 0
- 96
docs/api/api_python/mindarmour.adv_robustness.defenses.rst
View File
| @@ -1,96 +0,0 @@ | |||
| mindarmour.adv_robustness.defenses | |||
| ================================== | |||
| 该模块包括经典的防御算法,用于防御对抗样本,增强模型的安全性和可信性。 | |||
| .. py:class:: mindarmour.adv_robustness.defenses.AdversarialDefense(network, loss_fn=None, optimizer=None) | |||
| 使用给定的对抗样本进行对抗训练。 | |||
| 参数: | |||
| - **network** (Cell) - 要防御的MindSpore网络。 | |||
| - **loss_fn** (Union[Loss, None]) - 损失函数。默认值:None。 | |||
| - **optimizer** (Cell) - 用于训练网络的优化器。默认值:None。 | |||
| .. py:method:: defense(inputs, labels) | |||
| 通过使用输入样本进行训练来增强模型。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 防御操作的损失。 | |||
| .. py:class:: mindarmour.adv_robustness.defenses.AdversarialDefenseWithAttacks(network, attacks, loss_fn=None, optimizer=None, bounds=(0.0, 1.0), replace_ratio=0.5) | |||
| 利用特定的攻击方法和给定的对抗例子进行对抗训练,以增强模型的鲁棒性。 | |||
| 参数: | |||
| - **network** (Cell) - 要防御的MindSpore网络。 | |||
| - **attacks** (list[Attack]) - 攻击方法序列。 | |||
| - **loss_fn** (Union[Loss, None]) - 损失函数。默认值:None。 | |||
| - **optimizer** (Cell) - 用于训练网络的优化器。默认值:None。 | |||
| - **bounds** (tuple) - 数据的上下界。以(clip_min, clip_max)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **replace_ratio** (float) - 用对抗样本替换原始样本的比率,必须在0到1之间。默认值:0.5。 | |||
| 异常: | |||
| - **ValueError** - `replace_ratio` 不在0和1之间。 | |||
| .. py:method:: defense(inputs, labels) | |||
| 通过使用从输入样本生成的对抗样本进行训练来增强模型。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的标签。 | |||
| 返回: | |||
| - **numpy.ndarray** - 对抗性防御操作的损失。 | |||
| .. py:class:: mindarmour.adv_robustness.defenses.NaturalAdversarialDefense(network, loss_fn=None, optimizer=None, bounds=(0.0, 1.0), replace_ratio=0.5, eps=0.1) | |||
| 基于FGSM的对抗性训练。 | |||
| 参考文献:`A. Kurakin, et al., "Adversarial machine learning at scale," in ICLR, 2017 <https://arxiv.org/abs/1611.01236>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 要防御的MindSpore网络。 | |||
| - **loss_fn** (Union[Loss, None]) - 损失函数。默认值:None。 | |||
| - **optimizer** (Cell) - 用于训练网络的优化器。默认值:None。 | |||
| - **bounds** (tuple) - 数据的上下界。以(clip_min, clip_max)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **replace_ratio** (float) - 用对抗样本替换原始样本的比率。默认值:0.5。 | |||
| - **eps** (float) - 攻击方法(FGSM)的步长。默认值:0.1。 | |||
| .. py:class:: mindarmour.adv_robustness.defenses.ProjectedAdversarialDefense(network, loss_fn=None, optimizer=None, bounds=(0.0, 1.0), replace_ratio=0.5, eps=0.3, eps_iter=0.1, nb_iter=5, norm_level='inf') | |||
| 基于PGD的对抗性训练。 | |||
| 参考文献:`A. Madry, et al., "Towards deep learning models resistant to adversarial attacks," in ICLR, 2018 <https://arxiv.org/abs/1611.01236>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 要防御的MindSpore网络。 | |||
| - **loss_fn** (Union[Loss, None]) - 损失函数。默认值:None。 | |||
| - **optimizer** (Cell) - 用于训练网络的优化器。默认值:None。 | |||
| - **bounds** (tuple) - 输入数据的上下界。以(clip_min, clip_max)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **replace_ratio** (float) - 用对抗样本替换原始样本的比率。默认值:0.5。 | |||
| - **eps** (float) - PGD攻击参数epsilon。默认值:0.3。 | |||
| - **eps_iter** (int) - PGD攻击参数,内环epsilon。默认值:0.1。 | |||
| - **nb_iter** (int) - PGD攻击参数,迭代次数。默认值:5。 | |||
| - **norm_level** (Union[int, char, numpy.inf]) - 范数类型。可选值:1、2、np.inf、'l1'、'l2'、'np.inf' 或 'inf'。默认值:'inf'。 | |||
| .. py:class:: mindarmour.adv_robustness.defenses.EnsembleAdversarialDefense(network, attacks, loss_fn=None, optimizer=None, bounds=(0.0, 1.0), replace_ratio=0.5) | |||
| 使用特定攻击方法列表和给定的对抗样本进行对抗训练,以增强模型的鲁棒性。 | |||
| 参数: | |||
| - **network** (Cell) - 要防御的MindSpore网络。 | |||
| - **attacks** (list[Attack]) - 攻击方法序列。 | |||
| - **loss_fn** (Union[Loss, None]) - 损失函数。默认值:None。 | |||
| - **optimizer** (Cell) - 用于训练网络的优化器。默认值:None。 | |||
| - **bounds** (tuple) - 数据的上下界。以(clip_min, clip_max)的形式出现。默认值:(0.0, 1.0)。 | |||
| - **replace_ratio** (float) - 用对抗样本替换原始样本的比率,必须在0到1之间。默认值:0.5。 | |||
| 异常: | |||
| - **ValueError** - `replace_ratio` 不在0和1之间。 | |||
+ 0
- 348
docs/api/api_python/mindarmour.adv_robustness.detectors.rst
View File
| @@ -1,348 +0,0 @@ | |||
| mindarmour.adv_robustness.detectors | |||
| =================================== | |||
| 此模块是用于区分对抗样本和良性样本的检测器方法。 | |||
| .. py:class:: mindarmour.adv_robustness.detectors.ErrorBasedDetector(auto_encoder, false_positive_rate=0.01, bounds=(0.0, 1.0)) | |||
| 检测器重建输入样本,测量重建误差,并拒绝重建误差大的样本。 | |||
| 参考文献: `MagNet: a Two-Pronged Defense against Adversarial Examples, by Dongyu Meng and Hao Chen, at CCS 2017. <https://arxiv.org/abs/1705.09064>`_。 | |||
| 参数: | |||
| - **auto_encoder** (Model) - 一个(训练过的)自动编码器,对输入图片进行重构。 | |||
| - **false_positive_rate** (float) - 检测器的误报率。默认值:0.01。 | |||
| - **bounds** (tuple) - (clip_min, clip_max)。默认值:(0.0, 1.0)。 | |||
| .. py:method:: detect(inputs) | |||
| 检测输入样本是否具有对抗性。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 待判断的可疑样本。 | |||
| 返回: | |||
| - **list[int]** - 样本是否具有对抗性。如果res[i]=1,则索引为i的输入样本是对抗性的。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 检测原始样本和重建样本之间的距离。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| 返回: | |||
| - **float** - 重建样本和原始样本之间的距离。 | |||
| .. py:method:: fit(inputs, labels=None) | |||
| 查找给定数据集的阈值,以区分对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的标签。默认值:None。 | |||
| 返回: | |||
| - **float** - 区分对抗样本和良性样本的阈值。 | |||
| .. py:method:: set_threshold(threshold) | |||
| 设置阈值。 | |||
| 参数: | |||
| - **threshold** (float) - 检测阈值。 | |||
| .. py:method:: transform(inputs) | |||
| 重建输入样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| 返回: | |||
| - **numpy.ndarray** - 重建图像。 | |||
| .. py:class:: mindarmour.adv_robustness.detectors.DivergenceBasedDetector(auto_encoder, model, option='jsd', t=1, bounds=(0.0, 1.0)) | |||
| 基于发散的检测器学习通过js发散来区分正常样本和对抗样本。 | |||
| 参考文献: `MagNet: a Two-Pronged Defense against Adversarial Examples, by Dongyu Meng and Hao Chen, at CCS 2017. <https://arxiv.org/abs/1705.09064>`_。 | |||
| 参数: | |||
| - **auto_encoder** (Model) - 编码器模型。 | |||
| - **model** (Model) - 目标模型。 | |||
| - **option** (str) - 用于计算发散的方法。默认值:'jsd'。 | |||
| - **t** (int) - 用于克服数值问题的温度。默认值:1。 | |||
| - **bounds** (tuple) - 数据的上下界。以(clip_min, clip_max)的形式出现。默认值:(0.0, 1.0)。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 检测原始样本和重建样本之间的距离。 | |||
| 距离由JSD计算。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| 返回: | |||
| - **float** - 距离。 | |||
| 异常: | |||
| - **NotImplementedError** - 不支持参数 `option` 。 | |||
| .. py:class:: mindarmour.adv_robustness.detectors.RegionBasedDetector(model, number_points=10, initial_radius=0.0, max_radius=1.0, search_step=0.01, degrade_limit=0.0, sparse=False) | |||
| 基于区域的检测器利用对抗样本靠近分类边界的事实,并通过集成给定示例周围的信息,以检测输入是否为对抗样本。 | |||
| 参考文献: `Mitigating evasion attacks to deep neural networks via region-based classification <https://arxiv.org/abs/1709.05583>`_。 | |||
| 参数: | |||
| - **model** (Model) - 目标模型。 | |||
| - **number_points** (int) - 从原始样本的超立方体生成的样本数。默认值:10。 | |||
| - **initial_radius** (float) - 超立方体的初始半径。默认值:0.0。 | |||
| - **max_radius** (float) - 超立方体的最大半径。默认值:1.0。 | |||
| - **search_step** (float) - 半径搜索增量。默认值:0.01。 | |||
| - **degrade_limit** (float) - 分类精度的可接受下降。默认值:0.0。 | |||
| - **sparse** (bool) - 如果为True,则输入标签为稀疏编码。如果为False,则输入标签为onehot编码。默认值:False。 | |||
| .. py:method:: detect(inputs) | |||
| 判断输入样本是否具有对抗性。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 待判断的可疑样本。 | |||
| 返回: | |||
| - **list[int]** - 样本是否具有对抗性。如果res[i]=1,则索引为i的输入样本是对抗性的。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 返回原始预测结果和基于区域的预测结果。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| 返回: | |||
| - **numpy.ndarray** - 输入样本的原始预测结果和基于区域的预测结果。 | |||
| .. py:method:: fit(inputs, labels=None) | |||
| 训练检测器来决定最佳半径。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 良性样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的ground truth标签。默认值:None。 | |||
| 返回: | |||
| - **float** - 最佳半径。 | |||
| .. py:method:: set_radius(radius) | |||
| 设置半径。 | |||
| 参数: | |||
| - **radius** (float) - 区域的半径。 | |||
| .. py:method:: transform(inputs) | |||
| 为输入样本生成超级立方体。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| 返回: | |||
| - **numpy.ndarray** - 每个样本对应的超立方体。 | |||
| .. py:class:: mindarmour.adv_robustness.detectors.SpatialSmoothing(model, ksize=3, is_local_smooth=True, metric='l1', false_positive_ratio=0.05) | |||
| 基于空间平滑的检测方法。 | |||
| 使用高斯滤波、中值滤波和均值滤波,模糊原始图像。当模型在样本模糊前后的预测值之间有很大的阈值差异时,将其判断为对抗样本。 | |||
| 参数: | |||
| - **model** (Model) - 目标模型。 | |||
| - **ksize** (int) - 平滑窗口大小。默认值:3。 | |||
| - **is_local_smooth** (bool) - 如果为True,则触发局部平滑。如果为False,则无局部平滑。默认值:True。 | |||
| - **metric** (str) - 距离方法。默认值:'l1'。 | |||
| - **false_positive_ratio** (float) - 良性样本上的假正率。默认值:0.05。 | |||
| .. py:method:: detect(inputs) | |||
| 检测输入样本是否为对抗样本。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 待判断的可疑样本。 | |||
| 返回: | |||
| - **list[int]** - 样本是否具有对抗性。如果res[i]=1,则索引为i的输入样本是对抗样本。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 返回输入样本与其平滑对应样本之间的原始距离值(在应用阈值之前)。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 待判断的可疑样本。 | |||
| 返回: | |||
| - **float** - 距离。 | |||
| .. py:method:: fit(inputs, labels=None) | |||
| 训练检测器来决定阈值。适当的阈值能够确保良性样本上的实际假正率小于给定值。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 良性样本。 | |||
| - **labels** (numpy.ndarray) - 默认None。 | |||
| 返回: | |||
| - **float** - 阈值,大于该距离的距离报告为正,即对抗性。 | |||
| .. py:method:: set_threshold(threshold) | |||
| 设置阈值。 | |||
| 参数: | |||
| - **threshold** (float) - 检测阈值。 | |||
| .. py:class:: mindarmour.adv_robustness.detectors.EnsembleDetector(detectors, policy='vote') | |||
| 集合检测器,通过检测器列表从输入样本中检测对抗样本。 | |||
| 参数: | |||
| - **detectors** (Union[tuple, list]) - 检测器方法列表。 | |||
| - **policy** (str) - 决策策略,取值可为'vote'、'all'、'any'。默认值:'vote' | |||
| .. py:method:: detect(inputs) | |||
| 从输入样本中检测对抗性示例。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 输入样本。 | |||
| 返回: | |||
| - **list[int]** - 样本是否具有对抗性。如果res[i]=1,则索引为i的输入样本是对抗样本。 | |||
| 异常: | |||
| - **ValueError** - 不支持策略。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 此方法在此类中不可用。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 用于创建对抗样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 此函数在集成中不可用。 | |||
| .. py:method:: fit(inputs, labels=None) | |||
| 像机器学习模型一样拟合检测器。此方法在此类中不可用。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 计算阈值的数据。 | |||
| - **labels** (numpy.ndarray) - 数据的标签。默认值:None。 | |||
| 异常: | |||
| - **NotImplementedError** - 此函数在集成中不可用。 | |||
| .. py:method:: transform(inputs) | |||
| 过滤输入样本中的对抗性噪声。 | |||
| 此方法在此类中不可用。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 用于创建对抗样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 此函数在集成中不可用。 | |||
| .. py:class:: mindarmour.adv_robustness.detectors.SimilarityDetector(trans_model, max_k_neighbor=1000, chunk_size=1000, max_buffer_size=10000, tuning=False, fpr=0.001) | |||
| 检测器测量相邻查询之间的相似性,并拒绝与以前的查询非常相似的查询。 | |||
| 参考文献: `Stateful Detection of Black-Box Adversarial Attacks by Steven Chen, Nicholas Carlini, and David Wagner. at arxiv 2019 <https://arxiv.org/abs/1907.05587>`_。 | |||
| 参数: | |||
| - **trans_model** (Model) - 一个MindSpore模型,将输入数据编码为低维向量。 | |||
| - **max_k_neighbor** (int) - 最近邻的最大数量。默认值:1000。 | |||
| - **chunk_size** (int) - 缓冲区大小。默认值:1000。 | |||
| - **max_buffer_size** (int) - 最大缓冲区大小。默认值:10000。 | |||
| - **tuning** (bool) - 计算k个最近邻的平均距离。 | |||
| - 如果'tuning'为true,k= `max_k_neighbor` 。 | |||
| - 如果为False,k=1,..., `max_k_neighbor` 。默认值:False。 | |||
| - **fpr** (float) - 合法查询序列上的误报率。默认值:0.001 | |||
| .. py:method:: clear_buffer() | |||
| 清除缓冲区内存。 | |||
| .. py:method:: detect(inputs) | |||
| 处理查询以检测黑盒攻击。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 查询序列。 | |||
| 异常: | |||
| - **ValueError** - 阈值或set_threshold方法中 `num_of_neighbors` 参数不可用。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 从输入样本中检测对抗样本,如常见机器学习模型中的predict_proba函数。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 用于创建对抗样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 此函数在 `SimilarityDetector` 类(class)中不可用。 | |||
| .. py:method:: fit(inputs, labels=None) | |||
| 处理输入训练数据以计算阈值。 | |||
| 适当的阈值应确保假正率低于给定值。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 用于计算阈值的训练数据。 | |||
| - **labels** (numpy.ndarray) - 训练数据的标签。 | |||
| 返回: | |||
| - **list[int]** - 最近邻的数量。 | |||
| - **list[float]** - 不同k的阈值。 | |||
| 异常: | |||
| - **ValueError** - 训练数据个数小于 `max_k_neighbor`。 | |||
| .. py:method:: get_detected_queries() | |||
| 获取检测到的查询的索引。 | |||
| 返回: | |||
| - **list[int]** - 检测到的恶意查询的序列号。 | |||
| .. py:method:: get_detection_interval() | |||
| 获取相邻检测之间的间隔。 | |||
| 返回: | |||
| - **list[int]** - 相邻检测之间的查询数。 | |||
| .. py:method:: set_threshold(num_of_neighbors, threshold) | |||
| 设置参数num_of_neighbors和threshold。 | |||
| 参数: | |||
| - **num_of_neighbors** (int) - 最近邻的数量。 | |||
| - **threshold** (float) - 检测阈值。 | |||
| .. py:method:: transform(inputs) | |||
| 过滤输入样本中的对抗性噪声。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 用于创建对抗样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 此函数在 `SimilarityDetector` 类(class)中不可用。 | |||
+ 0
- 174
docs/api/api_python/mindarmour.adv_robustness.evaluations.rst
View File
| @@ -1,174 +0,0 @@ | |||
| mindarmour.adv_robustness.evaluations | |||
| ===================================== | |||
| 此模块包括各种指标,用于评估攻击或防御的结果。 | |||
| .. py:class:: mindarmour.adv_robustness.evaluations.AttackEvaluate(inputs, labels, adv_inputs, adv_preds, targeted=False, target_label=None) | |||
| 攻击方法的评估指标。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 原始样本。 | |||
| - **labels** (numpy.ndarray) - 原始样本的one-hot格式标签。 | |||
| - **adv_inputs** (numpy.ndarray) - 从原始样本生成的对抗样本。 | |||
| - **adv_preds** (numpy.ndarray) - 对对抗样本的对所有标签的预测概率。 | |||
| - **targeted** (bool) - 如果为True,则为目标攻击。如果为False,则为无目标攻击。默认值:False。 | |||
| - **target_label** (numpy.ndarray) - 对抗样本的目标标签,是大小为adv_inputs.shape[0]的一维。默认值:None。 | |||
| 异常: | |||
| - **ValueError** - 如果 `targeted` 为True时, `target_label` 为None。 | |||
| .. py:method:: avg_conf_adv_class() | |||
| 计算对抗类的平均置信度(ACAC)。 | |||
| 返回: | |||
| - **float** - 范围在(0,1)之间。值越高,攻击就越成功。 | |||
| .. py:method:: avg_conf_true_class() | |||
| 计算真类的平均置信度(ACTC)。 | |||
| 返回: | |||
| - **float** - 范围在(0,1)之间。值越低,攻击就越成功。 | |||
| .. py:method:: avg_lp_distance() | |||
| 计算平均lp距离(lp-dist)。 | |||
| 返回: | |||
| - **float** - 返回所有成功对抗样本的平均'l0'、'l2'或'linf'距离,返回值包括以下情况: | |||
| - 如果返回值 :math:`>=` 0,则为平均lp距离。值越低,攻击就越成功。 | |||
| - 如果返回值为-1,则没有成功的对抗样本。 | |||
| .. py:method:: avg_ssim() | |||
| 计算平均结构相似性(ASS)。 | |||
| 返回: | |||
| - **float** - 平均结构相似性。 | |||
| - 如果返回值在(0,1)之间,则值越高,攻击越成功。 | |||
| - 如果返回值为-1,则没有成功的对抗样本。 | |||
| .. py:method:: mis_classification_rate() | |||
| 计算错误分类率(MR)。 | |||
| 返回: | |||
| - **float** - 范围在(0,1)之间。值越高,攻击就越成功。 | |||
| .. py:method:: nte() | |||
| 计算噪声容量估计(NTE)。 | |||
| 参考文献:`Towards Imperceptible and Robust Adversarial Example Attacks against Neural Networks <https://arxiv.org/abs/1801.04693>`_。 | |||
| 返回: | |||
| - **float** - 范围在(0,1)之间。值越高,攻击就越成功。 | |||
| .. py:class:: mindarmour.adv_robustness.evaluations.BlackDefenseEvaluate(raw_preds, def_preds, raw_query_counts, def_query_counts, raw_query_time, def_query_time, def_detection_counts, true_labels, max_queries) | |||
| 反黑盒防御方法的评估指标。 | |||
| 参数: | |||
| - **raw_preds** (numpy.ndarray) - 原始模型上特定样本的预测结果。 | |||
| - **def_preds** (numpy.ndarray) - 原始防御模型上特定样本的预测结果。 | |||
| - **raw_query_counts** (numpy.ndarray) - 在原始模型上生成对抗样本的查询数,原始模型是大小是与raw_preds.shape[0]的第一纬度相同。对于良性样本,查询计数必须设置为0。 | |||
| - **def_query_counts** (numpy.ndarray) - 在防御模型上生成对抗样本的查询数,原始模型是大小是与raw_preds.shape[0]的第一纬度相同。对于良性样本,查询计数必须设置为0。 | |||
| - **raw_query_time** (numpy.ndarray) - 在原始模型上生成对抗样本的总持续时间,该样本是大小是与raw_preds.shape[0]的第一纬度。 | |||
| - **def_query_time** (numpy.ndarray) - 在防御模型上生成对抗样本的总持续时间,该样本是大小是与raw_preds.shape[0]的第一纬度。 | |||
| - **def_detection_counts** (numpy.ndarray) - 每次对抗样本生成期间检测到的查询总数,大小是与raw_preds.shape[0]的第一纬度。对于良性样本,如果查询被识别为可疑,则将def_detection_counts设置为1,否则将其设置为0。 | |||
| - **true_labels** (numpy.ndarray) - 大小是与raw_preds.shape[0]的第一纬度真标签。 | |||
| - **max_queries** (int) - 攻击预算,最大查询数。 | |||
| .. py:method:: asv() | |||
| 计算攻击成功率方差(ASV)。 | |||
| 返回: | |||
| - **float** - 值越低,防守就越强。如果num_adv_samples=0,则返回-1。 | |||
| .. py:method:: fpr() | |||
| 计算基于查询的检测器的假正率(FPR)。 | |||
| 返回: | |||
| - **float** - 值越低,防御的可用性越高。如果num_adv_samples=0,则返回-1。 | |||
| .. py:method:: qcv() | |||
| 计算查询计数方差(QCV)。 | |||
| 返回: | |||
| - **float** - 值越高,防守就越强。如果num_adv_samples=0,则返回-1。 | |||
| .. py:method:: qrv() | |||
| 计算良性查询响应时间方差(QRV)。 | |||
| 返回: | |||
| - **float** - 值越低,防御的可用性越高。如果num_adv_samples=0,则返回-1。 | |||
| .. py:class:: mindarmour.adv_robustness.evaluations.DefenseEvaluate(raw_preds, def_preds, true_labels) | |||
| 防御方法的评估指标。 | |||
| 参数: | |||
| - **raw_preds** (numpy.ndarray) - 原始模型上某些样本的预测结果。 | |||
| - **def_preds** (numpy.ndarray) - 防御模型上某些样本的预测结果。 | |||
| - **true_labels** (numpy.ndarray) - 样本的ground-truth标签,一个大小为ground-truth的一维数组。 | |||
| .. py:method:: cav() | |||
| 计算分类精度方差(CAV)。 | |||
| 返回: | |||
| - **float** - 值越高,防守就越成功。 | |||
| .. py:method:: ccv() | |||
| 计算分类置信度方差(CCV)。 | |||
| 返回: | |||
| - **float** - 值越低,防守就越成功。如果返回值== -1,则说明样本数量为0。 | |||
| .. py:method:: cos() | |||
| 参考文献:`Calculate classification output stability (COS) <https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence>`_。 | |||
| 返回: | |||
| - **float** - 如果返回值>=0,则是有效的防御。值越低,防守越成功。如果返回值== -1, 则说明样本数量为0。 | |||
| .. py:method:: crr() | |||
| 计算分类校正率(CRR)。 | |||
| 返回: | |||
| - **float** - 值越高,防守就越成功。 | |||
| .. py:method:: csr() | |||
| 计算分类牺牲比(CSR),越低越好。 | |||
| 返回: | |||
| - **float** - 值越低,防守就越成功。 | |||
| .. py:class:: mindarmour.adv_robustness.evaluations.RadarMetric(metrics_name, metrics_data, labels, title, scale='hide') | |||
| 雷达图,通过多个指标显示模型的鲁棒性。 | |||
| 参数: | |||
| - **metrics_name** (Union[tuple, list]) - 要显示的度量名称数组。每组值对应一条雷达曲线。 | |||
| - **metrics_data** (numpy.ndarray) - 多个雷达曲线的每个度量的(归一化)值,如[[0.5, 0.8, ...], [0.2,0.6,...], ...]。 | |||
| - **labels** (Union[tuple, list]) - 所有雷达曲线的图例。 | |||
| - **title** (str) - 图表的标题。 | |||
| - **scale** (str) - 用于调整轴刻度的标量,如'hide'、'norm'、'sparse'、'dense'。默认值:'hide'。 | |||
| 异常: | |||
| - **ValueError** - `scale` 值不在['hide', 'norm', 'sparse', 'dense']中。 | |||
| .. py:method:: show() | |||
| 显示雷达图。 | |||
+ 0
- 186
docs/api/api_python/mindarmour.fuzz_testing.rst
View File
| @@ -1,186 +0,0 @@ | |||
| mindarmour.fuzz_testing | |||
| ======================= | |||
| 该模块提供了一种基于神经元覆盖率增益的模糊测试方法来评估给定模型的鲁棒性。 | |||
| .. py:class:: mindarmour.fuzz_testing.Fuzzer(target_model) | |||
| 深度神经网络的模糊测试框架。 | |||
| 参考文献:`DeepHunter: A Coverage-Guided Fuzz Testing Framework for Deep Neural Networks <https://dl.acm.org/doi/10.1145/3293882.3330579>`_。 | |||
| 参数: | |||
| - **target_model** (Model) - 目标模糊模型。 | |||
| .. py:method:: fuzzing(mutate_config, initial_seeds, coverage, evaluate=True, max_iters=10000, mutate_num_per_seed=20) | |||
| 深度神经网络的模糊测试。 | |||
| 参数: | |||
| - **mutate_config** (list) - 变异方法配置。格式为: | |||
| .. code-block:: python | |||
| mutate_config = [ | |||
| {'method': 'GaussianBlur', | |||
| 'params': {'ksize': [1, 2, 3, 5], 'auto_param': [True, False]}}, | |||
| {'method': 'UniformNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'GaussianNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'Contrast', | |||
| 'params': {'alpha': [0.5, 1, 1.5], 'beta': [-10, 0, 10], 'auto_param': [False, True]}}, | |||
| {'method': 'Rotate', | |||
| 'params': {'angle': [20, 90], 'auto_param': [False, True]}}, | |||
| {'method': 'FGSM', | |||
| 'params': {'eps': [0.3, 0.2, 0.4], 'alpha': [0.1], 'bounds': [(0, 1)]}} | |||
| ...] | |||
| - 支持的方法在列表 `self._strategies` 中,每个方法的参数必须在可选参数的范围内。支持的方法分为两种类型: | |||
| - 首先,自然鲁棒性方法包括:'Translate'、'Scale'、'Shear'、'Rotate'、'Perspective'、'Curve'、'GaussianBlur'、'MotionBlur'、'GradientBlur'、'Contrast'、'GradientLuminance'、'UniformNoise'、'GaussianNoise'、'SaltAndPepperNoise'、'NaturalNoise'。 | |||
| - 其次,对抗样本攻击方式包括:'FGSM'、'PGD'和'MDIM'。'FGSM'、'PGD'和'MDIM'分别是 FastGradientSignMethod、ProjectedGradientDent和MomentumDiverseInputIterativeMethod的缩写。 `mutate_config` 必须包含在['Contrast', 'GradientLuminance', 'GaussianBlur', 'MotionBlur', 'GradientBlur', 'UniformNoise', 'GaussianNoise', 'SaltAndPepperNoise', 'NaturalNoise']中的方法。 | |||
| - 第一类方法的参数设置方式可以在'mindarmour/natural_robustness/transform/image'中看到。第二类方法参数配置参考 `self._attack_param_checklists` 。 | |||
| - **initial_seeds** (list[list]) - 用于生成变异样本的初始种子队列。初始种子队列的格式为[[image_data, label], [...], ...],且标签必须为one-hot。 | |||
| - **coverage** (CoverageMetrics) - 神经元覆盖率指标类。 | |||
| - **evaluate** (bool) - 是否返回评估报告。默认值:True。 | |||
| - **max_iters** (int) - 选择要变异的种子的最大数量。默认值:10000。 | |||
| - **mutate_num_per_seed** (int) - 每个种子的最大变异次数。默认值:20。 | |||
| 返回: | |||
| - **list** - 模糊测试生成的变异样本。 | |||
| - **list** - 变异样本的ground truth标签。 | |||
| - **list** - 预测结果。 | |||
| - **list** - 变异策略。 | |||
| - **dict** - Fuzzer的指标报告。 | |||
| 异常: | |||
| - **ValueError** - 参数 `coverage` 必须是CoverageMetrics的子类。 | |||
| - **ValueError** - 初始种子队列为空。 | |||
| - **ValueError** - `initial_seeds` 中的种子未包含两个元素。 | |||
| .. py:class:: mindarmour.fuzz_testing.CoverageMetrics(model, incremental=False, batch_size=32) | |||
| 计算覆盖指标的神经元覆盖类的抽象基类。 | |||
| 训练后网络的每个神经元输出有一个输出范围(我们称之为原始范围),测试数据集用于估计训练网络的准确性。然而,不同的测试数据集,神经元的输出分布会有所不同。因此,与传统模糊测试类似,模型模糊测试意味着测试这些神经元的输出,并评估在测试数据集上神经元输出值占原始范围的比例。 | |||
| 参考文献: `DeepGauge: Multi-Granularity Testing Criteria for Deep Learning Systems <https://arxiv.org/abs/1803.07519>`_。 | |||
| 参数: | |||
| - **model** (Model) - 被测模型。 | |||
| - **incremental** (bool) - 指标将以增量方式计算。默认值:False。 | |||
| - **batch_size** (int) - 模糊测试批次中的样本数。默认值:32。 | |||
| .. py:method:: get_metrics(dataset) | |||
| 计算给定数据集的覆盖率指标。 | |||
| 参数: | |||
| - **dataset** (numpy.ndarray) - 用于计算覆盖指标的数据集。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法。 | |||
| .. py:class:: mindarmour.fuzz_testing.NeuronCoverage(model, threshold=0.1, incremental=False, batch_size=32) | |||
| 计算神经元激活的覆盖率。当神经元的输出大于阈值时,神经元被激活。 | |||
| 神经元覆盖率等于网络中激活的神经元占总神经元的比例。 | |||
| 参数: | |||
| - **model** (Model) - 被测模型。 | |||
| - **threshold** (float) - 用于确定神经元是否激活的阈值。默认值:0.1。 | |||
| - **incremental** (bool) - 指标将以增量方式计算。默认值:False。 | |||
| - **batch_size** (int) - 模糊测试批次中的样本数。默认值:32。 | |||
| .. py:method:: get_metrics(dataset) | |||
| 获取神经元覆盖率的指标:激活的神经元占网络中神经元总数的比例。 | |||
| 参数: | |||
| - **dataset** (numpy.ndarray) - 用于计算覆盖率指标的数据集。 | |||
| 返回: | |||
| - **float** - 'neuron coverage'的指标。 | |||
| .. py:class:: mindarmour.fuzz_testing.TopKNeuronCoverage(model, top_k=3, incremental=False, batch_size=32) | |||
| 计算前k个激活神经元的覆盖率。当隐藏层神经元的输出值在最大的 `top_k` 范围内,神经元就会被激活。`top_k` 神经元覆盖率等于网络中激活神经元占总神经元的比例。 | |||
| 参数: | |||
| - **model** (Model) - 被测模型。 | |||
| - **top_k** (int) - 当隐藏层神经元的输出值在最大的 `top_k` 范围内,神经元就会被激活。默认值:3。 | |||
| - **incremental** (bool) - 指标将以增量方式计算。默认值:False。 | |||
| - **batch_size** (int) - 模糊测试批次中的样本数。默认值:32。 | |||
| .. py:method:: get_metrics(dataset) | |||
| 获取Top K激活神经元覆盖率的指标。 | |||
| 参数: | |||
| - **dataset** (numpy.ndarray) - 用于计算覆盖率指标的数据集。 | |||
| 返回: | |||
| - **float** - 'top k neuron coverage'的指标。 | |||
| .. py:class:: mindarmour.fuzz_testing.NeuronBoundsCoverage(model, train_dataset, incremental=False, batch_size=32) | |||
| 获取'neuron boundary coverage'的指标 :math:`NBC = (|UpperCornerNeuron| + |LowerCornerNeuron|)/(2*|N|)` ,其中 :math:`|N|` 是神经元的数量,NBC是指测试数据集中神经元输出值超过训练数据集中相应神经元输出值的上下界的神经元比例。 | |||
| 参数: | |||
| - **model** (Model) - 等待测试的预训练模型。 | |||
| - **train_dataset** (numpy.ndarray) - 用于确定神经元输出边界的训练数据集。 | |||
| - **incremental** (bool) - 指标将以增量方式计算。默认值:False。 | |||
| - **batch_size** (int) - 模糊测试批次中的样本数。默认值:32。 | |||
| .. py:method:: get_metrics(dataset) | |||
| 获取'neuron boundary coverage'的指标。 | |||
| 参数: | |||
| - **dataset** (numpy.ndarray) - 用于计算覆盖指标的数据集。 | |||
| 返回: | |||
| - **float** - 'neuron boundary coverage'的指标。 | |||
| .. py:class:: mindarmour.fuzz_testing.SuperNeuronActivateCoverage(model, train_dataset, incremental=False, batch_size=32) | |||
| 获取超激活神经元覆盖率('super neuron activation coverage')的指标。 :math:`SNAC = |UpperCornerNeuron|/|N|` 。SNAC是指测试集中神经元输出值超过训练集中相应神经元输出值上限的神经元比例。 | |||
| 参数: | |||
| - **model** (Model) - 等待测试的预训练模型。 | |||
| - **train_dataset** (numpy.ndarray) - 用于确定神经元输出边界的训练数据集。 | |||
| - **incremental** (bool) - 指标将以增量方式计算。默认值:False。 | |||
| - **batch_size** (int) - 模糊测试批次中的样本数。默认值:32。 | |||
| .. py:method:: get_metrics(dataset) | |||
| 获取超激活神经元覆盖率('super neuron activation coverage')的指标。 | |||
| 参数: | |||
| - **dataset** (numpy.ndarray) - 用于计算覆盖指标的数据集。 | |||
| 返回: | |||
| - **float** - 超激活神经元覆盖率('super neuron activation coverage')的指标 | |||
| .. py:class:: mindarmour.fuzz_testing.KMultisectionNeuronCoverage(model, train_dataset, segmented_num=100, incremental=False, batch_size=32) | |||
| 获取K分神经元覆盖率的指标。KMNC度量测试集神经元输出落在训练集输出范围k等分间隔上的比例。 | |||
| 参数: | |||
| - **model** (Model) - 等待测试的预训练模型。 | |||
| - **train_dataset** (numpy.ndarray) - 用于确定神经元输出边界的训练数据集。 | |||
| - **segmented_num** (int) - 神经元输出间隔的分段部分数量。默认值:100。 | |||
| - **incremental** (bool) - 指标将以增量方式计算。默认值:False。 | |||
| - **batch_size** (int) - 模糊测试批次中的样本数。默认值:32。 | |||
| .. py:method:: get_metrics(dataset) | |||
| 获取'k-multisection neuron coverage'的指标。 | |||
| 参数: | |||
| - **dataset** (numpy.ndarray) - 用于计算覆盖指标的数据集。 | |||
| 返回: | |||
| - **float** - 'k-multisection neuron coverage'的指标。 | |||
+ 0
- 143
docs/api/api_python/mindarmour.natural_robustness.transform.image.rst
View File
| @@ -1,143 +0,0 @@ | |||
| mindarmour.natural_robustness.transform.image | |||
| ============================================= | |||
| 本模块包含图像的自然扰动方法。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Contrast(alpha=1, beta=0, auto_param=False) | |||
| 图像的对比度。 | |||
| 参数: | |||
| - **alpha** (Union[float, int]) - 控制图像的对比度。:math:`out\_image = in\_image \times alpha+beta`。建议值范围[0.2, 2]。默认值:1。 | |||
| - **beta** (Union[float, int]) - 补充alpha的增量。默认值:0。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.GradientLuminance(color_start=(0, 0, 0), color_end=(255, 255, 255), start_point=(10, 10), scope=0.5, pattern='light', bright_rate=0.3, mode='circle', auto_param=False) | |||
| 渐变调整图片的亮度。 | |||
| 参数: | |||
| - **color_start** (union[tuple, list]) - 渐变中心的颜色。默认值:(0, 0, 0)。 | |||
| - **color_end** (union[tuple, list]) - 渐变边缘的颜色。默认值:(255, 255, 255)。 | |||
| - **start_point** (union[tuple, list]) - 渐变中心的二维坐标。默认值:(10, 10) | |||
| - **scope** (float) - 渐变的范围。值越大,渐变范围越大。默认值:0.5。 | |||
| - **pattern** (str) - 深色或浅色,此值必须在['light', 'dark']中。默认值:'light'。 | |||
| - **bright_rate** (float) - 控制亮度。值越大,梯度范围越大。如果参数 `pattern` 为'light',建议值范围为[0.1, 0.7],如果参数 `pattern` 为'dark',建议值范围为[0.1, 0.9]。默认值:0.3。 | |||
| - **mode** (str) - 渐变模式,值必须在['circle', 'horizontal', 'vertical']中。默认值:'circle'。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.GaussianBlur(ksize=2, auto_param=False) | |||
| 使用高斯模糊滤镜模糊图像。 | |||
| 参数: | |||
| - **ksize** (int) - 高斯核的大小,必须为非负数。默认值:2。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.MotionBlur(degree=5, angle=45, auto_param=False) | |||
| 运动模糊。 | |||
| 参数: | |||
| - **degree** (int) - 模糊程度。必须为正值。建议取值范围[1, 15]。默认值:5。 | |||
| - **angle** (union[float, int]) - 运动模糊的方向。angle=0表示上下运动模糊。角度为逆时针方向。默认值:45。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.GradientBlur(point, kernel_num=3, center=True, auto_param=False) | |||
| 渐变模糊。 | |||
| 参数: | |||
| - **point** (union[tuple, list]) - 模糊中心点的二维坐标。 | |||
| - **kernel_num** (int) - 模糊核的数量。建议取值范围[1, 8]。默认值:3。 | |||
| - **center** (bool) - 指定中心点模糊或指定中心点清晰。默认值:True。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.UniformNoise(factor=0.1, auto_param=False) | |||
| 图像添加均匀噪声。 | |||
| 参数: | |||
| - **factor** (float) - 噪声密度,单位像素区域添加噪声的比例。建议取值范围:[0.001, 0.15]。默认值:0.1。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.GaussianNoise(factor=0.1, auto_param=False) | |||
| 图像添加高斯噪声。 | |||
| 参数: | |||
| - **factor** (float) - 噪声密度,单位像素区域添加噪声的比例。建议取值范围:[0.001, 0.15]。默认值:0.1。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.SaltAndPepperNoise(factor=0, auto_param=False) | |||
| 图像添加椒盐噪声。 | |||
| 参数: | |||
| - **factor** (float) - 噪声密度,单位像素区域添加噪声的比例。建议取值范围:[0.001, 0.15]。默认值:0。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.NaturalNoise(ratio=0.0002, k_x_range=(1, 5), k_y_range=(3, 25), auto_param=False) | |||
| 图像添加自然噪声。 | |||
| 参数: | |||
| - **ratio** (float) - 噪声密度,单位像素区域添加噪声的比例。建议取值范围:[0.00001, 0.001]。默认值:0.0002。 | |||
| - **k_x_range** (union[list, tuple]) - 噪声块长度的取值范围。默认值:(1, 5)。 | |||
| - **k_y_range** (union[list, tuple]) - 噪声块宽度的取值范围。默认值:(3, 25)。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Translate(x_bias=0, y_bias=0, auto_param=False) | |||
| 图像平移。 | |||
| 参数: | |||
| - **x_bias** (Union[int, float]) - X方向平移, :math:`x = x + x_bias \times image\_length` 。建议取值范围在[-0.1, 0.1]中。默认值:0。 | |||
| - **y_bias** (Union[int, float]) - Y方向平移, :math:`y = y + y_bias \times image\_width` 。建议取值范围在[-0.1, 0.1]中。默认值:0。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Scale(factor_x=1, factor_y=1, auto_param=False) | |||
| 图像缩放。 | |||
| 参数: | |||
| - **factor_x** (Union[float, int]) - 在X方向缩放, :math:`x=factor_x \times x` 。建议取值范围在[0.5, 1]且abs(factor_y - factor_x) < 0.5。默认值:1。 | |||
| - **factor_y** (Union[float, int]) - 沿Y方向缩放, :math:`y=factor_y \times y` 。建议取值范围在[0.5, 1]且abs(factor_y - factor_x) < 0.5。默认值:1。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Shear(factor=0.2, direction='horizontal', auto_param=False) | |||
| 图像错切,错切后图像和原图的映射关系为: :math:`(new_x, new_y) = (x+factor_x \times y, factor_y \times x+y)` 。错切后图像将重新缩放到原图大小。 | |||
| 参数: | |||
| - **factor** (Union[float, int]) - 沿错切方向上的错切比例。建议值范围[0.05, 0.5]。默认值:0.2。 | |||
| - **direction** (str) - 形变方向。可选值为'vertical'或'horizontal'。默认值:'horizontal'。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Rotate(angle=20, auto_param=False) | |||
| 围绕图像中心点逆时针旋转图像。 | |||
| 参数: | |||
| - **angle** (Union[float, int]) - 逆时针旋转的度数。建议值范围[-60, 60]。默认值:20。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Perspective(ori_pos, dst_pos, auto_param=False) | |||
| 透视变换。 | |||
| 参数: | |||
| - **ori_pos** (list[list[int]]) - 原始图像中的四个点的坐标。 | |||
| - **dst_pos** (list[list[int]]) - 对应的 `ori_pos` 中4个点透视变换后的点坐标。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
| .. py:class:: mindarmour.natural_robustness.transform.image.Curve(curves=3, depth=10, mode='vertical', auto_param=False) | |||
| 使用Sin函数的曲线变换。 | |||
| 参数: | |||
| - **curves** (union[float, int]) - 曲线周期数。建议取值范围[0.1, 5]。默认值:3。 | |||
| - **depth** (union[float, int]) - sin函数的幅度。建议取值不超过图片长度的1/10。默认值:10。 | |||
| - **mode** (str) - 形变方向。可选值'vertical'或'horizontal'。默认值:'vertical'。 | |||
| - **auto_param** (bool) - 自动选择参数。在保留图像的语义的范围内自动选择参数。默认值:False。 | |||
+ 0
- 269
docs/api/api_python/mindarmour.privacy.diff_privacy.rst
View File
| @@ -1,269 +0,0 @@ | |||
| mindarmour.privacy.diff_privacy | |||
| =============================== | |||
| 本模块提供差分隐私功能,以保护用户隐私。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.NoiseGaussianRandom(norm_bound=1.0, initial_noise_multiplier=1.0, seed=0, decay_policy=None) | |||
| 基于 :math:`mean=0` 以及 :math:`standard\_deviation = norm\_bound * initial\_noise\_multiplier` 的高斯分布产生噪声。 | |||
| 参数: | |||
| - **norm_bound** (float) - 梯度的l2范数的裁剪范围。默认值:1.0。 | |||
| - **initial_noise_multiplier** (float) - 高斯噪声标准偏差除以 `norm_bound` 的比率,将用于计算隐私预算。默认值:1.0。 | |||
| - **seed** (int) - 原始随机种子,如果seed=0随机正态将使用安全随机数。如果seed!=0随机正态将使用给定的种子生成值。默认值:0。 | |||
| - **decay_policy** (str) - 衰减策略。默认值:None。 | |||
| .. py:method:: construct(gradients) | |||
| 产生高斯噪声。 | |||
| 参数: | |||
| - **gradients** (Tensor) - 梯度。 | |||
| 返回: | |||
| - **Tensor** - 生成的shape与给定梯度相同的噪声。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.NoiseAdaGaussianRandom(norm_bound=1.0, initial_noise_multiplier=1.0, seed=0, noise_decay_rate=6e-6, decay_policy='Exp') | |||
| 自适应高斯噪声产生机制。噪音会随着训练而衰减。衰减模式可以是'Time'、'Step'、'Exp'。 | |||
| 在模型训练过程中,将更新 `self._noise_multiplier` 。 | |||
| 参数: | |||
| - **norm_bound** (float) - 梯度的l2范数的裁剪范围。默认值:1.0。 | |||
| - **initial_noise_multiplier** (float) - 高斯噪声标准偏差除以 `norm_bound` 的比率,将用于计算隐私预算。默认值:1.0。 | |||
| - **seed** (int) - 原始随机种子,如果seed=0随机正态将使用安全随机数。如果seed!=0随机正态将使用给定的种子生成值。默认值:0。 | |||
| - **noise_decay_rate** (float) - 控制噪声衰减的超参数。默认值:6e-6。 | |||
| - **decay_policy** (str) - 噪声衰减策略包括'Step'、'Time'、'Exp'。默认值:'Exp'。 | |||
| .. py:method:: construct(gradients) | |||
| 生成自适应高斯噪声。 | |||
| 参数: | |||
| - **gradients** (Tensor) - 梯度。 | |||
| 返回: | |||
| - **Tensor** - 生成的shape与给定梯度相同的噪声。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.AdaClippingWithGaussianRandom(decay_policy='Linear', learning_rate=0.001, target_unclipped_quantile=0.9, fraction_stddev=0.01, seed=0) | |||
| 自适应剪裁。 | |||
| 如果 `decay_policy` 是'Linear',则更新公式为::math:`norm\_bound = norm\_bound - learning\_rate*(beta - target\_unclipped\_quantile)` 。 | |||
| 如果 `decay_policy` 是'Geometric',则更新公式为 :math:`norm\_bound = norm\_bound*exp(-learning\_rate*(empirical\_fraction - target\_unclipped\_quantile))` 。 | |||
| 其中,beta是值最多为 `target_unclipped_quantile` 的样本的经验分数。 | |||
| 参数: | |||
| - **decay_policy** (str) - 自适应剪裁的衰变策略, `decay_policy` 必须在['Linear', 'Geometric']中。默认值:'Linear'。 | |||
| - **learning_rate** (float) - 更新范数裁剪的学习率。默认值:0.001。 | |||
| - **target_unclipped_quantile** (float) - 范数裁剪的目标分位数。默认值:0.9。 | |||
| - **fraction_stddev** (float) - 高斯正态的stddev,用于 `empirical_fraction` ,公式为empirical_fraction + N(0, fraction_stddev)。默认值:0.01。 | |||
| - **seed** (int) - 原始随机种子,如果seed=0随机正态将使用安全随机数。如果seed!=0随机正态将使用给定的种子生成值。默认值:0。 | |||
| 返回: | |||
| - **Tensor** - 更新后的梯度裁剪阈值。 | |||
| .. py:method:: construct(empirical_fraction, norm_bound) | |||
| 更新 `norm_bound` 的值。 | |||
| 参数: | |||
| - **empirical_fraction** (Tensor) - 梯度裁剪的经验分位数,最大值不超过 `target_unclipped_quantile` 。 | |||
| - **norm_bound** (Tensor) - 梯度的l2范数的裁剪范围。 | |||
| 返回: | |||
| - **Tensor** - 生成的shape与给定梯度相同的噪声。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.NoiseMechanismsFactory | |||
| 噪声产生机制的工厂类。它目前支持高斯随机噪声(Gaussian Random Noise)和自适应高斯随机噪声(Adaptive Gaussian Random Noise)。 | |||
| 详情请查看: `教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| .. py:method:: create(mech_name, norm_bound=1.0, initial_noise_multiplier=1.0, seed=0, noise_decay_rate=6e-6, decay_policy=None) | |||
| 参数: | |||
| - **mech_name** (str) - 噪声生成策略,可以是'Gaussian'或'AdaGaussian'。噪声在'AdaGaussian'机制下衰减,而在'Gaussian'机制下则恒定。 | |||
| - **norm_bound** (float) - 梯度的l2范数的裁剪范围。默认值:1.0。 | |||
| - **initial_noise_multiplier** (float) - 高斯噪声标准偏差除以 `norm_bound` 的比率,将用于计算隐私预算。默认值:1.0。 | |||
| - **seed** (int) - 原始随机种子,如果seed=0随机正态将使用安全随机数。如果seed!=0随机正态将使用给定的种子生成值。默认值:0。 | |||
| - **noise_decay_rate** (float) - 控制噪声衰减的超参数。默认值:6e-6。 | |||
| - **decay_policy** (str) - 衰减策略。如果decay_policy为None,则不需要更新参数。默认值:None。 | |||
| 返回: | |||
| - **Mechanisms** - 产生的噪声类别机制。 | |||
| 异常: | |||
| - **NameError** - `mech_name` 必须在['Gaussian', 'AdaGaussian']中。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.ClipMechanismsFactory | |||
| 梯度剪裁机制的工厂类。它目前支持高斯随机噪声(Gaussian Random Noise)的自适应剪裁(Adaptive Clipping)。 | |||
| 详情请查看: `教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| .. py:method:: create(mech_name, decay_policy='Linear', learning_rate=0.001, target_unclipped_quantile=0.9, fraction_stddev=0.01, seed=0) | |||
| 参数: | |||
| - **mech_name** (str) - 噪声裁剪生成策略,现支持'Gaussian'。 | |||
| - **decay_policy** (str) - 自适应剪裁的衰变策略,decay_policy必须在['Linear', 'Geometric']中。默认值:Linear。 | |||
| - **learning_rate** (float) - 更新范数裁剪的学习率。默认值:0.001。 | |||
| - **target_unclipped_quantile** (float) - 范数裁剪的目标分位数。默认值:0.9。 | |||
| - **fraction_stddev** (float) - 高斯正态的stddev,用于empirical_fraction,公式为 :math:`empirical\_fraction + N(0, fraction\_stddev)` 。默认值:0.01。 | |||
| - **seed** (int) - 原始随机种子,如果seed=0随机正态将使用安全随机数。如果seed!=0随机正态将使用给定的种子生成值。默认值:0。 | |||
| 返回: | |||
| - **Mechanisms** - 产生的噪声类别机制。 | |||
| 异常: | |||
| - **NameError** - `mech_name` 必须在['Gaussian']中。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.PrivacyMonitorFactory | |||
| DP训练隐私监视器的工厂类。 | |||
| 详情请查看: `教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| .. py:method:: create(policy, *args, **kwargs) | |||
| 创建隐私预算监测类。 | |||
| 参数: | |||
| - **policy** (str) - 监控策略,现支持'rdp'和'zcdp'。 | |||
| - 如果策略为'rdp',监控器将根据Renyi差分隐私(Renyi differential privacy,RDP)理论计算DP训练的隐私预算; | |||
| - 如果策略为'zcdp',监控器将根据零集中差分隐私(zero-concentrated differential privacy,zCDP)理论计算DP训练的隐私预算。注意,'zcdp'不适合子采样噪声机制。 | |||
| - **args** (Union[int, float, numpy.ndarray, list, str]) - 用于创建隐私监视器的参数。 | |||
| - **kwargs** (Union[int, float, numpy.ndarray, list, str]) - 用于创建隐私监视器的关键字参数。 | |||
| 返回: | |||
| - **Callback** - 隐私监视器。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.RDPMonitor(num_samples, batch_size, initial_noise_multiplier=1.5, max_eps=10.0, target_delta=1e-3, max_delta=None, target_eps=None, orders=None, noise_decay_mode='Time', noise_decay_rate=6e-4, per_print_times=50, dataset_sink_mode=False) | |||
| 基于Renyi差分隐私(RDP)理论,计算DP训练的隐私预算。根据下面的参考文献,如果随机化机制被认为具有α阶的ε'-Renyi差分隐私,它也满足常规差分隐私(ε, δ),如下所示: | |||
| .. math:: | |||
| (ε'+\frac{log(1/δ)}{α-1}, δ) | |||
| 详情请查看: `教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| 参考文献: `Rényi Differential Privacy of the Sampled Gaussian Mechanism <https://arxiv.org/abs/1908.10530>`_。 | |||
| 参数: | |||
| - **num_samples** (int) - 训练数据集中的样本总数。 | |||
| - **batch_size** (int) - 训练时批处理中的样本数。 | |||
| - **initial_noise_multiplier** (Union[float, int]) - 高斯噪声标准偏差除以norm_bound的比率,将用于计算隐私预算。默认值:1.5。 | |||
| - **max_eps** (Union[float, int, None]) - DP训练的最大可接受epsilon预算,用于估计最大训练epoch。'None'表示epsilon预算没有限制。默认值:10.0。 | |||
| - **target_delta** (Union[float, int, None]) - DP训练的目标delta预算。如果 `target_delta` 设置为δ,则隐私预算δ将在整个训练过程中是固定的。默认值:1e-3。 | |||
| - **max_delta** (Union[float, int, None]) - DP训练的最大可接受delta预算,用于估计最大训练epoch。 `max_delta` 必须小于1,建议小于1e-3,否则会溢出。'None'表示delta预算没有限制。默认值:None。 | |||
| - **target_eps** (Union[float, int, None]) - DP训练的目标epsilon预算。如果target_eps设置为ε,则隐私预算ε将在整个训练过程中是固定的。默认值:None。 | |||
| - **orders** (Union[None, list[int, float]]) - 用于计算rdp的有限阶数,必须大于1。不同阶的隐私预算计算结果会有所不同。为了获得更严格(更小)的隐私预算估计,可以尝试阶列表。默认值:None。 | |||
| - **noise_decay_mode** (Union[None, str]) - 训练时添加噪音的衰减模式,可以是None、'Time'、'Step'、'Exp'。默认值:'Time'。 | |||
| - **noise_decay_rate** (float) - 训练时噪音的衰变率。默认值:6e-4。 | |||
| - **per_print_times** (int) - 计算和打印隐私预算的间隔步数。默认值:50。 | |||
| - **dataset_sink_mode** (bool) - 如果为True,所有训练数据都将一次性传递到设备(Ascend)。如果为False,则训练数据将在每步训练后传递到设备。默认值:False。 | |||
| .. py:method:: max_epoch_suggest() | |||
| 估计最大训练epoch,以满足预定义的隐私预算。 | |||
| 返回: | |||
| - **int** - 建议的最大训练epoch。 | |||
| .. py:method:: step_end(run_context) | |||
| 在每个训练步骤后计算隐私预算。 | |||
| 参数: | |||
| - **run_context** (RunContext) - 包含模型的一些信息。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.ZCDPMonitor(num_samples, batch_size, initial_noise_multiplier=1.5, max_eps=10.0, target_delta=1e-3, noise_decay_mode='Time', noise_decay_rate=6e-4, per_print_times=50, dataset_sink_mode=False) | |||
| 基于零集中差分隐私(zCDP)理论,计算DP训练的隐私预算。根据下面的参考文献,如果随机化机制满足ρ-zCDP机制,它也满足传统的差分隐私(ε, δ),如下所示: | |||
| .. math:: | |||
| (ρ+2\sqrt{ρ*log(1/δ)}, δ) | |||
| 注意,ZCDPMonitor不适合子采样噪声机制(如NoiseAdaGaussianRandom和NoiseGaussianRandom)。未来将开发zCDP的匹配噪声机制。 | |||
| 详情请查看:`教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| 参考文献:`Concentrated Differentially Private Gradient Descent with Adaptive per-Iteration Privacy Budget <https://arxiv.org/abs/1808.09501>`_。 | |||
| 参数: | |||
| - **num_samples** (int) - 训练数据集中的样本总数。 | |||
| - **batch_size** (int) - 训练时批处理中的样本数。 | |||
| - **initial_noise_multiplier** (Union[float, int]) - 高斯噪声标准偏差除以norm_bound的比率,将用于计算隐私预算。默认值:1.5。 | |||
| - **max_eps** (Union[float, int]) - DP训练的最大可接受epsilon预算,用于估计最大训练epoch。默认值:10.0。 | |||
| - **target_delta** (Union[float, int]) - DP训练的目标delta预算。如果 `target_delta` 设置为δ,则隐私预算δ将在整个训练过程中是固定的。默认值:1e-3。 | |||
| - **noise_decay_mode** (Union[None, str]) - 训练时添加噪音的衰减模式,可以是None、'Time'、'Step'、'Exp'。默认值:'Time'。 | |||
| - **noise_decay_rate** (float) - 训练时噪音的衰变率。默认值:6e-4。 | |||
| - **per_print_times** (int) - 计算和打印隐私预算的间隔步数。默认值:50。 | |||
| - **dataset_sink_mode** (bool) - 如果为True,所有训练数据都将一次性传递到设备(Ascend)。如果为False,则训练数据将在每步训练后传递到设备。默认值:False。 | |||
| .. py:method:: max_epoch_suggest() | |||
| 估计最大训练epoch,以满足预定义的隐私预算。 | |||
| 返回: | |||
| - **int** - 建议的最大训练epoch。 | |||
| .. py:method:: step_end(run_context) | |||
| 在每个训练步骤后计算隐私预算。 | |||
| 参数: | |||
| - **run_context** (RunContext) - 包含模型的一些信息。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.DPOptimizerClassFactory(micro_batches=2) | |||
| 优化器的工厂类。 | |||
| 参数: | |||
| - **micro_batches** (int) - 从原始批次拆分的小批次中的样本数量。默认值:2。 | |||
| 返回: | |||
| - **Optimizer** - 优化器类。 | |||
| .. py:method:: create(policy) | |||
| 创建DP优化器。策略可以是'sgd'、'momentum'、'adam'。 | |||
| 参数: | |||
| - **policy** (str) - 选择原始优化器类型。 | |||
| 返回: | |||
| - **Optimizer** - 一个带有差分加噪的优化器。 | |||
| .. py:method:: set_mechanisms(policy, *args, **kwargs) | |||
| 获取噪音机制对象。策略可以是'Gaussian'或'AdaGaussian'。候选的args和kwargs可以在mechanisms.py | |||
| 的 :class:`NoiseMechanismsFactory` 类中看到。 | |||
| 参数: | |||
| - **policy** (str) - 选择机制类型。 | |||
| .. py:class:: mindarmour.privacy.diff_privacy.DPModel(micro_batches=2, norm_bound=1.0, noise_mech=None, clip_mech=None, optimizer=nn.Momentum, **kwargs) | |||
| DPModel用于构建差分隐私训练的模型。 | |||
| 这个类重载自 :class:`mindspore.Model` 。 | |||
| 详情请查看: `教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| 参数: | |||
| - **micro_batches** (int) - 从原始批次拆分的小批次数。默认值:2。 | |||
| - **norm_bound** (float) - 用于裁剪范围,如果设置为1,将返回原始数据。默认值:1.0。 | |||
| - **noise_mech** (Mechanisms) - 用于生成不同类型的噪音。默认值:None。 | |||
| - **clip_mech** (Mechanisms) - 用于更新自适应剪裁。默认值:None。 | |||
| - **optimizer** (Cell) - 用于更新差分隐私训练过程中的模型权重值。默认值:nn.Momentum。 | |||
| 异常: | |||
| - **ValueError** - optimizer值为None。 | |||
| - **ValueError** - optimizer不是DPOptimizer,且noise_mech为None。 | |||
| - **ValueError** - optimizer是DPOptimizer,且noise_mech非None。 | |||
| - **ValueError** - noise_mech或DPOptimizer的mech方法是自适应的,而clip_mech不是None。 | |||
+ 0
- 108
docs/api/api_python/mindarmour.privacy.evaluation.rst
View File
| @@ -1,108 +0,0 @@ | |||
| mindarmour.privacy.evaluation | |||
| ============================= | |||
| 本模块提供了一些评估给定模型隐私泄露风险的方法。 | |||
| .. py:class:: mindarmour.privacy.evaluation.MembershipInference(model, n_jobs=-1) | |||
| 成员推理是由Shokri、Stronati、Song和Shmatikov提出的一种用于推断用户隐私数据的灰盒攻击。它需要训练样本的loss或logits结果,隐私是指单个用户的一些敏感属性。 | |||
| 有关详细信息,请参见: `教程 <https://mindspore.cn/mindarmour/docs/zh-CN/master/test_model_security_membership_inference.html>`_。 | |||
| 参考文献:`Reza Shokri, Marco Stronati, Congzheng Song, Vitaly Shmatikov. Membership Inference Attacks against Machine Learning Models. 2017. <https://arxiv.org/abs/1610.05820v2>`_。 | |||
| 参数: | |||
| - **model** (Model) - 目标模型。 | |||
| - **n_jobs** (int) - 并行运行的任务数量。-1表示使用所有处理器,否则n_jobs的值必须为正整数。 | |||
| 异常: | |||
| - **TypeError** - 模型的类型不是 :class:`mindspore.Model` 。 | |||
| - **TypeError** - `n_jobs` 的类型不是int。 | |||
| - **ValueError** - `n_jobs` 的值既不是-1,也不是正整数。 | |||
| .. py:method:: eval(dataset_train, dataset_test, metrics) | |||
| 评估目标模型的隐私泄露程度。 | |||
| 评估指标应由metrics规定。 | |||
| 参数: | |||
| - **dataset_train** (mindspore.dataset) - 目标模型的训练数据集。 | |||
| - **dataset_test** (mindspore.dataset) - 目标模型的测试数据集。 | |||
| - **metrics** (Union[list, tuple]) - 评估指标。指标的值必须在["precision", "accuracy", "recall"]中。默认值:["precision"]。 | |||
| 返回: | |||
| - **list** - 每个元素都包含攻击模型的评估指标。 | |||
| .. py:method:: train(dataset_train, dataset_test, attack_config) | |||
| 根据配置,使用输入数据集训练攻击模型。 | |||
| 参数: | |||
| - **dataset_train** (mindspore.dataset) - 目标模型的训练数据集。 | |||
| - **dataset_test** (mindspore.dataset) - 目标模型的测试集。 | |||
| - **attack_config** (Union[list, tuple]) - 攻击模型的参数设置。格式为 | |||
| .. code-block:: python | |||
| attack_config = | |||
| [{"method": "knn", "params": {"n_neighbors": [3, 5, 7]}}, | |||
| {"method": "lr", "params": {"C": np.logspace(-4, 2, 10)}}] | |||
| - 支持的方法有knn、lr、mlp和rf,每个方法的参数必须在可变参数的范围内。参数实现的提示可在下面找到: | |||
| - `KNN <https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html>`_ | |||
| - `LR <https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html>`_ | |||
| - `RF <https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html>`_ | |||
| - `MLP <https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html>`_ | |||
| 异常: | |||
| - **KeyError** - `attack_config` 中的配置没有键{"method", "params"}。 | |||
| - **NameError** - `attack_config` 中的方法(不区分大小写)不在["lr", "knn", "rf", "mlp"]中。 | |||
| .. py:class:: mindarmour.privacy.evaluation.ImageInversionAttack(network, input_shape, input_bound, loss_weights=(1, 0.2, 5)) | |||
| 一种通过还原图像的深层表达来重建图像的攻击方法。 | |||
| 参考文献:`Aravindh Mahendran, Andrea Vedaldi. Understanding Deep Image Representations by Inverting Them. 2014. <https://arxiv.org/pdf/1412.0035.pdf>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 网络,用于推断图像的深层特征。 | |||
| - **input_shape** (tuple) - 单个网络输入的数据形状,应与给定网络一致。形状的格式应为(channel, image_width, image_height)。 | |||
| - **input_bound** (Union[tuple, list]) - 原始图像的像素范围,应该像[minimum_pixel, maximum_pixel]或(minimum_pixel, maximum_pixel)。 | |||
| - **loss_weights** (Union[list, tuple]) - InversionLoss中三个子损失的权重,可以调整以获得更好的结果。默认值:(1, 0.2, 5)。 | |||
| 异常: | |||
| - **TypeError** - 网络类型不是Cell。 | |||
| - **ValueError** - `input_shape` 的值有非正整数。 | |||
| - **ValueError** - `loss_weights` 的值有非正数。 | |||
| .. py:method:: evaluate(original_images, inversion_images, labels=None, new_network=None) | |||
| 通过三个指标评估还原图像的质量:原始图像和还原图像之间的平均L2距离和SSIM值,以及新模型对还原图像的推理结果在真实标签上的置信度平均值。 | |||
| 参数: | |||
| - **original_images** (numpy.ndarray) - 原始图像,其形状应为(img_num, channels, img_width, img_height)。 | |||
| - **inversion_images** (numpy.ndarray) - 还原图像,其形状应为(img_num, channels, img_width, img_height)。 | |||
| - **labels** (numpy.ndarray) - 原始图像的ground truth标签。默认值:None。 | |||
| - **new_network** (Cell) - 其结构包含self._network中所有网络,但加载了不同的模型文件。默认值:None。 | |||
| 返回: | |||
| - **float** - l2距离。 | |||
| - **float** - 平均ssim值。 | |||
| - **Union[float, None]** - 平均置信度。如果 `labels` 或 `new_network` 为None,则该值为None。 | |||
| .. py:method:: generate(target_features, iters=100) | |||
| 根据 `target_features` 重建图像。 | |||
| 参数: | |||
| - **target_features** (numpy.ndarray) - 原始图像的深度表示。 `target_features` 的第一个维度应该是img_num。需要注意的是,如果img_num等于1,则 `target_features` 的形状应该是(1, dim2, dim3, ...)。 | |||
| - **iters** (int) - 逆向攻击的迭代次数,应为正整数。默认值:100。 | |||
| 返回: | |||
| - **numpy.ndarray** - 重建图像,预计与原始图像相似。 | |||
| 异常: | |||
| - **TypeError** - target_features的类型不是numpy.ndarray。 | |||
| - **ValueError** - `iters` 的值都不是正整数. | |||
+ 0
- 175
docs/api/api_python/mindarmour.privacy.sup_privacy.rst
View File
| @@ -1,175 +0,0 @@ | |||
| mindarmour.privacy.sup_privacy | |||
| ============================== | |||
| 本模块提供抑制隐私功能,以保护用户隐私。 | |||
| .. py:class:: mindarmour.privacy.sup_privacy.SuppressMasker(model, suppress_ctrl) | |||
| 周期性检查抑制隐私功能状态和切换(启动/关闭)抑制操作。 | |||
| 详情请查看: `应用抑制隐私机制保护用户隐私 | |||
| <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_suppress_privacy.html#%E5%BC%95%E5%85%A5%E6%8A%91%E5%88%B6%E9%9A%90%E7%A7%81%E8%AE%AD%E7%BB%83>`_。 | |||
| 参数: | |||
| - **model** (SuppressModel) - SuppressModel 实例。 | |||
| - **suppress_ctrl** (SuppressCtrl) - SuppressCtrl 实例。 | |||
| .. py:method:: step_end(run_context) | |||
| 更新用于抑制模型实例的掩码矩阵张量。 | |||
| 参数: | |||
| - **run_context** (RunContext) - 包含模型的一些信息。 | |||
| .. py:class:: mindarmour.privacy.sup_privacy.SuppressModel(network, loss_fn, optimizer, **kwargs) | |||
| 抑制隐私训练器,重载自 :class:`mindspore.Model` 。 | |||
| 有关详细信息,请查看: `应用抑制隐私机制保护用户隐私 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_suppress_privacy.html#%E5%BC%95%E5%85%A5%E6%8A%91%E5%88%B6%E9%9A%90%E7%A7%81%E8%AE%AD%E7%BB%83>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 要训练的神经网络模型。 | |||
| - **loss_fn** (Cell) - 优化器的损失函数。 | |||
| - **optimizer** (Optimizer) - 优化器实例。 | |||
| - **kwargs** - 创建抑制模型时使用的关键字参数。 | |||
| .. py:method:: link_suppress_ctrl(suppress_pri_ctrl) | |||
| SuppressCtrl实例关联到SuppressModel实例。 | |||
| 参数: | |||
| - **suppress_pri_ctrl** (SuppressCtrl) - SuppressCtrl实例。 | |||
| .. py:class:: mindarmour.privacy.sup_privacy.SuppressPrivacyFactory | |||
| SuppressCtrl机制的工厂类。 | |||
| 详情请查看: `应用抑制隐私机制保护用户隐私 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_suppress_privacy.html#%E5%BC%95%E5%85%A5%E6%8A%91%E5%88%B6%E9%9A%90%E7%A7%81%E8%AE%AD%E7%BB%83>`_。 | |||
| .. py:method:: create(networks, mask_layers, policy='local_train', end_epoch=10, batch_num=20, start_epoch=3, mask_times=1000, lr=0.05, sparse_end=0.90, sparse_start=0.0) | |||
| 参数: | |||
| - **networks** (Cell) - 要训练的神经网络模型。此网络参数应与SuppressModel()的'network'参数相同。 | |||
| - **mask_layers** (list) - 需要抑制的训练网络层的描述。 | |||
| - **policy** (str) - 抑制隐私训练的训练策略。默认值:"local_train",表示本地训练。 | |||
| - **end_epoch** (int) - 最后一次抑制操作对应的epoch序号,0<start_epoch<=end_epoch<=100。默认值:10。此end_epoch参数应与mindspore.train.model.train()的'epoch'参数相同。 | |||
| - **batch_num** (int) - 一个epoch中批次的数量,应等于num_samples/batch_size。默认值:20。 | |||
| - **start_epoch** (int) - 第一个抑制操作对应的epoch序号,0<start_epoch<=end_epoch<=100。默认值:3。 | |||
| - **mask_times** (int) - 抑制操作的数量。默认值:1000。 | |||
| - **lr** (Union[float, int]) - 学习率,在训练期间应保持不变。0<lr<=0.50. 默认值:0.05。此lr参数应与mindspore.nn.SGD()的'learning_rate'参数相同。 | |||
| - **sparse_end** (float) - 要到达的稀疏性,0.0<=sparse_start<sparse_end<1.0。默认值:0.90。 | |||
| - **sparse_start** (Union[float, int]) - 抑制操作启动时对应的稀疏性,0.0<=sparse_start<sparse_end<1.0。默认值:0.0。 | |||
| 返回: | |||
| - **SuppressCtrl** - 抑制隐私机制的类。 | |||
| .. py:class:: mindarmour.privacy.sup_privacy.SuppressCtrl(networks, mask_layers, end_epoch, batch_num, start_epoch, mask_times, lr, sparse_end, sparse_start) | |||
| 完成抑制隐私操作,包括计算抑制比例,找到应该抑制的参数,并永久抑制这些参数。 | |||
| 详情请查看: `应用抑制隐私机制保护用户隐私 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_suppress_privacy.html#%E5%BC%95%E5%85%A5%E6%8A%91%E5%88%B6%E9%9A%90%E7%A7%81%E8%AE%AD%E7%BB%83>`_。 | |||
| 参数: | |||
| - **networks** (Cell) - 要训练的神经网络模型。 | |||
| - **mask_layers** (list) - 需要抑制的层的描述。 | |||
| - **end_epoch** (int) - 最后一次抑制操作对应的epoch序号。 | |||
| - **batch_num** (int) - 一个epoch中的batch数量。 | |||
| - **start_epoch** (int) - 第一个抑制操作对应的epoch序号。 | |||
| - **mask_times** (int) - 抑制操作的数量。 | |||
| - **lr** (Union[float, int]) - 学习率。 | |||
| - **sparse_end** (float) - 要到达的稀疏性。 | |||
| - **sparse_start** (Union[float, int]) - 要启动的稀疏性。 | |||
| .. py:method:: calc_actual_sparse_for_conv(networks) | |||
| 计算con1层和con2层的网络稀疏性。 | |||
| 参数: | |||
| - **networks** (Cell) - 要训练的神经网络模型。 | |||
| .. py:method:: calc_actual_sparse_for_fc1(networks) | |||
| 计算全连接1层的实际稀疏 | |||
| 参数: | |||
| - **networks** (Cell) - 要训练的神经网络模型。 | |||
| .. py:method:: calc_actual_sparse_for_layer(networks, layer_name) | |||
| 计算一个网络层的实际稀疏性 | |||
| 参数: | |||
| - **networks** (Cell) - 要训练的神经网络模型。 | |||
| - **layer_name** (str) - 目标层的名称。 | |||
| .. py:method:: calc_theoretical_sparse_for_conv() | |||
| 计算卷积层的掩码矩阵的实际稀疏性。 | |||
| .. py:method:: print_paras() | |||
| 显示参数信息 | |||
| .. py:method:: reset_zeros() | |||
| 将用于加法运算的掩码数组设置为0。 | |||
| .. py:method:: update_mask(networks, cur_step, target_sparse=0.0) | |||
| 对整个模型的用于加法运算和乘法运算的掩码数组进行更新。 | |||
| 参数: | |||
| - **networks** (Cell) - 训练网络。 | |||
| - **cur_step** (int) - 整个训练过程的当前epoch。 | |||
| - **target_sparse** (float) - 要到达的稀疏性。默认值:0.0。 | |||
| .. py:method:: update_mask_layer(weight_array_flat, sparse_weight_thd, sparse_stop_pos, weight_abs_max, layer_index) | |||
| 对单层的用于加法运算和乘法运算的掩码数组进行更新。 | |||
| 参数: | |||
| - **weight_array_flat** (numpy.ndarray) - 层参数权重数组。 | |||
| - **sparse_weight_thd** (float) - 绝对值小于该阈值的权重会被抑制。 | |||
| - **sparse_stop_pos** (int) - 要抑制的最大元素数。 | |||
| - **weight_abs_max** (float) - 权重的最大绝对值。 | |||
| - **layer_index** (int) - 目标层的索引。 | |||
| .. py:method:: update_mask_layer_approximity(weight_array_flat, weight_array_flat_abs, actual_stop_pos, layer_index) | |||
| 对单层的用于加法运算和乘法运算的掩码数组进行更新。 | |||
| 禁用clipping lower、clipping、adding noise操作。 | |||
| 参数: | |||
| - **weight_array_flat** (numpy.ndarray) - 层参数权重数组。 | |||
| - **weight_array_flat_abs** (numpy.ndarray) - 层参数权重的绝对值的数组。 | |||
| - **actual_stop_pos** (int) - 应隐藏实际参数编号。 | |||
| - **layer_index** (int) - 目标层的索引。 | |||
| .. py:method:: update_status(cur_epoch, cur_step, cur_step_in_epoch) | |||
| 更新抑制操作状态。 | |||
| 参数: | |||
| - **cur_epoch** (int) - 整个训练过程的当前epoch。 | |||
| - **cur_step** (int) - 整个训练过程的当前步骤。 | |||
| - **cur_step_in_epoch** (int) - 当前epoch的当前步骤。 | |||
| .. py:class:: mindarmour.privacy.sup_privacy.MaskLayerDes(layer_name, grad_idx, is_add_noise, is_lower_clip, min_num, upper_bound=1.20) | |||
| 对抑制目标层的描述。 | |||
| 参数: | |||
| - **layer_name** (str) - 层名称,如下获取一个层的名称: | |||
| .. code-block:: | |||
| for layer in networks.get_parameters(expand=True): | |||
| if layer.name == "conv": ... | |||
| - **grad_idx** (int) - 掩码层在梯度元组中的索引。可参考 `model.py <https://gitee.com/mindspore/mindarmour/blob/master/mindarmour/privacy/sup_privacy/train/model.py>`_ 中TrainOneStepCell的构造函数,在PYNATIVE_MODE模式下打印某些层的索引值。 | |||
| - **is_add_noise** (bool) - 如果为True,则此层的权重可以添加噪声。如果为False,则此层的权重不能添加噪声。如果参数num大于100000,则 `is_add_noise` 无效。 | |||
| - **is_lower_clip** (bool) - 如果为True,则此层的权重将被剪裁到大于下限值。如果为False,此层的权重不会被要求大于下限制。如果参数num大于100000,则is_lower_clip无效。 | |||
| - **min_num** (int) - 未抑制的剩余权重数。如果min_num小于(参数总数量 * `SupperssCtrl.sparse_end` ),则min_num无效。 | |||
| - **upper_bound** (Union[float, int]) - 此层权重的最大abs值,默认值:1.20。如果参数num大于100000,则upper_bound无效。 | |||
+ 0
- 129
docs/api/api_python/mindarmour.reliability.rst
View File
| @@ -1,129 +0,0 @@ | |||
| mindarmour.reliability | |||
| ====================== | |||
| MindArmour的可靠性方法。 | |||
| .. py:class:: mindarmour.reliability.FaultInjector(model, fi_type=None, fi_mode=None, fi_size=None) | |||
| 故障注入模块模拟深度神经网络的各种故障场景,并评估模型的性能和可靠性。 | |||
| 详情请查看 `实现模型故障注入评估模型容错性 <https://mindspore.cn/mindarmour/docs/zh-CN/master/fault_injection.html>`_。 | |||
| 参数: | |||
| - **model** (Model) - 需要评估模型。 | |||
| - **fi_type** (list) - 故障注入的类型,包括'bitflips_random'(随机翻转)、'bitflips_designated'(翻转关键位)、'random'、'zeros'、'nan'、'inf'、'anti_activation'、'precision_loss'等。 | |||
| - **fi_mode** (list) - 故障注入的模式。可选值:'single_layer','all_layer'。 | |||
| - **fi_size** (list) - 故障注入的次数,表示需要注入多少值。 | |||
| .. py:method:: kick_off(ds_data, ds_label, iter_times=100) | |||
| 启动故障注入并返回最终结果。 | |||
| 参数: | |||
| - **ds_data** (np.ndarray) - 输入测试数据。评估基于这些数据。 | |||
| - **ds_label** (np.ndarray) - 数据的标签,对应于数据。 | |||
| - **iter_times** (int) - 评估数,这将决定批处理大小。 | |||
| 返回: | |||
| - **list** - 故障注入的结果。 | |||
| .. py:method:: metrics() | |||
| 最终结果的指标。 | |||
| 返回: | |||
| - **list** - 结果总结。 | |||
| .. py:class:: mindarmour.reliability.ConceptDriftCheckTimeSeries(window_size=100, rolling_window=10, step=10, threshold_index=1.5, need_label=False) | |||
| 概念漂移检查时间序列(ConceptDriftCheckTimeSeries)用于样本序列分布变化检测。 | |||
| 有关详细信息,请查看 `实现时序数据概念漂移检测应用 | |||
| <https://mindspore.cn/mindarmour/docs/zh-CN/master/concept_drift_time_series.html>`_。 | |||
| 参数: | |||
| - **window_size** (int) - 概念窗口的大小,不小于10。如果给定输入数据, `window_size` 在[10, 1/3*len( `data` )]中。 | |||
| 如果数据是周期性的,通常 `window_size` 等于2-5个周期。例如,对于月/周数据,30/7天的数据量是一个周期。默认值:100。 | |||
| - **rolling_window** (int) - 平滑窗口大小,在[1, `window_size` ]中。默认值:10。 | |||
| - **step** (int) - 滑动窗口的跳跃长度,在[1, `window_size` ]中。默认值:10。 | |||
| - **threshold_index** (float) - 阈值索引,:math:`(-\infty, +\infty)` 。默认值:1.5。 | |||
| - **need_label** (bool) - False或True。如果 `need_label` =True,则需要概念漂移标签。默认值:False。 | |||
| .. py:method:: concept_check(data) | |||
| 在数据序列中查找概念漂移位置。 | |||
| 参数: | |||
| - **data** (numpy.ndarray) - 输入数据。数据的shape可以是(n,1)或(n,m)。 | |||
| 请注意,每列(m列)是一个数据序列。 | |||
| 返回: | |||
| - **numpy.ndarray** - 样本序列的概念漂移分数。 | |||
| - **float** - 判断概念漂移的阈值。 | |||
| - **list** - 概念漂移的位置。 | |||
| .. py:class:: mindarmour.reliability.OodDetector(model, ds_train) | |||
| 分布外检测器的抽象类。 | |||
| 参数: | |||
| - **model** (Model) - 训练模型。 | |||
| - **ds_train** (numpy.ndarray) - 训练数据集。 | |||
| .. py:method:: get_optimal_threshold(label, ds_eval) | |||
| 获取最佳阈值。尝试找到一个最佳阈值来检测OOD样本。最佳阈值由标记的数据集 `ds_eval` 计算。 | |||
| 参数: | |||
| - **label** (numpy.ndarray) - 区分图像是否为分布内或分布外的标签。 | |||
| - **ds_eval** (numpy.ndarray) - 帮助查找阈值的测试数据集。 | |||
| 返回: | |||
| - **float** - 最佳阈值。 | |||
| .. py:method:: ood_predict(threshold, ds_test) | |||
| 分布外(out-of-distribution,OOD)检测。此函数的目的是检测被视为 `ds_test` 的图像是否为OOD样本。如果一张图像的预测分数大于 `threshold` ,则该图像为分布外。 | |||
| 参数: | |||
| - **threshold** (float) - 判断ood数据的阈值。可以根据经验设置值,也可以使用函数get_optimal_threshold。 | |||
| - **ds_test** (numpy.ndarray) - 测试数据集。 | |||
| 返回: | |||
| - **numpy.ndarray** - 检测结果。0表示数据不是ood,1表示数据是ood。 | |||
| .. py:class:: mindarmour.reliability.OodDetectorFeatureCluster(model, ds_train, n_cluster, layer) | |||
| 训练OOD检测器。提取训练数据特征,得到聚类中心。测试数据特征与聚类中心之间的距离确定图像是否为分布外(OOD)图像。 | |||
| 有关详细信息,请查看 `实现图像数据概念漂移检测应用 <https://mindspore.cn/mindarmour/docs/zh-CN/master/concept_drift_images.html>`_。 | |||
| 参数: | |||
| - **model** (Model) - 训练模型。 | |||
| - **ds_train** (numpy.ndarray) - 训练数据集。 | |||
| - **n_cluster** (int) - 聚类数量。取值属于[2,100]。 | |||
| 通常,n_cluster等于训练数据集的类号。如果OOD检测器在测试数据集中性能较差,我们可以适当增加n_cluster的值。 | |||
| - **layer** (str) - 特征层的名称。layer (str)由'name[:Tensor]'表示,其中'name'由用户在训练模型时给出。 | |||
| 请查看有关如何在'README.md'中命名模型层的更多详细信息。 | |||
| .. py:method:: get_optimal_threshold(label, ds_eval) | |||
| 获取最佳阈值。尝试找到一个最佳阈值来检测OOD样本。最佳阈值由标记的数据集 `ds_eval` 计算。 | |||
| 参数: | |||
| - **label** (numpy.ndarray) - 区分图像是否为分布内或分布外的标签。 | |||
| - **ds_eval** (numpy.ndarray) - 帮助查找阈值的测试数据集。 | |||
| 返回: | |||
| - **float** - 最佳阈值。 | |||
| .. py:method:: ood_predict(threshold, ds_test) | |||
| 分布外(out-of-distribution,OOD)检测。此函数的目的是检测 `ds_test` 中的图像是否为OOD样本。如果一张图像的预测分数大于 `threshold` ,则该图像为分布外。 | |||
| 参数: | |||
| - **threshold** (float) - 判断ood数据的阈值。可以根据经验设置值,也可以使用函数get_optimal_threshold。 | |||
| - **ds_test** (numpy.ndarray) - 测试数据集。 | |||
| 返回: | |||
| - **numpy.ndarray** - 检测结果。0表示数据不是ood,1表示数据是ood。 | |||
+ 0
- 344
docs/api/api_python/mindarmour.rst
View File
| @@ -1,344 +0,0 @@ | |||
| mindarmour | |||
| ========== | |||
| MindArmour是MindSpore的工具箱,用于增强模型可信,实现隐私保护机器学习。 | |||
| .. py:class:: mindarmour.Attack | |||
| 所有通过创建对抗样本的攻击类的抽象基类。 | |||
| 对抗样本是通过向原始样本添加对抗噪声来生成的。 | |||
| .. py:method:: batch_generate(inputs, labels, batch_size=64) | |||
| 根据输入样本及其标签来批量生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 生成对抗样本的原始样本。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 原始/目标标签。若每个输入有多个标签,将它包装在元组中。 | |||
| - **batch_size** (int) - 一个批次中的样本数。默认值:64。 | |||
| 返回: | |||
| - **numpy.ndarray** - 生成的对抗样本。 | |||
| .. py:method:: generate(inputs, labels) | |||
| 根据正常样本及其标签生成对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, tuple]) - 生成对抗样本的原始样本。 | |||
| - **labels** (Union[numpy.ndarray, tuple]) - 原始/目标标签。若每个输入有多个标签,将它包装在元组中。 | |||
| 异常: | |||
| - **NotImplementedError** - 此为抽象方法。 | |||
| .. py:class:: mindarmour.BlackModel | |||
| 将目标模型视为黑盒的抽象类。模型应由用户定义。 | |||
| .. py:method:: is_adversarial(data, label, is_targeted) | |||
| 检查输入样本是否为对抗样本。 | |||
| 参数: | |||
| - **data** (numpy.ndarray) - 要检查的输入样本,通常是一些恶意干扰的样本。 | |||
| - **label** (numpy.ndarray) - 对于目标攻击,标签是受扰动样本的预期标签。对于无目标攻击,标签是相应未扰动样本的原始标签。 | |||
| - **is_targeted** (bool) - 对于有目标/无目标攻击,请选择True/False。 | |||
| 返回: | |||
| - **bool** - 如果为True,则输入样本是对抗性的。如果为False,则输入样本不是对抗性的。 | |||
| .. py:method:: predict(inputs) | |||
| 使用用户指定的模型进行预测。预测结果的shape应该是(m,n),其中n表示此模型分类的类数。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 要预测的输入样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法未实现。 | |||
| .. py:class:: mindarmour.Detector | |||
| 所有对抗样本检测器的抽象基类。 | |||
| .. py:method:: detect(inputs) | |||
| 从输入样本中检测对抗样本。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 要检测的输入样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法未实现。 | |||
| .. py:method:: detect_diff(inputs) | |||
| 计算输入样本和去噪样本之间的差值。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 要检测的输入样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法未实现。 | |||
| .. py:method:: fit(inputs, labels=None) | |||
| 拟合阈值,拒绝与去噪样本差异大于阈值的对抗样本。当应用于正常样本时,阈值由假正率决定。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 用于计算阈值的输入样本。 | |||
| - **labels** (numpy.ndarray) - 训练数据的标签。默认值:None。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法未实现。 | |||
| .. py:method:: transform(inputs) | |||
| 过滤输入样本中的对抗性噪声。 | |||
| 参数: | |||
| - **inputs** (Union[numpy.ndarray, list, tuple]) - 要转换的输入样本。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法未实现。 | |||
| .. py:class:: mindarmour.Defense(network) | |||
| 所有防御类的抽象基类,用于防御对抗样本。 | |||
| 参数: | |||
| - **network** (Cell) - 要防御的MindSpore风格的深度学习模型。 | |||
| .. py:method:: batch_defense(inputs, labels, batch_size=32, epochs=5) | |||
| 对输入进行批量防御操作。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 生成对抗样本的原始样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的标签。 | |||
| - **batch_size** (int) - 一个批次中的样本数。默认值:32。 | |||
| - **epochs** (int) - epochs的数量。默认值:5。 | |||
| 返回: | |||
| - **numpy.ndarray** - `batch_defense` 操作的损失。 | |||
| 异常: | |||
| - **ValueError** - `batch_size` 为0。 | |||
| .. py:method:: defense(inputs, labels) | |||
| 对输入进行防御操作。 | |||
| 参数: | |||
| - **inputs** (numpy.ndarray) - 生成对抗样本的原始样本。 | |||
| - **labels** (numpy.ndarray) - 输入样本的标签。 | |||
| 异常: | |||
| - **NotImplementedError** - 抽象方法未实现。 | |||
| .. py:class:: mindarmour.Fuzzer(target_model) | |||
| 深度神经网络的模糊测试框架。 | |||
| 参考文献: `DeepHunter: A Coverage-Guided Fuzz Testing Framework for Deep Neural Networks <https://dl.acm.org/doi/10.1145/3293882.3330579>`_。 | |||
| 参数: | |||
| - **target_model** (Model) - 目标模糊模型。 | |||
| .. py:method:: fuzzing(mutate_config, initial_seeds, coverage, evaluate=True, max_iters=10000, mutate_num_per_seed=20) | |||
| 深度神经网络的模糊测试。 | |||
| 参数: | |||
| - **mutate_config** (list) - 变异方法配置。格式为: | |||
| .. code-block:: python | |||
| mutate_config = | |||
| [{'method': 'GaussianBlur', | |||
| 'params': {'ksize': [1, 2, 3, 5], 'auto_param': [True, False]}}, | |||
| {'method': 'UniformNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'GaussianNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'Contrast', | |||
| 'params': {'alpha': [0.5, 1, 1.5], 'beta': [-10, 0, 10], 'auto_param': [False, True]}}, | |||
| {'method': 'Rotate', | |||
| 'params': {'angle': [20, 90], 'auto_param': [False, True]}}, | |||
| {'method': 'FGSM', | |||
| 'params': {'eps': [0.3, 0.2, 0.4], 'alpha': [0.1], 'bounds': [(0, 1)]}}] | |||
| ...] | |||
| - 支持的方法在列表 `self._strategies` 中,每个方法的参数必须在可选参数的范围内。支持的方法分为两种类型: | |||
| - 首先,自然鲁棒性方法包括:'Translate', 'Scale'、'Shear'、'Rotate'、'Perspective'、'Curve'、'GaussianBlur'、'MotionBlur'、'GradientBlur'、'Contrast'、'GradientLuminance'、'UniformNoise'、'GaussianNoise'、'SaltAndPepperNoise'、'NaturalNoise'。 | |||
| - 其次,对抗样本攻击方式包括:'FGSM'、'PGD'和'MDIM'。'FGSM'、'PGD'和'MDIM'分别是 FastGradientSignMethod、ProjectedGradientDent和MomentumDiverseInputIterativeMethod的缩写。 `mutate_config` 必须包含在['Contrast', 'GradientLuminance', 'GaussianBlur', 'MotionBlur', 'GradientBlur', 'UniformNoise', 'GaussianNoise', 'SaltAndPepperNoise', 'NaturalNoise']中的方法。 | |||
| - 第一类方法的参数设置方式可以在 `mindarmour/natural_robustness/transform/image <https://gitee.com/mindspore/mindarmour/tree/master/mindarmour/natural_robustness/transform/image>`_ 中看到。第二类方法参数配置参考 `self._attack_param_checklists` 。 | |||
| - **initial_seeds** (list[list]) - 用于生成变异样本的初始种子队列。初始种子队列的格式为[[image_data, label], [...], ...],且标签必须为one-hot。 | |||
| - **coverage** (CoverageMetrics) - 神经元覆盖率指标类。 | |||
| - **evaluate** (bool) - 是否返回评估报告。默认值:True。 | |||
| - **max_iters** (int) - 选择要变异的种子的最大数量。默认值:10000。 | |||
| - **mutate_num_per_seed** (int) - 每个种子的最大变异次数。默认值:20。 | |||
| 返回: | |||
| - **list** - 模糊测试生成的变异样本。 | |||
| - **list** - 变异样本的ground truth标签。 | |||
| - **list** - 预测结果。 | |||
| - **list** - 变异策略。 | |||
| - **dict** - Fuzzer的指标报告。 | |||
| 异常: | |||
| - **ValueError** - 参数'Coverage'必须是CoverageMetrics的子类。 | |||
| - **ValueError** - 初始种子队列为空。 | |||
| - **ValueError** - 初始种子队列中的种子不是包含两个元素。 | |||
| .. py:class:: mindarmour.DPModel(micro_batches=2, norm_bound=1.0, noise_mech=None, clip_mech=None, optimizer=nn.Momentum, **kwargs) | |||
| DPModel用于构建差分隐私训练的模型。 | |||
| 此类重载 :class:`mindspore.Model`。 | |||
| 详情请查看: `应用差分隐私机制保护用户隐私 <https://mindspore.cn/mindarmour/docs/zh-CN/master/protect_user_privacy_with_differential_privacy.html#%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81>`_。 | |||
| 参数: | |||
| - **micro_batches** (int) - 从原始批次拆分的小批次数。默认值:2。 | |||
| - **norm_bound** (float) - 用于裁剪的约束,如果设置为1,将返回原始数据。默认值:1.0。 | |||
| - **noise_mech** (Mechanisms) - 用于生成不同类型的噪音。默认值:None。 | |||
| - **clip_mech** (Mechanisms) - 用于更新自适应剪裁。默认值:None。 | |||
| - **optimizer** (Cell) - 用于更新差分隐私训练过程中的模型权重值。默认值:nn.Momentum。 | |||
| 异常: | |||
| - **ValueError** - `optimizer` 值为None。 | |||
| - **ValueError** - `optimizer` 不是DPOptimizer,且 `noise_mech` 为None。 | |||
| - **ValueError** - `optimizer` 是DPOptimizer,且 `noise_mech` 非None。 | |||
| - **ValueError** - `noise_mech` 或DPOptimizer的mech方法是自适应的,而 `clip_mech` 不是None。 | |||
| .. py:class:: mindarmour.MembershipInference(model, n_jobs=-1) | |||
| 成员推理是由Shokri、Stronati、Song和Shmatikov提出的一种用于推测用户隐私数据的灰盒攻击。它需要训练样本的loss或logits结果,隐私是指单个用户的一些敏感属性。 | |||
| 有关详细信息,请参见:`使用成员推理测试模型安全性 <https://mindspore.cn/mindarmour/docs/zh-CN/master/test_model_security_membership_inference.html>`_。 | |||
| 参考文献:`Reza Shokri, Marco Stronati, Congzheng Song, Vitaly Shmatikov. Membership Inference Attacks against Machine Learning Models. 2017. <https://arxiv.org/abs/1610.05820v2>`_。 | |||
| 参数: | |||
| - **model** (Model) - 目标模型。 | |||
| - **n_jobs** (int) - 并行运行的任务数量。-1表示使用所有处理器,否则n_jobs的值必须为正整数。 | |||
| 异常: | |||
| - **TypeError** - 模型的类型不是Mindspore.Model。 | |||
| - **TypeError** - `n_jobs` 的类型不是int。 | |||
| - **ValueError** - `n_jobs` 的值既不是-1,也不是正整数。 | |||
| .. py:method:: eval(dataset_train, dataset_test, metrics) | |||
| 评估目标模型的不同隐私。 | |||
| 评估指标应由metrics规定。 | |||
| 参数: | |||
| - **dataset_train** (mindspore.dataset) - 目标模型的训练数据集。 | |||
| - **dataset_test** (mindspore.dataset) - 目标模型的测试数据集。 | |||
| - **metrics** (Union[list, tuple]) - 评估指标。指标的值必须在["precision", "accuracy", "recall"]中。默认值:["precision"]。 | |||
| 返回: | |||
| - **list** - 每个元素都包含攻击模型的评估指标。 | |||
| .. py:method:: train(dataset_train, dataset_test, attack_config) | |||
| 根据配置,使用输入数据集训练攻击模型。 | |||
| 参数: | |||
| - **dataset_train** (mindspore.dataset) - 目标模型的训练数据集。 | |||
| - **dataset_test** (mindspore.dataset) - 目标模型的测试集。 | |||
| - **attack_config** (Union[list, tuple]) - 攻击模型的参数设置。格式为: | |||
| .. code-block:: | |||
| attack_config = [ | |||
| {"method": "knn", "params": {"n_neighbors": [3, 5, 7]}}, | |||
| {"method": "lr", "params": {"C": np.logspace(-4, 2, 10)}}] | |||
| - 支持的方法有knn、lr、mlp和rf,每个方法的参数必须在可变参数的范围内。参数实现的提示可在下面找到: | |||
| - `KNN <https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html>`_ | |||
| - `LR <https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html>`_ | |||
| - `RF <https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html>`_ | |||
| - `MLP <https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html>`_ | |||
| 异常: | |||
| - **KeyError** - `attack_config` 中的配置没有键{"method", "params"}。 | |||
| - **NameError** - `attack_config` 中的方法(不区分大小写)不在["lr", "knn", "rf", "mlp"]中。 | |||
| .. py:class:: mindarmour.ImageInversionAttack(network, input_shape, input_bound, loss_weights=(1, 0.2, 5)) | |||
| 一种通过还原图像的深层表达来重建图像的攻击方法。 | |||
| 参考文献:`Aravindh Mahendran, Andrea Vedaldi. Understanding Deep Image Representations by Inverting Them. 2014. <https://arxiv.org/pdf/1412.0035.pdf>`_。 | |||
| 参数: | |||
| - **network** (Cell) - 网络,用于推断图像的深层特征。 | |||
| - **input_shape** (tuple) - 单个网络输入的数据形状,应与给定网络一致。形状的格式应为(channel, image_width, image_height)。 | |||
| - **input_bound** (Union[tuple, list]) - 原始图像的像素范围,应该像[minimum_pixel, maximum_pixel]或(minimum_pixel, maximum_pixel)。 | |||
| - **loss_weights** (Union[list, tuple]) - InversionLoss中三个子损失的权重,可以调整以获得更好的结果。默认值:(1, 0.2, 5)。 | |||
| 异常: | |||
| - **TypeError** - 网络类型不是Cell。 | |||
| - **ValueError** - `input_shape` 的值有非正整数。 | |||
| - **ValueError** - `loss_weights` 的值有非正数。 | |||
| .. py:method:: evaluate(original_images, inversion_images, labels=None, new_network=None) | |||
| 通过三个指标评估还原图像的质量:原始图像和还原图像之间的平均L2距离和SSIM值,以及新模型对还原图像的推理结果在真实标签上的置信度平均值。 | |||
| 参数: | |||
| - **original_images** (numpy.ndarray) - 原始图像,其形状应为(img_num, channels, img_width, img_height)。 | |||
| - **inversion_images** (numpy.ndarray) - 还原图像,其形状应为(img_num, channels, img_width, img_height)。 | |||
| - **labels** (numpy.ndarray) - 原始图像的ground truth标签。默认值:None。 | |||
| - **new_network** (Cell) - 其结构包含self._network中所有网络,但加载了不同的模型文件。默认值:None。 | |||
| 返回: | |||
| - **float** - l2距离。 | |||
| - **float** - 平均ssim值。 | |||
| - **Union** [float, None] - 平均置信度。如果labels或new_network为 None,则该值为None。 | |||
| .. py:method:: generate(target_features, iters=100) | |||
| 根据 `target_features` 重建图像。 | |||
| 参数: | |||
| - **target_features** (numpy.ndarray) - 原始图像的深度表示。 `target_features` 的第一个维度应该是img_num。 | |||
| 需要注意的是,如果img_num等于1,则 `target_features` 的形状应该是(1, dim2, dim3, ...)。 | |||
| - **iters** (int) - 逆向攻击的迭代次数,应为正整数。默认值:100。 | |||
| 返回: | |||
| - **numpy.ndarray** - 重建图像,预计与原始图像相似。 | |||
| 异常: | |||
| - **TypeError** - target_features的类型不是numpy.ndarray。 | |||
| - **ValueError** - `iters` 的有非正整数. | |||
| .. py:class:: mindarmour.ConceptDriftCheckTimeSeries(window_size=100, rolling_window=10, step=10, threshold_index=1.5, need_label=False) | |||
| 概念漂移检查时间序列(ConceptDriftCheckTimeSeries)用于样本序列分布变化检测。 | |||
| 有关详细信息,请查看: `实现时序数据概念漂移检测应用 <https://mindspore.cn/mindarmour/docs/zh-CN/master/concept_drift_time_series.html>`_。 | |||
| 参数: | |||
| - **window_size** (int) - 概念窗口的大小,不小于10。如果给定输入数据,window_size在[10, 1/3*len(input data)]中。如果数据是周期性的,通常window_size等于2-5个周期,例如,对于月/周数据,30/7天的数据量是一个周期。默认值:100。 | |||
| - **rolling_window** (int) - 平滑窗口大小,在[1, window_size]中。默认值:10。 | |||
| - **step** (int) - 滑动窗口的跳跃长度,在[1, window_size]中。默认值:10。 | |||
| - **threshold_index** (float) - 阈值索引,:math:`(-\infty, +\infty)` 。默认值:1.5。 | |||
| - **need_label** (bool) - False或True。如果need_label=True,则需要概念漂移标签。默认值:False。 | |||
| .. py:method:: concept_check(data) | |||
| 在数据序列中查找概念漂移位置。 | |||
| 参数: | |||
| - **data** (numpy.ndarray) - 输入数据。数据的shape可以是(n,1)或(n,m)。请注意,每列(m列)是一个数据序列。 | |||
| 返回: | |||
| - **numpy.ndarray** - 样本序列的概念漂移分数。 | |||
| - **float** - 判断概念漂移的阈值。 | |||
| - **list** - 概念漂移的位置。 | |||
+ 0
- 113
docs/api/api_python/mindarmour.utils.rst
View File
| @@ -1,113 +0,0 @@ | |||
| mindarmour.utils | |||
| ================ | |||
| MindArmour的工具方法。 | |||
| .. py:class:: mindarmour.utils.LogUtil | |||
| 日志记录模块。 | |||
| 在长期运行的脚本中记录随时间推移的日志统计信息。 | |||
| 异常: | |||
| - **SyntaxError** - 创建此类异常。 | |||
| .. py:method:: add_handler(handler) | |||
| 添加日志模块支持的其他处理程序。 | |||
| 参数: | |||
| - **handler** (logging.Handler) - 日志模块支持的其他处理程序。 | |||
| 异常: | |||
| - **ValueError** - 输入handler不是logging.Handler的实例。 | |||
| .. py:method:: debug(tag, msg, *args) | |||
| 记录'[tag] msg % args',严重性为'DEBUG'。 | |||
| 参数: | |||
| - **tag** (str) - Logger标记。 | |||
| - **msg** (str) - Logger消息。 | |||
| - **args** (Any) - 辅助值。 | |||
| .. py:method:: error(tag, msg, *args) | |||
| 记录'[tag] msg % args',严重性为'ERROR'。 | |||
| 参数: | |||
| - **tag** (str) - Logger标记。 | |||
| - **msg** (str) - Logger消息。 | |||
| - **args** (Any) - 辅助值。 | |||
| .. py:method:: get_instance() | |||
| 获取类 `LogUtil` 的实例。 | |||
| 返回: | |||
| - **Object** - 类 `LogUtil` 的实例。 | |||
| .. py:method:: info(tag, msg, *args) | |||
| 记录'[tag] msg % args',严重性为'INFO'。 | |||
| 参数: | |||
| - **tag** (str) - Logger标记。 | |||
| - **msg** (str) - Logger消息。 | |||
| - **args** (Any) - 辅助值。 | |||
| .. py:method:: set_level(level) | |||
| 设置此logger的日志级别,级别必须是整数或字符串。支持的级别为 'NOTSET'(integer: 0)、'ERROR'(integer: 1-40)、'WARNING'('WARN', integer: 1-30)、'INFO'(integer: 1-20)以及'DEBUG'(integer: 1-10) | |||
| 例如,如果logger.set_level('WARNING')或logger.set_level(21),则在运行时将打印脚本中的logger.warn()和logger.error(),而logger.info()或logger.debug()将不会打印。 | |||
| 参数: | |||
| - **level** (Union[int, str]) - logger的级别。 | |||
| .. py:method:: warn(tag, msg, *args) | |||
| 记录'[tag] msg % args',严重性为'WARNING'。 | |||
| 参数: | |||
| - **tag** (str) - Logger标记。 | |||
| - **msg** (str) - Logger消息。 | |||
| - **args** (Any) - 辅助值。 | |||
| .. py:class:: mindarmour.utils.GradWrapWithLoss(network) | |||
| 构造一个网络来计算输入空间中损失函数的梯度,并由 `weight` 加权。 | |||
| 参数: | |||
| - **network** (Cell) - 要包装的目标网络。 | |||
| .. py:method:: construct(inputs, labels) | |||
| 使用标签和权重计算 `inputs` 的梯度。 | |||
| 参数: | |||
| - **inputs** (Tensor) - 网络的输入。 | |||
| - **labels** (Tensor) - 输入的标签。 | |||
| 返回: | |||
| - **Tensor** - 梯度矩阵。 | |||
| .. py:class:: mindarmour.utils.GradWrap(network) | |||
| 构建一个网络,以计算输入空间中网络输出的梯度,并由 `weight` 加权,表示为雅可比矩阵。 | |||
| 参数: | |||
| - **network** (Cell) - 要包装的目标网络。 | |||
| .. py:method:: construct(*data) | |||
| 计算雅可比矩阵(jacobian matrix)。 | |||
| 参数: | |||
| - **data** (Tensor) - 数据由输入和权重组成。 | |||
| - inputs: 网络的输入。 | |||
| - weight: 每个梯度的权重,'weight'与'labels'的shape相同。 | |||
| 返回: | |||
| - **Tensor** - 雅可比矩阵。 | |||
BIN
docs/differential_privacy_architecture_cn.png
View File
{kind=link}
| Before | After |
|---|---|
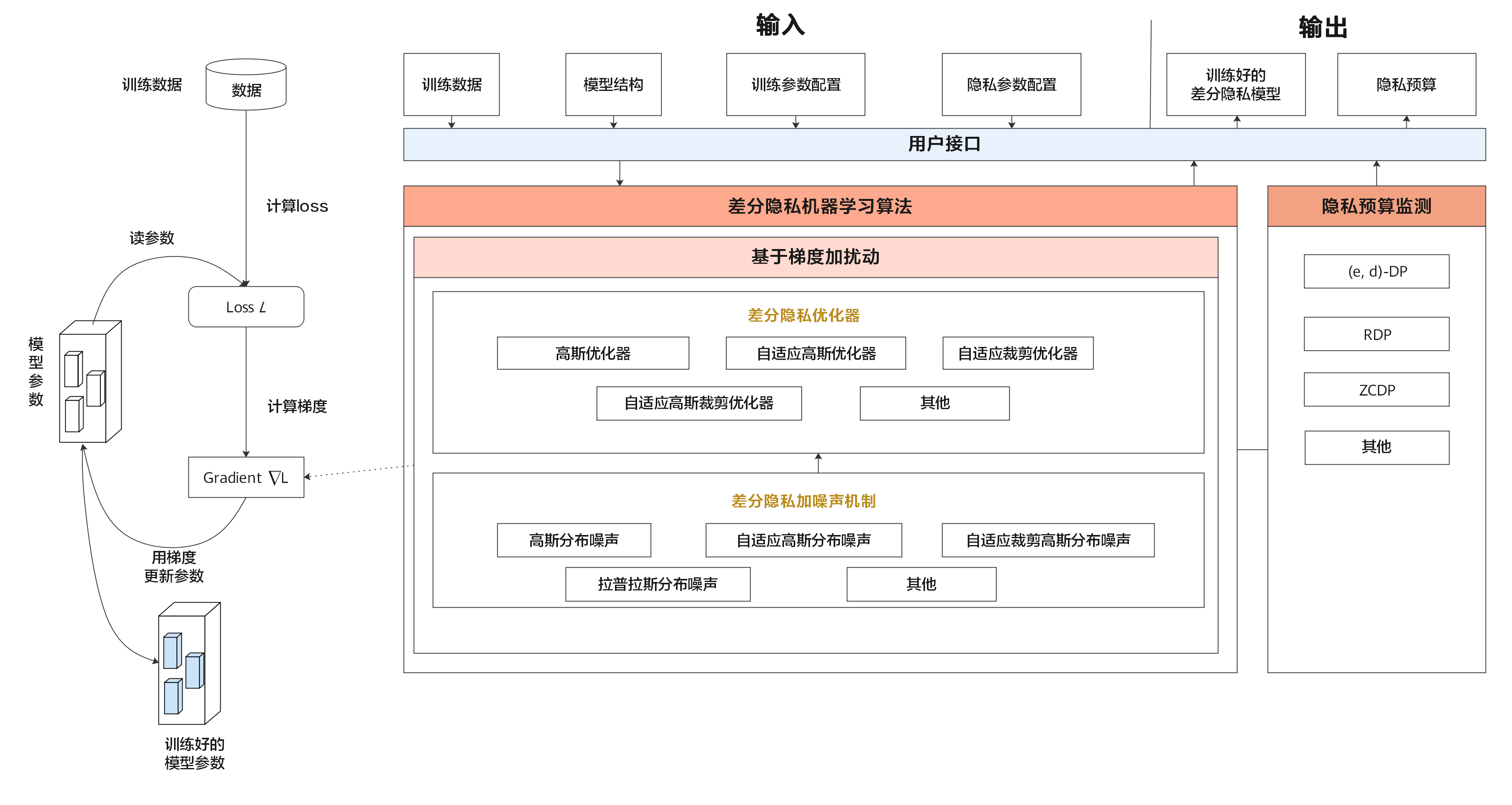
|
|
| Width: 3892 | Height: 2072 | Size: 236 kB |
BIN
docs/differential_privacy_architecture_en.png
View File
{kind=link}
| Before | After |
|---|---|
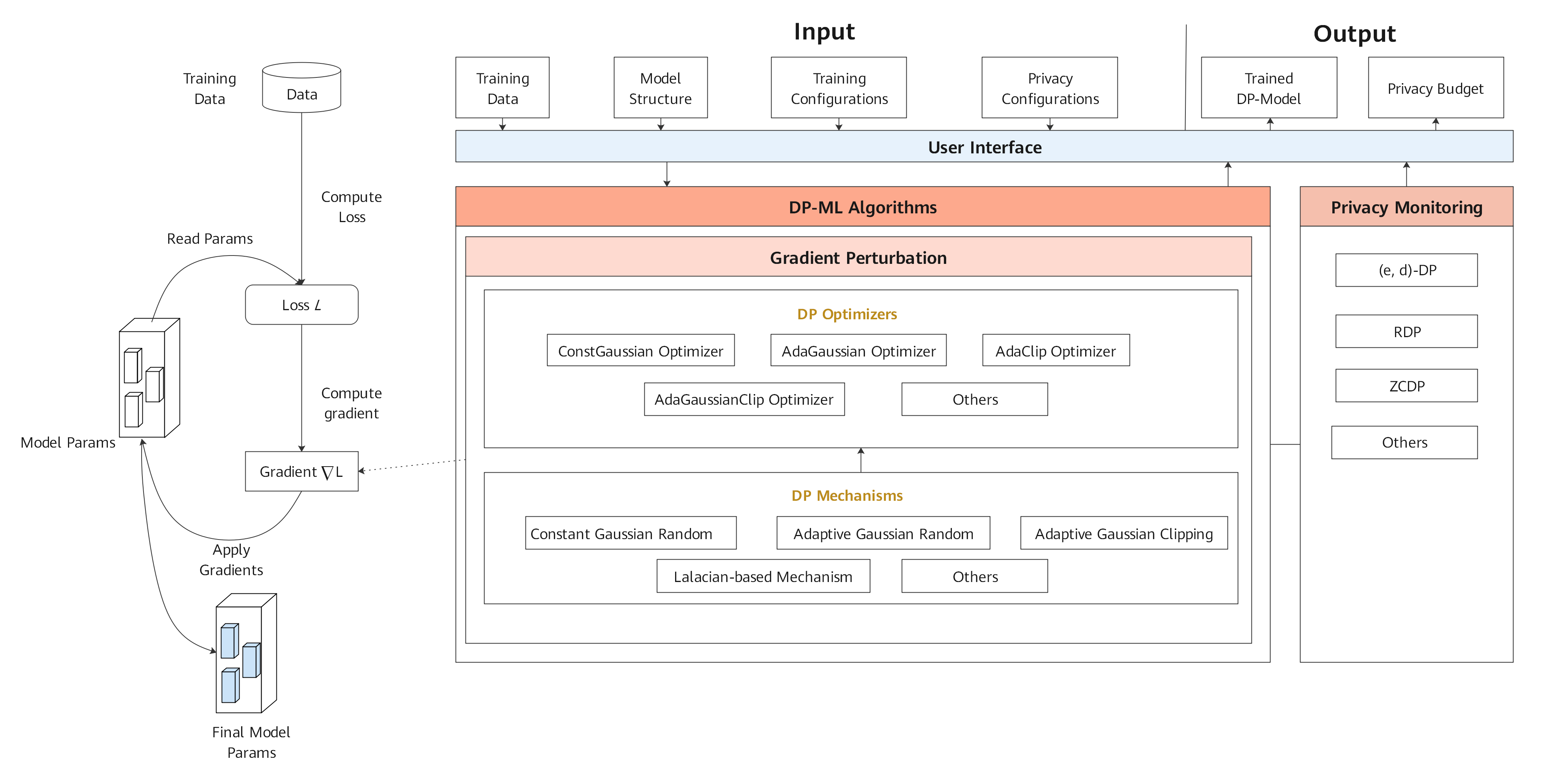
|
|
| Width: 4077 | Height: 2065 | Size: 218 kB |
BIN
docs/fuzzer_architecture_cn.png
View File
{kind=link}
| Before | After |
|---|---|
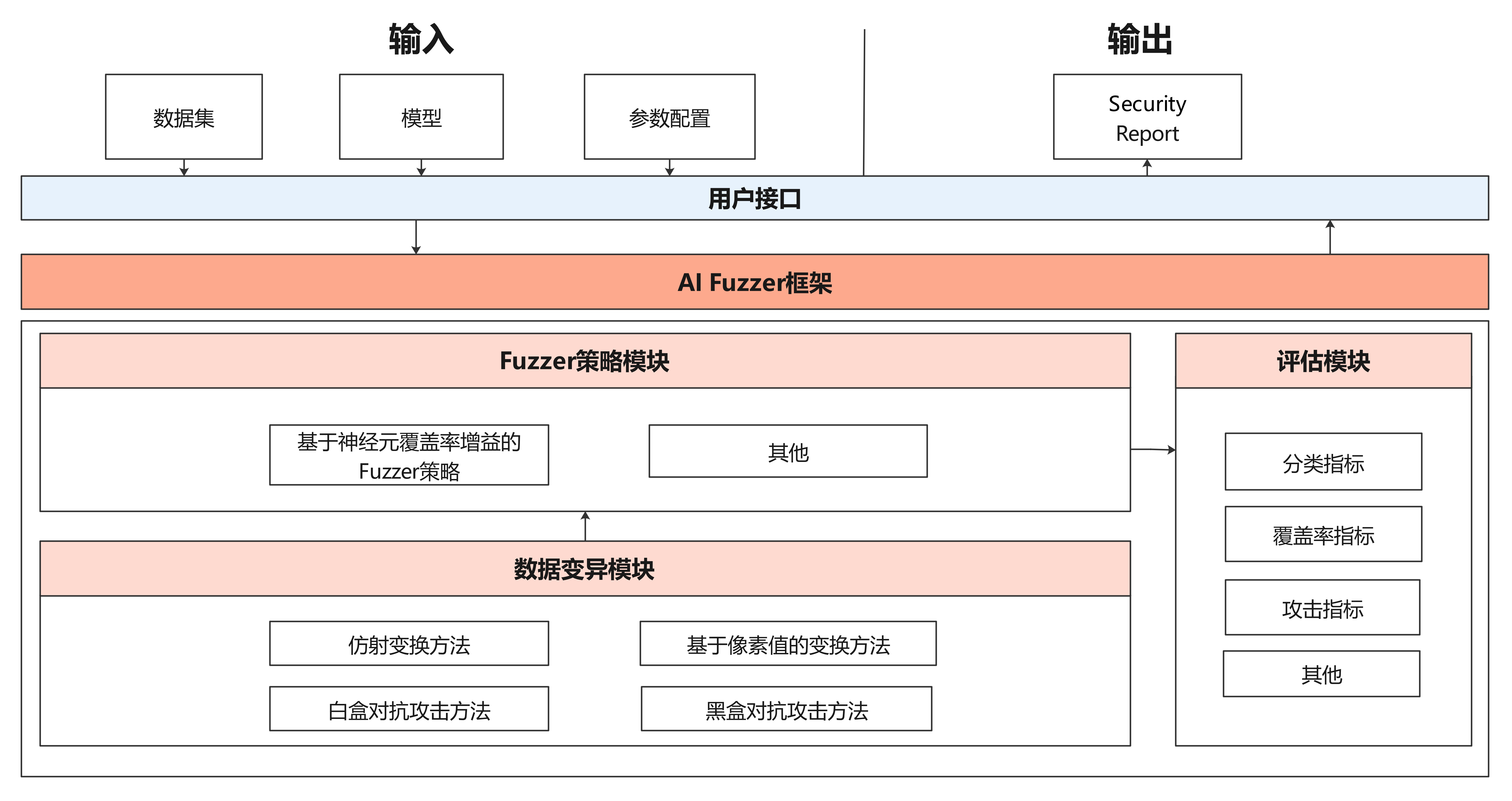
|
|
| Width: 6041 | Height: 3201 | Size: 394 kB |
BIN
docs/fuzzer_architecture_en.png
View File
{kind=link}
| Before | After |
|---|---|
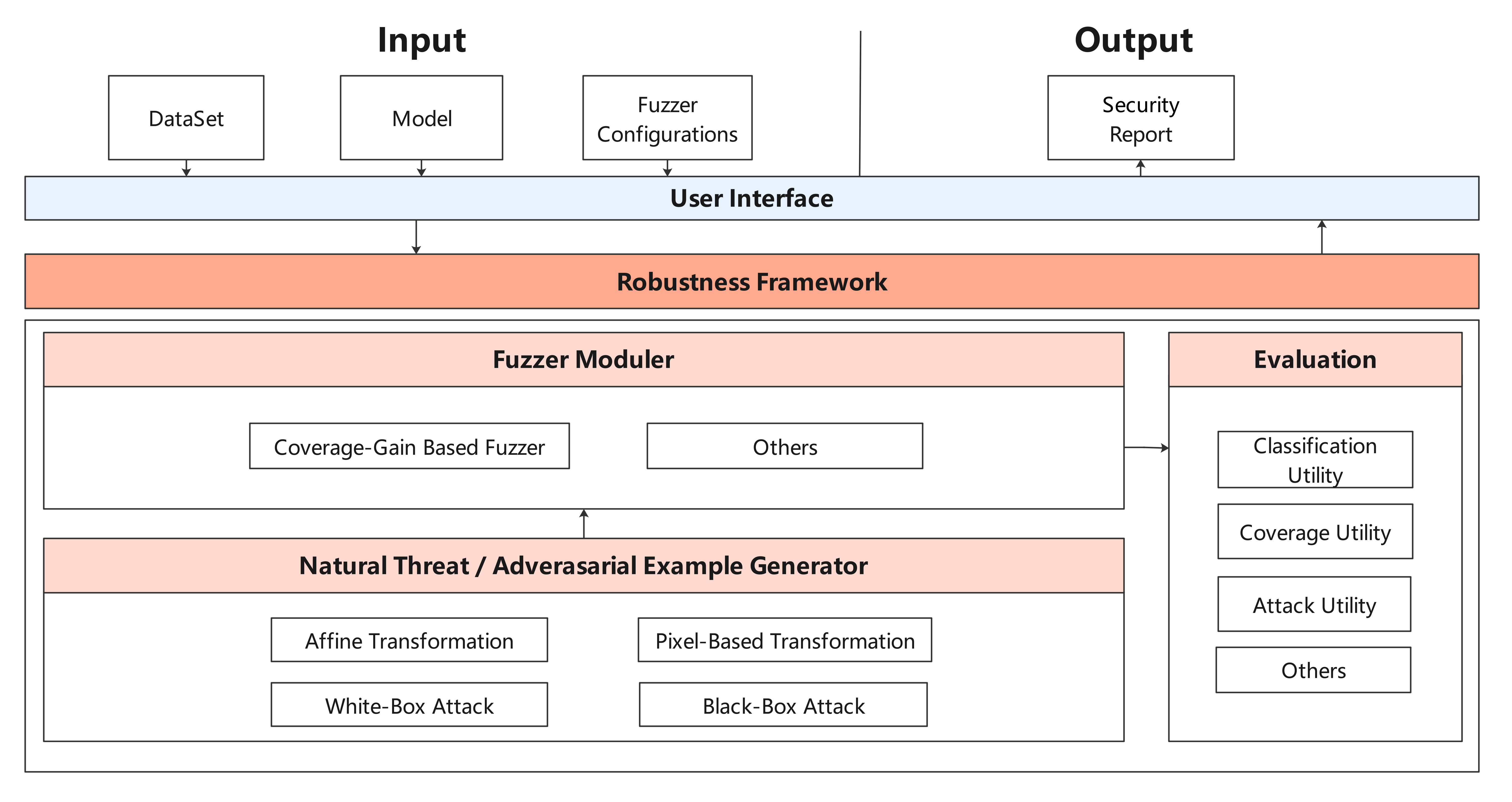
|
|
| Width: 6097 | Height: 3233 | Size: 394 kB |
BIN
docs/mindarmour_architecture.png
View File
{kind=link}
| Before | After |
|---|---|
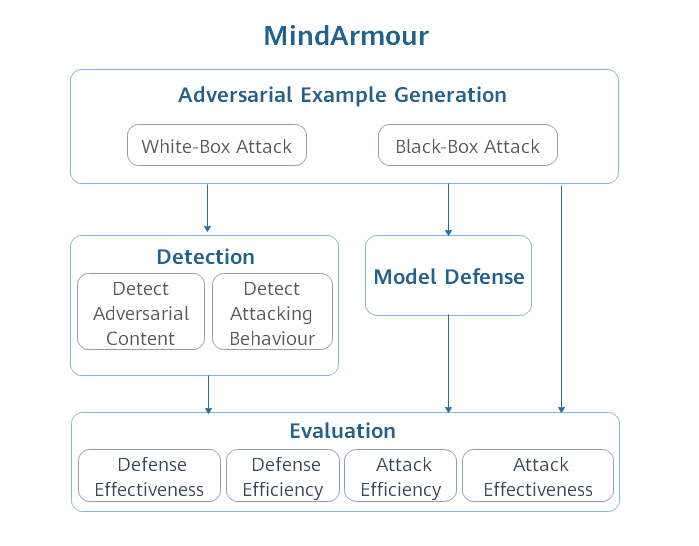
|
|
| Width: 699 | Height: 546 | Size: 28 kB |
BIN
docs/privacy_leakage_cn.png
View File
{kind=link}
| Before | After |
|---|---|
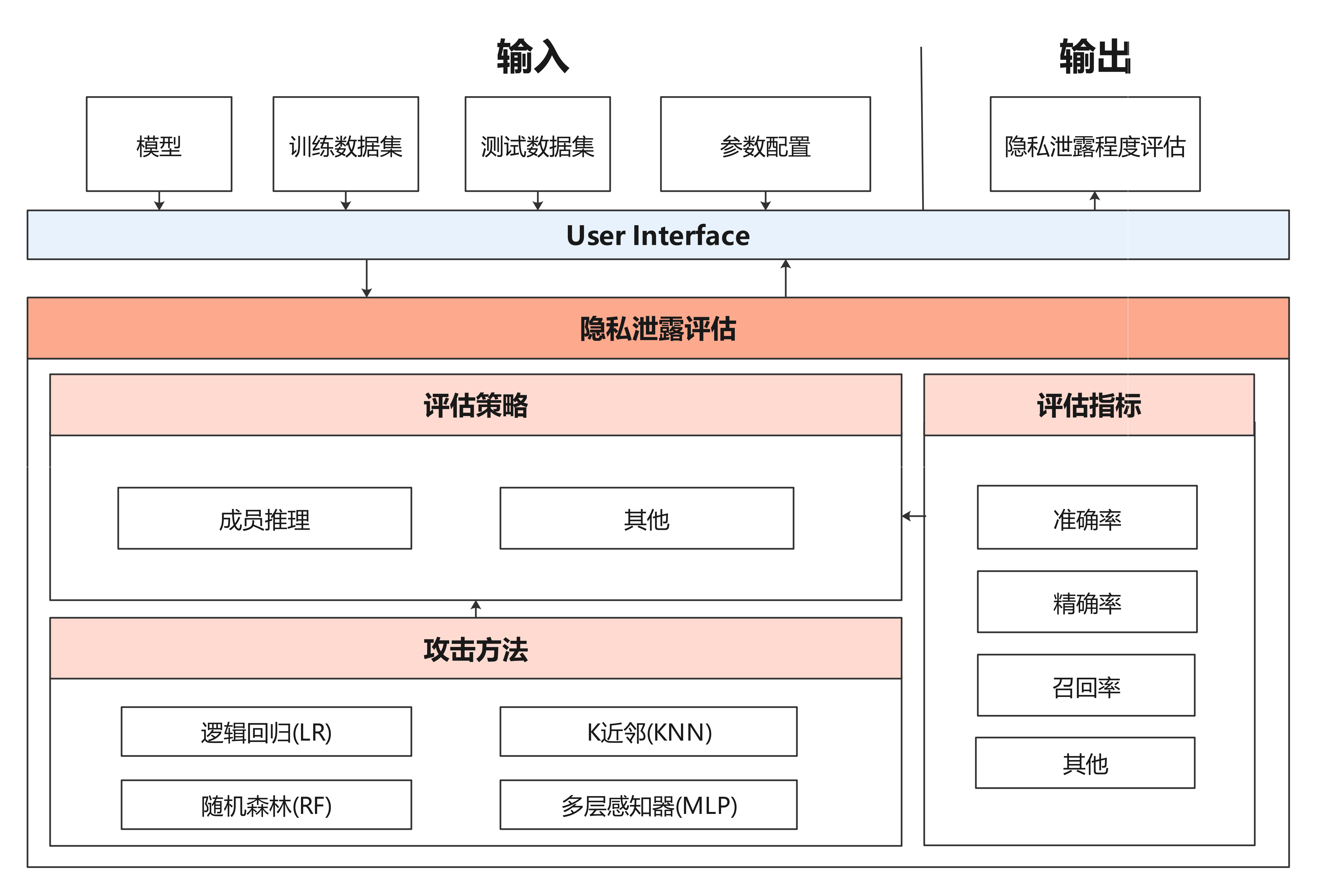
|
|
| Width: 4721 | Height: 3209 | Size: 334 kB |
BIN
docs/privacy_leakage_en.png
View File
{kind=link}
| Before | After |
|---|---|
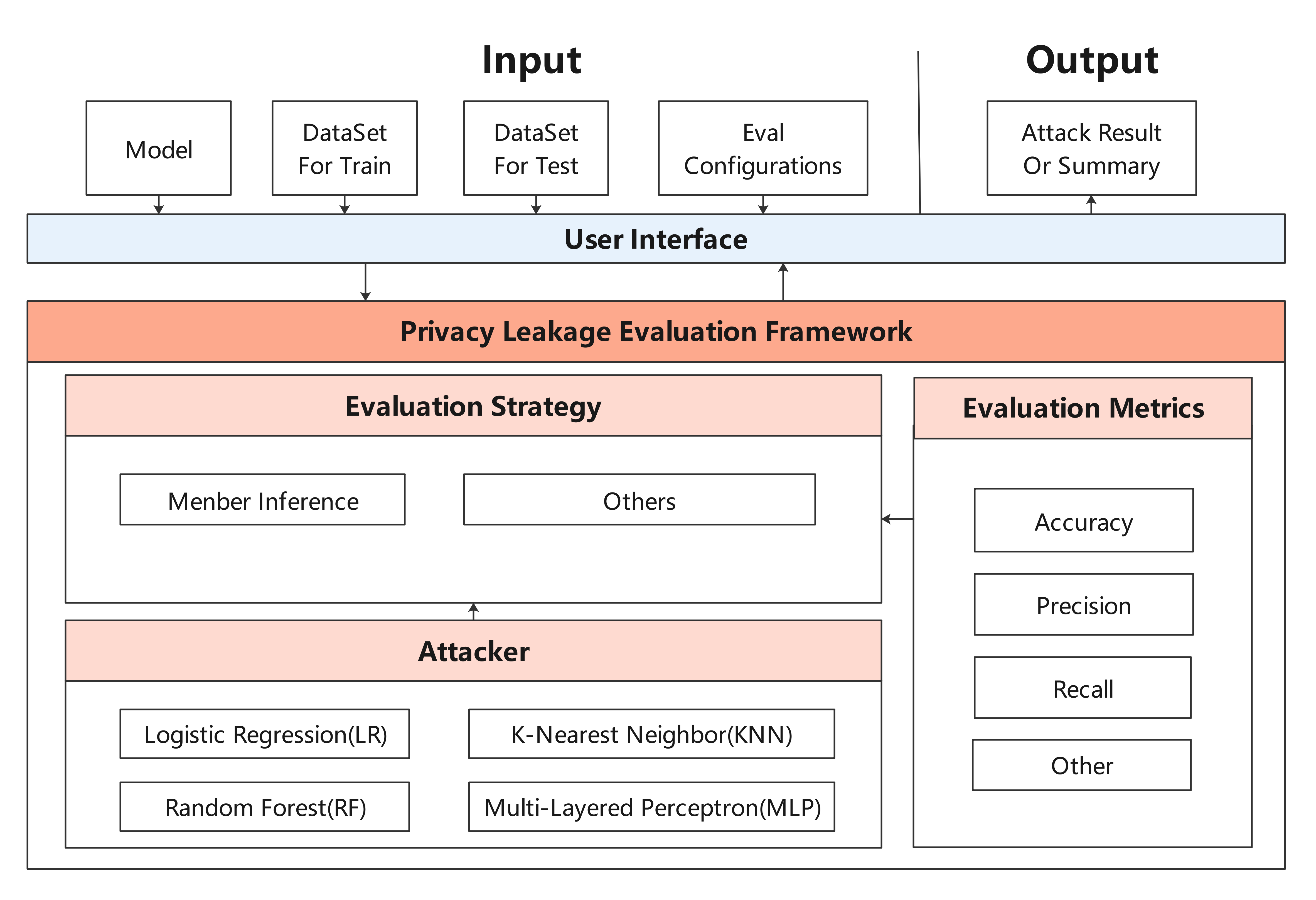
|
|
| Width: 4729 | Height: 3233 | Size: 371 kB |
+ 62
- 0
example/data_processing.py
View File
| @@ -0,0 +1,62 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.transforms.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.transforms.vision import Inter | |||
| import mindspore.common.dtype as mstype | |||
| def generate_mnist_dataset(data_path, batch_size=32, repeat_size=1, | |||
| num_parallel_workers=1, sparse=True): | |||
| """ | |||
| create dataset for training or testing | |||
| """ | |||
| # define dataset | |||
| ds1 = ds.MnistDataset(data_path) | |||
| # define operation parameters | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), | |||
| interpolation=Inter.LINEAR) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| one_hot_enco = C.OneHot(10) | |||
| # apply map operations on images | |||
| if not sparse: | |||
| ds1 = ds1.map(input_columns="label", operations=one_hot_enco, | |||
| num_parallel_workers=num_parallel_workers) | |||
| type_cast_op = C.TypeCast(mstype.float32) | |||
| ds1 = ds1.map(input_columns="label", operations=type_cast_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=resize_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=rescale_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=hwc2chw_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| ds1 = ds1.shuffle(buffer_size=buffer_size) | |||
| ds1 = ds1.batch(batch_size, drop_remainder=True) | |||
| ds1 = ds1.repeat(repeat_size) | |||
| return ds1 | |||
+ 46
- 0
example/mnist_demo/README.md
View File
| @@ -0,0 +1,46 @@ | |||
| # mnist demo | |||
| ## Introduction | |||
| The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from MNIST. The digits have been size-normalized and centered in a fixed-size image. | |||
| ## run demo | |||
| ### 1. download dataset | |||
| ```sh | |||
| $ cd example/mnist_demo | |||
| $ mkdir MNIST_unzip | |||
| $ cd MNIST_unzip | |||
| $ mkdir train | |||
| $ mkdir test | |||
| $ cd train | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz" | |||
| $ gzip train-images-idx3-ubyte.gz -d | |||
| $ gzip train-labels-idx1-ubyte.gz -d | |||
| $ cd ../test | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz" | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ cd ../../ | |||
| ``` | |||
| ### 1. trian model | |||
| ```sh | |||
| $ python mnist_train.py | |||
| ``` | |||
| ### 2. run attack test | |||
| ```sh | |||
| $ mkdir out.data | |||
| $ python mnist_attack_jsma.py | |||
| ``` | |||
| ### 3. run defense/detector test | |||
| ```sh | |||
| $ python mnist_defense_nad.py | |||
| $ python mnist_similarity_detector.py | |||
| ``` | |||
examples/common/networks/lenet5/lenet5_net.py → example/mnist_demo/lenet5_net.py
View File
| @@ -11,7 +11,8 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| from mindspore import nn | |||
| import mindspore.nn as nn | |||
| import mindspore.ops.operations as P | |||
| from mindspore.common.initializer import TruncatedNormal | |||
| @@ -29,7 +30,7 @@ def fc_with_initialize(input_channels, out_channels): | |||
| def weight_variable(): | |||
| return TruncatedNormal(0.05) | |||
| return TruncatedNormal(0.2) | |||
| class LeNet5(nn.Cell): | |||
| @@ -45,7 +46,7 @@ class LeNet5(nn.Cell): | |||
| self.fc3 = fc_with_initialize(84, 10) | |||
| self.relu = nn.ReLU() | |||
| self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) | |||
| self.flatten = nn.Flatten() | |||
| self.reshape = P.Reshape() | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| @@ -54,7 +55,7 @@ class LeNet5(nn.Cell): | |||
| x = self.conv2(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.flatten(x) | |||
| x = self.reshape(x, (-1, 16*5*5)) | |||
| x = self.fc1(x) | |||
| x = self.relu(x) | |||
| x = self.fc2(x) | |||
examples/model_security/model_attacks/white_box/mnist_attack_cw.py → example/mnist_demo/mnist_attack_cw.py
View File
| @@ -11,8 +11,10 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| @@ -20,30 +22,38 @@ from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks import CarliniWagnerL2Attack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.carlini_wagner import CarliniWagnerL2Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'CW_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_carlini_wagner_attack(): | |||
| """ | |||
| CW-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -54,7 +64,7 @@ def test_carlini_wagner_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -105,6 +115,4 @@ def test_carlini_wagner_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_carlini_wagner_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_deepfool.py → example/mnist_demo/mnist_attack_deepfool.py
View File
| @@ -11,8 +11,10 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| @@ -20,30 +22,39 @@ from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks.deep_fool import DeepFool | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.deep_fool import DeepFool | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'DeepFool_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_deepfool_attack(): | |||
| """ | |||
| DeepFool-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -54,7 +65,7 @@ def test_deepfool_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -106,6 +117,4 @@ def test_deepfool_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_deepfool_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_fgsm.py → example/mnist_demo/mnist_attack_fgsm.py
View File
| @@ -11,42 +11,53 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import FastGradientSignMethod | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'FGSM_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_sign_method(): | |||
| """ | |||
| FGSM-Attack test for CPU device. | |||
| FGSM-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size) | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| @@ -55,7 +66,7 @@ def test_fast_gradient_sign_method(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -67,16 +78,15 @@ def test_fast_gradient_sign_method(): | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = FastGradientSignMethod(net, eps=0.3, loss_fn=loss) | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| true_labels, batch_size=32) | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| np.save('./adv_data', adv_data) | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| @@ -86,7 +96,7 @@ def test_fast_gradient_sign_method(): | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| @@ -106,6 +116,4 @@ def test_fast_gradient_sign_method(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_fast_gradient_sign_method() | |||
examples/model_security/model_attacks/black_box/mnist_attack_genetic.py → example/mnist_demo/mnist_attack_genetic.py
View File
| @@ -11,24 +11,29 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| from scipy.special import softmax | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks.black.black_model import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Genetic_Attack' | |||
| @@ -41,25 +46,27 @@ class ModelToBeAttacked(BlackModel): | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_genetic_attack_on_mnist(): | |||
| """ | |||
| Genetic-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -70,7 +77,7 @@ def test_genetic_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -87,11 +94,11 @@ def test_genetic_attack_on_mnist(): | |||
| # attacking | |||
| attack = GeneticAttack(model=model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.4, step_size=0.25, temp=0.1, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=True) | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| start_time = time.clock() | |||
| success_list, adv_data, query_list = attack.generate( | |||
| @@ -128,6 +135,4 @@ def test_genetic_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_genetic_attack_on_mnist() | |||
examples/model_security/model_attacks/black_box/mnist_attack_hsja.py → example/mnist_demo/mnist_attack_hsja.py
View File
| @@ -11,21 +11,27 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import HopSkipJumpAttack | |||
| from mindarmour.attacks.black.hop_skip_jump_attack import HopSkipJumpAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'HopSkipJumpAttack' | |||
| @@ -58,26 +64,31 @@ def random_target_labels(true_labels): | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for data_label, data in zip(data_labels, dataset): | |||
| if data_label == label: | |||
| res.append(data) | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_hsja_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -88,7 +99,7 @@ def test_hsja_mnist_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -115,9 +126,9 @@ def test_hsja_mnist_attack(): | |||
| target_images = create_target_images(test_images, predict_labels, | |||
| target_labels) | |||
| attack.set_target_images(target_images) | |||
| success_list, adv_data, _ = attack.generate(test_images, target_labels) | |||
| success_list, adv_data, query_list = attack.generate(test_images, target_labels) | |||
| else: | |||
| success_list, adv_data, _ = attack.generate(test_images, None) | |||
| success_list, adv_data, query_list = attack.generate(test_images, None) | |||
| adv_datas = [] | |||
| gts = [] | |||
| @@ -125,18 +136,15 @@ def test_hsja_mnist_attack(): | |||
| if success: | |||
| adv_datas.append(adv) | |||
| gts.append(gt) | |||
| if gts: | |||
| if len(gts) > 0: | |||
| adv_datas = np.concatenate(np.asarray(adv_datas), axis=0) | |||
| gts = np.asarray(gts) | |||
| pred_logits_adv = model.predict(adv_datas) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, gts)) | |||
| mis_rate = (1 - accuracy_adv)*(len(adv_datas) / len(success_list)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| mis_rate) | |||
| accuracy_adv) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_hsja_mnist_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_jsma.py → example/mnist_demo/mnist_attack_jsma.py
View File
| @@ -11,8 +11,10 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| @@ -20,30 +22,39 @@ from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks import JSMAAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.jsma import JSMAAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'JSMA_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -54,7 +65,7 @@ def test_jsma_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -68,8 +79,8 @@ def test_jsma_attack(): | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %g", accuracy) | |||
| @@ -110,6 +121,4 @@ def test_jsma_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_jsma_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_lbfgs.py → example/mnist_demo/mnist_attack_lbfgs.py
View File
| @@ -11,42 +11,52 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import LBFGS | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.lbfgs import LBFGS | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'LBFGS_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_lbfgs_attack(): | |||
| """ | |||
| LBFGS-Attack test for CPU device. | |||
| LBFGS-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| @@ -55,7 +65,7 @@ def test_lbfgs_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -67,7 +77,7 @@ def test_lbfgs_attack(): | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| @@ -75,13 +85,13 @@ def test_lbfgs_attack(): | |||
| is_targeted = True | |||
| if is_targeted: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)).astype(np.int32) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels.astype(np.int32) | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = LBFGS(net, is_targeted=is_targeted, loss_fn=loss) | |||
| targeted_labels = np.eye(10)[targeted_labels].astype(np.float32) | |||
| attack = LBFGS(net, is_targeted=is_targeted) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| targeted_labels, | |||
| @@ -96,11 +106,12 @@ def test_lbfgs_attack(): | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv, | |||
| targeted=is_targeted, | |||
| target_label=targeted_labels) | |||
| target_label=np.argmax(targeted_labels, | |||
| axis=1)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| @@ -118,6 +129,4 @@ def test_lbfgs_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_lbfgs_attack() | |||
examples/model_security/model_attacks/black_box/mnist_attack_nes.py → example/mnist_demo/mnist_attack_nes.py
View File
| @@ -11,21 +11,27 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import NES | |||
| from mindarmour.attacks.black.natural_evolutionary_strategy import NES | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'HopSkipJumpAttack' | |||
| @@ -67,26 +73,31 @@ def _pseudorandom_target(index, total_indices, true_class): | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for data_label, data in zip(data_labels, dataset): | |||
| if data_label == label: | |||
| res.append(data) | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nes_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -98,7 +109,7 @@ def test_nes_mnist_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -140,7 +151,7 @@ def test_nes_mnist_attack(): | |||
| target_image = create_target_images(test_images, true_labels, | |||
| target_class) | |||
| nes_instance.set_target_images(target_image) | |||
| tag, adv, queries = nes_instance.generate(np.array(initial_img), np.array(target_class)) | |||
| tag, adv, queries = nes_instance.generate(initial_img, target_class) | |||
| if tag[0]: | |||
| success += 1 | |||
| queries_num += queries[0] | |||
| @@ -154,6 +165,4 @@ def test_nes_mnist_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_nes_mnist_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_pgd.py → example/mnist_demo/mnist_attack_pgd.py
View File
| @@ -11,42 +11,53 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import ProjectedGradientDescent | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.iterative_gradient_method import ProjectedGradientDescent | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'PGD_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_projected_gradient_descent_method(): | |||
| """ | |||
| PGD-Attack test for CPU device. | |||
| PGD-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size) | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| @@ -55,7 +66,7 @@ def test_projected_gradient_descent_method(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -67,17 +78,16 @@ def test_projected_gradient_descent_method(): | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = ProjectedGradientDescent(net, eps=0.3, loss_fn=loss) | |||
| start_time = time.process_time() | |||
| attack = ProjectedGradientDescent(net, eps=0.3) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| true_labels, batch_size=32) | |||
| stop_time = time.process_time() | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| np.save('./adv_data', adv_data) | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| @@ -86,7 +96,7 @@ def test_projected_gradient_descent_method(): | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| @@ -106,6 +116,4 @@ def test_projected_gradient_descent_method(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_projected_gradient_descent_method() | |||
examples/model_security/model_attacks/black_box/mnist_attack_pointwise.py → example/mnist_demo/mnist_attack_pointwise.py
View File
| @@ -11,20 +11,26 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import PointWiseAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.pointwise_attack import PointWiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Pointwise_Attack' | |||
| @@ -46,18 +52,23 @@ class ModelToBeAttacked(BlackModel): | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pointwise_attack_on_mnist(): | |||
| """ | |||
| Salt-and-Pepper-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -68,7 +79,7 @@ def test_pointwise_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -88,8 +99,8 @@ def test_pointwise_attack_on_mnist(): | |||
| attack = PointWiseAttack(model=model, is_targeted=is_target) | |||
| if is_target: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels | |||
| @@ -110,7 +121,7 @@ def test_pointwise_attack_on_mnist(): | |||
| test_labels_onehot = np.eye(10)[true_labels] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| np.array(adv_preds), targeted=is_target, | |||
| adv_preds, targeted=is_target, | |||
| target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| @@ -124,6 +135,4 @@ def test_pointwise_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_pointwise_attack_on_mnist() | |||
examples/model_security/model_attacks/black_box/mnist_attack_pso.py → example/mnist_demo/mnist_attack_pso.py
View File
| @@ -11,24 +11,29 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'PSO_Attack' | |||
| @@ -41,25 +46,27 @@ class ModelToBeAttacked(BlackModel): | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack_on_mnist(): | |||
| """ | |||
| PSO-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -70,7 +77,7 @@ def test_pso_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -121,6 +128,4 @@ def test_pso_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_pso_attack_on_mnist() | |||
examples/model_security/model_attacks/black_box/mnist_attack_salt_and_pepper.py → example/mnist_demo/mnist_attack_salt_and_pepper.py
View File
| @@ -11,20 +11,26 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import SaltAndPepperNoiseAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.salt_and_pepper_attack import SaltAndPepperNoiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Salt_and_Pepper_Attack' | |||
| @@ -46,18 +52,23 @@ class ModelToBeAttacked(BlackModel): | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_salt_and_pepper_attack_on_mnist(): | |||
| """ | |||
| Salt-and-Pepper-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -68,7 +79,7 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -86,16 +97,19 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| # attacking | |||
| is_target = False | |||
| attack = SaltAndPepperNoiseAttack(model=model, is_targeted=is_target, sparse=True) | |||
| attack = SaltAndPepperNoiseAttack(model=model, | |||
| is_targeted=is_target, | |||
| sparse=True) | |||
| if is_target: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels | |||
| LOGGER.debug(TAG, 'input shape is: {}'.format(np.concatenate(test_images).shape)) | |||
| success_list, adv_data, query_list = attack.generate(np.concatenate(test_images), targeted_labels) | |||
| success_list, adv_data, query_list = attack.generate( | |||
| np.concatenate(test_images), targeted_labels) | |||
| success_list = np.arange(success_list.shape[0])[success_list] | |||
| LOGGER.info(TAG, 'success_list: %s', success_list) | |||
| LOGGER.info(TAG, 'average of query times is : %s', np.mean(query_list)) | |||
| @@ -105,22 +119,24 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| adv_preds.extend(pred_logits_adv) | |||
| adv_preds = np.array(adv_preds) | |||
| accuracy_adv = np.mean(np.equal(np.max(adv_preds, axis=1), true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", accuracy_adv) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| test_labels_onehot = np.eye(10)[true_labels] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| adv_preds, targeted=is_target, | |||
| target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original samples and adversarial samples are: %s', | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_salt_and_pepper_attack_on_mnist() | |||
+ 144
- 0
example/mnist_demo/mnist_defense_nad.py
View File
| @@ -0,0 +1,144 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """defense example using nad""" | |||
| import sys | |||
| import logging | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| from mindarmour.defenses import NaturalAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Nad_Example' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nad_method(): | |||
| """ | |||
| NAD-Defense test. | |||
| """ | |||
| # 1. load trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| opt = nn.Momentum(net.trainable_params(), 0.01, 0.09) | |||
| nad = NaturalAdversarialDefense(net, loss_fn=loss, optimizer=opt, | |||
| bounds=(0.0, 1.0), eps=0.3) | |||
| # 2. get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size, | |||
| sparse=False) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs) | |||
| labels = np.concatenate(labels) | |||
| # 3. get accuracy of test data on original model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = inputs.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = inputs[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of TEST data on original model is : %s', | |||
| np.mean(acc_list)) | |||
| # 4. get adv of test data | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| adv_data = attack.batch_generate(inputs, labels) | |||
| LOGGER.debug(TAG, 'adv_data.shape is : %s', adv_data.shape) | |||
| # 5. get accuracy of adv data on original model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = adv_data.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = adv_data[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of adv data on original model is : %s', | |||
| np.mean(acc_list)) | |||
| # 6. defense | |||
| net.set_train() | |||
| nad.batch_defense(inputs, labels, batch_size=32, epochs=10) | |||
| # 7. get accuracy of test data on defensed model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = inputs.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = inputs[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of TEST data on defensed model is : %s', | |||
| np.mean(acc_list)) | |||
| # 8. get accuracy of adv data on defensed model | |||
| acc_list = [] | |||
| batchs = adv_data.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = adv_data[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of adv data on defensed model is : %s', | |||
| np.mean(acc_list)) | |||
| if __name__ == '__main__': | |||
| LOGGER.set_level(logging.DEBUG) | |||
| test_nad_method() | |||
examples/model_security/model_defenses/mnist_evaluation.py → example/mnist_demo/mnist_evaluation.py
View File
| @@ -12,34 +12,37 @@ | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """evaluate example""" | |||
| import sys | |||
| import os | |||
| import time | |||
| import numpy as np | |||
| from scipy.special import softmax | |||
| from lenet5_net import LeNet5 | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.ops.operations import Add | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from scipy.special import softmax | |||
| from mindarmour.adv_robustness.attacks import FastGradientSignMethod | |||
| from mindarmour.adv_robustness.attacks import GeneticAttack | |||
| from mindarmour.adv_robustness.attacks.black.black_model import BlackModel | |||
| from mindarmour.adv_robustness.defenses import NaturalAdversarialDefense | |||
| from mindarmour.adv_robustness.detectors import SimilarityDetector | |||
| from mindarmour.adv_robustness.evaluations import BlackDefenseEvaluate | |||
| from mindarmour.adv_robustness.evaluations import DefenseEvaluate | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| from mindarmour.attacks import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.defenses import NaturalAdversarialDefense | |||
| from mindarmour.evaluations import BlackDefenseEvaluate | |||
| from mindarmour.evaluations import DefenseEvaluate | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Defense_Evaluate_Example' | |||
| @@ -58,7 +61,7 @@ class EncoderNet(Cell): | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = Add() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| @@ -99,8 +102,6 @@ class ModelToBeAttacked(BlackModel): | |||
| """ | |||
| predict function | |||
| """ | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| query_num = inputs.shape[0] | |||
| results = [] | |||
| if self._detector: | |||
| @@ -108,7 +109,7 @@ class ModelToBeAttacked(BlackModel): | |||
| query = np.expand_dims(inputs[i].astype(np.float32), axis=0) | |||
| result = self._network(Tensor(query)).asnumpy() | |||
| det_num = len(self._detector.get_detected_queries()) | |||
| self._detector.detect(np.array([query])) | |||
| self._detector.detect([query]) | |||
| new_det_num = len(self._detector.get_detected_queries()) | |||
| # If attack query detected, return random predict result | |||
| if new_det_num > det_num: | |||
| @@ -119,8 +120,6 @@ class ModelToBeAttacked(BlackModel): | |||
| self._detected_res.append(False) | |||
| results = np.concatenate(results) | |||
| else: | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| results = self._network(Tensor(inputs.astype(np.float32))).asnumpy() | |||
| return results | |||
| @@ -128,30 +127,33 @@ class ModelToBeAttacked(BlackModel): | |||
| return self._detected_res | |||
| def test_defense_evaluation(): | |||
| def test_black_defense(): | |||
| # load trained network | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| ckpt_path = os.path.abspath(os.path.join( | |||
| current_dir, '../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt')) | |||
| ckpt_name = os.path.abspath(os.path.join( | |||
| current_dir, './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt')) | |||
| # ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| wb_net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(wb_net, load_dict) | |||
| # get test data | |||
| data_list = "../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size, | |||
| sparse=False) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(output_numpy=True): | |||
| for data in ds_test.create_tuple_iterator(): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs).astype(np.float32) | |||
| labels = np.concatenate(labels).astype(np.int32) | |||
| labels = np.concatenate(labels).astype(np.float32) | |||
| labels_sparse = np.argmax(labels, axis=1) | |||
| target_label = np.random.randint(0, 10, size=labels.shape[0]) | |||
| for idx in range(labels.shape[0]): | |||
| while target_label[idx] == labels[idx]: | |||
| target_label = np.random.randint(0, 10, size=labels_sparse.shape[0]) | |||
| for idx in range(labels_sparse.shape[0]): | |||
| while target_label[idx] == labels_sparse[idx]: | |||
| target_label[idx] = np.random.randint(0, 10) | |||
| target_label = np.eye(10)[target_label].astype(np.float32) | |||
| @@ -165,23 +167,23 @@ def test_defense_evaluation(): | |||
| wb_model = ModelToBeAttacked(wb_net) | |||
| # gen white-box adversarial examples of test data | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| wb_attack = FastGradientSignMethod(wb_net, eps=0.3, loss_fn=loss) | |||
| wb_attack = FastGradientSignMethod(wb_net, eps=0.3) | |||
| wb_adv_sample = wb_attack.generate(attacked_sample, | |||
| attacked_true_label) | |||
| wb_raw_preds = softmax(wb_model.predict(wb_adv_sample), axis=1) | |||
| accuracy_test = np.mean( | |||
| np.equal(np.argmax(wb_model.predict(attacked_sample), axis=1), | |||
| attacked_true_label)) | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy before white-box attack is : %s", | |||
| accuracy_test) | |||
| accuracy_adv = np.mean(np.equal(np.argmax(wb_raw_preds, axis=1), | |||
| attacked_true_label)) | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy after white-box attack is : %s", | |||
| accuracy_adv) | |||
| # improve the robustness of model with white-box adversarial examples | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| opt = nn.Momentum(wb_net.trainable_params(), 0.01, 0.09) | |||
| nad = NaturalAdversarialDefense(wb_net, loss_fn=loss, optimizer=opt, | |||
| @@ -192,12 +194,12 @@ def test_defense_evaluation(): | |||
| wb_def_preds = wb_net(Tensor(wb_adv_sample)).asnumpy() | |||
| wb_def_preds = softmax(wb_def_preds, axis=1) | |||
| accuracy_def = np.mean(np.equal(np.argmax(wb_def_preds, axis=1), | |||
| attacked_true_label)) | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy after defense is : %s", accuracy_def) | |||
| # calculate defense evaluation metrics for defense against white-box attack | |||
| wb_def_evaluate = DefenseEvaluate(wb_raw_preds, wb_def_preds, | |||
| attacked_true_label) | |||
| np.argmax(attacked_true_label, axis=1)) | |||
| LOGGER.info(TAG, 'defense evaluation for white-box adversarial attack') | |||
| LOGGER.info(TAG, | |||
| 'classification accuracy variance (CAV) is : {:.2f}'.format( | |||
| @@ -227,15 +229,15 @@ def test_defense_evaluation(): | |||
| load_param_into_net(bb_net, load_dict) | |||
| bb_model = ModelToBeAttacked(bb_net, defense=False) | |||
| attack_rm = GeneticAttack(model=bb_model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.5, step_size=0.25, temp=0.1, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| attack_target_label = target_label[:attacked_size] | |||
| true_label = labels[:attacked_size + benign_size] | |||
| true_label = labels_sparse[:attacked_size + benign_size] | |||
| # evaluate robustness of original model | |||
| # gen black-box adversarial examples of test data | |||
| for idx in range(attacked_size): | |||
| raw_st = time.time() | |||
| _, raw_a, raw_qc = attack_rm.generate( | |||
| raw_sl, raw_a, raw_qc = attack_rm.generate( | |||
| np.expand_dims(attacked_sample[idx], axis=0), | |||
| np.expand_dims(attack_target_label[idx], axis=0)) | |||
| raw_t = time.time() - raw_st | |||
| @@ -265,11 +267,11 @@ def test_defense_evaluation(): | |||
| # attack defensed model | |||
| attack_dm = GeneticAttack(model=bb_def_model, pop_size=6, | |||
| mutation_rate=0.05, | |||
| per_bounds=0.5, step_size=0.25, temp=0.1, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| for idx in range(attacked_size): | |||
| def_st = time.time() | |||
| _, def_a, def_qc = attack_dm.generate( | |||
| def_sl, def_a, def_qc = attack_dm.generate( | |||
| np.expand_dims(attacked_sample[idx], axis=0), | |||
| np.expand_dims(attack_target_label[idx], axis=0)) | |||
| def_t = time.time() - def_st | |||
| @@ -321,8 +323,4 @@ def test_defense_evaluation(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| DEVICE = context.get_context("device_target") | |||
| if DEVICE in ("Ascend", "GPU"): | |||
| test_defense_evaluation() | |||
| test_black_defense() | |||
examples/model_security/model_defenses/mnist_similarity_detector.py → example/mnist_demo/mnist_similarity_detector.py
View File
| @@ -11,26 +11,31 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import Add | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.adv_robustness.detectors import SimilarityDetector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Similarity Detector test' | |||
| @@ -50,13 +55,7 @@ class ModelToBeAttacked(BlackModel): | |||
| """ | |||
| query_num = inputs.shape[0] | |||
| for i in range(query_num): | |||
| if len(inputs[i].shape) == 2: | |||
| temp = np.expand_dims(inputs[i], axis=0) | |||
| else: | |||
| temp = inputs[i] | |||
| self._queries.append(temp.astype(np.float32)) | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| self._queries.append(inputs[i].astype(np.float32)) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @@ -72,7 +71,7 @@ class EncoderNet(Cell): | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = Add() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| @@ -94,18 +93,23 @@ class EncoderNet(Cell): | |||
| return self._encode_dim | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_similarity_detector(): | |||
| """ | |||
| Similarity Detector test. | |||
| """ | |||
| # load trained network | |||
| ckpt_path = '../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get mnist data | |||
| data_list = "../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 1000 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| model = ModelToBeAttacked(net) | |||
| @@ -115,7 +119,7 @@ def test_similarity_detector(): | |||
| true_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -167,7 +171,7 @@ def test_similarity_detector(): | |||
| # test attack queries | |||
| detector.clear_buffer() | |||
| detector.detect(np.array(suspicious_queries)) | |||
| detector.detect(suspicious_queries) | |||
| LOGGER.info(TAG, 'Number of detected attack queries is : %s', | |||
| len(detector.get_detected_queries())) | |||
| LOGGER.info(TAG, 'The detected attack query indexes are : %s', | |||
| @@ -175,8 +179,4 @@ def test_similarity_detector(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| DEVICE = context.get_context("device_target") | |||
| if DEVICE in ("Ascend", "GPU"): | |||
| test_similarity_detector() | |||
| test_similarity_detector() | |||
examples/common/networks/lenet5/mnist_train.py → example/mnist_demo/mnist_train.py
View File
| @@ -11,55 +11,78 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| import os | |||
| import sys | |||
| import mindspore.nn as nn | |||
| from mindspore import context | |||
| from mindspore.nn.metrics import Accuracy | |||
| from mindspore.train import Model | |||
| from mindspore import context, Tensor | |||
| from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.train import Model | |||
| import mindspore.ops.operations as P | |||
| from mindspore.nn.metrics import Accuracy | |||
| from mindspore.ops import functional as F | |||
| from mindspore.common import dtype as mstype | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Lenet5_train' | |||
| TAG = "Lenet5_train" | |||
| class CrossEntropyLoss(nn.Cell): | |||
| """ | |||
| Define loss for network | |||
| """ | |||
| def __init__(self): | |||
| super(CrossEntropyLoss, self).__init__() | |||
| self.cross_entropy = P.SoftmaxCrossEntropyWithLogits() | |||
| self.mean = P.ReduceMean() | |||
| self.one_hot = P.OneHot() | |||
| self.on_value = Tensor(1.0, mstype.float32) | |||
| self.off_value = Tensor(0.0, mstype.float32) | |||
| def construct(self, logits, label): | |||
| label = self.one_hot(label, F.shape(logits)[1], self.on_value, self.off_value) | |||
| loss = self.cross_entropy(logits, label)[0] | |||
| loss = self.mean(loss, (-1,)) | |||
| return loss | |||
| def mnist_train(epoch_size, batch_size, lr, momentum): | |||
| mnist_path = "../../dataset/MNIST" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", | |||
| enable_mem_reuse=False) | |||
| lr = lr | |||
| momentum = momentum | |||
| epoch_size = epoch_size | |||
| mnist_path = "./MNIST_unzip/" | |||
| ds = generate_mnist_dataset(os.path.join(mnist_path, "train"), | |||
| batch_size=batch_size, repeat_size=1) | |||
| network = LeNet5() | |||
| net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean") | |||
| network.set_train() | |||
| net_loss = CrossEntropyLoss() | |||
| net_opt = nn.Momentum(network.trainable_params(), lr, momentum) | |||
| config_ck = CheckpointConfig(save_checkpoint_steps=1875, | |||
| keep_checkpoint_max=10) | |||
| ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", | |||
| directory="./trained_ckpt_file/", | |||
| config=config_ck) | |||
| config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10) | |||
| ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory='./trained_ckpt_file/', config=config_ck) | |||
| model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()}) | |||
| LOGGER.info(TAG, "============== Starting Training ==============") | |||
| model.train(epoch_size, ds, callbacks=[ckpoint_cb, LossMonitor()], | |||
| dataset_sink_mode=False) | |||
| model.train(epoch_size, ds, callbacks=[ckpoint_cb, LossMonitor()], dataset_sink_mode=False) # train | |||
| LOGGER.info(TAG, "============== Starting Testing ==============") | |||
| ckpt_file_name = "trained_ckpt_file/checkpoint_lenet-10_1875.ckpt" | |||
| param_dict = load_checkpoint(ckpt_file_name) | |||
| param_dict = load_checkpoint("trained_ckpt_file/checkpoint_lenet-10_1875.ckpt") | |||
| load_param_into_net(network, param_dict) | |||
| ds_eval = generate_mnist_dataset(os.path.join(mnist_path, "test"), | |||
| batch_size=batch_size) | |||
| acc = model.eval(ds_eval, dataset_sink_mode=False) | |||
| ds_eval = generate_mnist_dataset(os.path.join(mnist_path, "test"), batch_size=batch_size) | |||
| acc = model.eval(ds_eval) | |||
| LOGGER.info(TAG, "============== Accuracy: %s ==============", acc) | |||
| if __name__ == '__main__': | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| mnist_train(10, 32, 0.01, 0.9) | |||
| mnist_train(10, 32, 0.001, 0.9) | |||
+ 0
- 45
examples/README.md
View File
| @@ -1,45 +0,0 @@ | |||
| # Examples | |||
| ## Introduction | |||
| This package includes application demos for all developed tools of MindArmour. Through these demos, you will soon | |||
| master those tools of MindArmour. Let's Start! | |||
| ## Preparation | |||
| Most of those demos are implemented based on LeNet5 and MNIST dataset. As a preparation, we should download MNIST and | |||
| train a LeNet5 model first. | |||
| ### 1. download dataset | |||
| The MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples | |||
| . It is a subset of a larger set available from MNIST. The digits have been size-normalized and centered in a fixed-size image. | |||
| ```sh | |||
| cd examples/common/dataset | |||
| mkdir MNIST | |||
| cd MNIST | |||
| mkdir train | |||
| mkdir test | |||
| cd train | |||
| wget "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz" | |||
| wget "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz" | |||
| gzip train-images-idx3-ubyte.gz -d | |||
| gzip train-labels-idx1-ubyte.gz -d | |||
| cd ../test | |||
| wget "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz" | |||
| wget "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz" | |||
| gzip t10k-images-idx3-ubyte.gz -d | |||
| gzip t10k-labels-idx1-ubyte.gz -d | |||
| ``` | |||
| ### 2. trian LeNet5 model | |||
| After training the network, you will obtain a group of ckpt files. Those ckpt files save the trained model parameters | |||
| of LeNet5, which can be used in 'examples/ai_fuzzer' and 'examples/model_security'. | |||
| ```sh | |||
| cd examples/common/networks/lenet5 | |||
| python mnist_train.py | |||
| ``` | |||
+ 0
- 16
examples/__init__.py
View File
| @@ -1,16 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| This package includes real application examples for developed features of MindArmour. | |||
| """ | |||
+ 0
- 32
examples/ai_fuzzer/README.md
View File
| @@ -1,32 +0,0 @@ | |||
| # Application demos of model fuzzing | |||
| ## Introduction | |||
| The same as the traditional software fuzz testing, we can also design fuzz test for AI models. Compared to | |||
| branch coverage or line coverage of traditional software, some people propose the | |||
| concept of 'neuron coverage' based on the unique structure of deep neural network. We can use the neuron coverage | |||
| as a guide to search more metamorphic inputs to test our models. | |||
| ## 1. calculation of neuron coverage | |||
| There are five metrics proposed for evaluating the neuron coverage of a test:NC, Effective NC, KMNC, NBC and SNAC. | |||
| Usually we need to feed all the training dataset into the model first, and record the output range of all neurons | |||
| (however, in KMNC, NBC and SNAC, only the last layer of neurons are recorded in our method). In the testing phase, | |||
| we feed test samples into the model, and calculate those three metrics mentioned above according to those neurons' | |||
| output distribution. | |||
| ```sh | |||
| cd examples/ai_fuzzer/ | |||
| python lenet5_mnist_coverage.py | |||
| ``` | |||
| ## 2. fuzz test for AI model | |||
| We have provided several types of methods for manipulating metamorphic inputs: affine transformation, pixel | |||
| transformation and adversarial attacks. Usually we feed the original samples into the fuzz function as seeds, and | |||
| then metamorphic samples are generated through iterative manipulations. | |||
| ```sh | |||
| cd examples/ai_fuzzer/ | |||
| python lenet5_mnist_fuzzing.py | |||
| ``` | |||
+ 0
- 176
examples/ai_fuzzer/fuzz_testing_and_model_enhense.py
View File
| @@ -1,176 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| An example of fuzz testing and then enhance non-robustness model. | |||
| """ | |||
| import random | |||
| import numpy as np | |||
| import mindspore | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindarmour.adv_robustness.defenses import AdversarialDefense | |||
| from mindarmour.fuzz_testing import Fuzzer | |||
| from mindarmour.fuzz_testing import KMultisectionNeuronCoverage | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net_for_fuzzing import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Fuzz_testing and enhance model' | |||
| LOGGER.set_level('INFO') | |||
| def split_dataset(image, label, proportion): | |||
| """ | |||
| Split the generated fuzz data into train and test set. | |||
| """ | |||
| indices = np.arange(len(image)) | |||
| random.shuffle(indices) | |||
| train_length = int(len(image) * proportion) | |||
| train_image = [image[i] for i in indices[:train_length]] | |||
| train_label = [label[i] for i in indices[:train_length]] | |||
| test_image = [image[i] for i in indices[:train_length]] | |||
| test_label = [label[i] for i in indices[:train_length]] | |||
| return train_image, train_label, test_image, test_label | |||
| def example_lenet_mnist_fuzzing(): | |||
| """ | |||
| An example of fuzz testing and then enhance the non-robustness model. | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model = Model(net) | |||
| mutate_config = [ | |||
| {'method': 'GaussianBlur', | |||
| 'params': {'ksize': [1, 2, 3, 5], 'auto_param': [True, False]}}, | |||
| {'method': 'MotionBlur', | |||
| 'params': {'degree': [1, 2, 5], 'angle': [45, 10, 100, 140, 210, 270, 300], 'auto_param': [True]}}, | |||
| {'method': 'GradientBlur', | |||
| 'params': {'point': [[10, 10]], 'auto_param': [True]}}, | |||
| {'method': 'UniformNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'GaussianNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'SaltAndPepperNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'NaturalNoise', | |||
| 'params': {'ratio': [0.1], 'k_x_range': [(1, 3), (1, 5)], 'k_y_range': [(1, 5)], 'auto_param': [False, True]}}, | |||
| {'method': 'Contrast', | |||
| 'params': {'alpha': [0.5, 1, 1.5], 'beta': [-10, 0, 10], 'auto_param': [False, True]}}, | |||
| {'method': 'GradientLuminance', | |||
| 'params': {'color_start': [(0, 0, 0)], 'color_end': [(255, 255, 255)], 'start_point': [(10, 10)], | |||
| 'scope': [0.5], 'pattern': ['light'], 'bright_rate': [0.3], 'mode': ['circle'], | |||
| 'auto_param': [False, True]}}, | |||
| {'method': 'Translate', | |||
| 'params': {'x_bias': [0, 0.05, -0.05], 'y_bias': [0, -0.05, 0.05], 'auto_param': [False, True]}}, | |||
| {'method': 'Scale', | |||
| 'params': {'factor_x': [1, 0.9], 'factor_y': [1, 0.9], 'auto_param': [False, True]}}, | |||
| {'method': 'Shear', | |||
| 'params': {'factor': [0.2, 0.1], 'direction': ['horizontal', 'vertical'], 'auto_param': [False, True]}}, | |||
| {'method': 'Rotate', | |||
| 'params': {'angle': [20, 90], 'auto_param': [False, True]}}, | |||
| {'method': 'Perspective', | |||
| 'params': {'ori_pos': [[[0, 0], [0, 800], [800, 0], [800, 800]]], | |||
| 'dst_pos': [[[50, 0], [0, 800], [780, 0], [800, 800]]], 'auto_param': [False, True]}}, | |||
| {'method': 'Curve', | |||
| 'params': {'curves': [5], 'depth': [2], 'mode': ['vertical'], 'auto_param': [False, True]}}, | |||
| {'method': 'FGSM', | |||
| 'params': {'eps': [0.3, 0.2, 0.4], 'alpha': [0.1], 'bounds': [(0, 1)]}}] | |||
| # get training data | |||
| data_list = "../common/dataset/MNIST/train" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| train_images = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| train_images.append(images) | |||
| train_images = np.concatenate(train_images, axis=0) | |||
| segmented_num = 100 | |||
| # fuzz test with original test data | |||
| data_list = "../common/dataset/MNIST/test" | |||
| batch_size = batch_size | |||
| init_samples = 50 | |||
| max_iters = 500 | |||
| mutate_num_per_seed = 10 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size, num_samples=init_samples, sparse=False) | |||
| test_images = [] | |||
| test_labels = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| test_images.append(data[0].astype(np.float32)) | |||
| test_labels.append(data[1]) | |||
| test_images = np.concatenate(test_images, axis=0) | |||
| test_labels = np.concatenate(test_labels, axis=0) | |||
| coverage = KMultisectionNeuronCoverage(model, train_images, segmented_num=segmented_num, incremental=True) | |||
| kmnc = coverage.get_metrics(test_images[:100]) | |||
| print('kmnc: ', kmnc) | |||
| # make initial seeds | |||
| initial_seeds = [] | |||
| for img, label in zip(test_images, test_labels): | |||
| initial_seeds.append([img, label]) | |||
| model_fuzz_test = Fuzzer(model) | |||
| gen_samples, gt, _, _, metrics = model_fuzz_test.fuzzing(mutate_config, | |||
| initial_seeds, coverage, | |||
| evaluate=True, | |||
| max_iters=max_iters, | |||
| mutate_num_per_seed=mutate_num_per_seed) | |||
| if metrics: | |||
| for key in metrics: | |||
| LOGGER.info(TAG, key + ': %s', metrics[key]) | |||
| train_image, train_label, test_image, test_label = split_dataset(gen_samples, gt, 0.7) | |||
| # load model B and test it on the test set | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model_b = Model(net) | |||
| pred_b = model_b.predict(Tensor(test_image, dtype=mindspore.float32)).asnumpy() | |||
| acc_b = np.sum(np.argmax(pred_b, axis=1) == np.argmax(test_label, axis=1)) / len(test_label) | |||
| print('Accuracy of model B on test set is ', acc_b) | |||
| # enhense model robustness | |||
| lr = 0.001 | |||
| momentum = 0.9 | |||
| loss_fn = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| optimizer = Momentum(net.trainable_params(), lr, momentum) | |||
| adv_defense = AdversarialDefense(net, loss_fn, optimizer) | |||
| adv_defense.batch_defense(np.array(train_image).astype(np.float32), np.argmax(train_label, axis=1).astype(np.int32)) | |||
| preds_en = net(Tensor(test_image, dtype=mindspore.float32)).asnumpy() | |||
| acc_en = np.sum(np.argmax(preds_en, axis=1) == np.argmax(test_label, axis=1)) / len(test_label) | |||
| print('Accuracy of enhensed model on test set is ', acc_en) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| example_lenet_mnist_fuzzing() | |||
+ 0
- 89
examples/ai_fuzzer/lenet5_mnist_coverage.py
View File
| @@ -1,89 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import numpy as np | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.fuzz_testing.model_coverage_metrics import NeuronCoverage, TopKNeuronCoverage, NeuronBoundsCoverage,\ | |||
| SuperNeuronActivateCoverage, KMultisectionNeuronCoverage | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net_for_fuzzing import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Neuron coverage test' | |||
| LOGGER.set_level('INFO') | |||
| def test_lenet_mnist_coverage(): | |||
| # upload trained network | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model = Model(net) | |||
| # get training data | |||
| data_list = "../common/dataset/MNIST/train" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=True) | |||
| train_images = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| train_images.append(images) | |||
| train_images = np.concatenate(train_images, axis=0) | |||
| # fuzz test with original test data | |||
| # get test data | |||
| data_list = "../common/dataset/MNIST/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=True) | |||
| test_images = [] | |||
| test_labels = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| test_images = np.concatenate(test_images, axis=0) | |||
| # initialize fuzz test with training dataset | |||
| nc = NeuronCoverage(model, threshold=0.1) | |||
| nc_metric = nc.get_metrics(test_images) | |||
| tknc = TopKNeuronCoverage(model, top_k=3) | |||
| tknc_metrics = tknc.get_metrics(test_images) | |||
| snac = SuperNeuronActivateCoverage(model, train_images) | |||
| snac_metrics = snac.get_metrics(test_images) | |||
| nbc = NeuronBoundsCoverage(model, train_images) | |||
| nbc_metrics = nbc.get_metrics(test_images) | |||
| kmnc = KMultisectionNeuronCoverage(model, train_images, segmented_num=100) | |||
| kmnc_metrics = kmnc.get_metrics(test_images) | |||
| print('KMNC of this test is: ', kmnc_metrics) | |||
| print('NBC of this test is: ', nbc_metrics) | |||
| print('SNAC of this test is: ', snac_metrics) | |||
| print('NC of this test is: ', nc_metric) | |||
| print('TKNC of this test is: ', tknc_metrics) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_lenet_mnist_coverage() | |||
+ 0
- 131
examples/ai_fuzzer/lenet5_mnist_fuzzing.py
View File
| @@ -1,131 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import numpy as np | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore import load_checkpoint, load_param_into_net | |||
| from mindarmour.fuzz_testing import Fuzzer | |||
| from mindarmour.fuzz_testing import KMultisectionNeuronCoverage | |||
| from mindarmour.utils import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net_for_fuzzing import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Fuzz_test' | |||
| LOGGER.set_level('INFO') | |||
| def test_lenet_mnist_fuzzing(): | |||
| # upload trained network | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model = Model(net) | |||
| mutate_config = [ | |||
| {'method': 'GaussianBlur', | |||
| 'params': {'ksize': [1, 2, 3, 5], | |||
| 'auto_param': [True, False]}}, | |||
| {'method': 'MotionBlur', | |||
| 'params': {'degree': [1, 2, 5], 'angle': [45, 10, 100, 140, 210, 270, 300], 'auto_param': [True]}}, | |||
| {'method': 'GradientBlur', | |||
| 'params': {'point': [[10, 10]], 'auto_param': [True]}}, | |||
| {'method': 'UniformNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'GaussianNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'SaltAndPepperNoise', | |||
| 'params': {'factor': [0.1, 0.2, 0.3], 'auto_param': [False, True]}}, | |||
| {'method': 'NaturalNoise', | |||
| 'params': {'ratio': [0.1, 0.2, 0.3], 'k_x_range': [(1, 3), (1, 5)], 'k_y_range': [(1, 5)], | |||
| 'auto_param': [False, True]}}, | |||
| {'method': 'Contrast', | |||
| 'params': {'alpha': [0.5, 1, 1.5], 'beta': [-10, 0, 10], 'auto_param': [False, True]}}, | |||
| {'method': 'GradientLuminance', | |||
| 'params': {'color_start': [(0, 0, 0)], 'color_end': [(255, 255, 255)], 'start_point': [(10, 10)], | |||
| 'scope': [0.5], 'pattern': ['light'], 'bright_rate': [0.3], 'mode': ['circle'], | |||
| 'auto_param': [False, True]}}, | |||
| {'method': 'Translate', | |||
| 'params': {'x_bias': [0, 0.05, -0.05], 'y_bias': [0, -0.05, 0.05], 'auto_param': [False, True]}}, | |||
| {'method': 'Scale', | |||
| 'params': {'factor_x': [1, 0.9], 'factor_y': [1, 0.9], 'auto_param': [False, True]}}, | |||
| {'method': 'Shear', | |||
| 'params': {'factor': [0.2, 0.1], 'direction': ['horizontal', 'vertical'], 'auto_param': [False, True]}}, | |||
| {'method': 'Rotate', | |||
| 'params': {'angle': [20, 90], 'auto_param': [False, True]}}, | |||
| {'method': 'Perspective', | |||
| 'params': {'ori_pos': [[[0, 0], [0, 800], [800, 0], [800, 800]]], | |||
| 'dst_pos': [[[50, 0], [0, 800], [780, 0], [800, 800]]], 'auto_param': [False, True]}}, | |||
| {'method': 'Curve', | |||
| 'params': {'curves': [5], 'depth': [2], 'mode': ['vertical'], 'auto_param': [False, True]}}, | |||
| {'method': 'FGSM', | |||
| 'params': {'eps': [0.3, 0.2, 0.4], 'alpha': [0.1], 'bounds': [(0, 1)]}}, | |||
| {'method': 'PGD', | |||
| 'params': {'eps': [0.1, 0.2, 0.4], 'eps_iter': [0.05, 0.1], 'nb_iter': [1, 3]}}, | |||
| {'method': 'MDIIM', | |||
| 'params': {'eps': [0.1, 0.2, 0.4], 'prob': [0.5, 0.1], | |||
| 'norm_level': [1, 2, '1', '2', 'l1', 'l2', 'inf', 'np.inf', 'linf']}} | |||
| ] | |||
| # get training data | |||
| data_list = "../common/dataset/MNIST/train" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| train_images = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| train_images.append(images) | |||
| train_images = np.concatenate(train_images, axis=0) | |||
| # fuzz test with original test data | |||
| # get test data | |||
| data_list = "../common/dataset/MNIST/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| test_images = [] | |||
| test_labels = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| test_images = np.concatenate(test_images, axis=0) | |||
| test_labels = np.concatenate(test_labels, axis=0) | |||
| initial_seeds = [] | |||
| # make initial seeds | |||
| for img, label in zip(test_images, test_labels): | |||
| initial_seeds.append([img, label]) | |||
| coverage = KMultisectionNeuronCoverage(model, train_images, segmented_num=100, incremental=True) | |||
| kmnc = coverage.get_metrics(test_images[:100]) | |||
| print('KMNC of initial seeds is: ', kmnc) | |||
| initial_seeds = initial_seeds[:100] | |||
| model_fuzz_test = Fuzzer(model) | |||
| _, _, _, _, metrics = model_fuzz_test.fuzzing(mutate_config, | |||
| initial_seeds, coverage, | |||
| evaluate=True, | |||
| max_iters=10, | |||
| mutate_num_per_seed=20) | |||
| if metrics: | |||
| for key in metrics: | |||
| print(key + ': ', metrics[key]) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU"GPU, "" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_lenet_mnist_fuzzing() | |||
+ 0
- 188
examples/common/dataset/data_processing.py
View File
| @@ -1,188 +0,0 @@ | |||
| # Copyright 2021 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """data processing""" | |||
| import os | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.vision import Inter | |||
| import mindspore.common.dtype as mstype | |||
| def generate_mnist_dataset(data_path, batch_size=32, repeat_size=1, | |||
| num_samples=None, num_parallel_workers=1, sparse=True): | |||
| """ | |||
| create dataset for training or testing | |||
| """ | |||
| # define dataset | |||
| ds1 = ds.MnistDataset(data_path, num_samples=num_samples) | |||
| # define operation parameters | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), | |||
| interpolation=Inter.LINEAR) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| # apply map operations on images | |||
| if not sparse: | |||
| one_hot_enco = C.OneHot(10) | |||
| ds1 = ds1.map(input_columns="label", operations=one_hot_enco, | |||
| num_parallel_workers=num_parallel_workers) | |||
| type_cast_op = C.TypeCast(mstype.float32) | |||
| ds1 = ds1.map(input_columns="label", operations=type_cast_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=resize_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=rescale_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=hwc2chw_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| ds1 = ds1.shuffle(buffer_size=buffer_size) | |||
| ds1 = ds1.batch(batch_size, drop_remainder=True) | |||
| ds1 = ds1.repeat(repeat_size) | |||
| return ds1 | |||
| def vgg_create_dataset100(data_home, image_size, batch_size, rank_id=0, rank_size=1, repeat_num=1, | |||
| training=True, num_samples=None, shuffle=True): | |||
| """Data operations.""" | |||
| ds.config.set_seed(1) | |||
| data_dir = os.path.join(data_home, "train") | |||
| if not training: | |||
| data_dir = os.path.join(data_home, "test") | |||
| if num_samples is not None: | |||
| data_set = ds.Cifar100Dataset(data_dir, num_shards=rank_size, shard_id=rank_id, | |||
| num_samples=num_samples, shuffle=shuffle) | |||
| else: | |||
| data_set = ds.Cifar100Dataset(data_dir, num_shards=rank_size, shard_id=rank_id) | |||
| input_columns = ["fine_label"] | |||
| output_columns = ["label"] | |||
| data_set = data_set.rename(input_columns=input_columns, output_columns=output_columns) | |||
| data_set = data_set.project(["image", "label"]) | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| random_crop_op = CV.RandomCrop((32, 32), (4, 4, 4, 4)) # padding_mode default CONSTANT | |||
| random_horizontal_op = CV.RandomHorizontalFlip() | |||
| resize_op = CV.Resize(image_size) # interpolation default BILINEAR | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| normalize_op = CV.Normalize((0.4465, 0.4822, 0.4914), (0.2010, 0.1994, 0.2023)) | |||
| changeswap_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| c_trans = [] | |||
| if training: | |||
| c_trans = [random_crop_op, random_horizontal_op] | |||
| c_trans += [resize_op, rescale_op, normalize_op, | |||
| changeswap_op] | |||
| # apply map operations on images | |||
| data_set = data_set.map(input_columns="label", operations=type_cast_op) | |||
| data_set = data_set.map(input_columns="image", operations=c_trans) | |||
| # apply shuffle operations | |||
| data_set = data_set.shuffle(buffer_size=1000) | |||
| # apply batch operations | |||
| data_set = data_set.batch(batch_size=batch_size, drop_remainder=True) | |||
| # apply repeat operations | |||
| data_set = data_set.repeat(repeat_num) | |||
| return data_set | |||
| def create_dataset_imagenet(path, batch_size=32, repeat_size=20, status="train", target="GPU"): | |||
| image_ds = ds.ImageFolderDataset(path, decode=True) | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| cfg = {'num_classes': 10, | |||
| 'learning_rate': 0.002, | |||
| 'momentum': 0.9, | |||
| 'epoch_size': 30, | |||
| 'batch_size': 32, | |||
| 'buffer_size': 1000, | |||
| 'image_height': 224, | |||
| 'image_width': 224, | |||
| 'save_checkpoint_steps': 1562, | |||
| 'keep_checkpoint_max': 10} | |||
| resize_op = CV.Resize((cfg['image_height'], cfg['image_width'])) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| normalize_op = CV.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) | |||
| random_crop_op = CV.RandomCrop([32, 32], [4, 4, 4, 4]) | |||
| random_horizontal_op = CV.RandomHorizontalFlip() | |||
| channel_swap_op = CV.HWC2CHW() | |||
| typecast_op = C.TypeCast(mstype.int32) | |||
| image_ds = image_ds.map(input_columns="label", operations=typecast_op, num_parallel_workers=6) | |||
| image_ds = image_ds.map(input_columns="image", operations=random_crop_op, num_parallel_workers=6) | |||
| image_ds = image_ds.map(input_columns="image", operations=random_horizontal_op, num_parallel_workers=6) | |||
| image_ds = image_ds.map(input_columns="image", operations=resize_op, num_parallel_workers=6) | |||
| image_ds = image_ds.map(input_columns="image", operations=rescale_op, num_parallel_workers=6) | |||
| image_ds = image_ds.map(input_columns="image", operations=normalize_op, num_parallel_workers=6) | |||
| image_ds = image_ds.map(input_columns="image", operations=channel_swap_op, num_parallel_workers=6) | |||
| image_ds = image_ds.shuffle(buffer_size=cfg['buffer_size']) | |||
| image_ds = image_ds.repeat(repeat_size) | |||
| return image_ds | |||
| def create_dataset_cifar(data_path, image_height, image_width, repeat_num=1, training=True): | |||
| """ | |||
| create data for next use such as training or infering | |||
| """ | |||
| cifar_ds = ds.Cifar10Dataset(data_path) | |||
| resize_height = image_height # 224 | |||
| resize_width = image_width # 224 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| batch_size = 32 | |||
| # define map operations | |||
| random_crop_op = CV.RandomCrop((32, 32), (4, 4, 4, 4)) # padding_mode default CONSTANT | |||
| random_horizontal_op = CV.RandomHorizontalFlip() | |||
| resize_op = CV.Resize((resize_height, resize_width)) # interpolation default BILINEAR | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| normalize_op = CV.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) | |||
| changeswap_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| c_trans = [] | |||
| if training: | |||
| c_trans = [random_crop_op, random_horizontal_op] | |||
| c_trans += [resize_op, rescale_op, normalize_op, | |||
| changeswap_op] | |||
| # apply map operations on images | |||
| cifar_ds = cifar_ds.map(operations=type_cast_op, input_columns="label") | |||
| cifar_ds = cifar_ds.map(operations=c_trans, input_columns="image") | |||
| # apply shuffle operations | |||
| cifar_ds = cifar_ds.shuffle(buffer_size=10) | |||
| # apply batch operations | |||
| cifar_ds = cifar_ds.batch(batch_size=batch_size, drop_remainder=True) | |||
| # apply repeat operations | |||
| cifar_ds = cifar_ds.repeat(repeat_num) | |||
| return cifar_ds | |||
+ 0
- 0
examples/common/networks/__init__.py
View File
+ 0
- 0
examples/common/networks/lenet5/__init__.py
View File
+ 0
- 98
examples/common/networks/lenet5/lenet5_net_for_fuzzing.py
View File
| @@ -1,98 +0,0 @@ | |||
| # Copyright 2021 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| lenet network with summary | |||
| """ | |||
| from mindspore import nn | |||
| from mindspore.common.initializer import TruncatedNormal | |||
| from mindspore.ops import TensorSummary | |||
| def conv(in_channels, out_channels, kernel_size, stride=1, padding=0): | |||
| """Wrap conv.""" | |||
| weight = weight_variable() | |||
| return nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, | |||
| weight_init=weight, has_bias=False, pad_mode="valid") | |||
| def fc_with_initialize(input_channels, out_channels): | |||
| """Wrap initialize method of full connection layer.""" | |||
| weight = weight_variable() | |||
| bias = weight_variable() | |||
| return nn.Dense(input_channels, out_channels, weight, bias) | |||
| def weight_variable(): | |||
| """Wrap initialize variable.""" | |||
| return TruncatedNormal(0.05) | |||
| class LeNet5(nn.Cell): | |||
| """ | |||
| Lenet network | |||
| """ | |||
| def __init__(self): | |||
| super(LeNet5, self).__init__() | |||
| self.conv1 = conv(1, 6, 5) | |||
| self.conv2 = conv(6, 16, 5) | |||
| self.fc1 = fc_with_initialize(16*5*5, 120) | |||
| self.fc2 = fc_with_initialize(120, 84) | |||
| self.fc3 = fc_with_initialize(84, 10) | |||
| self.relu = nn.ReLU() | |||
| self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) | |||
| self.flatten = nn.Flatten() | |||
| self.summary = TensorSummary() | |||
| def construct(self, x): | |||
| """ | |||
| construct the network architecture | |||
| Returns: | |||
| x (tensor): network output | |||
| """ | |||
| x = self.conv1(x) | |||
| self.summary('1', x) | |||
| x = self.relu(x) | |||
| self.summary('2', x) | |||
| x = self.max_pool2d(x) | |||
| self.summary('3', x) | |||
| x = self.conv2(x) | |||
| self.summary('4', x) | |||
| x = self.relu(x) | |||
| self.summary('5', x) | |||
| x = self.max_pool2d(x) | |||
| self.summary('6', x) | |||
| x = self.flatten(x) | |||
| self.summary('7', x) | |||
| x = self.fc1(x) | |||
| self.summary('8', x) | |||
| x = self.relu(x) | |||
| self.summary('9', x) | |||
| x = self.fc2(x) | |||
| self.summary('10', x) | |||
| x = self.relu(x) | |||
| self.summary('11', x) | |||
| x = self.fc3(x) | |||
| self.summary('output', x) | |||
| return x | |||
+ 0
- 0
examples/common/networks/resnet/__init__.py
View File
+ 0
- 401
examples/common/networks/resnet/resnet.py
View File
| @@ -1,401 +0,0 @@ | |||
| # Copyright 2021 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import functional as F | |||
| from mindspore.common.tensor import Tensor | |||
| from scipy.stats import truncnorm | |||
| from mindspore.ops import TensorSummary | |||
| def _conv_variance_scaling_initializer(in_channel, out_channel, kernel_size): | |||
| fan_in = in_channel * kernel_size * kernel_size | |||
| scale = 1.0 | |||
| scale /= max(1., fan_in) | |||
| stddev = (scale ** 0.5) / .87962566103423978 | |||
| mu, sigma = 0, stddev | |||
| weight = truncnorm(-2, 2, loc=mu, scale=sigma).rvs(out_channel * in_channel * kernel_size*kernel_size) | |||
| weight = np.reshape(weight, (out_channel, in_channel, kernel_size, kernel_size)) | |||
| return Tensor(weight, dtype=mstype.float32) | |||
| def _weight_variable(shape, factor=0.01): | |||
| init_value = np.random.randn(*shape).astype(np.float32) * factor | |||
| return Tensor(init_value) | |||
| def _conv3x3(in_channel, out_channel, stride=1, use_se=False): | |||
| if use_se: | |||
| weight = _conv_variance_scaling_initializer(in_channel, out_channel, kernel_size=3) | |||
| else: | |||
| weight_shape = (out_channel, in_channel, 3, 3) | |||
| weight = _weight_variable(weight_shape) | |||
| return nn.Conv2d(in_channel, out_channel, | |||
| kernel_size=3, stride=stride, padding=0, pad_mode='same', weight_init=weight) | |||
| def _conv1x1(in_channel, out_channel, stride=1, use_se=False): | |||
| if use_se: | |||
| weight = _conv_variance_scaling_initializer(in_channel, out_channel, kernel_size=1) | |||
| else: | |||
| weight_shape = (out_channel, in_channel, 1, 1) | |||
| weight = _weight_variable(weight_shape) | |||
| return nn.Conv2d(in_channel, out_channel, | |||
| kernel_size=1, stride=stride, padding=0, pad_mode='same', weight_init=weight) | |||
| def _conv7x7(in_channel, out_channel, stride=1, use_se=False): | |||
| if use_se: | |||
| weight = _conv_variance_scaling_initializer(in_channel, out_channel, kernel_size=7) | |||
| else: | |||
| weight_shape = (out_channel, in_channel, 7, 7) | |||
| weight = _weight_variable(weight_shape) | |||
| return nn.Conv2d(in_channel, out_channel, | |||
| kernel_size=7, stride=stride, padding=0, pad_mode='same', weight_init=weight) | |||
| def _bn(channel): | |||
| return nn.BatchNorm2d(channel, eps=1e-4, momentum=0.9, | |||
| gamma_init=1, beta_init=0, moving_mean_init=0, moving_var_init=1) | |||
| def _bn_last(channel): | |||
| return nn.BatchNorm2d(channel, eps=1e-4, momentum=0.9, | |||
| gamma_init=0, beta_init=0, moving_mean_init=0, moving_var_init=1) | |||
| def _fc(in_channel, out_channel, use_se=False): | |||
| if use_se: | |||
| weight = np.random.normal(loc=0, scale=0.01, size=out_channel*in_channel) | |||
| weight = Tensor(np.reshape(weight, (out_channel, in_channel)), dtype=mstype.float32) | |||
| else: | |||
| weight_shape = (out_channel, in_channel) | |||
| weight = _weight_variable(weight_shape) | |||
| return nn.Dense(in_channel, out_channel, has_bias=True, weight_init=weight, bias_init=0) | |||
| class ResidualBlock(nn.Cell): | |||
| """ | |||
| ResNet V1 residual block definition. | |||
| Args: | |||
| in_channel (int): Input channel. | |||
| out_channel (int): Output channel. | |||
| stride (int): Stride size for the first convolutional layer. Default: 1. | |||
| use_se (bool): enable SE-ResNet50 net. Default: False. | |||
| se_block (bool): use se block in SE-ResNet50 net. Default: False. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| Examples: | |||
| >>> ResidualBlock(3, 256, stride=2) | |||
| """ | |||
| expansion = 4 | |||
| def __init__(self, | |||
| in_channel, | |||
| out_channel, | |||
| stride=1, | |||
| use_se=False, se_block=False): | |||
| super(ResidualBlock, self).__init__() | |||
| self.summary = TensorSummary() | |||
| self.stride = stride | |||
| self.use_se = use_se | |||
| self.se_block = se_block | |||
| channel = out_channel // self.expansion | |||
| self.conv1 = _conv1x1(in_channel, channel, stride=1, use_se=self.use_se) | |||
| self.bn1 = _bn(channel) | |||
| if self.use_se and self.stride != 1: | |||
| self.e2 = nn.SequentialCell([_conv3x3(channel, channel, stride=1, use_se=True), _bn(channel), | |||
| nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='same')]) | |||
| else: | |||
| self.conv2 = _conv3x3(channel, channel, stride=stride, use_se=self.use_se) | |||
| self.bn2 = _bn(channel) | |||
| self.conv3 = _conv1x1(channel, out_channel, stride=1, use_se=self.use_se) | |||
| self.bn3 = _bn_last(out_channel) | |||
| if self.se_block: | |||
| self.se_global_pool = P.ReduceMean(keep_dims=False) | |||
| self.se_dense_0 = _fc(out_channel, int(out_channel/4), use_se=self.use_se) | |||
| self.se_dense_1 = _fc(int(out_channel/4), out_channel, use_se=self.use_se) | |||
| self.se_sigmoid = nn.Sigmoid() | |||
| self.se_mul = P.Mul() | |||
| self.relu = nn.ReLU() | |||
| self.down_sample = False | |||
| if stride != 1 or in_channel != out_channel: | |||
| self.down_sample = True | |||
| self.down_sample_layer = None | |||
| if self.down_sample: | |||
| if self.use_se: | |||
| if stride == 1: | |||
| self.down_sample_layer = nn.SequentialCell([_conv1x1(in_channel, out_channel, | |||
| stride, use_se=self.use_se), _bn(out_channel)]) | |||
| else: | |||
| self.down_sample_layer = nn.SequentialCell([nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='same'), | |||
| _conv1x1(in_channel, out_channel, 1, | |||
| use_se=self.use_se), _bn(out_channel)]) | |||
| else: | |||
| self.down_sample_layer = nn.SequentialCell([_conv1x1(in_channel, out_channel, stride, | |||
| use_se=self.use_se), _bn(out_channel)]) | |||
| self.add = P.TensorAdd() | |||
| def construct(self, x): | |||
| identity = x | |||
| out = self.conv1(x) | |||
| out = self.bn1(out) | |||
| out = self.relu(out) | |||
| if self.use_se and self.stride != 1: | |||
| out = self.e2(out) | |||
| else: | |||
| out = self.conv2(out) | |||
| out = self.bn2(out) | |||
| out = self.relu(out) | |||
| out = self.conv3(out) | |||
| out = self.bn3(out) | |||
| if self.se_block: | |||
| out_se = out | |||
| out = self.se_global_pool(out, (2, 3)) | |||
| out = self.se_dense_0(out) | |||
| out = self.relu(out) | |||
| out = self.se_dense_1(out) | |||
| out = self.se_sigmoid(out) | |||
| out = F.reshape(out, F.shape(out) + (1, 1)) | |||
| out = self.se_mul(out, out_se) | |||
| if self.down_sample: | |||
| identity = self.down_sample_layer(identity) | |||
| out = self.add(out, identity) | |||
| out = self.relu(out) | |||
| return out | |||
| class ResNet(nn.Cell): | |||
| """ | |||
| ResNet architecture. | |||
| Args: | |||
| block (Cell): Block for network. | |||
| layer_nums (list): Numbers of block in different layers. | |||
| in_channels (list): Input channel in each layer. | |||
| out_channels (list): Output channel in each layer. | |||
| strides (list): Stride size in each layer. | |||
| num_classes (int): The number of classes that the training images are belonging to. | |||
| use_se (bool): enable SE-ResNet50 net. Default: False. | |||
| se_block (bool): use se block in SE-ResNet50 net in layer 3 and layer 4. Default: False. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| Examples: | |||
| >>> ResNet(ResidualBlock, | |||
| >>> [3, 4, 6, 3], | |||
| >>> [64, 256, 512, 1024], | |||
| >>> [256, 512, 1024, 2048], | |||
| >>> [1, 2, 2, 2], | |||
| >>> 10) | |||
| """ | |||
| def __init__(self, | |||
| block, | |||
| layer_nums, | |||
| in_channels, | |||
| out_channels, | |||
| strides, | |||
| num_classes, | |||
| use_se=False): | |||
| super(ResNet, self).__init__() | |||
| if not len(layer_nums) == len(in_channels) == len(out_channels) == 4: | |||
| raise ValueError("the length of layer_num, in_channels, out_channels list must be 4!") | |||
| self.use_se = use_se | |||
| self.se_block = False | |||
| if self.use_se: | |||
| self.se_block = True | |||
| if self.use_se: | |||
| self.conv1_0 = _conv3x3(3, 32, stride=2, use_se=self.use_se) | |||
| self.bn1_0 = _bn(32) | |||
| self.conv1_1 = _conv3x3(32, 32, stride=1, use_se=self.use_se) | |||
| self.bn1_1 = _bn(32) | |||
| self.conv1_2 = _conv3x3(32, 64, stride=1, use_se=self.use_se) | |||
| else: | |||
| self.conv1 = _conv7x7(3, 64, stride=2) | |||
| self.bn1 = _bn(64) | |||
| self.relu = P.ReLU() | |||
| self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same") | |||
| self.layer1 = self._make_layer(block, | |||
| layer_nums[0], | |||
| in_channel=in_channels[0], | |||
| out_channel=out_channels[0], | |||
| stride=strides[0], | |||
| use_se=self.use_se) | |||
| self.layer2 = self._make_layer(block, | |||
| layer_nums[1], | |||
| in_channel=in_channels[1], | |||
| out_channel=out_channels[1], | |||
| stride=strides[1], | |||
| use_se=self.use_se) | |||
| self.layer3 = self._make_layer(block, | |||
| layer_nums[2], | |||
| in_channel=in_channels[2], | |||
| out_channel=out_channels[2], | |||
| stride=strides[2], | |||
| use_se=self.use_se, | |||
| se_block=self.se_block) | |||
| self.layer4 = self._make_layer(block, | |||
| layer_nums[3], | |||
| in_channel=in_channels[3], | |||
| out_channel=out_channels[3], | |||
| stride=strides[3], | |||
| use_se=self.use_se, | |||
| se_block=self.se_block) | |||
| self.mean = P.ReduceMean(keep_dims=True) | |||
| self.flatten = nn.Flatten() | |||
| self.end_point = _fc(out_channels[3], num_classes, use_se=self.use_se) | |||
| self.summary = TensorSummary() | |||
| def _make_layer(self, block, layer_num, in_channel, out_channel, stride, use_se=False, se_block=False): | |||
| """ | |||
| Make stage network of ResNet. | |||
| Args: | |||
| block (Cell): Resnet block. | |||
| layer_num (int): Layer number. | |||
| in_channel (int): Input channel. | |||
| out_channel (int): Output channel. | |||
| stride (int): Stride size for the first convolutional layer. | |||
| se_block (bool): use se block in SE-ResNet50 net. Default: False. | |||
| Returns: | |||
| SequentialCell, the output layer. | |||
| Examples: | |||
| >>> _make_layer(ResidualBlock, 3, 128, 256, 2) | |||
| """ | |||
| layers = [] | |||
| resnet_block = block(in_channel, out_channel, stride=stride, use_se=use_se) | |||
| layers.append(resnet_block) | |||
| if se_block: | |||
| for _ in range(1, layer_num - 1): | |||
| resnet_block = block(out_channel, out_channel, stride=1, use_se=use_se) | |||
| layers.append(resnet_block) | |||
| resnet_block = block(out_channel, out_channel, stride=1, use_se=use_se, se_block=se_block) | |||
| layers.append(resnet_block) | |||
| else: | |||
| for _ in range(1, layer_num): | |||
| resnet_block = block(out_channel, out_channel, stride=1, use_se=use_se) | |||
| layers.append(resnet_block) | |||
| return nn.SequentialCell(layers) | |||
| def construct(self, x): | |||
| if self.use_se: | |||
| x = self.conv1_0(x) | |||
| x = self.bn1_0(x) | |||
| x = self.relu(x) | |||
| x = self.conv1_1(x) | |||
| x = self.bn1_1(x) | |||
| x = self.relu(x) | |||
| x = self.conv1_2(x) | |||
| else: | |||
| x = self.conv1(x) | |||
| x = self.bn1(x) | |||
| x = self.relu(x) | |||
| c1 = self.maxpool(x) | |||
| c2 = self.layer1(c1) | |||
| c3 = self.layer2(c2) | |||
| c4 = self.layer3(c3) | |||
| c5 = self.layer4(c4) | |||
| out = self.mean(c5, (2, 3)) | |||
| out = self.flatten(out) | |||
| self.summary('1', out) | |||
| out = self.end_point(out) | |||
| if self.training: | |||
| return out | |||
| self.summary('output', out) | |||
| return out | |||
| def resnet50(class_num=10): | |||
| """ | |||
| Get ResNet50 neural network. | |||
| Args: | |||
| class_num (int): Class number. | |||
| Returns: | |||
| Cell, cell instance of ResNet50 neural network. | |||
| Examples: | |||
| >>> net = resnet50(10) | |||
| """ | |||
| return ResNet(ResidualBlock, | |||
| [3, 4, 6, 3], | |||
| [64, 256, 512, 1024], | |||
| [256, 512, 1024, 2048], | |||
| [1, 2, 2, 2], | |||
| class_num) | |||
| def se_resnet50(class_num=1001): | |||
| """ | |||
| Get SE-ResNet50 neural network. | |||
| Args: | |||
| class_num (int): Class number. | |||
| Returns: | |||
| Cell, cell instance of SE-ResNet50 neural network. | |||
| Examples: | |||
| >>> net = se-resnet50(1001) | |||
| """ | |||
| return ResNet(ResidualBlock, | |||
| [3, 4, 6, 3], | |||
| [64, 256, 512, 1024], | |||
| [256, 512, 1024, 2048], | |||
| [1, 2, 2, 2], | |||
| class_num, | |||
| use_se=True) | |||
| def resnet101(class_num=1001): | |||
| """ | |||
| Get ResNet101 neural network. | |||
| Args: | |||
| class_num (int): Class number. | |||
| Returns: | |||
| Cell, cell instance of ResNet101 neural network. | |||
| Examples: | |||
| >>> net = resnet101(1001) | |||
| """ | |||
| return ResNet(ResidualBlock, | |||
| [3, 4, 23, 3], | |||
| [64, 256, 512, 1024], | |||
| [256, 512, 1024, 2048], | |||
| [1, 2, 2, 2], | |||
| class_num) | |||
+ 0
- 14
examples/common/networks/vgg/__init__.py
View File
| @@ -1,14 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the License); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # httpwww.apache.orglicensesLICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an AS IS BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
+ 0
- 45
examples/common/networks/vgg/config.py
View File
| @@ -1,45 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| network config setting, will be used in train.py and eval.py | |||
| """ | |||
| from easydict import EasyDict as edict | |||
| # config for vgg16, cifar100 | |||
| cifar_cfg = edict({ | |||
| "num_classes": 100, | |||
| "lr": 0.01, | |||
| "lr_init": 0.01, | |||
| "lr_max": 0.1, | |||
| "lr_epochs": '30,60,90,120', | |||
| "lr_scheduler": "step", | |||
| "warmup_epochs": 5, | |||
| "batch_size": 64, | |||
| "max_epoch": 100, | |||
| "momentum": 0.9, | |||
| "weight_decay": 5e-4, | |||
| "loss_scale": 1.0, | |||
| "label_smooth": 0, | |||
| "label_smooth_factor": 0, | |||
| "buffer_size": 10, | |||
| "image_size": '224,224', | |||
| "pad_mode": 'same', | |||
| "padding": 0, | |||
| "has_bias": False, | |||
| "batch_norm": True, | |||
| "keep_checkpoint_max": 10, | |||
| "initialize_mode": "XavierUniform", | |||
| "has_dropout": False | |||
| }) | |||
+ 0
- 39
examples/common/networks/vgg/crossentropy.py
View File
| @@ -1,39 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """define loss function for network""" | |||
| from mindspore.nn.loss.loss import _Loss | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import functional as F | |||
| from mindspore import Tensor | |||
| from mindspore.common import dtype as mstype | |||
| import mindspore.nn as nn | |||
| class CrossEntropy(_Loss): | |||
| """the redefined loss function with SoftmaxCrossEntropyWithLogits""" | |||
| def __init__(self, smooth_factor=0., num_classes=1001): | |||
| super(CrossEntropy, self).__init__() | |||
| self.onehot = P.OneHot() | |||
| self.on_value = Tensor(1.0 - smooth_factor, mstype.float32) | |||
| self.off_value = Tensor(1.0 * smooth_factor / (num_classes - 1), mstype.float32) | |||
| self.ce = nn.SoftmaxCrossEntropyWithLogits() | |||
| self.mean = P.ReduceMean(False) | |||
| def construct(self, logit, label): | |||
| one_hot_label = self.onehot(label, F.shape(logit)[1], self.on_value, self.off_value) | |||
| loss = self.ce(logit, one_hot_label) | |||
| loss = self.mean(loss, 0) | |||
| return loss | |||
+ 0
- 23
examples/common/networks/vgg/linear_warmup.py
View File
| @@ -1,23 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| linear warm up learning rate. | |||
| """ | |||
| def linear_warmup_lr(current_step, warmup_steps, base_lr, init_lr): | |||
| lr_inc = (float(base_lr) - float(init_lr)) / float(warmup_steps) | |||
| lr = float(init_lr) + lr_inc*current_step | |||
| return lr | |||
+ 0
- 0
examples/common/networks/vgg/utils/__init__.py
View File
+ 0
- 36
examples/common/networks/vgg/utils/util.py
View File
| @@ -1,36 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Util class or function.""" | |||
| def get_param_groups(network): | |||
| """Param groups for optimizer.""" | |||
| decay_params = [] | |||
| no_decay_params = [] | |||
| for x in network.trainable_params(): | |||
| parameter_name = x.name | |||
| if parameter_name.endswith('.bias'): | |||
| # all bias not using weight decay | |||
| no_decay_params.append(x) | |||
| elif parameter_name.endswith('.gamma'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| no_decay_params.append(x) | |||
| elif parameter_name.endswith('.beta'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| no_decay_params.append(x) | |||
| else: | |||
| decay_params.append(x) | |||
| return [{'params': no_decay_params, 'weight_decay': 0.0}, {'params': decay_params}] | |||
+ 0
- 219
examples/common/networks/vgg/utils/var_init.py
View File
| @@ -1,219 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| Initialize. | |||
| """ | |||
| import math | |||
| from functools import reduce | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.common import initializer as init | |||
| def _calculate_gain(nonlinearity, param=None): | |||
| r""" | |||
| Return the recommended gain value for the given nonlinearity function. | |||
| The values are as follows: | |||
| ================= ==================================================== | |||
| nonlinearity gain | |||
| ================= ==================================================== | |||
| Linear / Identity :math:`1` | |||
| Conv{1,2,3}D :math:`1` | |||
| Sigmoid :math:`1` | |||
| Tanh :math:`\frac{5}{3}` | |||
| ReLU :math:`\sqrt{2}` | |||
| Leaky Relu :math:`\sqrt{\frac{2}{1 + \text{negative\_slope}^2}}` | |||
| ================= ==================================================== | |||
| Args: | |||
| nonlinearity: the non-linear function | |||
| param: optional parameter for the non-linear function | |||
| Examples: | |||
| >>> gain = calculate_gain('leaky_relu', 0.2) # leaky_relu with negative_slope=0.2 | |||
| """ | |||
| linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d'] | |||
| if nonlinearity in linear_fns or nonlinearity == 'sigmoid': | |||
| return 1 | |||
| if nonlinearity == 'tanh': | |||
| return 5.0 / 3 | |||
| if nonlinearity == 'relu': | |||
| return math.sqrt(2.0) | |||
| if nonlinearity == 'leaky_relu': | |||
| if param is None: | |||
| negative_slope = 0.01 | |||
| elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float): | |||
| negative_slope = param | |||
| else: | |||
| raise ValueError("negative_slope {} not a valid number".format(param)) | |||
| return math.sqrt(2.0 / (1 + negative_slope**2)) | |||
| raise ValueError("Unsupported nonlinearity {}".format(nonlinearity)) | |||
| def _assignment(arr, num): | |||
| """Assign the value of `num` to `arr`.""" | |||
| if arr.shape == (): | |||
| arr = arr.reshape((1)) | |||
| arr[:] = num | |||
| arr = arr.reshape(()) | |||
| else: | |||
| if isinstance(num, np.ndarray): | |||
| arr[:] = num[:] | |||
| else: | |||
| arr[:] = num | |||
| return arr | |||
| def _calculate_in_and_out(arr): | |||
| """ | |||
| Calculate n_in and n_out. | |||
| Args: | |||
| arr (Array): Input array. | |||
| Returns: | |||
| Tuple, a tuple with two elements, the first element is `n_in` and the second element is `n_out`. | |||
| """ | |||
| dim = len(arr.shape) | |||
| if dim < 2: | |||
| raise ValueError("If initialize data with xavier uniform, the dimension of data must greater than 1.") | |||
| n_in = arr.shape[1] | |||
| n_out = arr.shape[0] | |||
| if dim > 2: | |||
| counter = reduce(lambda x, y: x*y, arr.shape[2:]) | |||
| n_in *= counter | |||
| n_out *= counter | |||
| return n_in, n_out | |||
| def _select_fan(array, mode): | |||
| mode = mode.lower() | |||
| valid_modes = ['fan_in', 'fan_out'] | |||
| if mode not in valid_modes: | |||
| raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes)) | |||
| fan_in, fan_out = _calculate_in_and_out(array) | |||
| return fan_in if mode == 'fan_in' else fan_out | |||
| class KaimingInit(init.Initializer): | |||
| r""" | |||
| Base Class. Initialize the array with He kaiming algorithm. | |||
| Args: | |||
| a: the negative slope of the rectifier used after this layer (only | |||
| used with ``'leaky_relu'``) | |||
| mode: either ``'fan_in'`` (default) or ``'fan_out'``. Choosing ``'fan_in'`` | |||
| preserves the magnitude of the variance of the weights in the | |||
| forward pass. Choosing ``'fan_out'`` preserves the magnitudes in the | |||
| backwards pass. | |||
| nonlinearity: the non-linear function, recommended to use only with | |||
| ``'relu'`` or ``'leaky_relu'`` (default). | |||
| """ | |||
| def __init__(self, a=0, mode='fan_in', nonlinearity='leaky_relu'): | |||
| super(KaimingInit, self).__init__() | |||
| self.mode = mode | |||
| self.gain = _calculate_gain(nonlinearity, a) | |||
| def _initialize(self, arr): | |||
| pass | |||
| class KaimingUniform(KaimingInit): | |||
| r""" | |||
| Initialize the array with He kaiming uniform algorithm. The resulting tensor will | |||
| have values sampled from :math:`\mathcal{U}(-\text{bound}, \text{bound})` where | |||
| .. math:: | |||
| \text{bound} = \text{gain} \times \sqrt{\frac{3}{\text{fan\_mode}}} | |||
| Input: | |||
| arr (Array): The array to be assigned. | |||
| Returns: | |||
| Array, assigned array. | |||
| Examples: | |||
| >>> w = np.empty(3, 5) | |||
| >>> KaimingUniform(w, mode='fan_in', nonlinearity='relu') | |||
| """ | |||
| def _initialize(self, arr): | |||
| fan = _select_fan(arr, self.mode) | |||
| bound = math.sqrt(3.0)*self.gain / math.sqrt(fan) | |||
| np.random.seed(0) | |||
| data = np.random.uniform(-bound, bound, arr.shape) | |||
| _assignment(arr, data) | |||
| class KaimingNormal(KaimingInit): | |||
| r""" | |||
| Initialize the array with He kaiming normal algorithm. The resulting tensor will | |||
| have values sampled from :math:`\mathcal{N}(0, \text{std}^2)` where | |||
| .. math:: | |||
| \text{std} = \frac{\text{gain}}{\sqrt{\text{fan\_mode}}} | |||
| Input: | |||
| arr (Array): The array to be assigned. | |||
| Returns: | |||
| Array, assigned array. | |||
| Examples: | |||
| >>> w = np.empty(3, 5) | |||
| >>> KaimingNormal(w, mode='fan_out', nonlinearity='relu') | |||
| """ | |||
| def _initialize(self, arr): | |||
| fan = _select_fan(arr, self.mode) | |||
| std = self.gain / math.sqrt(fan) | |||
| np.random.seed(0) | |||
| data = np.random.normal(0, std, arr.shape) | |||
| _assignment(arr, data) | |||
| def default_recurisive_init(custom_cell): | |||
| """default_recurisive_init""" | |||
| for _, cell in custom_cell.cells_and_names(): | |||
| if isinstance(cell, nn.Conv2d): | |||
| cell.weight.default_input = init.initializer(KaimingUniform(a=math.sqrt(5)), | |||
| cell.weight.shape, | |||
| cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| fan_in, _ = _calculate_in_and_out(cell.weight) | |||
| bound = 1 / math.sqrt(fan_in) | |||
| np.random.seed(0) | |||
| cell.bias.default_input = init.initializer(init.Uniform(bound), | |||
| cell.bias.shape, | |||
| cell.bias.dtype) | |||
| elif isinstance(cell, nn.Dense): | |||
| cell.weight.default_input = init.initializer(KaimingUniform(a=math.sqrt(5)), | |||
| cell.weight.shape, | |||
| cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| fan_in, _ = _calculate_in_and_out(cell.weight) | |||
| bound = 1 / math.sqrt(fan_in) | |||
| np.random.seed(0) | |||
| cell.bias.default_input = init.initializer(init.Uniform(bound), | |||
| cell.bias.shape, | |||
| cell.bias.dtype) | |||
| elif isinstance(cell, (nn.BatchNorm2d, nn.BatchNorm1d)): | |||
| pass | |||
+ 0
- 142
examples/common/networks/vgg/vgg.py
View File
| @@ -1,142 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| Image classifiation. | |||
| """ | |||
| import math | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.common import initializer as init | |||
| from mindspore.common.initializer import initializer | |||
| from .utils.var_init import default_recurisive_init, KaimingNormal | |||
| def _make_layer(base, args, batch_norm): | |||
| """Make stage network of VGG.""" | |||
| layers = [] | |||
| in_channels = 3 | |||
| for v in base: | |||
| if v == 'M': | |||
| layers += [nn.MaxPool2d(kernel_size=2, stride=2)] | |||
| else: | |||
| weight_shape = (v, in_channels, 3, 3) | |||
| weight = initializer('XavierUniform', shape=weight_shape, dtype=mstype.float32).to_tensor() | |||
| if args.initialize_mode == "KaimingNormal": | |||
| weight = 'normal' | |||
| conv2d = nn.Conv2d(in_channels=in_channels, | |||
| out_channels=v, | |||
| kernel_size=3, | |||
| padding=args.padding, | |||
| pad_mode=args.pad_mode, | |||
| has_bias=args.has_bias, | |||
| weight_init=weight) | |||
| if batch_norm: | |||
| layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU()] | |||
| else: | |||
| layers += [conv2d, nn.ReLU()] | |||
| in_channels = v | |||
| return nn.SequentialCell(layers) | |||
| class Vgg(nn.Cell): | |||
| """ | |||
| VGG network definition. | |||
| Args: | |||
| base (list): Configuration for different layers, mainly the channel number of Conv layer. | |||
| num_classes (int): Class numbers. Default: 1000. | |||
| batch_norm (bool): Whether to do the batchnorm. Default: False. | |||
| batch_size (int): Batch size. Default: 1. | |||
| Returns: | |||
| Tensor, infer output tensor. | |||
| Examples: | |||
| >>> Vgg([64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], | |||
| >>> num_classes=1000, batch_norm=False, batch_size=1) | |||
| """ | |||
| def __init__(self, base, num_classes=1000, batch_norm=False, batch_size=1, args=None, phase="train"): | |||
| super(Vgg, self).__init__() | |||
| _ = batch_size | |||
| self.layers = _make_layer(base, args, batch_norm=batch_norm) | |||
| self.flatten = nn.Flatten() | |||
| dropout_ratio = 0.5 | |||
| if not args.has_dropout or phase == "test": | |||
| dropout_ratio = 1.0 | |||
| self.classifier = nn.SequentialCell([ | |||
| nn.Dense(512*7*7, 4096), | |||
| nn.ReLU(), | |||
| nn.Dropout(dropout_ratio), | |||
| nn.Dense(4096, 4096), | |||
| nn.ReLU(), | |||
| nn.Dropout(dropout_ratio), | |||
| nn.Dense(4096, num_classes)]) | |||
| if args.initialize_mode == "KaimingNormal": | |||
| default_recurisive_init(self) | |||
| self.custom_init_weight() | |||
| def construct(self, x): | |||
| x = self.layers(x) | |||
| x = self.flatten(x) | |||
| x = self.classifier(x) | |||
| return x | |||
| def custom_init_weight(self): | |||
| """ | |||
| Init the weight of Conv2d and Dense in the net. | |||
| """ | |||
| for _, cell in self.cells_and_names(): | |||
| if isinstance(cell, nn.Conv2d): | |||
| cell.weight.default_input = init.initializer( | |||
| KaimingNormal(a=math.sqrt(5), mode='fan_out', nonlinearity='relu'), | |||
| cell.weight.shape, cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| cell.bias.default_input = init.initializer( | |||
| 'zeros', cell.bias.shape, cell.bias.dtype) | |||
| elif isinstance(cell, nn.Dense): | |||
| cell.weight.default_input = init.initializer( | |||
| init.Normal(0.01), cell.weight.shape, cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| cell.bias.default_input = init.initializer( | |||
| 'zeros', cell.bias.shape, cell.bias.dtype) | |||
| cfg = { | |||
| '11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], | |||
| '13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], | |||
| '16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], | |||
| '19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'], | |||
| } | |||
| def vgg16(num_classes=1000, args=None, phase="train"): | |||
| """ | |||
| Get Vgg16 neural network with batch normalization. | |||
| Args: | |||
| num_classes (int): Class numbers. Default: 1000. | |||
| args(namespace): param for net init. | |||
| phase(str): train or test mode. | |||
| Returns: | |||
| Cell, cell instance of Vgg16 neural network with batch normalization. | |||
| Examples: | |||
| >>> vgg16(num_classes=1000, args=args) | |||
| """ | |||
| net = Vgg(cfg['16'], num_classes=num_classes, args=args, batch_norm=args.batch_norm, phase=phase) | |||
| return net | |||
+ 0
- 40
examples/common/networks/vgg/warmup_cosine_annealing_lr.py
View File
| @@ -1,40 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| warm up cosine annealing learning rate. | |||
| """ | |||
| import math | |||
| import numpy as np | |||
| from .linear_warmup import linear_warmup_lr | |||
| def warmup_cosine_annealing_lr(lr, steps_per_epoch, warmup_epochs, max_epoch, t_max, eta_min=0): | |||
| """warm up cosine annealing learning rate.""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch*steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs*steps_per_epoch) | |||
| lr_each_step = [] | |||
| for i in range(total_steps): | |||
| last_epoch = i // steps_per_epoch | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = eta_min + (base_lr - eta_min)*(1. + math.cos(math.pi*last_epoch / t_max)) / 2 | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
+ 0
- 84
examples/common/networks/vgg/warmup_step_lr.py
View File
| @@ -1,84 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| warm up step learning rate. | |||
| """ | |||
| from collections import Counter | |||
| import numpy as np | |||
| from .linear_warmup import linear_warmup_lr | |||
| def lr_steps(global_step, lr_init, lr_max, warmup_epochs, total_epochs, steps_per_epoch): | |||
| """Set learning rate.""" | |||
| lr_each_step = [] | |||
| total_steps = steps_per_epoch*total_epochs | |||
| warmup_steps = steps_per_epoch*warmup_epochs | |||
| if warmup_steps != 0: | |||
| inc_each_step = (float(lr_max) - float(lr_init)) / float(warmup_steps) | |||
| else: | |||
| inc_each_step = 0 | |||
| for i in range(total_steps): | |||
| if i < warmup_steps: | |||
| lr_value = float(lr_init) + inc_each_step*float(i) | |||
| else: | |||
| base = (1.0 - (float(i) - float(warmup_steps)) / (float(total_steps) - float(warmup_steps))) | |||
| lr_value = float(lr_max)*base*base | |||
| if lr_value < 0.0: | |||
| lr_value = 0.0 | |||
| lr_each_step.append(lr_value) | |||
| current_step = global_step | |||
| lr_each_step = np.array(lr_each_step).astype(np.float32) | |||
| learning_rate = lr_each_step[current_step:] | |||
| return learning_rate | |||
| def warmup_step_lr(lr, lr_epochs, steps_per_epoch, warmup_epochs, max_epoch, gamma=0.1): | |||
| """warmup_step_lr""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch*steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs*steps_per_epoch) | |||
| milestones = lr_epochs | |||
| milestones_steps = [] | |||
| for milestone in milestones: | |||
| milestones_step = milestone*steps_per_epoch | |||
| milestones_steps.append(milestones_step) | |||
| lr_each_step = [] | |||
| lr = base_lr | |||
| milestones_steps_counter = Counter(milestones_steps) | |||
| for i in range(total_steps): | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = lr*gamma**milestones_steps_counter[i] | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
| def multi_step_lr(lr, milestones, steps_per_epoch, max_epoch, gamma=0.1): | |||
| return warmup_step_lr(lr, milestones, steps_per_epoch, 0, max_epoch, gamma=gamma) | |||
| def step_lr(lr, epoch_size, steps_per_epoch, max_epoch, gamma=0.1): | |||
| lr_epochs = [] | |||
| for i in range(1, max_epoch): | |||
| if i % epoch_size == 0: | |||
| lr_epochs.append(i) | |||
| return multi_step_lr(lr, lr_epochs, steps_per_epoch, max_epoch, gamma=gamma) | |||
+ 0
- 0
examples/community/__init__.py
View File
+ 0
- 119
examples/community/face_adversarial_attack/README.md
View File
| @@ -1,119 +0,0 @@ | |||
| # 人脸识别物理对抗攻击 | |||
| ## 描述 | |||
| 本项目是基于MindSpore框架对人脸识别模型的物理对抗攻击,通过生成对抗口罩,使人脸佩戴后实现有目标攻击和非目标攻击。 | |||
| ## 模型结构 | |||
| 采用华为MindSpore官方训练的FaceRecognition模型 | |||
| https://www.mindspore.cn/resources/hub/details?MindSpore/1.7/facerecognition_ms1mv2 | |||
| ## 环境要求 | |||
| mindspore>=1.7,硬件平台为GPU。 | |||
| ## 脚本说明 | |||
| ```markdown | |||
| ├── readme.md | |||
| ├── photos | |||
| │ ├── adv_input //对抗图像 | |||
| │ ├── input //输入图像 | |||
| │ └── target //目标图像 | |||
| ├── outputs //训练后的图像 | |||
| ├── adversarial_attack.py //训练脚本 | |||
| │── example_non_target_attack.py //无目标攻击训练 | |||
| │── example_target_attack.py //有目标攻击训练 | |||
| │── loss_design.py //训练优化设置 | |||
| └── test.py //评估攻击效果 | |||
| ``` | |||
| ## 模型调用 | |||
| 方法一: | |||
| ```python | |||
| #基于mindspore_hub库调用FaceRecognition模型 | |||
| import mindspore_hub as mshub | |||
| from mindspore import context | |||
| def get_model(): | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU", device_id=0) | |||
| model = "mindspore/1.7/facerecognition_ms1mv2" | |||
| network = mshub.load(model) | |||
| network.set_train(False) | |||
| return network | |||
| ``` | |||
| 方法二: | |||
| ```text | |||
| 利用MindSpore代码仓中的 <https://gitee.com/mindspore/models/blob/master/research/cv/FaceRecognition/eval.py> 的get_model函数加载模型 | |||
| ``` | |||
| ## 训练过程 | |||
| 有目标攻击: | |||
| ```shell | |||
| cd face_adversarial_attack/ | |||
| python example_target_attack.py | |||
| ``` | |||
| 非目标攻击: | |||
| ```shell | |||
| cd face_adversarial_attack/ | |||
| python example_non_target_attack.py | |||
| ``` | |||
| ## 默认训练参数 | |||
| optimizer=adam, learning rate=0.01, weight_decay=0.0001, epoch=2000 | |||
| ## 评估过程 | |||
| 评估方法一: | |||
| ```shell | |||
| adversarial_attack.FaceAdversarialAttack.test_non_target_attack() | |||
| adversarial_attack.FaceAdversarialAttack.test_target_attack() | |||
| ``` | |||
| 评估方法二: | |||
| ```shell | |||
| cd face_adversarial_attack/ | |||
| python test.py | |||
| ``` | |||
| ## 实验结果 | |||
| 有目标攻击: | |||
| ```text | |||
| input_label: 60 | |||
| target_label: 345 | |||
| The confidence of the input image on the input label: 26.67 | |||
| The confidence of the input image on the target label: 0.95 | |||
| ================================ | |||
| adversarial_label: 345 | |||
| The confidence of the adversarial sample on the correct label: 1.82 | |||
| The confidence of the adversarial sample on the target label: 10.96 | |||
| input_label: 60, target_label: 345, adversarial_label: 345 | |||
| photos中是有目标攻击的实验结果 | |||
| ``` | |||
| 非目标攻击: | |||
| ```text | |||
| input_label: 60 | |||
| The confidence of the input image on the input label: 25.16 | |||
| ================================ | |||
| adversarial_label: 251 | |||
| The confidence of the adversarial sample on the correct label: 9.52 | |||
| The confidence of the adversarial sample on the adversarial label: 60.96 | |||
| input_label: 60, adversarial_label: 251 | |||
| ``` | |||
+ 0
- 275
examples/community/face_adversarial_attack/adversarial_attack.py
View File
| @@ -1,275 +0,0 @@ | |||
| # Copyright 2022 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Train set""" | |||
| import os | |||
| import re | |||
| import numpy as np | |||
| import face_recognition as fr | |||
| import face_recognition_models as frm | |||
| import dlib | |||
| from PIL import Image, ImageDraw | |||
| import mindspore | |||
| import mindspore.dataset.vision.py_transforms as P | |||
| from mindspore.dataset.vision.py_transforms import ToPIL as ToPILImage | |||
| from mindspore.dataset.vision.py_transforms import ToTensor | |||
| from mindspore import Parameter, ops, nn, Tensor | |||
| from loss_design import MyTrainOneStepCell, MyWithLossCellTargetAttack, \ | |||
| MyWithLossCellNonTargetAttack, FaceLossTargetAttack, FaceLossNoTargetAttack | |||
| class FaceAdversarialAttack(): | |||
| """ | |||
| Class used to create adversarial facial recognition attacks. | |||
| Args: | |||
| input_img (numpy.ndarray): The input image. | |||
| target_img (numpy.ndarray): The target image. | |||
| seed (int): optional Sets custom seed for reproducibility. Default is generated randomly. | |||
| net (mindspore.Model): face recognition model. | |||
| """ | |||
| def __init__(self, input_img, target_img, net, seed=None): | |||
| if seed is not None: | |||
| np.random.seed(seed) | |||
| self.mean = Tensor([0.485, 0.456, 0.406]) | |||
| self.std = Tensor([0.229, 0.224, 0.225]) | |||
| self.expand_dims = mindspore.ops.ExpandDims() | |||
| self.imageize = ToPILImage() | |||
| self.tensorize = ToTensor() | |||
| self.normalize = P.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) | |||
| self.resnet = net | |||
| self.input_tensor = Tensor(self.normalize(self.tensorize(input_img))) | |||
| self.target_tensor = Tensor(self.normalize(self.tensorize(target_img))) | |||
| self.input_emb = self.resnet(self.expand_dims(self.input_tensor, 0)) | |||
| self.target_emb = self.resnet(self.expand_dims(self.target_tensor, 0)) | |||
| self.adversarial_emb = None | |||
| self.mask_tensor = create_mask(input_img) | |||
| self.ref = self.mask_tensor | |||
| self.pm = Parameter(self.mask_tensor) | |||
| self.opt = nn.Adam([self.pm], learning_rate=0.01, weight_decay=0.0001) | |||
| def train(self, attack_method): | |||
| """ | |||
| Optimized adversarial image. | |||
| Args: | |||
| attack_method (String) : Including target attack and non_target attack. | |||
| Returns: | |||
| Tensor, adversarial image. | |||
| Tensor, mask image. | |||
| """ | |||
| if attack_method == "non_target_attack": | |||
| loss = FaceLossNoTargetAttack() | |||
| net_with_criterion = MyWithLossCellNonTargetAttack(self.resnet, loss, self.input_tensor) | |||
| if attack_method == "target_attack": | |||
| loss = FaceLossTargetAttack(self.target_emb) | |||
| net_with_criterion = MyWithLossCellTargetAttack(self.resnet, loss, self.input_tensor) | |||
| train_net = MyTrainOneStepCell(net_with_criterion, self.opt) | |||
| for i in range(2000): | |||
| self.mask_tensor = Tensor(self.pm) | |||
| loss = train_net(self.mask_tensor) | |||
| print("epoch %d ,loss: %f \n " % (i, loss.asnumpy().item())) | |||
| self.mask_tensor = ops.clip_by_value( | |||
| self.mask_tensor, Tensor(0, mindspore.float32), Tensor(1, mindspore.float32)) | |||
| adversarial_tensor = apply( | |||
| self.input_tensor, | |||
| (self.mask_tensor - self.mean[:, None, None]) / self.std[:, None, None], | |||
| self.ref) | |||
| adversarial_tensor = self._reverse_norm(adversarial_tensor) | |||
| processed_input_tensor = self._reverse_norm(self.input_tensor) | |||
| processed_target_tensor = self._reverse_norm(self.target_tensor) | |||
| return { | |||
| "adversarial_tensor": adversarial_tensor, | |||
| "mask_tensor": self.mask_tensor, | |||
| "processed_input_tensor": processed_input_tensor, | |||
| "processed_target_tensor": processed_target_tensor | |||
| } | |||
| def test_target_attack(self): | |||
| """ | |||
| The model is used to test the recognition ability of adversarial images under target attack. | |||
| """ | |||
| adversarial_tensor = apply( | |||
| self.input_tensor, | |||
| (self.mask_tensor - self.mean[:, None, None]) / self.std[:, None, None], | |||
| self.ref) | |||
| self.adversarial_emb = self.resnet(self.expand_dims(adversarial_tensor, 0)) | |||
| self.input_emb = self.resnet(self.expand_dims(self.input_tensor, 0)) | |||
| self.target_emb = self.resnet(self.expand_dims(self.target_tensor, 0)) | |||
| adversarial_index = np.argmax(self.adversarial_emb.asnumpy()) | |||
| target_index = np.argmax(self.target_emb.asnumpy()) | |||
| input_index = np.argmax(self.input_emb.asnumpy()) | |||
| print("input_label:", input_index) | |||
| print("target_label:", target_index) | |||
| print("The confidence of the input image on the input label:", self.input_emb.asnumpy()[0][input_index]) | |||
| print("The confidence of the input image on the target label:", self.input_emb.asnumpy()[0][target_index]) | |||
| print("================================") | |||
| print("adversarial_label:", adversarial_index) | |||
| print("The confidence of the adversarial sample on the correct label:", | |||
| self.adversarial_emb.asnumpy()[0][input_index]) | |||
| print("The confidence of the adversarial sample on the target label:", | |||
| self.adversarial_emb.asnumpy()[0][target_index]) | |||
| print("input_label: %d, target_label: %d, adversarial_label: %d" | |||
| % (input_index, target_index, adversarial_index)) | |||
| def test_non_target_attack(self): | |||
| """ | |||
| The model is used to test the recognition ability of adversarial images under non_target attack. | |||
| """ | |||
| adversarial_tensor = apply( | |||
| self.input_tensor, | |||
| (self.mask_tensor - self.mean[:, None, None]) / self.std[:, None, None], | |||
| self.ref) | |||
| self.adversarial_emb = self.resnet(self.expand_dims(adversarial_tensor, 0)) | |||
| self.input_emb = self.resnet(self.expand_dims(self.input_tensor, 0)) | |||
| adversarial_index = np.argmax(self.adversarial_emb.asnumpy()) | |||
| input_index = np.argmax(self.input_emb.asnumpy()) | |||
| print("input_label:", input_index) | |||
| print("The confidence of the input image on the input label:", self.input_emb.asnumpy()[0][input_index]) | |||
| print("================================") | |||
| print("adversarial_label:", adversarial_index) | |||
| print("The confidence of the adversarial sample on the correct label:", | |||
| self.adversarial_emb.asnumpy()[0][input_index]) | |||
| print("The confidence of the adversarial sample on the adversarial label:", | |||
| self.adversarial_emb.asnumpy()[0][adversarial_index]) | |||
| print( | |||
| "input_label: %d, adversarial_label: %d" % (input_index, adversarial_index)) | |||
| def _reverse_norm(self, image_tensor): | |||
| """ | |||
| Reverses normalization for a given image_tensor. | |||
| Args: | |||
| image_tensor (Tensor): Tensor. | |||
| Returns: | |||
| Tensor, image. | |||
| """ | |||
| tensor = image_tensor * self.std[:, None, None] + self.mean[:, None, None] | |||
| return tensor | |||
| def apply(image_tensor, mask_tensor, reference_tensor): | |||
| """ | |||
| Apply a mask over an image. | |||
| Args: | |||
| image_tensor (Tensor): Canvas to be used to apply mask on. | |||
| mask_tensor (Tensor): Mask to apply over the image. | |||
| reference_tensor (Tensor): Used to reference mask boundaries | |||
| Returns: | |||
| Tensor, image. | |||
| """ | |||
| tensor = mindspore.numpy.where((reference_tensor == 0), image_tensor, mask_tensor) | |||
| return tensor | |||
| def create_mask(face_image): | |||
| """ | |||
| Create mask image. | |||
| Args: | |||
| face_image (PIL.Image): image of a detected face. | |||
| Returns: | |||
| mask_tensor : a mask image. | |||
| """ | |||
| mask = Image.new('RGB', face_image.size, color=(0, 0, 0)) | |||
| d = ImageDraw.Draw(mask) | |||
| landmarks = fr.face_landmarks(np.array(face_image)) | |||
| area = [landmark | |||
| for landmark in landmarks[0]['chin'] | |||
| if landmark[1] > max(landmarks[0]['nose_tip'])[1]] | |||
| area.append(landmarks[0]['nose_bridge'][1]) | |||
| d.polygon(area, fill=(255, 255, 255)) | |||
| mask = np.array(mask) | |||
| mask = mask.astype(np.float32) | |||
| for i in range(mask.shape[0]): | |||
| for j in range(mask.shape[1]): | |||
| for k in range(mask.shape[2]): | |||
| if mask[i][j][k] == 255.: | |||
| mask[i][j][k] = 0.5 | |||
| else: | |||
| mask[i][j][k] = 0 | |||
| mask_tensor = Tensor(mask) | |||
| mask_tensor = mask_tensor.swapaxes(0, 2).swapaxes(1, 2) | |||
| mask_tensor.requires_grad = True | |||
| return mask_tensor | |||
| def detect_face(image): | |||
| """ | |||
| Face detection and alignment process using dlib library. | |||
| Args: | |||
| image (numpy.ndarray): image file location. | |||
| Returns: | |||
| face_image : Resized face image. | |||
| """ | |||
| dlib_detector = dlib.get_frontal_face_detector() | |||
| dlib_shape_predictor = dlib.shape_predictor(frm.pose_predictor_model_location()) | |||
| dlib_image = dlib.load_rgb_image(image) | |||
| detections = dlib_detector(dlib_image, 1) | |||
| dlib_faces = dlib.full_object_detections() | |||
| for det in detections: | |||
| dlib_faces.append(dlib_shape_predictor(dlib_image, det)) | |||
| face_image = Image.fromarray(dlib.get_face_chip(dlib_image, dlib_faces[0], size=112)) | |||
| return face_image | |||
| def load_data(data): | |||
| """ | |||
| An auxiliary function that loads image data. | |||
| Args: | |||
| data (String): The path to the given data. | |||
| Returns: | |||
| list : Resize list of face images. | |||
| """ | |||
| image_files = [f for f in os.listdir(data) if re.search(r'.*\.(jpe?g|png)', f)] | |||
| image_files_locs = [os.path.join(data, f) for f in image_files] | |||
| image_list = [] | |||
| for img in image_files_locs: | |||
| image_list.append(detect_face(img)) | |||
| return image_list | |||
+ 0
- 45
examples/community/face_adversarial_attack/example_non_target_attack.py
View File
| @@ -1,45 +0,0 @@ | |||
| # Copyright 2022 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """non target attack""" | |||
| import numpy as np | |||
| import matplotlib.image as mp | |||
| from mindspore import context | |||
| import adversarial_attack | |||
| from FaceRecognition.eval import get_model | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| if __name__ == '__main__': | |||
| inputs = adversarial_attack.load_data('photos/input/') | |||
| targets = adversarial_attack.load_data('photos/target/') | |||
| net = get_model() | |||
| adversarial = adversarial_attack.FaceAdversarialAttack(inputs[0], targets[0], net) | |||
| ATTACK_METHOD = "non_target_attack" | |||
| tensor_dict = adversarial.train(attack_method=ATTACK_METHOD) | |||
| mp.imsave('./outputs/adversarial_example.jpg', | |||
| np.transpose(tensor_dict.get("adversarial_tensor").asnumpy(), (1, 2, 0))) | |||
| mp.imsave('./outputs/mask.jpg', | |||
| np.transpose(tensor_dict.get("mask_tensor").asnumpy(), (1, 2, 0))) | |||
| mp.imsave('./outputs/input_image.jpg', | |||
| np.transpose(tensor_dict.get("processed_input_tensor").asnumpy(), (1, 2, 0))) | |||
| mp.imsave('./outputs/target_image.jpg', | |||
| np.transpose(tensor_dict.get("processed_target_tensor").asnumpy(), (1, 2, 0))) | |||
| adversarial.test_non_target_attack() | |||
+ 0
- 46
examples/community/face_adversarial_attack/example_target_attack.py
View File
| @@ -1,46 +0,0 @@ | |||
| # Copyright 2022 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """target attack""" | |||
| import numpy as np | |||
| import matplotlib.image as mp | |||
| from mindspore import context | |||
| import adversarial_attack | |||
| from FaceRecognition.eval import get_model | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| if __name__ == '__main__': | |||
| inputs = adversarial_attack.load_data('photos/input/') | |||
| targets = adversarial_attack.load_data('photos/target/') | |||
| net = get_model() | |||
| adversarial = adversarial_attack.FaceAdversarialAttack(inputs[0], targets[0], net) | |||
| ATTACK_METHOD = "target_attack" | |||
| tensor_dict = adversarial.train(attack_method=ATTACK_METHOD) | |||
| mp.imsave('./outputs/adversarial_example.jpg', | |||
| np.transpose(tensor_dict.get("adversarial_tensor").asnumpy(), (1, 2, 0))) | |||
| mp.imsave('./outputs/mask.jpg', | |||
| np.transpose(tensor_dict.get("mask_tensor").asnumpy(), (1, 2, 0))) | |||
| mp.imsave('./outputs/input_image.jpg', | |||
| np.transpose(tensor_dict.get("processed_input_tensor").asnumpy(), (1, 2, 0))) | |||
| mp.imsave('./outputs/target_image.jpg', | |||
| np.transpose(tensor_dict.get("processed_target_tensor").asnumpy(), (1, 2, 0))) | |||
| adversarial.test_target_attack() | |||
+ 0
- 154
examples/community/face_adversarial_attack/loss_design.py
View File
| @@ -1,154 +0,0 @@ | |||
| # Copyright 2022 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """optimization Settings""" | |||
| import mindspore | |||
| from mindspore import ops, nn, Tensor | |||
| from mindspore.dataset.vision.py_transforms import ToTensor | |||
| import mindspore.dataset.vision.py_transforms as P | |||
| class MyTrainOneStepCell(nn.TrainOneStepCell): | |||
| """ | |||
| Encapsulation class of network training. | |||
| Append an optimizer to the training network after that the construct | |||
| function can be called to create the backward graph. | |||
| Args: | |||
| network (Cell): The training network. Note that loss function should have been added. | |||
| optimizer (Optimizer): Optimizer for updating the weights. | |||
| sens (Number): The adjust parameter. Default: 1.0. | |||
| """ | |||
| def __init__(self, network, optimizer, sens=1.0): | |||
| super(MyTrainOneStepCell, self).__init__(network, optimizer, sens) | |||
| self.grad = ops.composite.GradOperation(get_all=True, sens_param=False) | |||
| def construct(self, *inputs): | |||
| """Defines the computation performed.""" | |||
| loss = self.network(*inputs) | |||
| grads = self.grad(self.network)(*inputs) | |||
| self.optimizer(grads) | |||
| return loss | |||
| class MyWithLossCellTargetAttack(nn.Cell): | |||
| """The loss function defined by the target attack""" | |||
| def __init__(self, net, loss_fn, input_tensor): | |||
| super(MyWithLossCellTargetAttack, self).__init__(auto_prefix=False) | |||
| self.net = net | |||
| self._loss_fn = loss_fn | |||
| self.std = Tensor([0.229, 0.224, 0.225]) | |||
| self.mean = Tensor([0.485, 0.456, 0.406]) | |||
| self.expand_dims = mindspore.ops.ExpandDims() | |||
| self.normalize = P.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) | |||
| self.tensorize = ToTensor() | |||
| self.input_tensor = input_tensor | |||
| self.input_emb = self.net(self.expand_dims(self.input_tensor, 0)) | |||
| @property | |||
| def backbone_network(self): | |||
| return self.net | |||
| def construct(self, mask_tensor): | |||
| ref = mask_tensor | |||
| adversarial_tensor = mindspore.numpy.where( | |||
| (ref == 0), | |||
| self.input_tensor, | |||
| (mask_tensor - self.mean[:, None, None]) / self.std[:, None, None]) | |||
| adversarial_emb = self.net(self.expand_dims(adversarial_tensor, 0)) | |||
| loss = self._loss_fn(adversarial_emb) | |||
| return loss | |||
| class MyWithLossCellNonTargetAttack(nn.Cell): | |||
| """The loss function defined by the non target attack""" | |||
| def __init__(self, net, loss_fn, input_tensor): | |||
| super(MyWithLossCellNonTargetAttack, self).__init__(auto_prefix=False) | |||
| self.net = net | |||
| self._loss_fn = loss_fn | |||
| self.std = Tensor([0.229, 0.224, 0.225]) | |||
| self.mean = Tensor([0.485, 0.456, 0.406]) | |||
| self.expand_dims = mindspore.ops.ExpandDims() | |||
| self.normalize = P.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) | |||
| self.tensorize = ToTensor() | |||
| self.input_tensor = input_tensor | |||
| self.input_emb = self.net(self.expand_dims(self.input_tensor, 0)) | |||
| @property | |||
| def backbone_network(self): | |||
| return self.net | |||
| def construct(self, mask_tensor): | |||
| ref = mask_tensor | |||
| adversarial_tensor = mindspore.numpy.where( | |||
| (ref == 0), | |||
| self.input_tensor, | |||
| (mask_tensor - self.mean[:, None, None]) / self.std[:, None, None]) | |||
| adversarial_emb = self.net(self.expand_dims(adversarial_tensor, 0)) | |||
| loss = self._loss_fn(adversarial_emb, self.input_emb) | |||
| return loss | |||
| class FaceLossTargetAttack(nn.Cell): | |||
| """The loss function of the target attack""" | |||
| def __init__(self, target_emb): | |||
| super(FaceLossTargetAttack, self).__init__() | |||
| self.uniformreal = ops.UniformReal(seed=2) | |||
| self.sum = ops.ReduceSum(keep_dims=False) | |||
| self.norm = nn.Norm(keep_dims=True) | |||
| self.zeroslike = ops.ZerosLike() | |||
| self.concat_op1 = ops.Concat(1) | |||
| self.concat_op2 = ops.Concat(2) | |||
| self.pow = ops.Pow() | |||
| self.reduce_sum = ops.operations.ReduceSum() | |||
| self.target_emb = target_emb | |||
| self.abs = ops.Abs() | |||
| self.reduce_mean = ops.ReduceMean() | |||
| def construct(self, adversarial_emb): | |||
| prod_sum = self.reduce_sum(adversarial_emb * self.target_emb, (1,)) | |||
| square1 = self.reduce_sum(ops.functional.square(adversarial_emb), (1,)) | |||
| square2 = self.reduce_sum(ops.functional.square(self.target_emb), (1,)) | |||
| denom = ops.functional.sqrt(square1) * ops.functional.sqrt(square2) | |||
| loss = -(prod_sum / denom) | |||
| return loss | |||
| class FaceLossNoTargetAttack(nn.Cell): | |||
| """The loss function of the non-target attack""" | |||
| def __init__(self): | |||
| """Initialization""" | |||
| super(FaceLossNoTargetAttack, self).__init__() | |||
| self.uniformreal = ops.UniformReal(seed=2) | |||
| self.sum = ops.ReduceSum(keep_dims=False) | |||
| self.norm = nn.Norm(keep_dims=True) | |||
| self.zeroslike = ops.ZerosLike() | |||
| self.concat_op1 = ops.Concat(1) | |||
| self.concat_op2 = ops.Concat(2) | |||
| self.pow = ops.Pow() | |||
| self.reduce_sum = ops.operations.ReduceSum() | |||
| self.abs = ops.Abs() | |||
| self.reduce_mean = ops.ReduceMean() | |||
| def construct(self, adversarial_emb, input_emb): | |||
| prod_sum = self.reduce_sum(adversarial_emb * input_emb, (1,)) | |||
| square1 = self.reduce_sum(ops.functional.square(adversarial_emb), (1,)) | |||
| square2 = self.reduce_sum(ops.functional.square(input_emb), (1,)) | |||
| denom = ops.functional.sqrt(square1) * ops.functional.sqrt(square2) | |||
| loss = prod_sum / denom | |||
| return loss | |||
BIN
examples/community/face_adversarial_attack/photos/adv_input/adv.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 318 | Height: 318 | Size: 267 kB |
BIN
examples/community/face_adversarial_attack/photos/input/input1.jpg
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1024 | Height: 774 | Size: 88 kB |
BIN
examples/community/face_adversarial_attack/photos/target/target1.jpg
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1523 | Height: 2048 | Size: 653 kB |
+ 0
- 59
examples/community/face_adversarial_attack/test.py
View File
| @@ -1,59 +0,0 @@ | |||
| # Copyright 2022 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """test""" | |||
| import numpy as np | |||
| from mindspore import context, Tensor | |||
| import mindspore | |||
| from mindspore.dataset.vision.py_transforms import ToTensor | |||
| import mindspore.dataset.vision.py_transforms as P | |||
| from FaceRecognition.eval import get_model | |||
| import adversarial_attack | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| if __name__ == '__main__': | |||
| image = adversarial_attack.load_data('photos/adv_input/') | |||
| inputs = adversarial_attack.load_data('photos/input/') | |||
| targets = adversarial_attack.load_data('photos/target/') | |||
| tensorize = ToTensor() | |||
| normalize = P.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) | |||
| expand_dims = mindspore.ops.ExpandDims() | |||
| mean = Tensor([0.485, 0.456, 0.406]) | |||
| std = Tensor([0.229, 0.224, 0.225]) | |||
| resnet = get_model() | |||
| adv = Tensor(normalize(tensorize(image[0]))) | |||
| input_tensor = Tensor(normalize(tensorize(inputs[0]))) | |||
| target_tensor = Tensor(normalize(tensorize(targets[0]))) | |||
| adversarial_emb = resnet(expand_dims(adv, 0)) | |||
| input_emb = resnet(expand_dims(input_tensor, 0)) | |||
| target_emb = resnet(expand_dims(target_tensor, 0)) | |||
| adversarial_index = np.argmax(adversarial_emb.asnumpy()) | |||
| target_index = np.argmax(target_emb.asnumpy()) | |||
| input_index = np.argmax(input_emb.asnumpy()) | |||
| print("input_label:", input_index) | |||
| print("The confidence of the input image on the input label:", input_emb.asnumpy()[0][input_index]) | |||
| print("================================") | |||
| print("adversarial_label:", adversarial_index) | |||
| print("The confidence of the adversarial sample on the correct label:", adversarial_emb.asnumpy()[0][input_index]) | |||
| print("The confidence of the adversarial sample on the adversarial label:", | |||
| adversarial_emb.asnumpy()[0][adversarial_index]) | |||
| print("input_label:%d, adversarial_label:%d" % (input_index, adversarial_index)) | |||
+ 0
- 40
examples/model_security/README.md
View File
| @@ -1,40 +0,0 @@ | |||
| # Application demos of model security | |||
| ## Introduction | |||
| It has been proved that AI models are vulnerable to adversarial noise that invisible to human eye. Through those | |||
| demos in this package, you will learn to use the tools provided by MindArmour to generate adversarial samples and | |||
| also improve the robustness of your model. | |||
| ## 1. Generate adversarial samples (Attack method) | |||
| Attack methods can be classified into white box attack and black box attack. White-box attack means that the attacker | |||
| is accessible to the model structure and its parameters. Black-box means that the attacker can only obtain the predict | |||
| results of the | |||
| target model. | |||
| ### white-box attack | |||
| Running the classical attack method: FGSM-Attack. | |||
| ```sh | |||
| $ cd examples/model_security/model_attacks/white-box | |||
| $ python mnist_attack_fgsm.py | |||
| ``` | |||
| ### black-box attack | |||
| Running the classical black method: PSO-Attack. | |||
| ```sh | |||
| $ cd examples/model_security/model_attacks/black-box | |||
| $ python mnist_attack_pso.py | |||
| ``` | |||
| ## 2. Improve the robustness of models | |||
| ### adversarial training | |||
| Adversarial training is an effective method to enhance the model's robustness to attacks, in which generated | |||
| adversarial samples are fed into the model for retraining. | |||
| ```sh | |||
| $ cd examples/model_security/model_defenses | |||
| $ python mnist_defense_nad.py | |||
| ``` | |||
| ### adversarial detection | |||
| Besides adversarial training, there is another type of defense method: adversarial detection. This method is mainly | |||
| for black-box attack. The reason is that black-box attacks usually require frequent queries to the model, and the | |||
| difference between adjacent queries input is small. The detection algorithm could analyze the similarity of a series | |||
| of queries and recognize the attack. | |||
| ```sh | |||
| $ cd examples/model_security/model_defenses | |||
| $ python mnist_similarity_detector.py | |||
| ``` | |||
+ 0
- 0
examples/model_security/__init__.py
View File
+ 0
- 0
examples/model_security/model_attacks/__init__.py
View File
+ 0
- 0
examples/model_security/model_attacks/black_box/__init__.py
View File
+ 0
- 47
examples/model_security/model_attacks/cv/faster_rcnn/README.md
View File
| @@ -1,47 +0,0 @@ | |||
| # Dataset | |||
| Dataset used: [COCO2017](<https://cocodataset.org/>) | |||
| - Dataset size:19G | |||
| - Train:18G,118000 images | |||
| - Val:1G,5000 images | |||
| - Annotations:241M,instances,captions,person_keypoints etc | |||
| - Data format:image and json files | |||
| - Note:Data will be processed in dataset.py | |||
| # Environment Requirements | |||
| - Install [MindSpore](https://www.mindspore.cn/install/en). | |||
| - Download the dataset COCO2017. | |||
| - We use COCO2017 as dataset in this example. | |||
| Install Cython and pycocotool, and you can also install mmcv to process data. | |||
| ``` | |||
| pip install Cython | |||
| pip install pycocotools | |||
| pip install mmcv==0.2.14 | |||
| ``` | |||
| And change the COCO_ROOT and other settings you need in `config.py`. The directory structure is as follows: | |||
| ``` | |||
| . | |||
| └─cocodataset | |||
| ├─annotations | |||
| ├─instance_train2017.json | |||
| └─instance_val2017.json | |||
| ├─val2017 | |||
| └─train2017 | |||
| ``` | |||
| # Quick start | |||
| You can download the pre-trained model checkpoint file [here](<https://www.mindspore.cn/resources/hub/details?2505/MindSpore/ascend/0.7/fasterrcnn_v1.0_coco2017>). | |||
| ``` | |||
| python coco_attack_pgd.py --pre_trained [PRETRAINED_CHECKPOINT_FILE] | |||
| ``` | |||
| > Adversarial samples will be generated and saved as pickle file. | |||
+ 0
- 150
examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_genetic.py
View File
| @@ -1,150 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """PSO attack for Faster R-CNN""" | |||
| import os | |||
| import numpy as np | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.common import set_seed | |||
| from mindspore import Tensor | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from src.FasterRcnn.faster_rcnn_r50 import Faster_Rcnn_Resnet50 | |||
| from src.config import config | |||
| from src.dataset import data_to_mindrecord_byte_image, create_fasterrcnn_dataset | |||
| # pylint: disable=locally-disabled, unused-argument, redefined-outer-name | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| set_seed(1) | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', device_id=1) | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, images, img_metas, gt_boxes, gt_labels, gt_num): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(images.shape) == 3: | |||
| inputs_num = 1 | |||
| images = np.expand_dims(images, axis=0) | |||
| else: | |||
| inputs_num = images.shape[0] | |||
| box_and_confi = [] | |||
| pred_labels = [] | |||
| gt_number = np.sum(gt_num) | |||
| for i in range(inputs_num): | |||
| inputs_i = np.expand_dims(images[i], axis=0) | |||
| output = self._network(Tensor(inputs_i.astype(np.float16)), Tensor(img_metas), | |||
| Tensor(gt_boxes), Tensor(gt_labels), Tensor(gt_num)) | |||
| all_bbox = output[0] | |||
| all_labels = output[1] | |||
| all_mask = output[2] | |||
| all_bbox_squee = np.squeeze(all_bbox.asnumpy()) | |||
| all_labels_squee = np.squeeze(all_labels.asnumpy()) | |||
| all_mask_squee = np.squeeze(all_mask.asnumpy()) | |||
| all_bboxes_tmp_mask = all_bbox_squee[all_mask_squee, :] | |||
| all_labels_tmp_mask = all_labels_squee[all_mask_squee] | |||
| if all_bboxes_tmp_mask.shape[0] > gt_number + 1: | |||
| inds = np.argsort(-all_bboxes_tmp_mask[:, -1]) | |||
| inds = inds[:gt_number+1] | |||
| all_bboxes_tmp_mask = all_bboxes_tmp_mask[inds] | |||
| all_labels_tmp_mask = all_labels_tmp_mask[inds] | |||
| box_and_confi.append(all_bboxes_tmp_mask) | |||
| pred_labels.append(all_labels_tmp_mask) | |||
| return np.array(box_and_confi), np.array(pred_labels) | |||
| if __name__ == '__main__': | |||
| prefix = 'FasterRcnn_eval.mindrecord' | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_file = os.path.join(mindrecord_dir, prefix) | |||
| pre_trained = '/ckpt_path' | |||
| print("CHECKING MINDRECORD FILES ...") | |||
| if not os.path.exists(mindrecord_file): | |||
| if not os.path.isdir(mindrecord_dir): | |||
| os.makedirs(mindrecord_dir) | |||
| if os.path.isdir(config.coco_root): | |||
| print("Create Mindrecord. It may take some time.") | |||
| data_to_mindrecord_byte_image("coco", False, prefix, file_num=1) | |||
| print("Create Mindrecord Done, at {}".format(mindrecord_dir)) | |||
| else: | |||
| print("coco_root not exits.") | |||
| print('Start generate adversarial samples.') | |||
| # build network and dataset | |||
| ds = create_fasterrcnn_dataset(mindrecord_file, batch_size=config.test_batch_size, \ | |||
| repeat_num=1, is_training=False) | |||
| net = Faster_Rcnn_Resnet50(config) | |||
| param_dict = load_checkpoint(pre_trained) | |||
| load_param_into_net(net, param_dict) | |||
| net = net.set_train(False) | |||
| # build attacker | |||
| model = ModelToBeAttacked(net) | |||
| attack = GeneticAttack(model, model_type='detection', max_steps=50, reserve_ratio=0.3, mutation_rate=0.05, | |||
| per_bounds=0.5, step_size=0.25, temp=0.1) | |||
| # generate adversarial samples | |||
| sample_num = 5 | |||
| ori_imagess = [] | |||
| adv_imgs = [] | |||
| ori_meta = [] | |||
| ori_box = [] | |||
| ori_labels = [] | |||
| ori_gt_num = [] | |||
| idx = 0 | |||
| for data in ds.create_dict_iterator(): | |||
| if idx > sample_num: | |||
| break | |||
| img_data = data['image'] | |||
| img_metas = data['image_shape'] | |||
| gt_bboxes = data['box'] | |||
| gt_labels = data['label'] | |||
| gt_num = data['valid_num'] | |||
| ori_imagess.append(img_data.asnumpy()) | |||
| ori_meta.append(img_metas.asnumpy()) | |||
| ori_box.append(gt_bboxes.asnumpy()) | |||
| ori_labels.append(gt_labels.asnumpy()) | |||
| ori_gt_num.append(gt_num.asnumpy()) | |||
| all_inputs = (img_data.asnumpy(), img_metas.asnumpy(), gt_bboxes.asnumpy(), | |||
| gt_labels.asnumpy(), gt_num.asnumpy()) | |||
| pre_gt_boxes, pre_gt_label = model.predict(*all_inputs) | |||
| success_flags, adv_img, query_times = attack.generate(all_inputs, (pre_gt_boxes, pre_gt_label)) | |||
| adv_imgs.append(adv_img) | |||
| idx += 1 | |||
| np.save('ori_imagess.npy', ori_imagess) | |||
| np.save('ori_meta.npy', ori_meta) | |||
| np.save('ori_box.npy', ori_box) | |||
| np.save('ori_labels.npy', ori_labels) | |||
| np.save('ori_gt_num.npy', ori_gt_num) | |||
| np.save('adv_imgs.npy', adv_imgs) | |||
| print('Generate adversarial samples complete.') | |||
+ 0
- 135
examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pgd.py
View File
| @@ -1,135 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """PGD attack for faster rcnn""" | |||
| import os | |||
| import argparse | |||
| import pickle | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.common import set_seed | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.composite import GradOperation | |||
| from mindarmour.adv_robustness.attacks import ProjectedGradientDescent | |||
| from src.FasterRcnn.faster_rcnn_r50 import Faster_Rcnn_Resnet50 | |||
| from src.config import config | |||
| from src.dataset import data_to_mindrecord_byte_image, create_fasterrcnn_dataset | |||
| # pylint: disable=locally-disabled, unused-argument, redefined-outer-name | |||
| set_seed(1) | |||
| parser = argparse.ArgumentParser(description='FasterRCNN attack') | |||
| parser.add_argument('--pre_trained', type=str, required=True, help='pre-trained ckpt file path for target model.') | |||
| parser.add_argument('--device_id', type=int, default=0, help='Device id, default is 0.') | |||
| parser.add_argument('--num', type=int, default=5, help='Number of adversarial examples.') | |||
| args = parser.parse_args() | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', device_id=args.device_id) | |||
| class LossNet(Cell): | |||
| """loss function.""" | |||
| def construct(self, x1, x2, x3, x4, x5, x6): | |||
| return x4 + x6 | |||
| class WithLossCell(Cell): | |||
| """Wrap the network with loss function.""" | |||
| def __init__(self, backbone, loss_fn): | |||
| super(WithLossCell, self).__init__(auto_prefix=False) | |||
| self._backbone = backbone | |||
| self._loss_fn = loss_fn | |||
| def construct(self, img_data, img_metas, gt_bboxes, gt_labels, gt_num, *labels): | |||
| loss1, loss2, loss3, loss4, loss5, loss6 = self._backbone(img_data, img_metas, gt_bboxes, gt_labels, gt_num) | |||
| return self._loss_fn(loss1, loss2, loss3, loss4, loss5, loss6) | |||
| @property | |||
| def backbone_network(self): | |||
| return self._backbone | |||
| class GradWrapWithLoss(Cell): | |||
| """ | |||
| Construct a network to compute the gradient of loss function in \ | |||
| input space and weighted by `weight`. | |||
| """ | |||
| def __init__(self, network): | |||
| super(GradWrapWithLoss, self).__init__() | |||
| self._grad_all = GradOperation(get_all=True, sens_param=False) | |||
| self._network = network | |||
| def construct(self, *inputs): | |||
| gout = self._grad_all(self._network)(*inputs) | |||
| return gout[0] | |||
| if __name__ == '__main__': | |||
| prefix = 'FasterRcnn_eval.mindrecord' | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_file = os.path.join(mindrecord_dir, prefix) | |||
| pre_trained = args.pre_trained | |||
| print("CHECKING MINDRECORD FILES ...") | |||
| if not os.path.exists(mindrecord_file): | |||
| if not os.path.isdir(mindrecord_dir): | |||
| os.makedirs(mindrecord_dir) | |||
| if os.path.isdir(config.coco_root): | |||
| print("Create Mindrecord. It may take some time.") | |||
| data_to_mindrecord_byte_image("coco", False, prefix, file_num=1) | |||
| print("Create Mindrecord Done, at {}".format(mindrecord_dir)) | |||
| else: | |||
| print("coco_root not exits.") | |||
| print('Start generate adversarial samples.') | |||
| # build network and dataset | |||
| ds = create_fasterrcnn_dataset(mindrecord_file, batch_size=config.test_batch_size, \ | |||
| repeat_num=1, is_training=True) | |||
| net = Faster_Rcnn_Resnet50(config) | |||
| param_dict = load_checkpoint(pre_trained) | |||
| load_param_into_net(net, param_dict) | |||
| net = net.set_train() | |||
| # build attacker | |||
| with_loss_cell = WithLossCell(net, LossNet()) | |||
| grad_with_loss_net = GradWrapWithLoss(with_loss_cell) | |||
| attack = ProjectedGradientDescent(grad_with_loss_net, bounds=None, eps=0.1) | |||
| # generate adversarial samples | |||
| num = args.num | |||
| num_batches = num // config.test_batch_size | |||
| channel = 3 | |||
| adv_samples = [0]*(num_batches*config.test_batch_size) | |||
| adv_id = 0 | |||
| for data in ds.create_dict_iterator(num_epochs=num_batches): | |||
| img_data = data['image'] | |||
| img_metas = data['image_shape'] | |||
| gt_bboxes = data['box'] | |||
| gt_labels = data['label'] | |||
| gt_num = data['valid_num'] | |||
| adv_img = attack.generate((img_data.asnumpy(), \ | |||
| img_metas.asnumpy(), gt_bboxes.asnumpy(), gt_labels.asnumpy(), gt_num.asnumpy()), gt_labels.asnumpy()) | |||
| for item in adv_img: | |||
| adv_samples[adv_id] = item | |||
| adv_id += 1 | |||
| if adv_id >= num_batches*config.test_batch_size: | |||
| break | |||
| pickle.dump(adv_samples, open('adv_samples.pkl', 'wb')) | |||
| print('Generate adversarial samples complete.') | |||
+ 0
- 149
examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pso.py
View File
| @@ -1,149 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """PSO attack for Faster R-CNN""" | |||
| import os | |||
| import numpy as np | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.common import set_seed | |||
| from mindspore import Tensor | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from src.FasterRcnn.faster_rcnn_r50 import Faster_Rcnn_Resnet50 | |||
| from src.config import config | |||
| from src.dataset import data_to_mindrecord_byte_image, create_fasterrcnn_dataset | |||
| # pylint: disable=locally-disabled, unused-argument, redefined-outer-name | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| set_seed(1) | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', device_id=1) | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, images, img_metas, gt_boxes, gt_labels, gt_num): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(images.shape) == 3: | |||
| inputs_num = 1 | |||
| images = np.expand_dims(images, axis=0) | |||
| else: | |||
| inputs_num = images.shape[0] | |||
| box_and_confi = [] | |||
| pred_labels = [] | |||
| gt_number = np.sum(gt_num) | |||
| for i in range(inputs_num): | |||
| inputs_i = np.expand_dims(images[i], axis=0) | |||
| output = self._network(Tensor(inputs_i.astype(np.float16)), Tensor(img_metas), | |||
| Tensor(gt_boxes), Tensor(gt_labels), Tensor(gt_num)) | |||
| all_bbox = output[0] | |||
| all_labels = output[1] | |||
| all_mask = output[2] | |||
| all_bbox_squee = np.squeeze(all_bbox.asnumpy()) | |||
| all_labels_squee = np.squeeze(all_labels.asnumpy()) | |||
| all_mask_squee = np.squeeze(all_mask.asnumpy()) | |||
| all_bboxes_tmp_mask = all_bbox_squee[all_mask_squee, :] | |||
| all_labels_tmp_mask = all_labels_squee[all_mask_squee] | |||
| if all_bboxes_tmp_mask.shape[0] > gt_number + 1: | |||
| inds = np.argsort(-all_bboxes_tmp_mask[:, -1]) | |||
| inds = inds[:gt_number+1] | |||
| all_bboxes_tmp_mask = all_bboxes_tmp_mask[inds] | |||
| all_labels_tmp_mask = all_labels_tmp_mask[inds] | |||
| box_and_confi.append(all_bboxes_tmp_mask) | |||
| pred_labels.append(all_labels_tmp_mask) | |||
| return np.array(box_and_confi), np.array(pred_labels) | |||
| if __name__ == '__main__': | |||
| prefix = 'FasterRcnn_eval.mindrecord' | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_file = os.path.join(mindrecord_dir, prefix) | |||
| pre_trained = '/ckpt_path' | |||
| print("CHECKING MINDRECORD FILES ...") | |||
| if not os.path.exists(mindrecord_file): | |||
| if not os.path.isdir(mindrecord_dir): | |||
| os.makedirs(mindrecord_dir) | |||
| if os.path.isdir(config.coco_root): | |||
| print("Create Mindrecord. It may take some time.") | |||
| data_to_mindrecord_byte_image("coco", False, prefix, file_num=1) | |||
| print("Create Mindrecord Done, at {}".format(mindrecord_dir)) | |||
| else: | |||
| print("coco_root not exits.") | |||
| print('Start generate adversarial samples.') | |||
| # build network and dataset | |||
| ds = create_fasterrcnn_dataset(mindrecord_file, batch_size=config.test_batch_size, \ | |||
| repeat_num=1, is_training=False) | |||
| net = Faster_Rcnn_Resnet50(config) | |||
| param_dict = load_checkpoint(pre_trained) | |||
| load_param_into_net(net, param_dict) | |||
| net = net.set_train(False) | |||
| # build attacker | |||
| model = ModelToBeAttacked(net) | |||
| attack = PSOAttack(model, c=0.2, t_max=50, pm=0.5, model_type='detection', reserve_ratio=0.3) | |||
| # generate adversarial samples | |||
| sample_num = 5 | |||
| ori_imagess = [] | |||
| adv_imgs = [] | |||
| ori_meta = [] | |||
| ori_box = [] | |||
| ori_labels = [] | |||
| ori_gt_num = [] | |||
| idx = 0 | |||
| for data in ds.create_dict_iterator(): | |||
| if idx > sample_num: | |||
| break | |||
| img_data = data['image'] | |||
| img_metas = data['image_shape'] | |||
| gt_bboxes = data['box'] | |||
| gt_labels = data['label'] | |||
| gt_num = data['valid_num'] | |||
| ori_imagess.append(img_data.asnumpy()) | |||
| ori_meta.append(img_metas.asnumpy()) | |||
| ori_box.append(gt_bboxes.asnumpy()) | |||
| ori_labels.append(gt_labels.asnumpy()) | |||
| ori_gt_num.append(gt_num.asnumpy()) | |||
| all_inputs = (img_data.asnumpy(), img_metas.asnumpy(), gt_bboxes.asnumpy(), | |||
| gt_labels.asnumpy(), gt_num.asnumpy()) | |||
| pre_gt_boxes, pre_gt_label = model.predict(*all_inputs) | |||
| success_flags, adv_img, query_times = attack.generate(all_inputs, (pre_gt_boxes, pre_gt_label)) | |||
| adv_imgs.append(adv_img) | |||
| idx += 1 | |||
| np.save('ori_imagess.npy', ori_imagess) | |||
| np.save('ori_meta.npy', ori_meta) | |||
| np.save('ori_box.npy', ori_box) | |||
| np.save('ori_labels.npy', ori_labels) | |||
| np.save('ori_gt_num.npy', ori_gt_num) | |||
| np.save('adv_imgs.npy', adv_imgs) | |||
| print('Generate adversarial samples complete.') | |||
+ 0
- 31
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/__init__.py
View File
| @@ -1,31 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn Init.""" | |||
| from .resnet50 import ResNetFea, ResidualBlockUsing | |||
| from .bbox_assign_sample import BboxAssignSample | |||
| from .bbox_assign_sample_stage2 import BboxAssignSampleForRcnn | |||
| from .fpn_neck import FeatPyramidNeck | |||
| from .proposal_generator import Proposal | |||
| from .rcnn import Rcnn | |||
| from .rpn import RPN | |||
| from .roi_align import SingleRoIExtractor | |||
| from .anchor_generator import AnchorGenerator | |||
| __all__ = [ | |||
| "ResNetFea", "BboxAssignSample", "BboxAssignSampleForRcnn", | |||
| "FeatPyramidNeck", "Proposal", "Rcnn", | |||
| "RPN", "SingleRoIExtractor", "AnchorGenerator", "ResidualBlockUsing" | |||
| ] | |||
+ 0
- 84
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/anchor_generator.py
View File
| @@ -1,84 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn anchor generator.""" | |||
| import numpy as np | |||
| class AnchorGenerator(): | |||
| """Anchor generator for FasterRcnn.""" | |||
| def __init__(self, base_size, scales, ratios, scale_major=True, ctr=None): | |||
| """Anchor generator init method.""" | |||
| self.base_size = base_size | |||
| self.scales = np.array(scales) | |||
| self.ratios = np.array(ratios) | |||
| self.scale_major = scale_major | |||
| self.ctr = ctr | |||
| self.base_anchors = self.gen_base_anchors() | |||
| def gen_base_anchors(self): | |||
| """Generate a single anchor.""" | |||
| w = self.base_size | |||
| h = self.base_size | |||
| if self.ctr is None: | |||
| x_ctr = 0.5 * (w - 1) | |||
| y_ctr = 0.5 * (h - 1) | |||
| else: | |||
| x_ctr, y_ctr = self.ctr | |||
| h_ratios = np.sqrt(self.ratios) | |||
| w_ratios = 1 / h_ratios | |||
| if self.scale_major: | |||
| ws = (w * w_ratios[:, None] * self.scales[None, :]).reshape(-1) | |||
| hs = (h * h_ratios[:, None] * self.scales[None, :]).reshape(-1) | |||
| else: | |||
| ws = (w * self.scales[:, None] * w_ratios[None, :]).reshape(-1) | |||
| hs = (h * self.scales[:, None] * h_ratios[None, :]).reshape(-1) | |||
| base_anchors = np.stack( | |||
| [ | |||
| x_ctr - 0.5 * (ws - 1), y_ctr - 0.5 * (hs - 1), | |||
| x_ctr + 0.5 * (ws - 1), y_ctr + 0.5 * (hs - 1) | |||
| ], | |||
| axis=-1).round() | |||
| return base_anchors | |||
| def _meshgrid(self, x, y, row_major=True): | |||
| """Generate grid.""" | |||
| xx = np.repeat(x.reshape(1, len(x)), len(y), axis=0).reshape(-1) | |||
| yy = np.repeat(y, len(x)) | |||
| if row_major: | |||
| return xx, yy | |||
| return yy, xx | |||
| def grid_anchors(self, featmap_size, stride=16): | |||
| """Generate anchor list.""" | |||
| base_anchors = self.base_anchors | |||
| feat_h, feat_w = featmap_size | |||
| shift_x = np.arange(0, feat_w) * stride | |||
| shift_y = np.arange(0, feat_h) * stride | |||
| shift_xx, shift_yy = self._meshgrid(shift_x, shift_y) | |||
| shifts = np.stack([shift_xx, shift_yy, shift_xx, shift_yy], axis=-1) | |||
| shifts = shifts.astype(base_anchors.dtype) | |||
| # first feat_w elements correspond to the first row of shifts | |||
| # add A anchors (1, A, 4) to K shifts (K, 1, 4) to get | |||
| # shifted anchors (K, A, 4), reshape to (K*A, 4) | |||
| all_anchors = base_anchors[None, :, :] + shifts[:, None, :] | |||
| all_anchors = all_anchors.reshape(-1, 4) | |||
| return all_anchors | |||
+ 0
- 166
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/bbox_assign_sample.py
View File
| @@ -1,166 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn positive and negative sample screening for RPN.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| import mindspore.common.dtype as mstype | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| class BboxAssignSample(nn.Cell): | |||
| """ | |||
| Bbox assigner and sampler defination. | |||
| Args: | |||
| config (dict): Config. | |||
| batch_size (int): Batchsize. | |||
| num_bboxes (int): The anchor nums. | |||
| add_gt_as_proposals (bool): add gt bboxes as proposals flag. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| bbox_targets: bbox location, (batch_size, num_bboxes, 4) | |||
| bbox_weights: bbox weights, (batch_size, num_bboxes, 1) | |||
| labels: label for every bboxes, (batch_size, num_bboxes, 1) | |||
| label_weights: label weight for every bboxes, (batch_size, num_bboxes, 1) | |||
| Examples: | |||
| BboxAssignSample(config, 2, 1024, True) | |||
| """ | |||
| def __init__(self, config, batch_size, num_bboxes, add_gt_as_proposals): | |||
| super(BboxAssignSample, self).__init__() | |||
| cfg = config | |||
| self.batch_size = batch_size | |||
| self.neg_iou_thr = Tensor(cfg.neg_iou_thr, mstype.float16) | |||
| self.pos_iou_thr = Tensor(cfg.pos_iou_thr, mstype.float16) | |||
| self.min_pos_iou = Tensor(cfg.min_pos_iou, mstype.float16) | |||
| self.zero_thr = Tensor(0.0, mstype.float16) | |||
| self.num_bboxes = num_bboxes | |||
| self.num_gts = cfg.num_gts | |||
| self.num_expected_pos = cfg.num_expected_pos | |||
| self.num_expected_neg = cfg.num_expected_neg | |||
| self.add_gt_as_proposals = add_gt_as_proposals | |||
| if self.add_gt_as_proposals: | |||
| self.label_inds = Tensor(np.arange(1, self.num_gts + 1)) | |||
| self.concat = P.Concat(axis=0) | |||
| self.max_gt = P.ArgMaxWithValue(axis=0) | |||
| self.max_anchor = P.ArgMaxWithValue(axis=1) | |||
| self.sum_inds = P.ReduceSum() | |||
| self.iou = P.IOU() | |||
| self.greaterequal = P.GreaterEqual() | |||
| self.greater = P.Greater() | |||
| self.select = P.Select() | |||
| self.gatherND = P.GatherNd() | |||
| self.squeeze = P.Squeeze() | |||
| self.cast = P.Cast() | |||
| self.logicaland = P.LogicalAnd() | |||
| self.less = P.Less() | |||
| self.random_choice_with_mask_pos = P.RandomChoiceWithMask(self.num_expected_pos) | |||
| self.random_choice_with_mask_neg = P.RandomChoiceWithMask(self.num_expected_neg) | |||
| self.reshape = P.Reshape() | |||
| self.equal = P.Equal() | |||
| self.bounding_box_encode = P.BoundingBoxEncode(means=(0.0, 0.0, 0.0, 0.0), stds=(1.0, 1.0, 1.0, 1.0)) | |||
| self.scatterNdUpdate = P.ScatterNdUpdate() | |||
| self.scatterNd = P.ScatterNd() | |||
| self.logicalnot = P.LogicalNot() | |||
| self.tile = P.Tile() | |||
| self.zeros_like = P.ZerosLike() | |||
| self.assigned_gt_inds = Tensor(np.array(-1 * np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_zeros = Tensor(np.array(np.zeros(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_ones = Tensor(np.array(np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_ignores = Tensor(np.array(-1 * np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_pos_ones = Tensor(np.array(np.ones(self.num_expected_pos), dtype=np.int32)) | |||
| self.check_neg_mask = Tensor(np.array(np.ones(self.num_expected_neg - self.num_expected_pos), dtype=np.bool)) | |||
| self.range_pos_size = Tensor(np.arange(self.num_expected_pos).astype(np.float16)) | |||
| self.check_gt_one = Tensor(np.array(-1 * np.ones((self.num_gts, 4)), dtype=np.float16)) | |||
| self.check_anchor_two = Tensor(np.array(-2 * np.ones((self.num_bboxes, 4)), dtype=np.float16)) | |||
| def construct(self, gt_bboxes_i, gt_labels_i, valid_mask, bboxes, gt_valids): | |||
| gt_bboxes_i = self.select(self.cast(self.tile(self.reshape(self.cast(gt_valids, mstype.int32), \ | |||
| (self.num_gts, 1)), (1, 4)), mstype.bool_), gt_bboxes_i, self.check_gt_one) | |||
| bboxes = self.select(self.cast(self.tile(self.reshape(self.cast(valid_mask, mstype.int32), \ | |||
| (self.num_bboxes, 1)), (1, 4)), mstype.bool_), bboxes, self.check_anchor_two) | |||
| overlaps = self.iou(bboxes, gt_bboxes_i) | |||
| max_overlaps_w_gt_index, max_overlaps_w_gt = self.max_gt(overlaps) | |||
| _, max_overlaps_w_ac = self.max_anchor(overlaps) | |||
| neg_sample_iou_mask = self.logicaland(self.greaterequal(max_overlaps_w_gt, self.zero_thr), \ | |||
| self.less(max_overlaps_w_gt, self.neg_iou_thr)) | |||
| assigned_gt_inds2 = self.select(neg_sample_iou_mask, self.assigned_gt_zeros, self.assigned_gt_inds) | |||
| pos_sample_iou_mask = self.greaterequal(max_overlaps_w_gt, self.pos_iou_thr) | |||
| assigned_gt_inds3 = self.select(pos_sample_iou_mask, \ | |||
| max_overlaps_w_gt_index + self.assigned_gt_ones, assigned_gt_inds2) | |||
| assigned_gt_inds4 = assigned_gt_inds3 | |||
| for j in range(self.num_gts): | |||
| max_overlaps_w_ac_j = max_overlaps_w_ac[j:j+1:1] | |||
| overlaps_w_gt_j = self.squeeze(overlaps[j:j+1:1, ::]) | |||
| pos_mask_j = self.logicaland(self.greaterequal(max_overlaps_w_ac_j, self.min_pos_iou), \ | |||
| self.equal(overlaps_w_gt_j, max_overlaps_w_ac_j)) | |||
| assigned_gt_inds4 = self.select(pos_mask_j, self.assigned_gt_ones + j, assigned_gt_inds4) | |||
| assigned_gt_inds5 = self.select(valid_mask, assigned_gt_inds4, self.assigned_gt_ignores) | |||
| pos_index, valid_pos_index = self.random_choice_with_mask_pos(self.greater(assigned_gt_inds5, 0)) | |||
| pos_check_valid = self.cast(self.greater(assigned_gt_inds5, 0), mstype.float16) | |||
| pos_check_valid = self.sum_inds(pos_check_valid, -1) | |||
| valid_pos_index = self.less(self.range_pos_size, pos_check_valid) | |||
| pos_index = pos_index * self.reshape(self.cast(valid_pos_index, mstype.int32), (self.num_expected_pos, 1)) | |||
| pos_assigned_gt_index = self.gatherND(assigned_gt_inds5, pos_index) - self.assigned_pos_ones | |||
| pos_assigned_gt_index = pos_assigned_gt_index * self.cast(valid_pos_index, mstype.int32) | |||
| pos_assigned_gt_index = self.reshape(pos_assigned_gt_index, (self.num_expected_pos, 1)) | |||
| neg_index, valid_neg_index = self.random_choice_with_mask_neg(self.equal(assigned_gt_inds5, 0)) | |||
| num_pos = self.cast(self.logicalnot(valid_pos_index), mstype.float16) | |||
| num_pos = self.sum_inds(num_pos, -1) | |||
| unvalid_pos_index = self.less(self.range_pos_size, num_pos) | |||
| valid_neg_index = self.logicaland(self.concat((self.check_neg_mask, unvalid_pos_index)), valid_neg_index) | |||
| pos_bboxes_ = self.gatherND(bboxes, pos_index) | |||
| pos_gt_bboxes_ = self.gatherND(gt_bboxes_i, pos_assigned_gt_index) | |||
| pos_gt_labels = self.gatherND(gt_labels_i, pos_assigned_gt_index) | |||
| pos_bbox_targets_ = self.bounding_box_encode(pos_bboxes_, pos_gt_bboxes_) | |||
| valid_pos_index = self.cast(valid_pos_index, mstype.int32) | |||
| valid_neg_index = self.cast(valid_neg_index, mstype.int32) | |||
| bbox_targets_total = self.scatterNd(pos_index, pos_bbox_targets_, (self.num_bboxes, 4)) | |||
| bbox_weights_total = self.scatterNd(pos_index, valid_pos_index, (self.num_bboxes,)) | |||
| labels_total = self.scatterNd(pos_index, pos_gt_labels, (self.num_bboxes,)) | |||
| total_index = self.concat((pos_index, neg_index)) | |||
| total_valid_index = self.concat((valid_pos_index, valid_neg_index)) | |||
| label_weights_total = self.scatterNd(total_index, total_valid_index, (self.num_bboxes,)) | |||
| return bbox_targets_total, self.cast(bbox_weights_total, mstype.bool_), \ | |||
| labels_total, self.cast(label_weights_total, mstype.bool_) | |||